计算机根据用户输入的关键词进行匹配,从已有的数据库中摘录出相关的记录反馈给用户。 线性匹配: 比如,用户在百度文本框中输入, 1、即使在相关结果数量接近3600万时,也能快速得出结果。 2、搜索的结果不仅仅局限于完整的“吃饭睡觉写程序”这一短语,而是将此短语拆分成,“写程序”,“吃饭”,“睡觉”,“程序”等关键字。 3、对拆分后的搜索关键字进行标红显示。 4、即使只满足部分关键字也能查询出来 5、即使输错一两个字母也能查询出来,例如:搜索facebool,能查询到Facebook 问题:上述功能,使用普通的关系型数据库, 搜索能够方便实现吗? 搜索引擎按照功能通常分为垂直搜索和综合搜索。 1. 垂直搜索是指专门针对某一类信息进行搜索。例如:会搜网 主要做商务搜索的,并且提供商务信息。除此之外还有爱看图标网、职友集等。 2. 综合搜索是指对众多信息进行综合性的搜索。例如:百度、谷歌、搜狗、360搜索等。 3. 站内搜索是指对网站内的信息进行的搜索。例如:京东、招聘网站等 搜索引擎目前主流的实现原理:倒排索引技术 倒排索引又叫反向索引(如下图)以字或词为关键字进行索引,表中关键字所对应的记录表项,记录了出现这个字或词的所有文档,每一个表项记录该文档的编号和关键字在该文档中出现的位置情况。 在实际的运用中,我们可以对数据库中原始的数据结构(如:商品表),在业务空闲时,事先生成文档列表(左图)及倒排索引区域(右图)。 用户有查询需求时,先访问倒排索引数据区域(右图),得出文档编号后,通过文档编号即可快速,准确的通过左图找到具体的文档内容。 例如:用户输入“跳槽”关键字,先到右图的索引区查询,找到1,4;再根据id=1和id=4到左图找到两条记录。整个过程走的都是索引,比传统的链式匹配更加快速。 倒排索引技术只是底层原理,我们可以自己写代码实现。也可以使用开源组织写好的方案:lucene。 Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供 Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具 Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。例如:solr和elasticsearch 全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。 lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。 lucene是类似于servlet,而搜索引擎就是tomcat 。 官网下载地址如下: elasticsearch:https://www.elastic.co/cn/downloads/past-releases#elasticsearch kibana:https://www.elastic.co/cn/downloads/past-releases#kibana ik分词器:https://github.com/medcl/elasticsearch-analysis-ik/releases 可以去官网下载特定版本,建议6.8.1版本 注意:kibana、elasticsearch和IK分词器的版本号要一致,否则可能带来兼容性问题 另外,需要 jdk1.8 以上环境。 如果启动未成功,请去查看相关日志 例如:这里cluster-name配置的是 my-es,那么就是指: 如果可以返回以上 json数据就证明配置没有问题 日志文件就生成在bin目录下: 浏览器访问 : https://虚拟机IP:5601 , 如图 点击左边菜单 DevTools , 因为这个 kibana 发送命令的时候都是 restful 风格的, 所以要通过json的方式发送数据请求 在Console中,执行 右边的结果中,status 为 表示es启动正常,并且与kibana连接正常。 kibana 就相当于ElasticSearch 的客户端, 在这里面就可以发送命令, 交给 ElasticSearch 执行, 执行成功之后 ElasticSearch 就会将执行的结果返回给 kibana 在控制台显示, 并且这个工具的提示功能特别强大 第一种方式每次修改词典都要重启搜索服务,不推荐。推荐使用nginx的方式,并发量大,修改内容不需要重启。 Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。 对比关系: 数据结构对比 这两个对象如果放在关系型数据库保存,会被拆成2张表,但是elasticsearch是用一个json来表示一个document 所以他保存到es 要注意的是:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。 表头的含义 索引有了,接下来肯定是添加数据。但是,在添加数据之前必须定义映射。 什么是映射? 只有配置清楚,Elasticsearch才会帮我们进行索引库的创建(不一定) 类型名称:就是前面将的type的概念,类似于数据库中的不同表 字段名:类似于列名,properties下可以指定许多字段。 每个字段可以有很多属性。