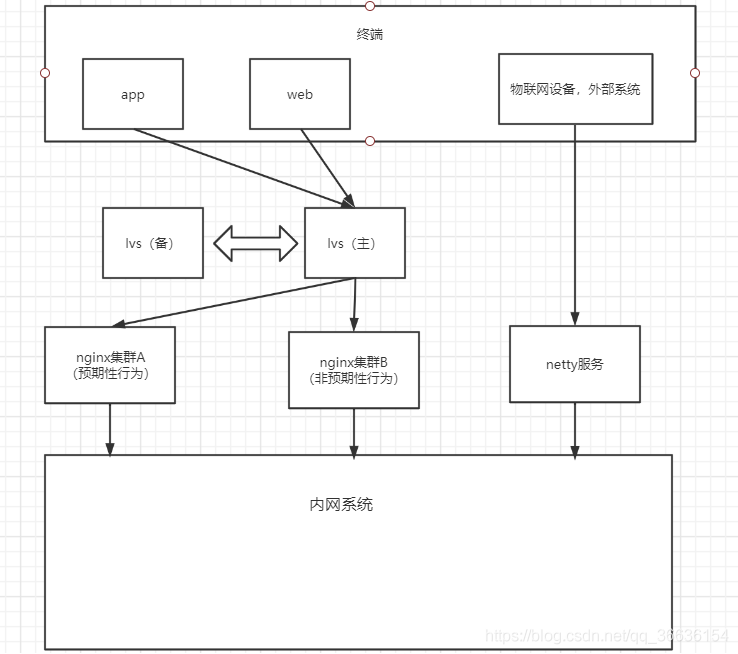
每一个系统都需要有一个供用户进入的入口,这个入口一般是用来接通公网和内网的通道。它是系统流量的总入口也是系统最前端的哨兵。本篇主要介绍从用户发起请求到负载均衡层的设计。 系统入口的业务 当前系统与外部交互的场景有两个: 1.与终端的交互 当前系统终端有app端(andriod,ios)web端。所有终端主要都通过http协议与服务端交互。 2.与外部系统的交互 当前系统从某种意义上讲也是一个大的数据中台,有可能是提供接口由外部系统调我们接口灌输进来,也可能是我们需要提供接口供外部系统取用数据 流量体量分析 当前系统的流量灌输主要有以下几个方面: 1.外部数据的导入 外部数据会定时从各个地方汇聚到本系统,本场景下流量稳定,不会有流量激增。数据汇聚的频率具体要看每种数据的提供方,但总体来说并不会有很大的流量,唯一有高流量的位置在接收物联网设计的信息,暂定这一块的会产生100次每秒的并发。 2.用户行为 C端,B端,G端用户使用本产品所产生的流量,这部分流量应该从两方面来分析,一方面是预期行为产生的流量,另一方面是非预期行为产生的流量。 预期行为指的是用户在正常使用产品时产生的流量,比如查看首页,修改个人信息,查看药品信息等,这些行为极少会产生突增的流量倾泻,一般是依赖用户数量的增长而增长,依照业务方提供的信息,该企业服务过1亿左右的人,拥有多次消费的忠实用户大约有三百万人。经过业务的测算并考虑到以后的增长,我们以10倍的体量来设计,暂时认定本系统用户基数为3000W,每日产生2000万pv 非预期行为指如秒杀,爆款,明星离婚带来的不确定性用户行为,可能会在某个时间突然激增,这些流量可能会是我们预知的,比如秒杀。也可能是我们未知的比如突然出现爆款等。这些行为的流量就不好测算了,但是要求我们的系统拥有在突发情况下的紧急应对办法。 这里我们主要讨论请求到达后端之后的流程,前端和app端的不做考虑。 针对如上的需求,我的设计是入口层分两部分:第一步分为http请求的输入,这一部分主要是用户行为产生的流量,包括预期性性和非预期性行为,请求首先到达第一层负载均衡器lvs,然后再由lvs转发到不同的第二层负载均衡器nginx上,nginx部分分为集群A和集群B,分别用来处理预期性行为和非预期性行为;第二部分为netty服务,用来接收各种各样协议类型的物联网数据。 业务要求架构要能适应系统的野蛮生长,所以我整体上采用了两层负载的方案去设计。详细设计分为三个模块:1.第一层负载lvs 2.第二层负载nginx 3.netty服务 第一层负载lvs 对于nginx相信很多人都了解,但是对于lvs可能很多人都不熟悉。它与nginx相同,都是一个开源的软件,但不同点是它是基于的四层负载,而nginx是基于七层负载。我们用lvs做第一层负载,将请求负载到不同的nginx上。这样可以让二层的nginx做水平扩展。并且可以让每个nginx在功能上有所区分,比如nginx1负责业务1,nginx2负载业务2。这样架构就更加灵活了,可以让各个业务互不影响。比如出现秒杀场景时,可以在秒杀开始前增加秒杀场景nginx,即使没来得及增加设备,当前nginx挂掉,其他业务线也可以稳定运行。 *关于四层负载和七层负载这里简单讲解下: osi网络分层将网络协议分为了七层,从下到上分为物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。每一层都有不同的协议,四层负载是指负载均衡器是根据前四层的协议来决定请求如何分发,也就是基于IP,TCP,IP等协议,根据ip加端口来决定请求如何分发,常见的有lvs和f5。它的速度比七层负载要快,因为不需要再解析请求的5,6,7层协议。七层负载指负载均衡器是根据前七层的协议来决定请求如何分发,常见的有nginx,apache。可以根据具体的应用层协议来决定如何转发请求,功能更多更灵活,但是效率要低于四层负载。 在这一层我们准备两台腾讯云服务器,采用lvs+keepalive来构建一个高可用的第一层负载。 第二层负载均衡nginx 这里我们需要配置两套nginx,一套用来接收用户预期性行为,一套用来接收非预期性的行为。由于在上一层我们使用了lvs,所以我们这一层的nginx可以水平扩容的,它的伸展性特别好,可以根据业务类型新增nginx(新开一条业务线,如果想让这条业务线与其他业务线隔绝,可以为这条业务线新加一套nginx),也可以根据流量大小横向扩展已经存在的nginx集群。 下面我们开始搭建我们的nginx: 1.安装nginx所需要的环境 2.安装nginx 由于nginx是源码包,所以需要编译安装,依次执行下面的命令 安装完成后会在/usr/local/nginx目下下生成如下目录 如果出现如下输出证明安装成功 安装成功后我们可以启动nginx啦 /usr/local/nginx/sbin/nginx –启动nginx 启动成功后我们可以在浏览器输入nginx所在机器的ip来访问了(nginx默认监听80端口,所以直接ip访问即可) 上图为访问ip之后出现的页面,说明我们的nginx已经没有问题了。 下面为了让我们的nginx更加可靠,我们还需要再对nginx做一些配置,附上我的nginx配置文件(负载均衡服务器数量还没有确定,后面根据压测结果确定最终节点数)。 集群A的nginx.conf文件 *:需要为nginx安装http_stub_status_module模块 *:nginx的安装和启动都比较方便,值得一提的是,nginx的所有操作都被封装到sbin目录下的nginx脚本里了,不管我们要对nginx做什么操作都可以直接运行这个脚本。下面列出一些常用的命令 ./nginx –不带参数表示启动nginx,默认去找conf目录下的nginx.conf配置文件 ./nginx -c /usr/local/nginx/conf/nginx.conf –以指定的配置文件来启动nginx ./nginx -s stop –停止nginx /nginx -s reload –重新加载nginx的配置文件,如果修改了nginx配置可以使用这个命令刷新配置
背景
概要设计
详细设计
yum -y install gcc pcre-devel zlib-devel openssl openssl-devel
./configure --prefix=/usr/local/nginx
