三连后观看,养成好习惯! 好久不更新博客了,有小伙伴问我,怎么不更新啦,是不是退博了?! (1) Sqlserver目前国内无成熟CDC解决方案,开源生态较mysql等数据库较差。 优点: 缺点: 主要的思路是使用kafka connect,Connector目前有 Debezium和Confluent提供两个开源的sqlserver连接器。 Confluent sqlserver connector: Debezium提供了多种连接器,支持mysql,MongoDB,PostgreSQL,SQL Server,Oracle ,Db2 ,Cassandra 架构图: 缺点: Kafka connect的几个重要的概念包括:connectors、tasks、workers和converters。 Connectors-在kafka connect中,connector决定了数据应该从哪里复制过来以及数据应该写入到哪里去,一个connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业,connector plugin是jar文件,实现了kafka定义的一些接口来完成特定的任务。 Tasks- task是kafka connect数据模型的主角,每一个connector都会协调一系列的task去执行任务,connector可以把一项工作分割成许多的task,然后再把task分发到各个worker中去执行(分布式模式下),task不自己保存自己的状态信息,而是交给特定的kafka 主题去保存(config.storage.topic 和status.storage.topic)。在分布式模式下有一个概念叫做任务再平衡(Task Rebalancing),当一个connector第一次提交到集群时,所有的worker都会做一个task rebalance从而保证每一个worker都运行了差不多数量的工作,而不是所有的工作压力都集中在某个worker进程中,而当某个进程挂了之后也会执行task rebalance。 task rebalance: Workers-connectors和tasks都是逻辑工作单位,必须安排在进程中执行,而在kafka connect中,这些进程就是workers,分别有两种worker:standalone和distributed。这里不对standalone进行介绍,具体的可以查看官方文档。它提供了可扩展性以及自动容错的功能,你可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行connector和task,如果你新加了一个worker或者挂了一个worker,其他的worker会检测到然后在重新分配connector和task。 Converters- converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那么jdbc connector可以写avro格式的数据到kafka,当然,hdfs connector也可以从kafka中读出avro格式的数据。 Kafka connect的工作模式分为两种,分别是standalone模式和distributed模式。 Standalone一般用于测试环境,下面演示一个小的测试demo 在启动kafkaconnect的distributed模式之前,首先需要创建三个主题,这三个主题的配置分别对应connect-distributed.properties文件中config.storage.topic(default connect-configs)、offset.storage.topic (default connect-offsets) 、status.storage.topic (default connect-status)的配置。 如显示正常,此时kafka connect集群就启动成功了! 在connect-distributed.properties的配置文件中,其实并没有配置了你的connector的信息,因为在distributed模式下,启动不需要传递connector的参数,而是通过REST API来对kafka connect进行管理。 参数说明: 你知道的越多,你的头就会越秃 原创不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见! 本博客仅发布于ImapBox—一个帅到不能再帅的人 Mr_kidBK。转载请标明出处。 !!转发!!!么么哒!
点个关注吧,球球啦!
没有没有,只是前段时间要换工作,需要花时间复习什么的,加上找房子之类的事情耗费了不少时间,2020年真的是太难了。。。

不过好在一切都顺利,一番周折也是顺理找到了自己比较满意的工作。
后面我考虑会更新一波面经,大数据方面的,腾讯、华为等大厂亲身经历(cantongjiaoxun),有需要的小伙伴点个关注吧!