例如: type:类型,可以是text、long、short、date、integer、object、keyword等 注意:keyword也表示文本,用来保存类似邮箱、地址、状态等,不会分词但是常用。 index:是否索引,默认为true store:是否存储,默认为false analyzer:分词器,这里使用ik分词器: 响应结果: 我们说几个关键的: String类型,又分两种: Numerical:数值类型,分两类 Date:日期类型 elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。 index影响字段的索引情况。 index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。 但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。 是否将数据进行额外存储。 示例: 事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。 测试一下: 自动对判断添加对应的数据类型 再看下索引库的映射关系: stock,saleable,attr都被成功映射了。 如果是字符串类型的数据,会添加两种类型:text + keyword。如上例中的category 和 brand 修改数据分为,整体覆盖和修改某一个字段。 比如,我们把id为2的数据进行修改: 查看结果 : 更新使用POST请求 删除使用DELETE请求,同样,需要根据id进行删除: 首先查询到id, 下面删除默认生成的id数据 查询所有: 根据id查询: 基本查询语法如下: 这里的query代表一个查询对象,里面可以有不同的查询属性 查询结果: 匹配所有 查询出很多数据,不仅包括 某些情况下,我们需要更精确查找,我们希望这个关系变成 按短语查询,不再利用分词技术,直接用短语在原始数据中匹配 可以通过 elasticsearch支持的最大编辑距离是2。 布尔查询又叫组合查询 所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用 from:从那一条开始 size:取多少条 查看百度高亮的原理: pre_tags:前置标签 post_tags:后置标签 默认情况下,elasticsearch在搜索的结果中,会把文档中保存在 如果我们只想获取其中的部分字段,可以添加 聚合可以让我们极其方便的实现对数据的统计、分析。例如: 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。 Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫 桶(bucket) 桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个 Elasticsearch中提供的划分桶的方式有很多: bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量 度量(metrics) 分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为 比较常用的一些度量聚合方式: 首先,我们按照手机的品牌 前面的例子告诉我们每个桶里面的文档数量,这很有用。 但通常,我们的应用需要提供更复杂的文档度量。 例如,每种品牌手机的平均价格是多少? 因此,我们需要告诉Elasticsearch 现在,我们为刚刚的聚合结果添加 求价格平均值的度量: 刚刚的案例中,我们在桶内嵌套度量运算。事实上桶不仅可以嵌套运算, 还可以再嵌套其它桶。也就是说在每个分组中,再分更多组。 比如:我们想统计每个品牌都生产了那些产品,按照 目前市面上有两类客户端 一类是TransportClient 为代表的ES原生客户端,不能执行原生dsl语句必须使用它的Java api方法。 另外一种是以Rest Api为主的missing client,最典型的就是jest。 这种客户端可以直接使用dsl语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。 两种方式各有优劣,但是最近elasticsearch官网,宣布计划在7.0以后的版本中废除TransportClient。以RestClient为主。 所以在官方的RestClient 基础上,进行了简单包装的Jest客户端,就成了首选,而且该客户端也与springboot完美集成。 需要降低springboot依赖的版本, 否则加载不到 查询一个:结果 感谢阅读, 如果文章对你有更好的建议或方案可以留言或交流群:1101584918
了解 百度 , 谷歌 的搜索技术
什么是搜索?
select * from item where title like ’%小米%‘新业务需求
吃饭睡觉写程序,会出现的以下结果:
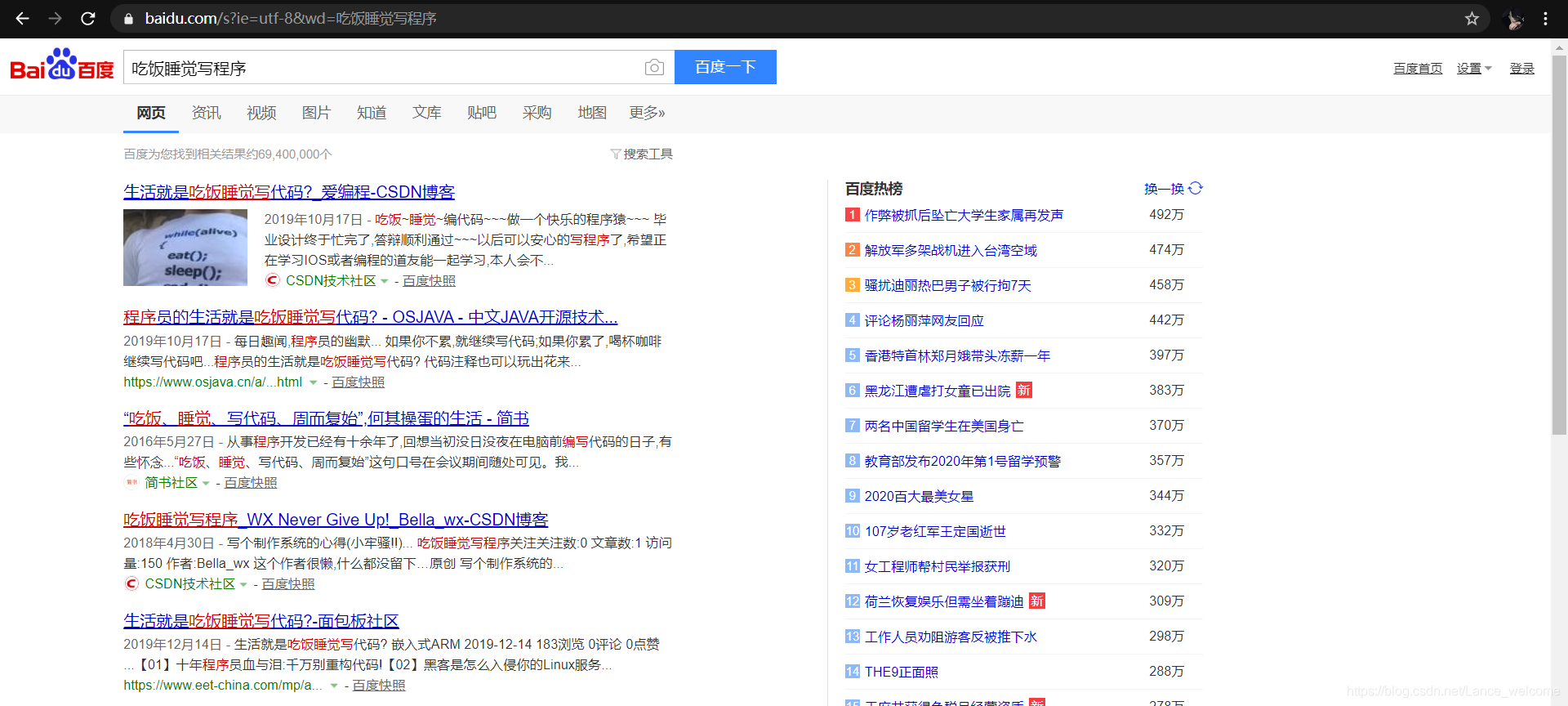
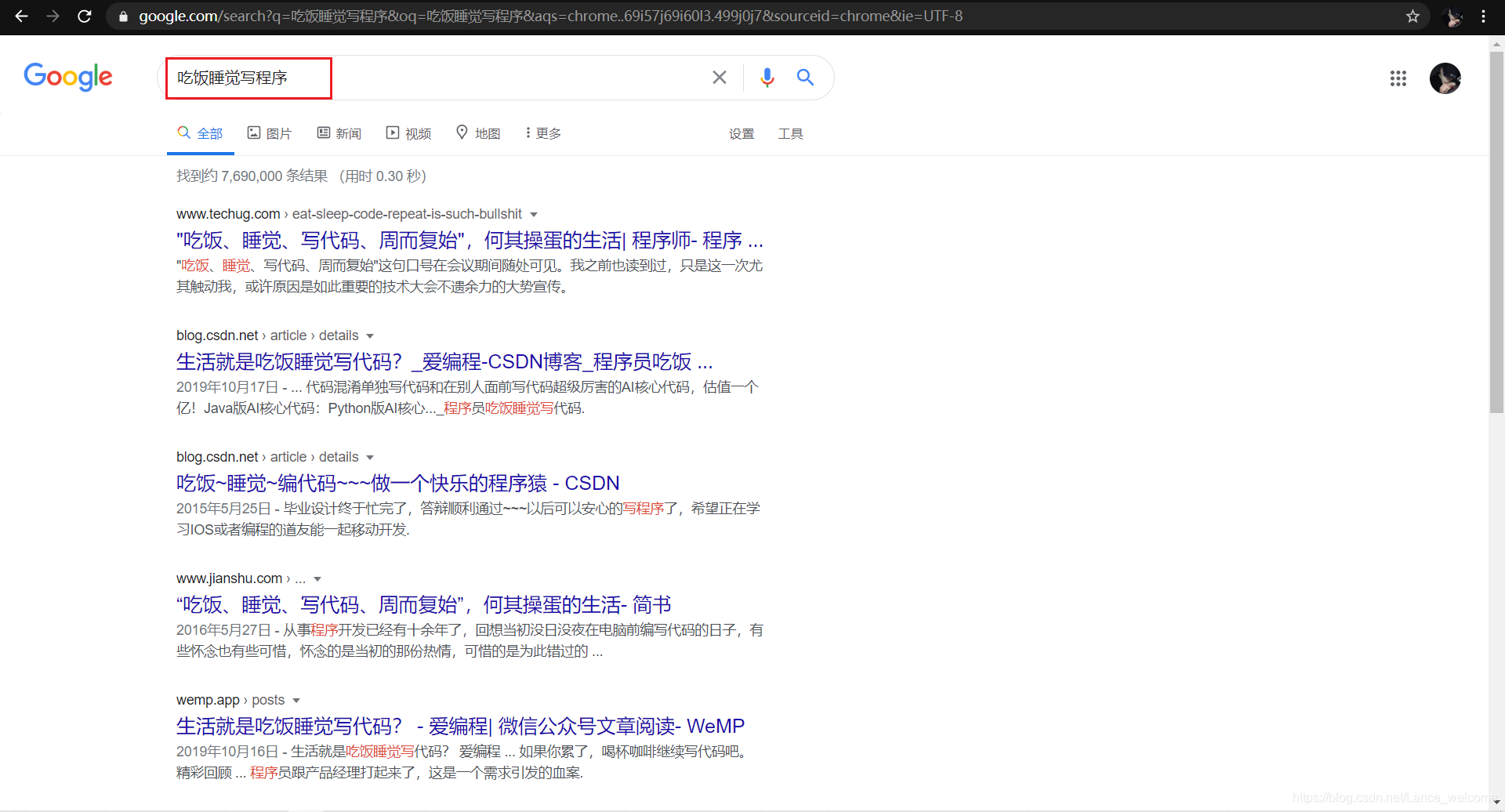
从结果可以看出,百度搜索具备以下明显特点:ElasticSearch搜索引擎

