类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、AB、O)等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。 序号编码(Ordinal Encoding)、独热编码(One-hot Encoding)、二进制编码(Binary Encoding) 问题 在对数据进行预处理时,应该怎样处理类别型特征? ■ 序号编码 ■ 独热编码 (2)配合特征选择来降低维度。高维度特征会带来几方面的问题。一是在K近邻算法中,高维空间下两点之间的距离很难得到有效的衡量;二是在逻辑回归模型中,参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。 除了本章介绍的编码方法外,有兴趣的读者还可以进一步了解其他的编码方式,比如Helmert Contrast、Sum Contrast、Polynomial Contrast、Backward Difference Contrast等。 另外博主这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图 更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。 Don’t give up, just be yourself, cause life’s too short to be anybody else. 永远都不要放弃做自己,因为人生很短,根本没时间模仿别人
02 类别型特征
场景描述
知识点
分析与解答
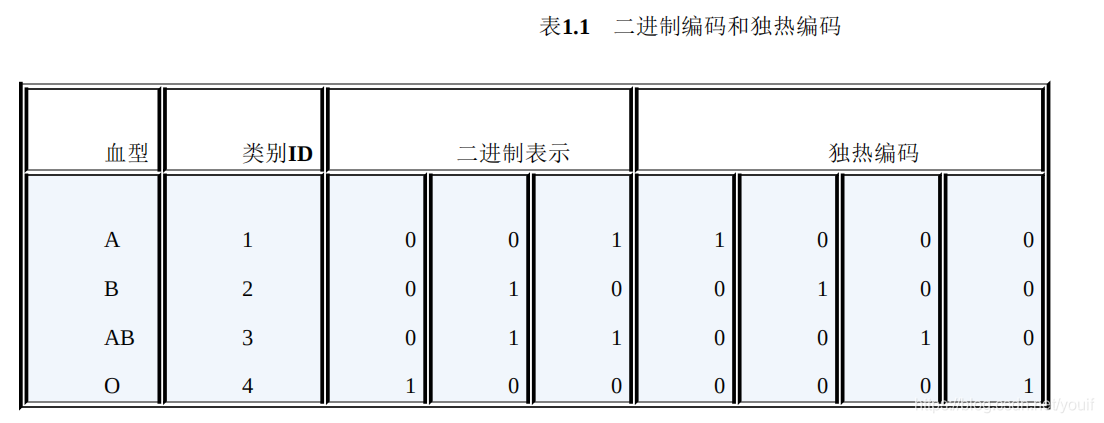
序号编码通常用于处理类别间具有大小关系的数据。例如成绩,可以分为低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
独热编码通常用于处理类别间不具有大小关系的特征。例如血型,一共有4个取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0,1, 0),O型血表示为(0, 0, 0, 1)。对于类别取值较多的情况下使用独热编码需要注意以下问题。
(1)使用稀疏向量来节省空间。在独热编码下,特征向量只有某一维取值为1,其他位置取值均为0。因此可以利用向量的稀疏表示有效地节省空间,并且目25前大部分的算法均接受稀疏向量形式的输入。# * coding:utf-8_*_ # 作者 :XiangLin # 创建时间 :10/06/2020 17:36 # 文件 :onehot.py # IDE :PyCharm import pandas as pd def one_hot_encoder(df, nan_as_category=True): original_columns = list(df.columns) # 属性 categorical_columns = [col for col in df.columns if df[col].dtype == 'object'] df = pd.get_dummies(df, columns=categorical_columns, dummy_na=nan_as_category) # new_columns = [c for c in df.columns if c not in original_columns] return df, new_columns # 测试 data = [['handsome', 'tall', 'Japan'], ['ugly', 'short', 'Japan'], ['handsome', 'middle', 'Chinese']] df = pd.DataFrame(data, columns=['face', 'stature ', ' country ']) df, df_cat = one_hot_encoder(df) print(df) print(df_cat) 
■ 二进制编码
二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。以A、B、AB、O血型为例,表1.1是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为010;以此类推可以得到AB型血和O型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间。

给大家推荐一个Github,上面非常非常多的干货:https://github.com/XiangLinPro/IT_book
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)