目录
一、问题难点、痛点
(2) Sqlserver无binlog日志概念,因此不能使用maxwell和canal等类似解决方案。
(3) 使用sqoop或dadaX等同步工具实时性、稳定性较差,需要配合调度框架每隔一段时间进行脚本调度,如遇到运行失败等问题,需要手动或者使用监控脚本进行二次调度,使用成本较大。二、解决方案
(一)分段同步
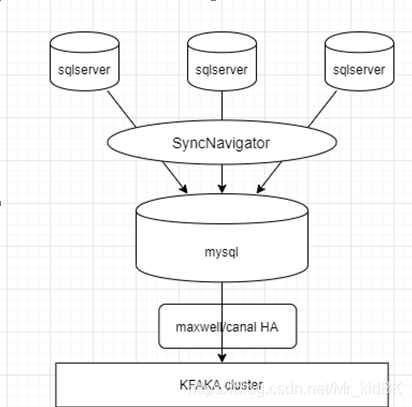
使用SyncNavigator将多个sqlserver先同步到mysql,然后使用canal或maxwell进行监控mysql binlog日志进行增量同步。
mysql到kafka 使用canal和maxwell进行CDC同步技术较为成熟,开源生态较好,市面使用情况较多。
需要sqlserver使用触发器,数据量大的情况下可能会对后端业务场景响应速度产生影响。(二)使用connector
使用Change Tarcking获取数据变更,更轻量级,但是官方声明由于某种原因这个连接器已经不再提供维护支持了,官方推荐使用Debezium。

Debezium sqlserver connector:
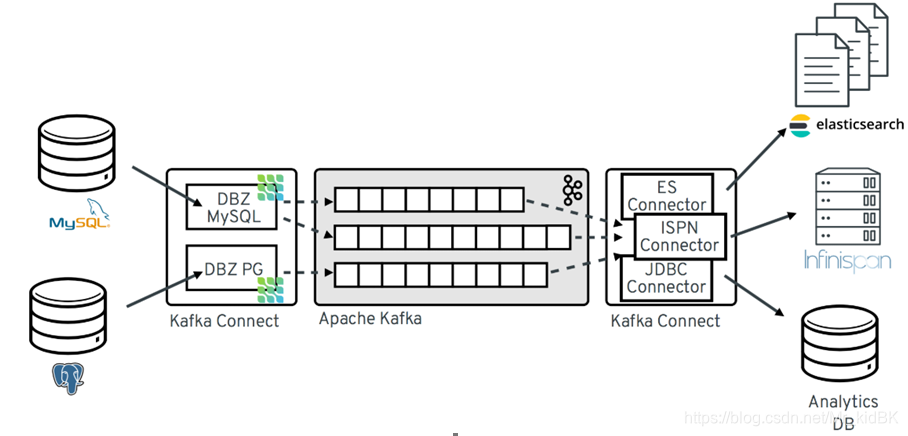
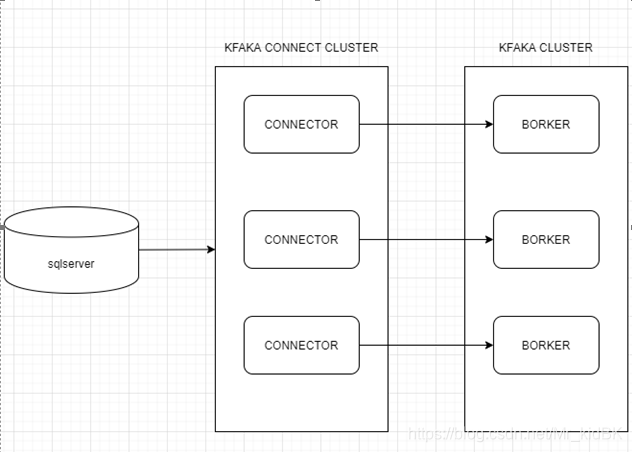
优点:
轻量,使用CDC方式获取sqlserver更改的数据,不会对业务数据库造成影响。
使用分布式架构,并且自带容错机制。
需要sqlserver版本支持Change Data Capture。
经测试,08版本(企业版)以上都支持CDC三、Kafka Connect
3.1、Kafka connect核心概念
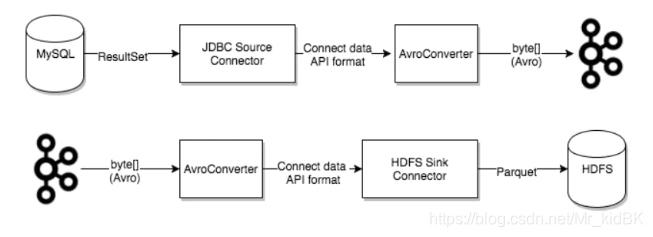
3.2、Kafka connect启动
3.2.1 Standalone
(1) 配置connector.properties
name=local-file-source connector.class=FileStreamSource tasks.max=1 file= /opt/module/kafka_2.11-2.4.0/test.txt topic=connect-test (2) 编写test测试文件
[root@hadoop102 kafka_2.11-2.4.0]# vim test.txt hahaha kafka 123 hello aaa (3) 启动:
bin/connect-standalone.sh config/connect-standalone.properties config/connector.properties (4) 启动kafka connect
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties (5) 查看推送到topic connect-test 的数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic connect-test --from-beginning 3.2.2 Distributed
(1) 创建topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --topic connect-offsets --replication-factor 2 --partitions 3 bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --topic connect-configs --replication-factor 2 --partitions 1 bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --topic connect-status --replication-factor 2 --partitions 3 (2) 将需要的connector jar包解压到connectors文件夹下
[root@hadoop102 kafka_2.11-2.4.0]# mkdir connectors [root@hadoop102 connectors]# pwd /opt/module/kafka_2.11-2.4.0/connectors [root@hadoop102 soft]# tar -zxvf debezium-connector-sqlserver-1.1.2.Final-plugin.tar.gz -C /opt/module/kafka_2.11-2.4.0/connectors/ #展示 [root@hadoop102 connectors]# tree . └── debezium-connector-sqlserver ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-api-1.1.2.Final.jar ├── debezium-connector-sqlserver-1.1.2.Final.jar ├── debezium-core-1.1.2.Final.jar ├── LICENSE-3rd-PARTIES.txt ├── LICENSE.txt ├── mssql-jdbc-7.2.2.jre8.jar └── README.md (3) 编写connect-distributed.properties配置文件