倒排索引

了解lucene
什么是全文检索
倒排索引是全文检索技术的一种实现方式。elasticsearch
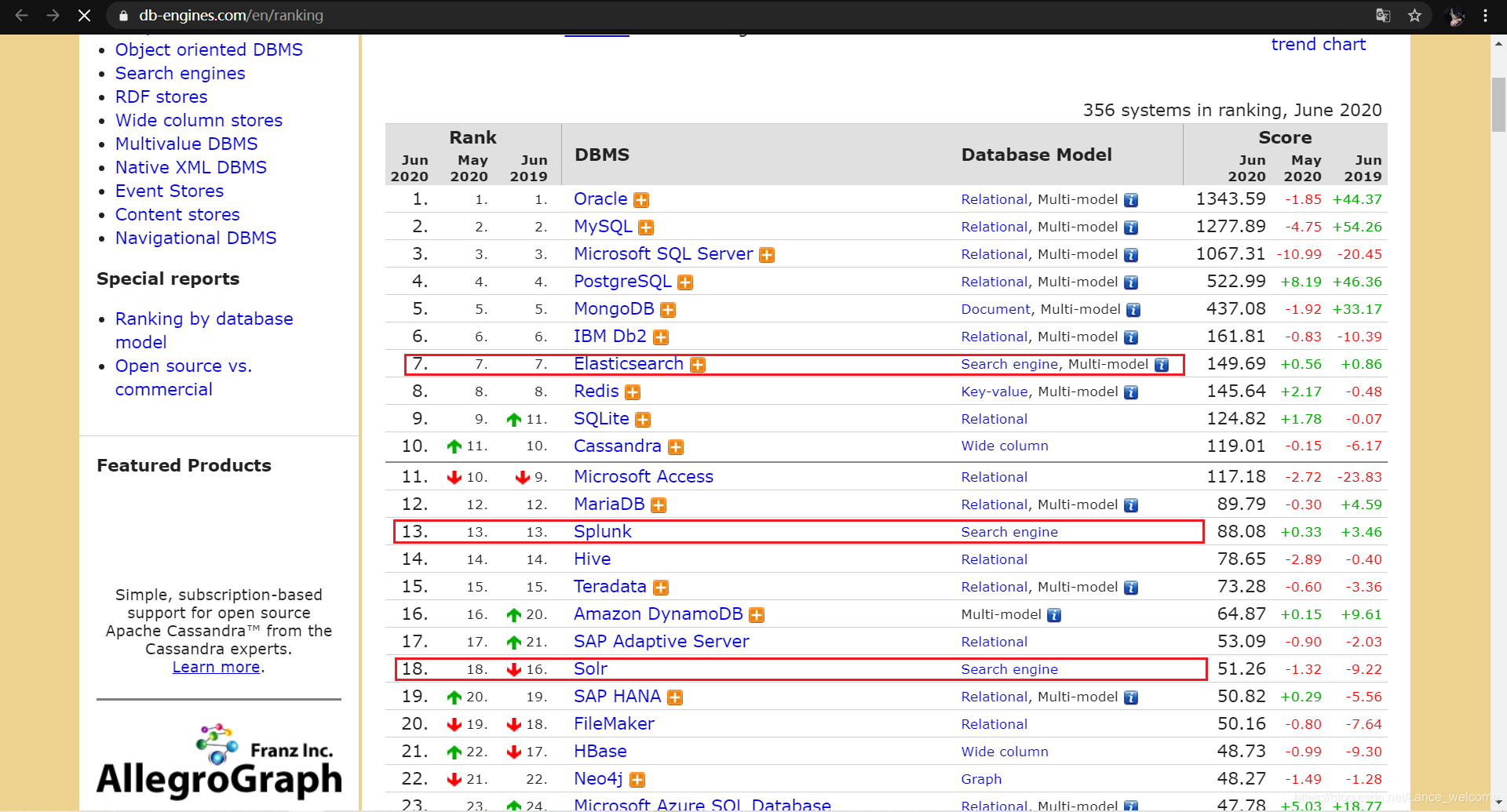
elasticsearch和solr。这两款都是基于lucene搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作,修改、添加、保存、查询等等都十分类似。就好像都是支持sql语言的两种数据库软件。只要学会其中一个另一个很容易上手。
elastic
elasticsearch

最新版本7.7.1, 因为更新比较快,所以下面使用的是稳定版本6.8.1。下载
提取码:2d5x
复制这段内容后打开百度网盘手机App,操作更方便哦安装 elasticsearch

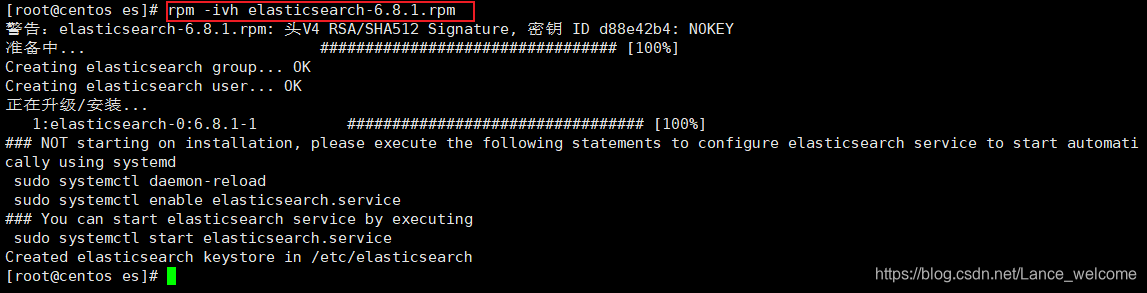
rpm -ivh elasticsearch-6.8.1.rpm
vim /etc/sysconfig/elasticsearch


