—— 有的事情不去尝试,就永远无法探知自我能力的极限将能触碰到何处。 —— 有的事情不去尝试,也永远无法知悉“糟粕污秽”究竟能恶心到什么境地。 —— 显然PySpark不能是前者【Facepalm】 自从劲松加入了小米项目的团队后,MARS数据这个烂摊子就全落在笔者一个打杂的身上,幸好有提前做好和PySpark相关的功课,不至于接手的时候慌得手忙脚乱,上手两三天后越发地被PySpark这种生成任何数据表的结果只要一行代码就能写出来的简洁、优雅所吸引,感叹SQL确实是一门精妙的语言,实在是极大地满足了我这种代码强迫症患者的欲求。 直到昨天被两个突如其来而又令人费解的BUG冲昏了头脑,才意识到自己的弱小和世道的险恶。 没错就是标题中的三个笔者自定义命名的BUG,也许确实是我太菜了,连这种问题都要拿出来“显摆”,但是这三个问题真的是把把我坑了很长很长的时间,不把他们挂出来实在是吾心难安。 手机关机,拒绝加班,万事与我无关。今晚且让笔者为看官娓娓道来~ 生成结果表的函数运行不报错,但是我忽然发现这个函数返回的DataFrame类型的变量df无法写入到外部文件,但是在运行df.count()命令与df.dtypes命令都可以正确的返回到数据表的大小与各个字段的数据类型。进而发现在运行df.show(),display(df)时也会报错,这已经很让我费解了,更离谱的是报错竟然是这样的👇 笔者表示这个报错究竟说了些什么并不需要,重要的是这个形状很有美感,而且实际报错差不多有十几个这样的锯齿状的图形,实在是令人回味无穷😂 笔者的第一感是,既然函数正常返回了,df的一些属性和方法也可以正常调用,说明本身函数代码逻辑没有问题,因为是在Azure平台上调用的MARS内部数据,也许是无法写入到外部文件以及无法查看数据情况也许是数据权限的问题。我怎么也想不到可以正常返回的代码竟然也可以存在影响编译的逻辑错误。直到后来经前辈指点才知道这是发生了一种“循环连接BUG”。 引用https://www.pianshen.com/article/7826345270/这篇博客的说法,如果连接是如下的一种逻辑👇 从一张行为表中,抽取有特点行为的用户 将这部分用户id拿到之后保存 然后再将这部分用户id关联回行为表,获得这部分用户的所有行为 就会产生循环连接的BUG,本质是因为PySpark在多重连接中会造成连接字段的冗余。 选取报错的一部分查看,可以看到返回的问题是👇 然而这个问题往往很难避免,实践中常常会遇到需要先从主表中抽取一部分特定用户的信息(如高消费用户,使用高消费用户表与主表连接得到这些用户的属性),然后根据用户的一些其他属性,如所在地区,去筛选出这些高消费用户所在地区的所有用户出来。这可以说是一种极其普遍使用的逻辑,但是就是会产生这么离谱的BUG。 笔者的看法是,因为PySpark特殊的后处理机制,即与SQL语句一样,每个SQL语句必然产生一个表,反过来任何表的生成都只需要一句SQL语句,无论多么复杂PySpark代码逻辑生成的数据表,在实际编译时都只会转换为一句话,并只会在需要将数据表“实例化”(我将写入以及展示数据表这种操作称为实例化,这么命名是因为在实例化前函数返回的结果都是抽象的表,只有在实例化时代码的编译结果才会实际运行)操作时才会实际运行编译结果,这就是“循环连接BUG”产生的根源。 在Java或者Scala版本的spark语言中,似乎可以通过一些更合规的写法来避免这种错误(如在进行表的连接时使用参数on来指明需要匹配的字段而非是SQL语法的df1.uid==df2.uid),但是似乎在python版本的spark中这种问题仍然存在,时不时地会出来恶心你。 如果说上面的循环连接BUG还是可以理解的,但是接下来这个正则替换BUG几乎就是个未解之谜了👇 需求是要将calculate_week字段中表示P的部分,如果是P11,P12这种两位数的P,则保留之,但如果是P1~P9这些一位数的P则需要补充为P01~P09的格式(看起来非常容易,实际上也非常容易)。笔者在实际运行PySpark代码前还特地在notebook里用re库测试了一下👇 显然re库的测试结果完全是可以正确替换的,但是我依次测试了以下四种情况👇 首先我们继续生成一个测试DataFrame👇 依次使用pyspark.sql.functions模块下的regexp_replace函数来执行正则替换👇 结果就是这个样子👇 目前我已经被迫使用udf写很硬的替换逻辑,实在是不能理解为什么PySpark里竟然有这么恶心的BUG,幸好我传数据前扫了一遍表,发现都是2020P01的结果,感觉非常奇怪,然后测试了一下才发现这个狗血的问题。初步分析认为是regexp_replace函数在处理捕获元引用时出现问题(但是在SQL中的同名函数REGEXP_REPLACE函数是可以做到捕获元引用),因为在测试不用捕获元的正则替换时是显然不会出错的,感觉可能是PySpark的正则编译出了一些问题,显然是捕获到(d)了,但是无法识别1的引用,我也尝试了$1之类的引用写法,统统都不能识别。这个问题也请教了前辈,也没有给出很好的解释,他们认为PySpark确实有不少坑,还是建议我暂时先用udf处理掉,再从长计议。 相对来说”正则替换BUG“到底还是比较容易修正的,而最后一个我要说的“DataFrame拼接BUG”是真的把我恶心到了极点。我认为这个问题可能是最恶心也最离谱的一个BUG了,在Pandas中如果我们需要拼接两个columns完全一致的DataFrame时,简单concat即可👇 即便我恶意颠倒columns的顺序,也不妨碍实际结果的正确性👇 然后我就被PySpark狠狠的恶心了一通👇 这个union的BUG的恶心之处在于如果事先没有这个知识储备,代码逻辑自然不可能抛出异常,因此如果没有及时靠肉眼发现数据中的字段错乱,很可能造成极其严重的后果。而且这种BUG其实很常见,比如首先我用一个表同样带有uid和uname字段的表来和df1_sp进行内连接(on=”uid”),再用同样的表与df1_sp进行内连接(on=”uname”),那么两个结果的uid和uname在columns中的位置就会发生变化,从而造成拼接后的错误,这是极其难以察觉的。不仅如此,即便你侥幸靠肉眼发现了字段错乱,如何定位是哪个union的地方出现的问题也是非常困难的(如果想要断点debug,由于PySpark的后处理性值,效率是极其低下的,因为每个断点处都需要从头运行一遍)。 那么怎么修正这个BUG呢,目前笔者用了最愚蠢的方法,即手动调整columns的顺序,然而如果columns中的列数极多,比如成百上千列,可以想象这是个多么离谱的修正方法👇 当然df.columns可以返回所有的字段名,但是似乎也是一个很蠢的修正方法,目前不太清楚PySpark是否有其他靠谱点的concat的方法。 总之昨天是真的被搞得焦头烂额。PySpark出错还不能无法设置断点查看变量情况(因为是后处理的缘故,本身执行的代码并不会得到实例化的表,只有到最终实例化时才会实际执行全部的代码逻辑),就只能在notebook里一步一步手动断点调试,每次display还特别费时间,真的是使用体验感极差。果然还是什么样的人用什么样的东西,像我这种菜狗子就只能摸爬滚打一身泥。 总之都是从坑里爬起来才能变得更强,学习,共同进步吧!
序言
1 循环连接BUG
1.1 BUG起因及症状