[root@hadoop102 config]# vim connect-distributed.properties # kafka集群地址 bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 # Connector集群的名称,同一集群内的Connector需要保持此group.id一致 group.id=connect-cluster # 存储到kafka的数据格式 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false # 内部转换器的格式,针对offsets、config和status,一般不需要修改 internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false # 用于保存offsets的topic,应该有多个partitions,并且拥有副本(replication) # Kafka Connect会自动创建这个topic,但是你可以根据需要自行创建 offset.storage.topic=connect-offsets offset.storage.replication.factor=2 offset.storage.partitions=3 # 保存connector和task的配置,应该只有1个partition,并且有多个副本 config.storage.topic=connect-configs config.storage.replication.factor=2 # 用于保存状态,可以拥有多个partition和replication status.storage.topic=connect-status status.storage.replication.factor=2 status.storage.partitions=3 # Flush much faster than normal, which is useful for testing/debugging offset.flush.interval.ms=10000 # RESET主机名,默认为本机 #rest.host.name= # REST端口号 rest.port=18083 # The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers. #rest.advertised.host.name= #rest.advertised.port= # 保存connectors的路径 #plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors, plugin.path=/opt/module/kafka_2.11-2.4.0/connectors (3) 分发配置文件 [root@hadoop102 config]# xsync connect-distributed.properties (4) 启动kafka coneect集群 [root@hadoop102 kafka_2.11-2.4.0]# xcall /opt/module/kafka_2.11-2.4.0/bin/connect-distributed.sh -daemon /opt/module/kafka_2.11-2.4.0/config/connect-distributed.properties [root@hadoop102 kafka_2.11-2.4.0]# xcall jps 要执行的命令是jps ---------------------hadoop101----------------- 3984 Jps 3938 ConnectDistributed 2713 QuorumPeerMain 3434 Kafka ---------------------hadoop102----------------- 4297 Jps 2909 QuorumPeerMain 4237 ConnectDistributed 3711 Kafka ---------------------hadoop103----------------- 3960 ConnectDistributed 2718 QuorumPeerMain 3454 Kafka 4014 Jps (5) 测试