配置elasticsearch
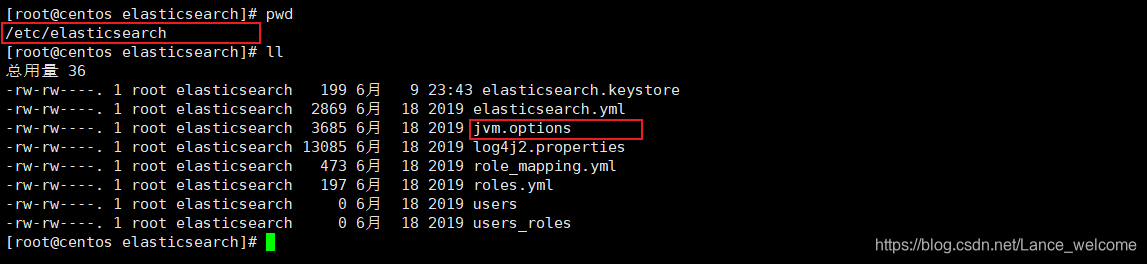
jvm.options 和elasticsearch.yml
jvm.options 。elasticsearch默认占用所有内存,导致虚拟机很慢,可以改的小一点。[ 默认是1G ]vim /etc/elasticsearch/jvm.options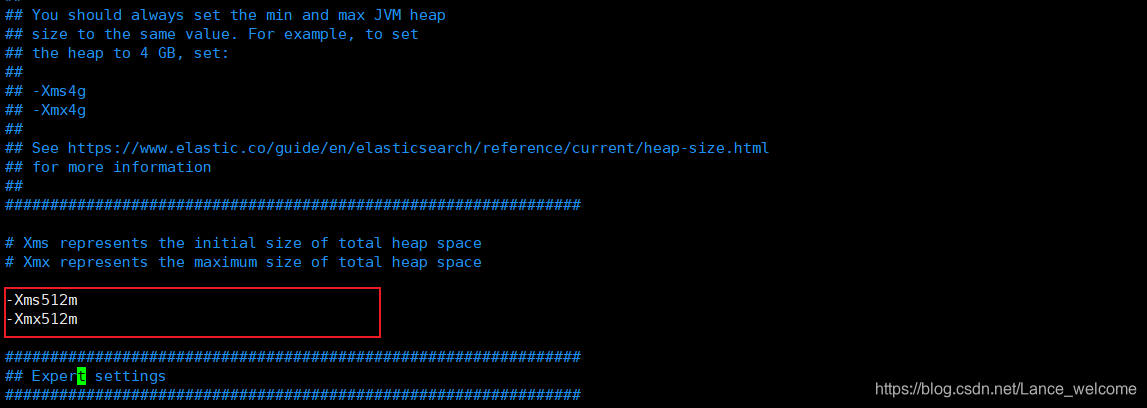
两个值必须相等
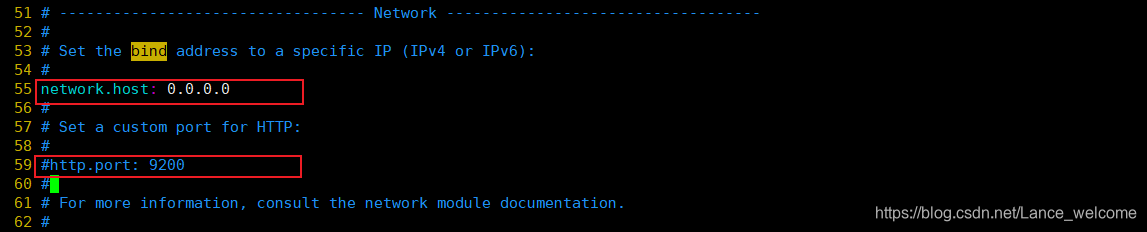
elasticsearch.yml 配置文件vim /etc/elasticsearch/elasticsearch.yml


0.0.0.0后则可以远程访问;9200
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
6. 配置集群列表,这里只有一个。可以配置计算机名,也可以配置ip [ 建议配主机名 , 因为ip可能会变所以配主机名称 ]
首先查看主机名 : hostname

主机名是你计算机名,一定不可以写错!!

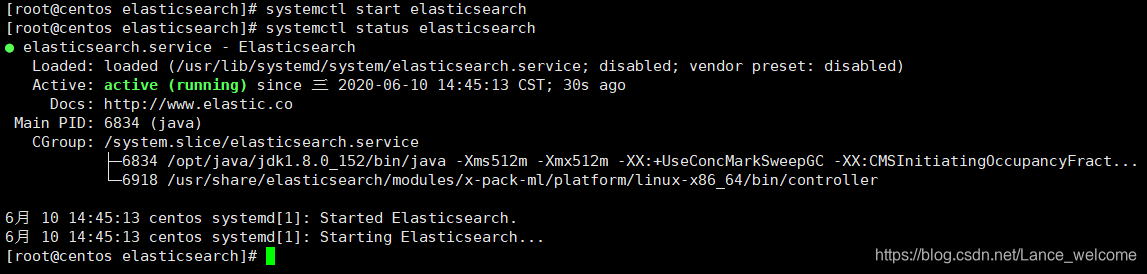
以上 ElasticSearch 基本配置完成了重启
systemctl start elasticsearchsystemctl status elasticsearch
vim /var/log/elasticsearch/{cluster-name}.logvim /var/log/elasticsearch/my-es.log文件
测试
curl https://localhost:9200[root@centos elasticsearch]# curl https://localhost:9200 { "name" : "node-1", "cluster_name" : "my-application", "cluster_uuid" : "NVxe9XcoS2aqWn_cjt4Mag", "version" : { "number" : "6.8.1", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "1fad4e1", "build_date" : "2019-06-18T13:16:52.517138Z", "build_snapshot" : false, "lucene_version" : "7.7.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" } [root@centos elasticsearch]#
如果防火墙也关闭了, 浏览器也可以正常显示的 , 如图

cluster_block_exception
elasticsearch.yml中取消硬盘检查。elasticsearch.yml配置文件中末尾,追加这个配置:vim /etc/elasticsearch/elasticsearch.ymlcluster.routing.allocation.disk.threshold_enabled: false安装kibana
cd /opt/es 目录下解压

cd kibana-6.8.1-linux-x86_64/config 修改 kibana.yml配置文件,允许访问的ip地址5601

7行 修改为虚拟机IP地址

28行 配置elasticsearch服务器列表:

