hello大家好,好久不见!今天我们的《教妹学数据库系统》来学习数据库系统中的查询优化。教妹学数据库,没见过这么酷炫的标题吧?“语不惊人死不休”,没错,标题就是这么酷炫。 我的妹妹小埋18岁,校园中女神一般的存在,成绩优异体育万能,个性温柔正直善良。然而,只有我知道,众人眼中光芒万丈的小埋,在过去是一个披着仓鼠斗篷,满地打滚,除了吃就是睡和玩的超级宅女。而这一切的转变,是从那一天晚上开始的。 从此之后,小埋经常让我帮她辅导功课。今天她想了解数据库系统中的查询优化。本篇教程通过我与小埋的对话的方式来谈一谈查询优化。 如果两个关系代数表达式在任意数据库实例上的结果都相同,则这两个关系代数表达式等价(equivalent) 将关系代数表达式树 (expression tree) 中的选择操作向下推 (push down) 通常可以提高查询执行效率 选择下推可以尽早过滤掉与结果无关的元组 选择度:满足条件的元组所占的比例 尽早过滤掉更多与结果无关的元组 将复杂的选择条件进行分解,然后再进行选择下推 改写低效的选择条件改写前: 改写后: 去掉不必要的选择条件 改写前: 检查无法满足的选择条件 合并选择条件 改写前: 改写后: 在选择操作可以向表达式树的多个分支下推的情况下,需要考虑到底向哪个分支下推 将关系代数表达式树中的投影操作向下推(pushdown)一般可以提高查询执行效率 有些情况下,投影操作下推会浪费查询优化的机会投影操作的结果上没有索引 去除不必要的投影 假设所有学生选过课 查询计划的代价用查询计划执行过程中产生的中间结果的元组数来度量。 DBMS根据关系代数操作的输入关系的大小(元组数)来估计操作结果的大小(元组数) 准确 易计算 逻辑一致性(logicallyconsistent) 逻辑一致性 单调性:一个操作的输入越大,操作结果大小的估计值越大 顺序无关:在多个关系上执行同一种满足交换律和结合律的操作时(如on,×,∪,∩),最终结果大小的估计值与操作的执行顺序无关 系统目录(systemcatalog)中记录着一些与估计操作结果大小有关的统计信息 T( R ): 关系R的元组数 V(R,A): 关系R的属性集A的不同值的个数 属性值均匀分布假设,每个属性的取值均服从均匀分布 属性独立假设,关系的所有属性相互独立 手动收集统计信息 笛卡尔积结果大小的估计 投影结果大小的估计 选择结果大小的估计 后两个有区别吗 考虑两个关系R和S的自然连接 R on S 对于连接属性K,如果V(R,K) ≤ V(S,K),则R的K属性值集合是S的K属性值集合的子集 对于R中任意非连接属性A,有V(R on S,A) = V(R,A) 自然连接没有相同属性,退化成笛卡尔连接 无论是按不同顺序进行二路连接(2-wayjoin),还是进行1次多路连接(multi-wayjoin),上述方法得到的结果大小估计值相同 属性值各区间的宽度不同 各区间内属性值的出现次数基本相同 不使用直方图: T(R on S)=245×245/100=600 如果某种等价变换能降低查询计划的代价,则对查询计划执行该变换 尽管连接操作满足交换律,但在查询计划中连接操作的输入关系具有不同的作用 在R on S中,R是左关系(left relation),S是右关系(right relation) 如果使用一趟连接(one-pass join),则左关系是构建关系(build relation),右关系是探测关系(proberelation) 如果使用嵌套循环连接(nested-loop join),则左关系是外关系(outer relation),右关系是内关系(inner relation) 如果使用索引连接(index-based join),则右关系是有索引的关系(indexed relation) 一组关系上的连接操作的执行顺序可以用连接树(join tree)来表示 左深连接树(left-deep join tree):只有一个关系是左关系(left relation),其他关系都是右关系(right relation) 右深连接树(right-deep join tree):只有一个关系是右关系,其他关系都是左关系(left relation) 浓密树(bushy tree):除左深连接树和右深连接树以外的其他连接树 如果下列查询计划全部使用一趟连接(one-pass join)算法,那么在流水线查询执行模型(piplining model)下,左深连接树查询计划在任何时刻对内存的需求都比其他查询计划更低。 代价是0,表示没有中间结果 适用条件 适用条件: 适用条件: 多个关系在相同连接属性上做多路连接也适合使用排序归并连接,如R(a,b) on S(a,c) on T(a,d) 一趟连接(One-PassJoin) 内存缓冲池的可用页数影响着执行模型的选择 咱们玩归玩,闹归闹,别拿学习开玩笑。 本篇介绍了查询优化:包括逻辑查询优化比如选择下推等,和物理查询优化比如基于索引的选择等。学习时要注重抓住查询优化的原理,牢记查询优化的方法。
逻辑查询优化
等价关系代数表达式
等价变换规则