make
make install
cd /usr/loca/nginx/ ---进入安装目录 ./sbin/nginx -t ---检测是否安装成功 ![]()
####################################################################################### ################这里暂时只有一台服务器,大家见谅####################################### ####################################################################################### #user nobody; #设置worker进程的数量,这里设置成于cpu相同 worker_processes 2; ##设置错误日志的输出级别为warn,减轻日志输出的压力 error_log logs/error.log warn; ##设置pid文件路径 pid logs/nginx.pid; events { ##使用epoll模型,linux下建议使用epoll use epoll; ##每个worker线城所能接受的最大连接数 worker_connections 50000; ##设置网路连接序列化,防止惊群现象发生,默认为on。 ##如果当前机器的worker线城很多的话可以选择置为off,但如果只有几个work线程的话建议为on,当前设为on。 accept_mutex on; } #################################################################################################################### ################对于轮询算法的选择这里推荐:当集群中的机器配置都一致时采用轮询即可################################## ################如果配置不同则采用权重算法,调高配置高的机器的权重。同时如果发送到################################## ################服务的请求有很多比较耗时,可以采用第三方模块nginx-upstream-fair##################################### #################################################################################################################### ##疫苗集群地址,这里为疫苗服务设置了5台机器,因为这里是主打业务。 upstream vaccine-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8021 max_fails=5 fail_timeout=600s; server 172.17.16.4:8022 max_fails=5 fail_timeout=600s; server 172.17.16.4:8023 max_fails=5 fail_timeout=600s; server 172.17.16.4:8024 max_fails=5 fail_timeout=600s; server 172.17.16.4:8025 max_fails=5 fail_timeout=600s; } ##样本集群地址 upstream specimen-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8031 max_fails=5 fail_timeout=600s; server 172.17.16.4:8032 max_fails=5 fail_timeout=600s; } ##血液集群地址 upstream blood-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8041 max_fails=5 fail_timeout=600s; server 172.17.16.4:8042 max_fails=5 fail_timeout=600s; } ##健康管理集群地址,这里为健康管理服务设置了5台机器,因为这里是主打业务。 upstream healthy-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8051 max_fails=5 fail_timeout=600s; server 172.17.16.4:8052 max_fails=5 fail_timeout=600s; server 172.17.16.4:8053 max_fails=5 fail_timeout=600s; server 172.17.16.4:8054 max_fails=5 fail_timeout=600s; server 172.17.16.4:8055 max_fails=5 fail_timeout=600s; } ##用户集群地址,用户基数比较多,设置了三台 upstream user-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8061 max_fails=5 fail_timeout=600s; server 172.17.16.4:8062 max_fails=5 fail_timeout=600s; server 172.17.16.4:8063 max_fails=5 fail_timeout=600s; } ##静态资源服务器 upstream static-cluster{ ##这里采用默认的轮询算法即可 server 172.17.16.4:8071 max_fails=5 fail_timeout=600s; server 172.17.16.4:8072 max_fails=5 fail_timeout=600s; } http { ##设定mime类型,类型由mime.type文件定义 include mime.types; default_type