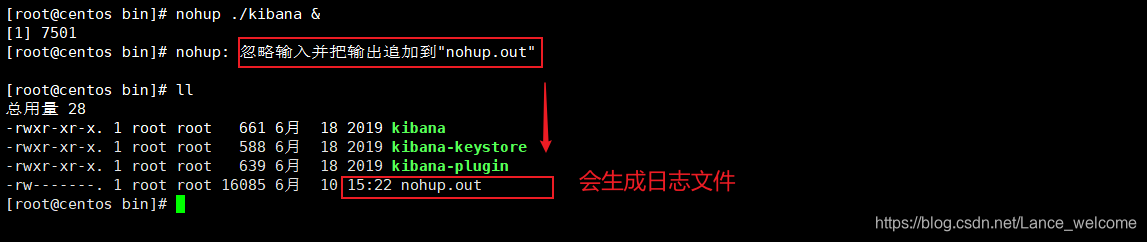
启动:
kibana 的 bin目录下

./kibana # 阻塞的方式启动, 会输出日志,并独占当前窗口
nohup ./kibana & # 后台启动
测试:
启动的时候可能比较慢, 因为会去加载ElasticSearch里面的数据
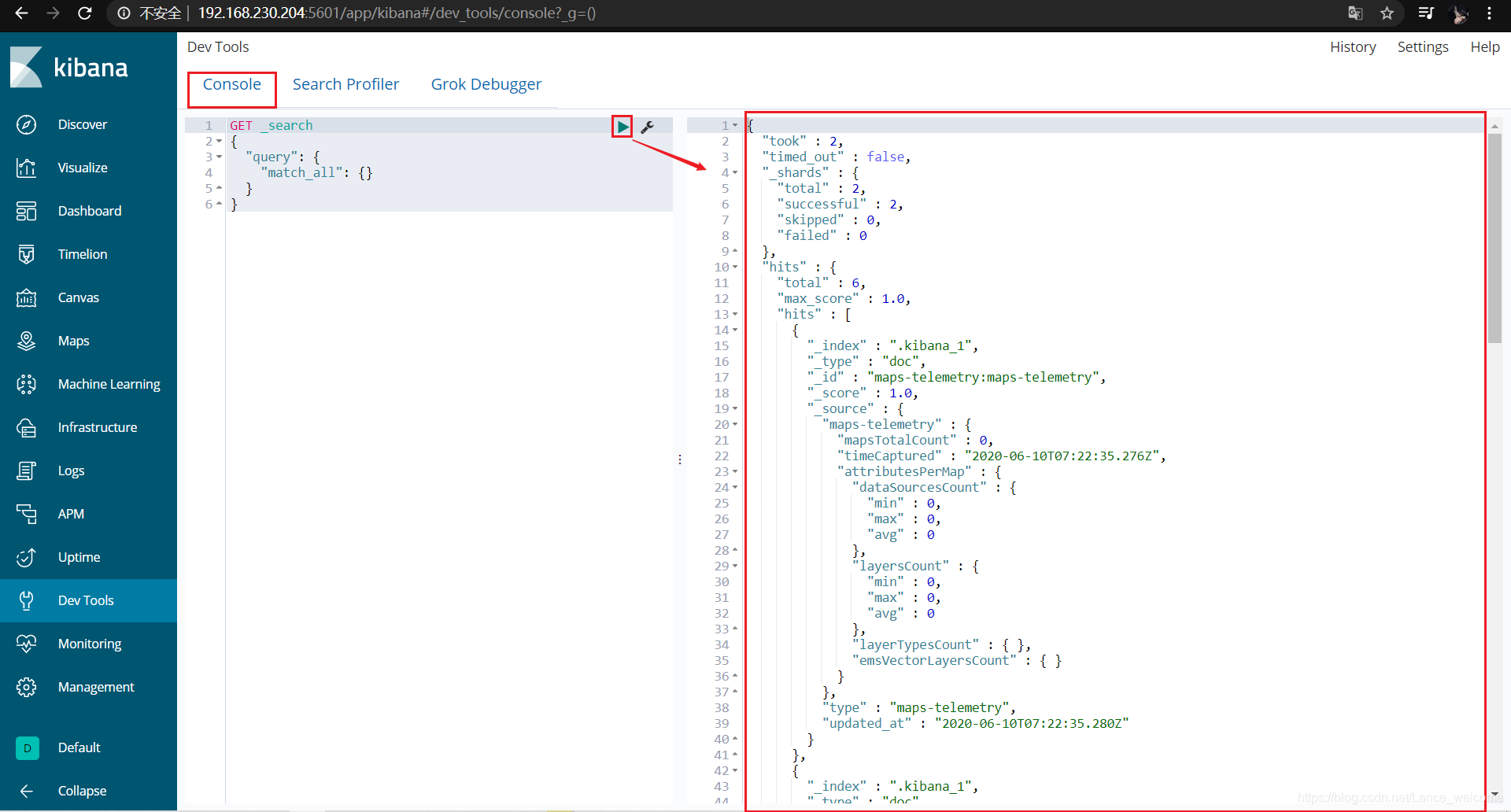
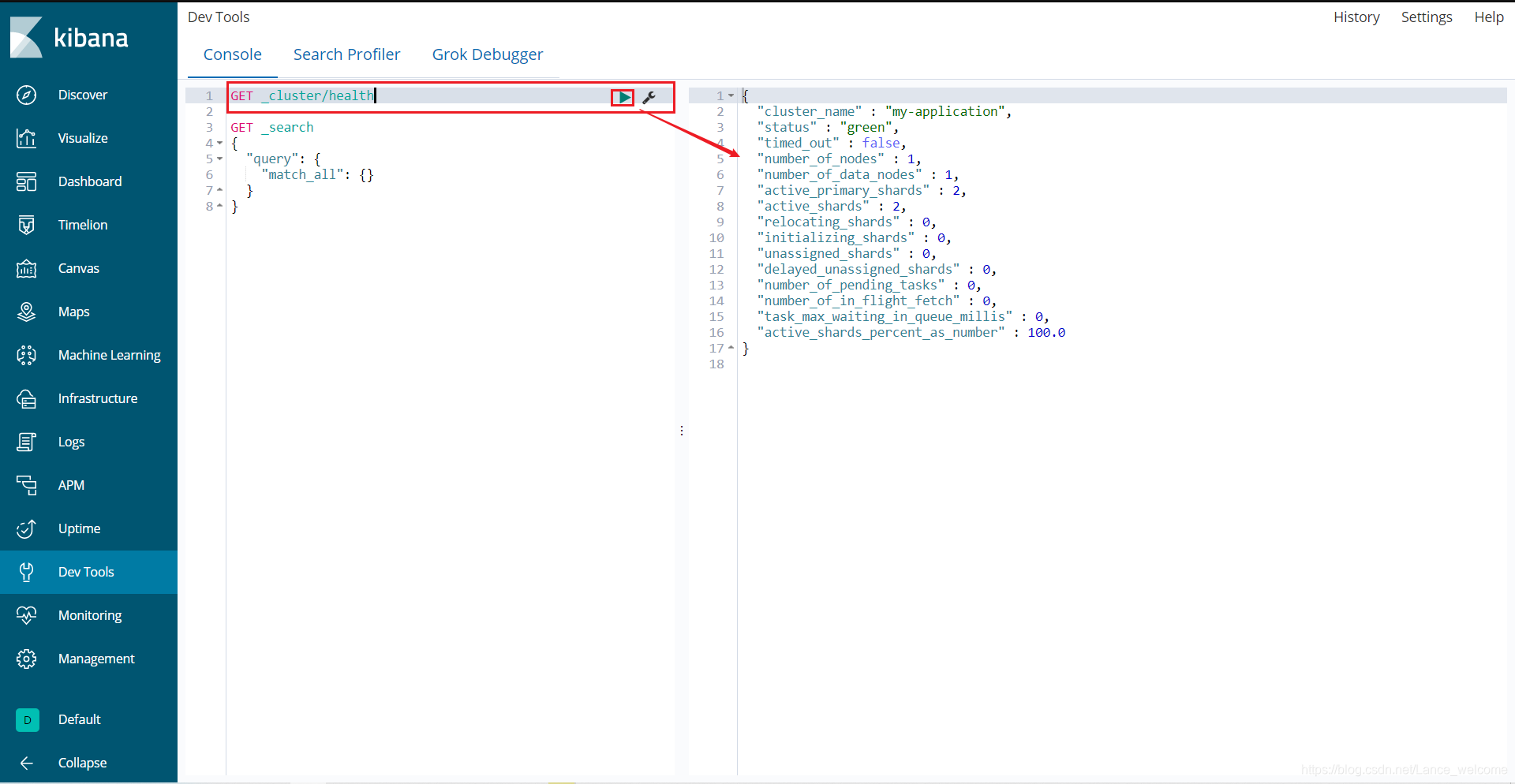
控制台测试 :
get _cluster/health 可以查看状态