在浏览器输入:https://192.168.176.102:18083/ {"version": "2.4.0","commit": "77a89fcf8d7fa018","kafka_cluster_id": "q4M_m7GZRQuX7k-0KHmvgQ"} 或者 [root@hadoop102 ~]# wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm [root@hadoop102 ~]# rpm -ivh epel-release-latest-7.noarch.rpm [root@hadoop102 ~]# yum repolist [root@hadoop102 ~]# yum install -y jq [root@hadoop102 ~]# curl -s 192.168.176.102:18083/ | jq { "version": "2.4.0", "commit": "77a89fcf8d7fa018", "kafka_cluster_id": "q4M_m7GZRQuX7k-0KHmvgQ" } 3.2.3 REST API
GET /connectors – 返回所有正在运行的connector名。 POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。 GET /connectors/{name} – 获取指定connetor的信息。 GET /connectors/{name}/config – 获取指定connector的配置信息。 PUT /connectors/{name}/config – 更新指定connector的配置信息。 GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。 GET /connectors/{name}/tasks – 获取指定connector正在运行的task。 GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息。 PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。 PUT /connectors/{name}/resume – 恢复一个被暂停的connector。 POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用 POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。 DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。 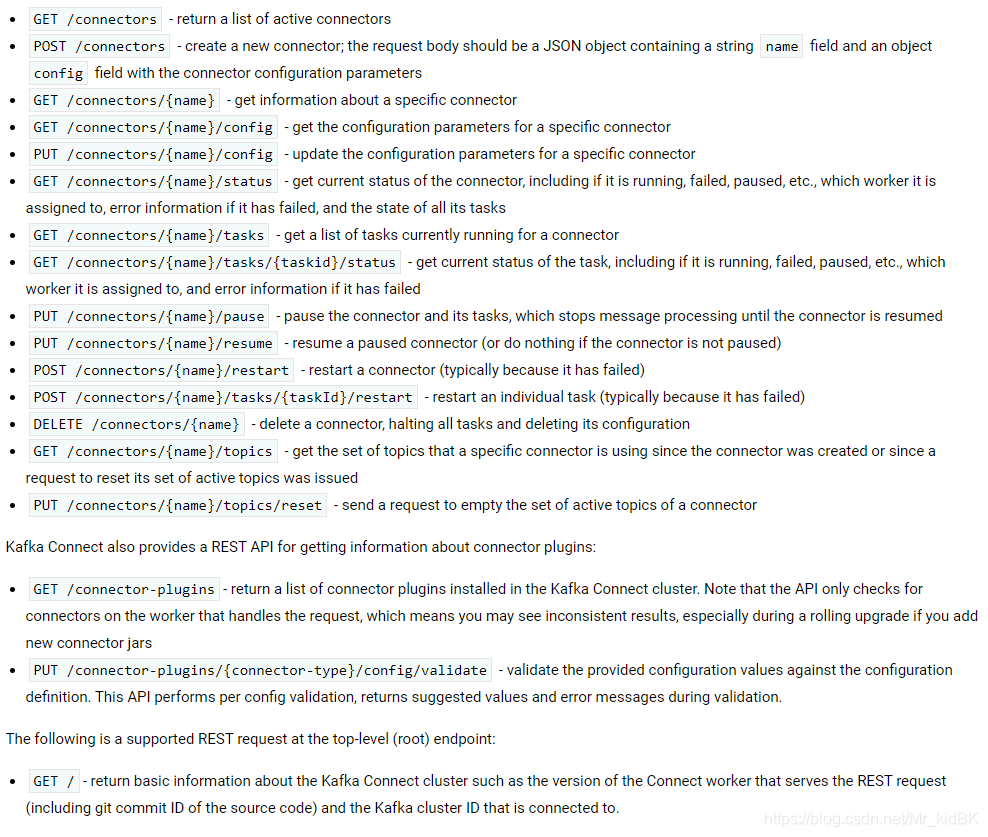
官方文档地址:
https://kafka.apache.org/documentation/#connect
https://docs.confluent.io/current/connect
https://debezium.io/documentation/reference/1.1/connectors/sqlserver.html#sqlserver-property-heartbeat-topics-prefix
推荐使用postman测试。(1) 查看已经部署的Connectors
GET:https://192.168.176.102:18083/connectors [ "inventory-connector3", "inventory-connector2", "inventory-connector" ] 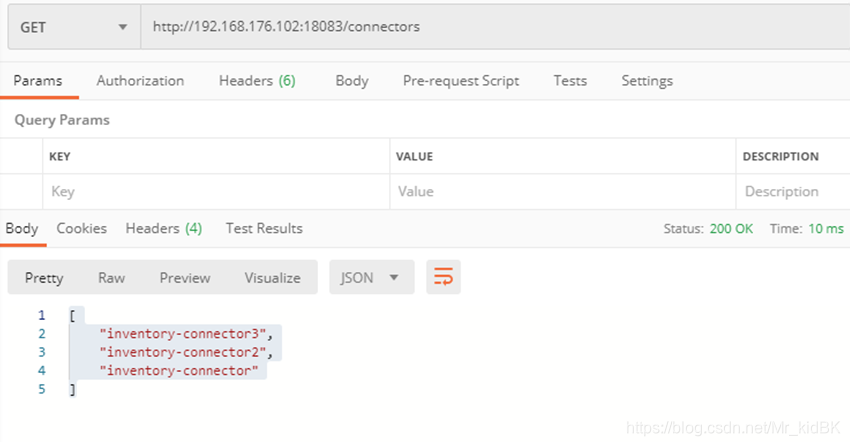
(2) 查看当前运行的Connector详细信息
GET:https://192.168.176.102:18083/connectors/{connector_name} { "name": "connector_name", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.user": " username ", "database.dbname": "TestDB2", "database.hostname": " hostname ", "database.password": " password ", "database.history.kafka.bootstrap.servers": "hadoop101:9092,hadoop102:9092,hadoop103:9092", "database.history.kafka.topic": "dbhistory.fullfillment", "name": "inventory-connector3", "database.server.name": "fullfillment", "database.port": "1433" }, "tasks": [ { "connector": "inventory-connector3", "task": 0 } ], "type": "source" } (3) 查询目前运行的tasks信息