application/octet-stream; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; ##只提供80端口的监听 server { listen 80; server_name localhost; ##设置编码为utf-8 charset utf-8; ##开启访问日志,用来更好的统计用户访问数据 access_log logs/host.access.log main; ##匹配疫苗服务相关请求 location ^~/vaccine { proxy_pass https://vaccine-cluster; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##匹配样本服务相关请求 location ^~/specimen { proxy_pass https://specimen-cluster; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##匹配血液服务相关请求 location ^~/blood { proxy_pass https://blood-cluster; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##匹配健康管理服务相关请求 location ^~/healthy { proxy_pass https://healthy-cluster; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##匹配用户服务相关请求 location ^~/user { proxy_pass https://user-cluster; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##匹配数据拉取服务相关请求 location ^~/transfer { proxy_pass https://172.17.16.4:8010; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##状态监控 location /status { stub_status on; access_log off; ##设置允许的ip,只有127.0.0.1和172.16.100.71两台服务器可以访问状态监控 allow 127.0.0.1; ##设置允许的ip,只有127.0.0.1和172.16.100.71两台服务器可以访问状态监控 allow 172.16.100.71; ##禁止访问,配合allow可以起到白名单的效果 deny all; } ##匹配静态资源服务器,这里没有将静态资源放到本nginx本地,因为考虑到后期可能会水平扩展nginx,所以将静态资源独立存放。 location ~ .*.(js|css|html|svg|ico|png|jpg|gif) { proxy_pass https://static-cluster; root static; proxy_connection_timeout 30s; proxy_send_timeout 30s; proxy_read_timeout 30s; } ##如果都没有匹配则禁止访问 location / { ##禁止访问 deny all; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }
#user nobody; #设置worker进程的数量,这里设置成于cpu相同 worker_processes 2; ##设置错误日志的输出级别为warn,减轻日志输出的压力 error_log logs/error.log warn; ##设置pid文件路径 pid logs/nginx.pid; events { ##使用epoll模型,linux下建议使用epoll use epoll; ##每个worker线城所能接受的最大连接数 worker_connections 10240; ##设置网路连接序列化,防止惊群现象发生,默认为on。 ##如果当前机器的worker线城很多的话可以选择置为off,但如果只有几个work线程的话建议为on,当前设为on。 accept_mutex on; } ##疫苗预约集群地址,这里为疫苗服务设置了5台机器,因为这里是主打业务。 upstream vaccine-order-cluster{ server 172.17.16.4:8091 max_fails=5 fail_timeout=60s; server 172.17.16.4:8092 max_fails=5 fail_timeout=60s; server 172.17.16.4:8093 max_fails=5 fail_timeout=60s; server 172.17.16.4:8094 max_fails=5 fail_timeout=60s; server 172.17.16.4:8095 max_fails=5 fail_timeout=60s; } http { ##设定mime类型,类型由mime.type文件定义 include mime.types; default_type application/octet-stream; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; ##只提供80端口的监听 server { listen 80; server_name localhost; ##设置编码为utf-8 charset utf-8; ##开启访问日志,用来更好的统计用户访问数据 access_log logs/host.access.log main; ##匹配疫苗预约订单服务相关请求 location ^~/vaccine/order { proxy_pass https://vaccine-order-cluster; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } location / { deny all; } } }
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