yellow或者green。
IK分词器
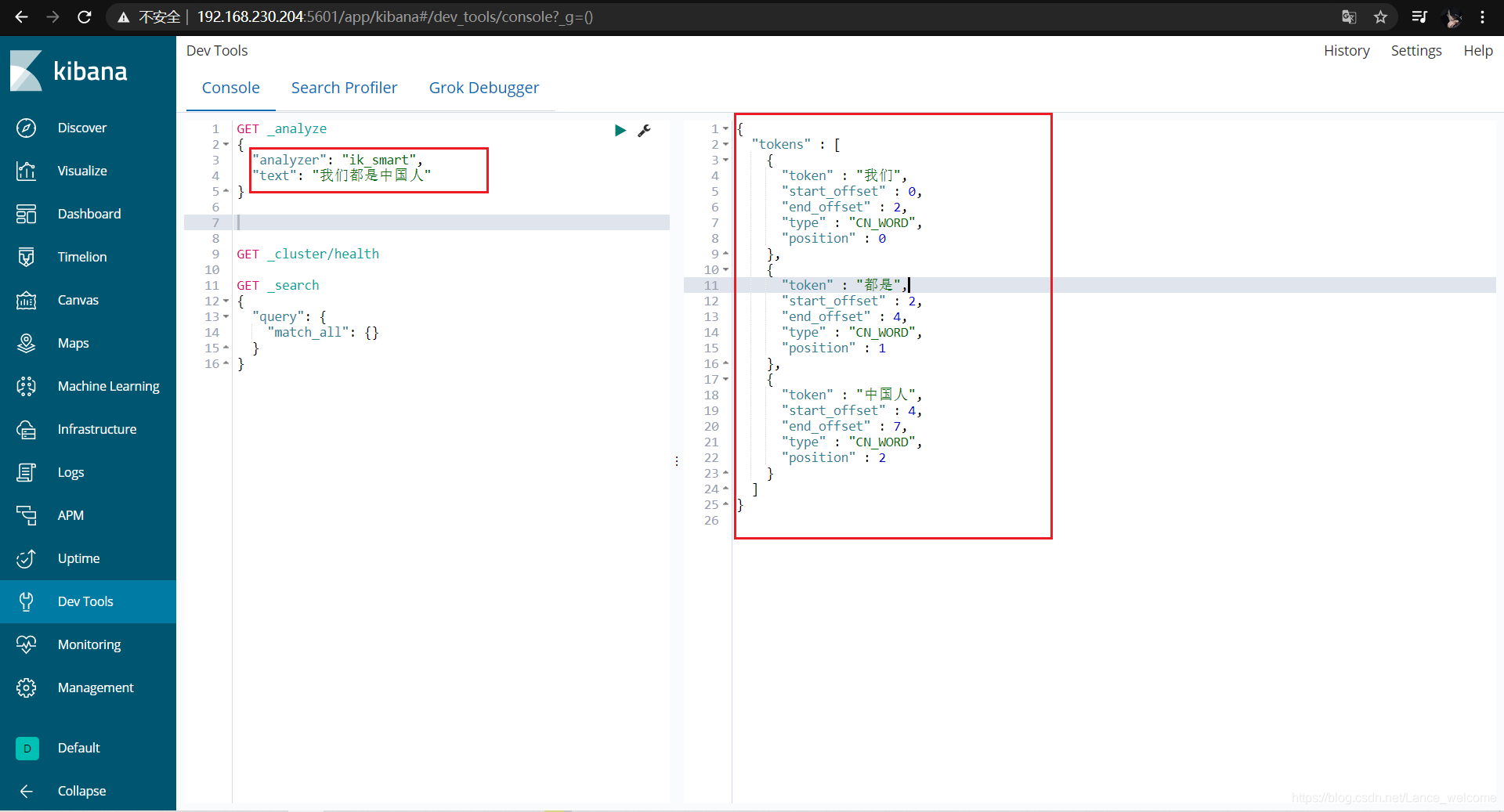
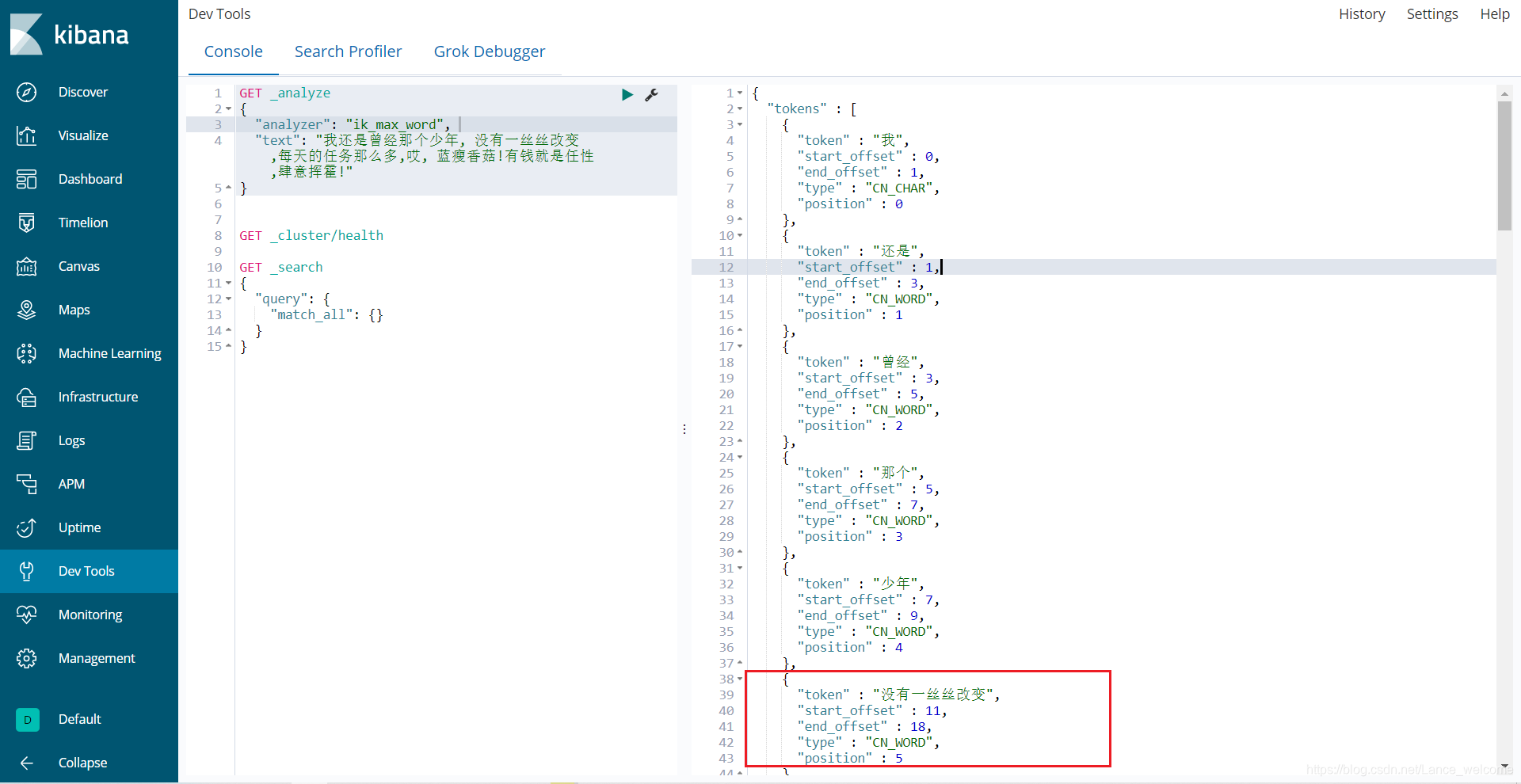
GET _analyze { "text": "我们都是中国人" } 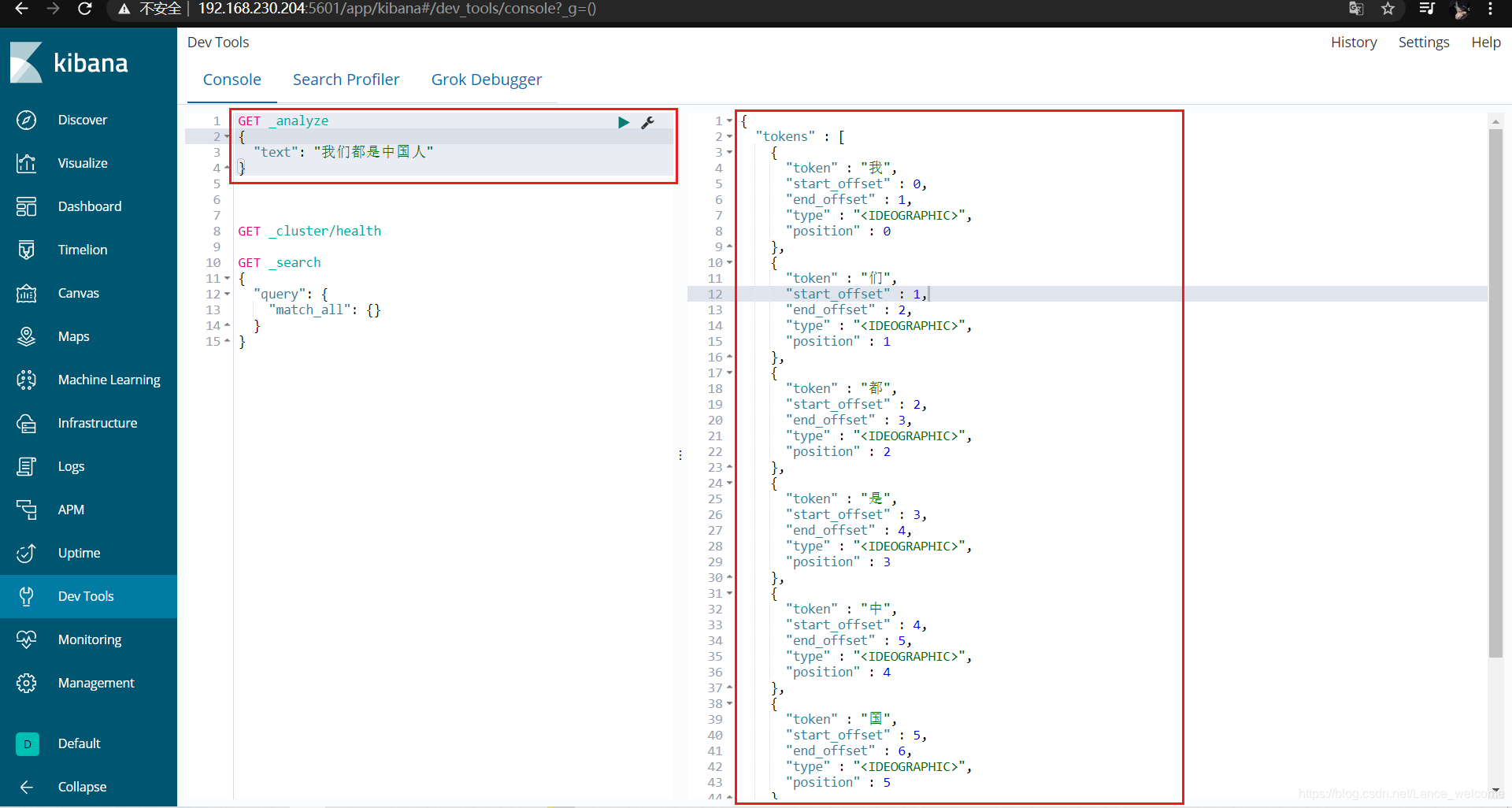
elasticsearch 本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。