GET:https://192.168.176.102:18083/connectors/{connector_name}/tasks [ { "id": { "connector": " connector_name ", "task": 0 }, "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.user": " username ", "database.dbname": "TestDB2", "task.class": "io.debezium.connector.sqlserver.SqlServerConnectorTask", "database.hostname": " hostname ", "database.password": " password ", "database.history.kafka.bootstrap.servers": "hadoop101:9092,hadoop102:9092,hadoop103:9092", "database.history.kafka.topic": "dbhistory.fullfillment", "name": "inventory-connector3", "database.server.name": "fullfillment", "database.port": "1433" } } ] (4) 增加connector(下面演示的是debezium-connector-sqlserver)
POST:https://192.168.176.102:18083/connectors Headers:Content-Type: application/json Body:{ "name": " connector_name", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.hostname": " hostname ", "database.port": "1433", "database.user": "username", "database.password": " password ", "database.dbname": "TestDB2", "database.server.name": "fullfillment", "database.history.kafka.bootstrap.servers": "hadoop101:9092,hadoop102:9092,hadoop103:9092", "database.history.kafka.topic": "dbhistory.fullfillment" } }
Property
Default
Description
database.server.name
逻辑名,只能使用字母数字下划线,用作kafka topic的名称前缀
database.history.kafka.topic
连接器自己维护的一个管理DDL语句的topic,由debezium内部管理维护
tasks.max
1
可以被connector创建最大task数量,sqlserver一般是一个task,因此使用默认值即可
table.whitelist
table白名单,使用逗号分隔表名,默认将监控库中所有非系统表,不能与table黑名单一起使用
table.blacklist
Table黑名单,使用逗号分隔表名,不能与table白名单一起使用
tombstones.on.delete
控制是否应在删除事件之后生成逻辑删除事件。
poll.interval.ms
1000
max.queue.size
8192
max.batch.size
2048
每批次最大拉取事件个数的大小
heartbeat.interval.ms
0
心跳间隔时间,可以使用监控器对其监控,默认0未开启
heartbeat.topics.prefix
__debezium-heartbeat
心跳发送的kafka topic
database.server.timezone
时区设置,支持时间偏移量 “+08:00” 或asia/shanghai asia/chongqing
四、sqlserver CDC
(1) 对数据库启用CDC
USE DB_NAME GO EXEC sys.sp_cdc_enable_db GO (2) 对表启用CDC
USE DB_NAME GO EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'TABLE_NAME', @role_name = NULL, @supports_net_changes = 1 GO 点关注,不迷路!
点个赞再走,球球啦!
https://blog.csdn.net/Mr_kidBK
!!转发!!!么么哒!
!!转发!!!么么哒!
!!转发!!!么么哒!
!!转发!!!么么哒!
————————————————

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