有关选择的等价变换规则

 、
、选择下推
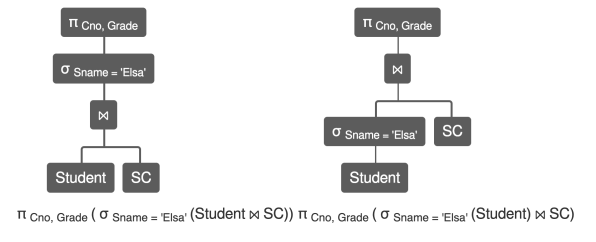
选择度(selectivity)最高的选择操作最先做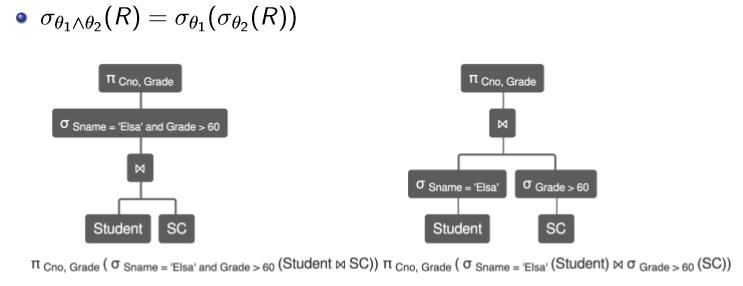
选择条件的改写
X=Y AND X=3X=3 AND X=3SELECT * FROM R WHERE 1=1;改写后:SELECT * FROM R;SELECT * FROM R WHERE 1=0; SELECT*FROMR WHEREABETWEEN1AND100 ORABETWEEN50AND150; SELECT*FROMR WHEREABETWEEN1AND150;
有关投影的等价变换规则


投影下推
ΠSno,Sname(Student)使后续的选择和连接操作无法利用该索引
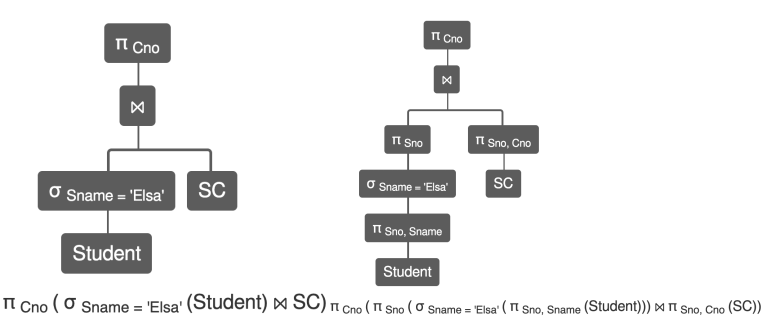
查询改写

去除不必要的连接

逻辑查询计划代价估计
查询计划代价的度量指标

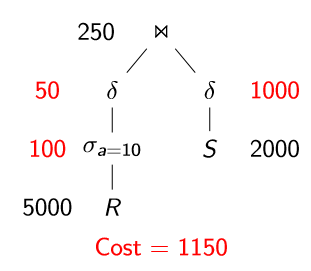
操作的结果大小估计
估计操作结果大小所需的统计信息
Postgres/SQLite:ANALYZE Oracle/MySQL:ANALYZETABLE SQLServer:UPDATESTATISTICS DB2:RUNSTATS T(R×S)=T(R)T(S) T(ΠL(R))=T(R)(不带去重的投影) T(ΠL(R))=V(R,L)(带去重的投影) 