但是实际应用中,用户都是以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。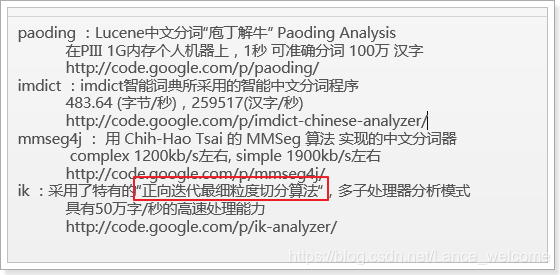
IK分词器使用最多。介绍
下载
密码: doze安装
/usr/share/elasticsearch/plugins 目录下-d ik-analyzerunzip elasticsearch-analysis-ik-6.8.1.zip -d ik-analyzer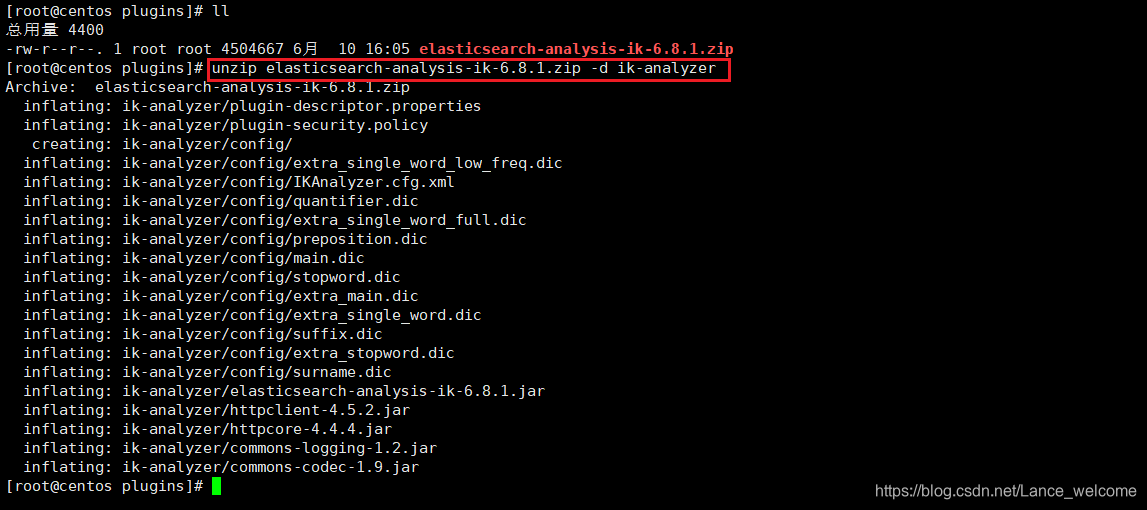