1.2 BUG产生原因说明
org.apache.spark.sql.AnalysisException: Resolved attribute(s) special_type#5709002,group_name#5708999,group_type#5709001,group_source#5709000,group_id#5708998 missing from shelf_life#5500450,sku_id#5500448,sku_name#5500457,brand_name#5500488,group_source#5708995, pack_type#5500685,segment#5500466,type#5500909,group_name#5708994,special_type#5708997,grou p_type#5708996,group_id#5708993 in operator !Deduplicate [group_id#5708998, group_type#5709001, pack_type#5500685, group_source#5709000, segment#5500466, special_type#5709002, group_name#5708999, brand_name#5500488, shelf_life#5500450, sku_name#5500457, type#5500909, sku_id#5500448]. Attribute(s) with the same name appear in the operation: special_type,group_name,group_type,group_source,group_id. Please check if the right attribute(s) are used.;;
2 正则替换BUG
2.1 BUG起因及症状

2.2 BUG原因分析

F.regexp_replace("calculate_week",r"P(d)W",r"P0(1)W") # 全部变成了P01W F.regexp_replace("calculate_week",r"P(d)W","P0(1)W") # 全部变成了P0W F.regexp_replace("calculate_week","P(d)W",r"P0(1)W") # 全部变成了P01W F.regexp_replace("calculate_week",r"P(d)W",r"P0(1)W") # 全部变成了P0W 

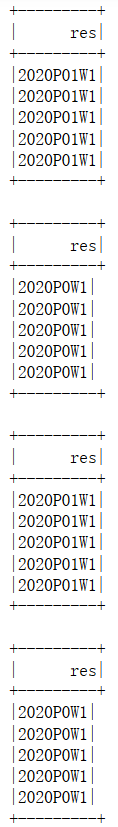
3 DataFrame拼接BUG





4 后记
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 3万+
3万+