二路自然连接结果大小的估计

情况2: R和S有2个连接属性X和Y
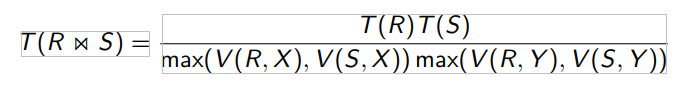
自然连接结果大小估计的逻辑一致性

集合操作结果大小的估计

去重结果大小的估计

直方图
等宽直方图
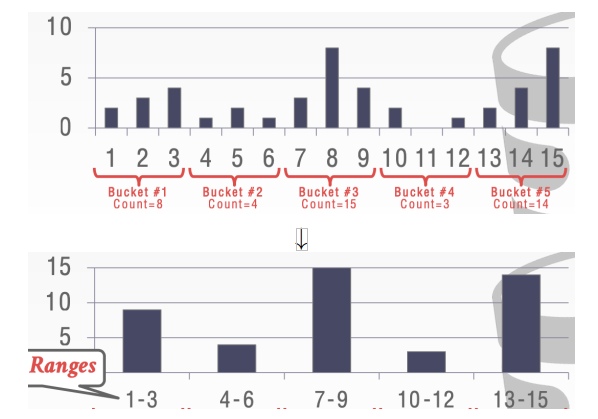
等高直方图
基于直方图估计连接结果大小
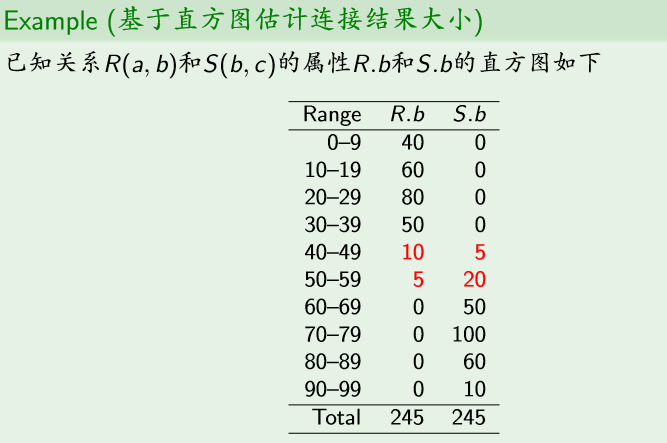
使用直方图: T(R on S)=10×5/10+5×20/10=15逻辑查询计划的启发式优化方法

连接顺序的优化
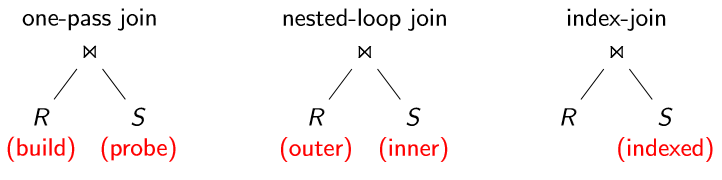
连接树(JoinTrees)
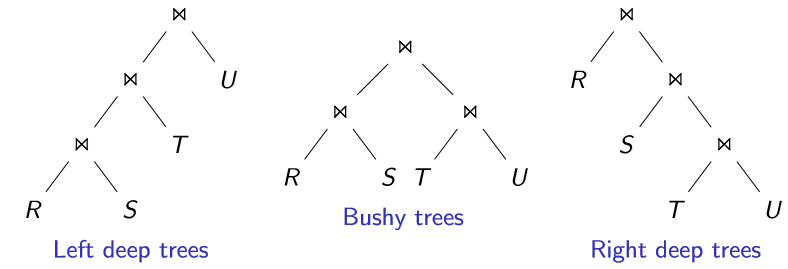
为什么左深连接树查询计划更高效?
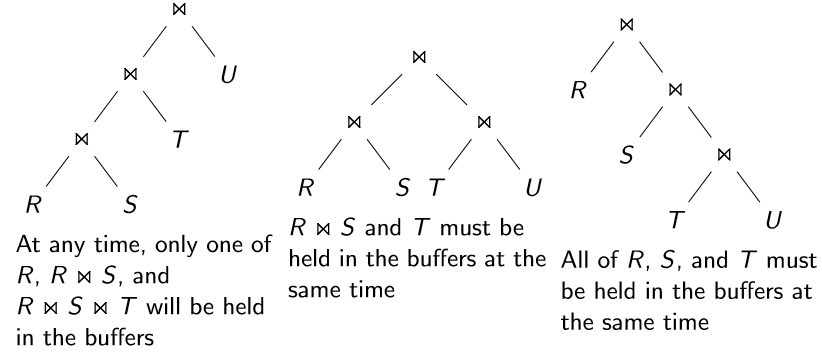
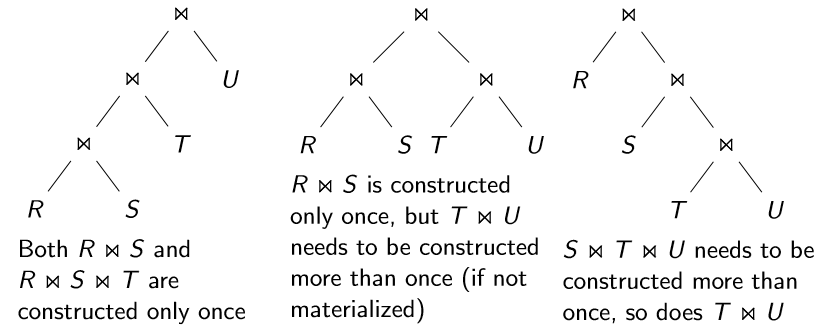
如果下列查询计划全部使用嵌套循环连接(nested-loopjoin)算法,那么在流水线查询执行模型(pipliningmodel)下,左深连接树查询计划不需要多次构建中间关系。
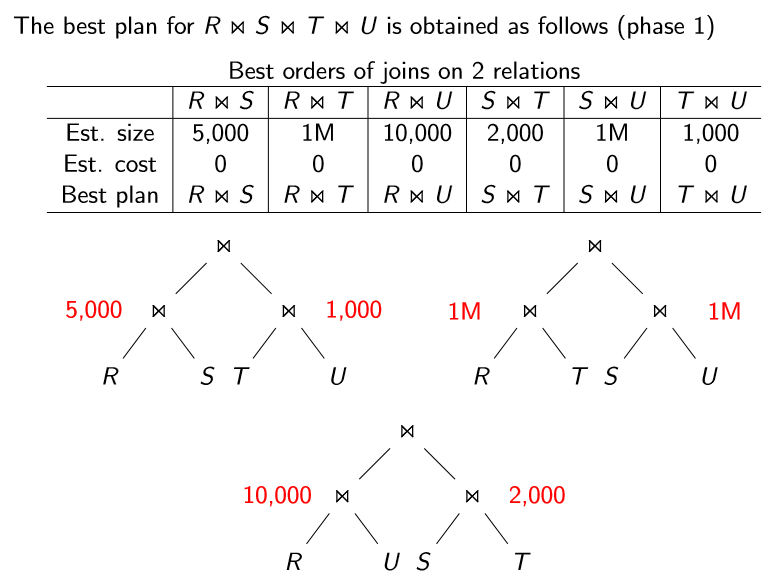
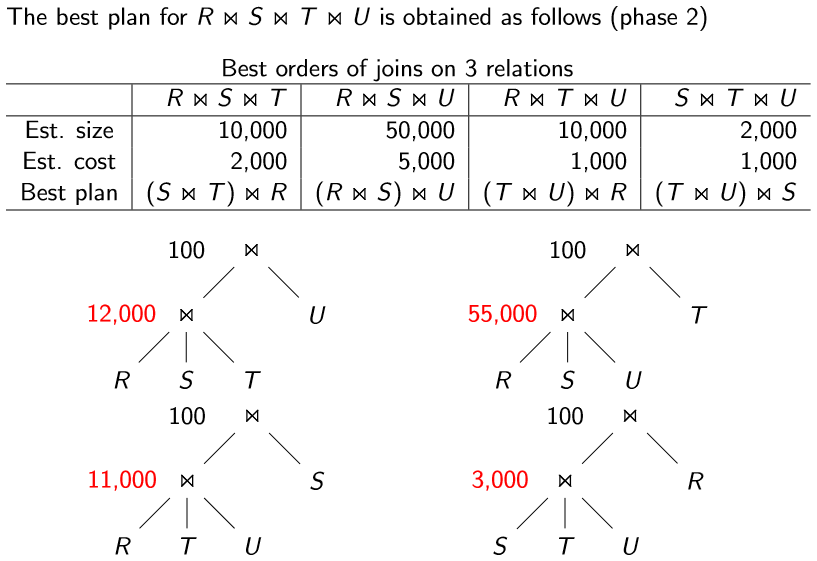
优化连接顺序的动态规划方法


物理查询计划的优化
确定选择操作的执行方法
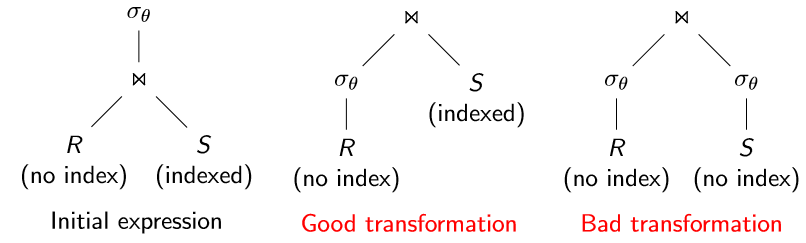
基于索引的选择
确定连接操作的执行方法
索引连接(IndexJoin)
排序归并连接(Sort-MergeJoin)
哈希连接(HashJoin)
嵌套循环连接(Nested-LoopJoin)确定执行模型
总结
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