测试
systemctl restart elasticsearch.service
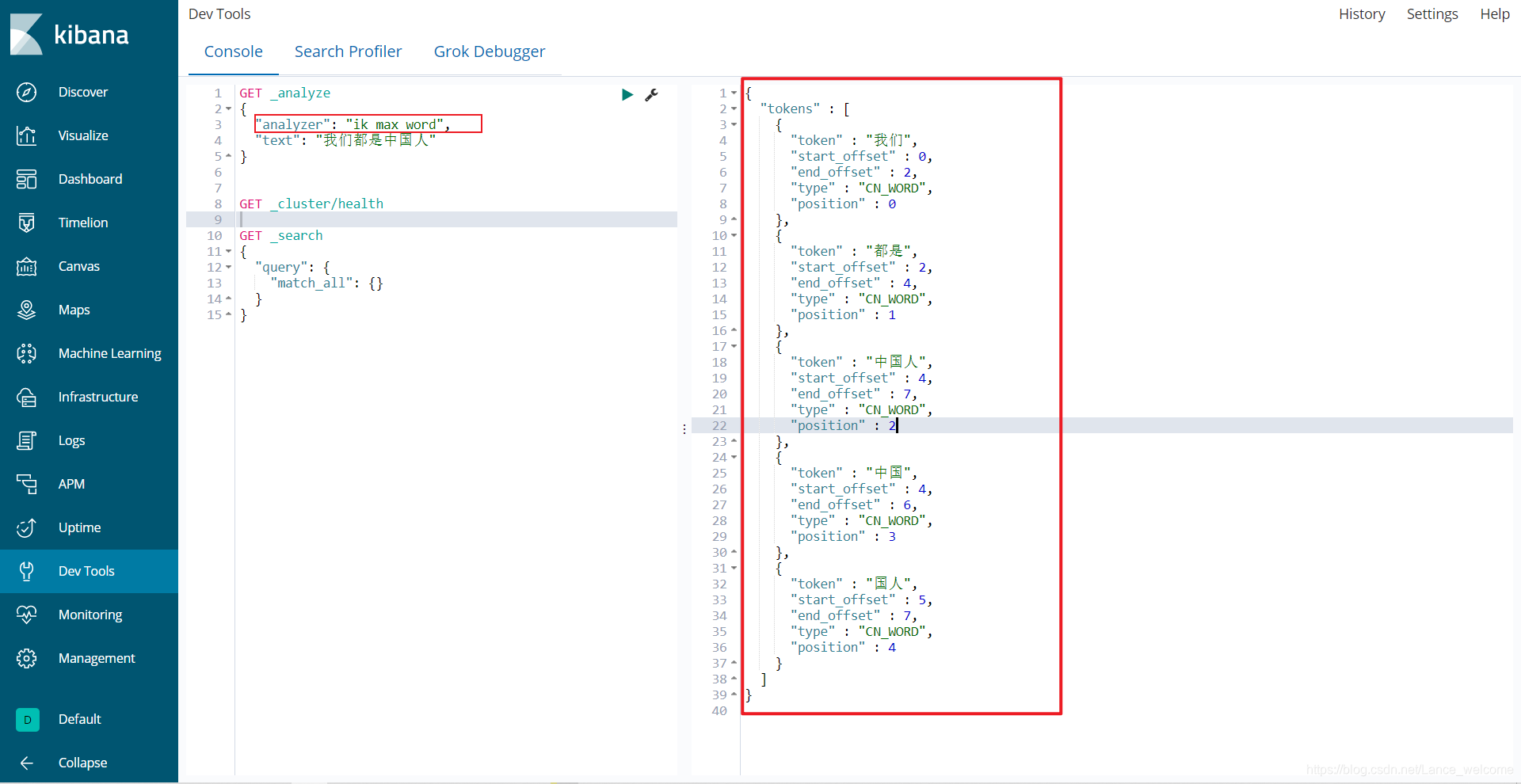
"analyzer": "ik_smart" 在次测试GET _analyze { "analyzer": "ik_smart", "text": "我们都是中国人" }
ik_max_word
自定义词库
elasticsearch 加载 ik分词器插件时,ik会读取一个配置文件,这个配置文件在ik分词器根目录的 config 目录下:
vim IKAnalyzer.cfg.xml打开编辑
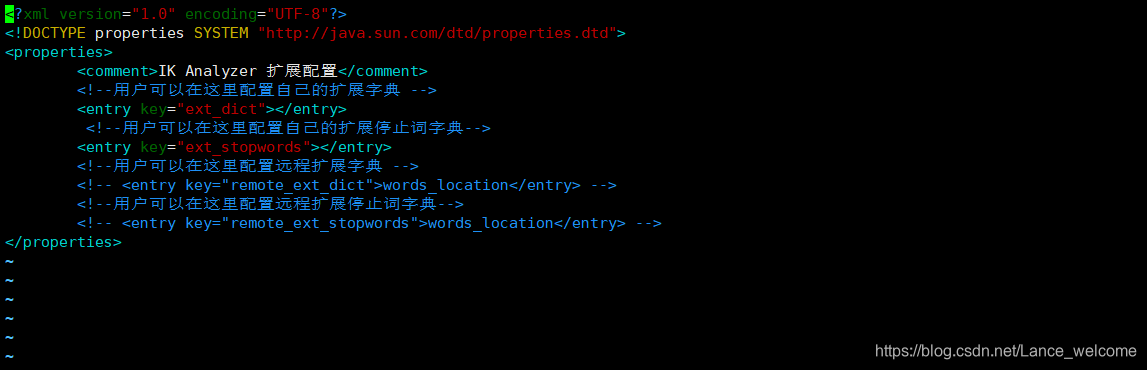
这里有两种方式配置扩展词典和停用词典:
Nginx 安装
第一步:利用nginx搭建远程词库。
nginx.conf文件vim /usr/local/nginx/conf/nginx.conf

elasticsearch目录编辑cd /usr/local/nginx/
mkdir -p /usr/local/nginx/elasticsearch/compile
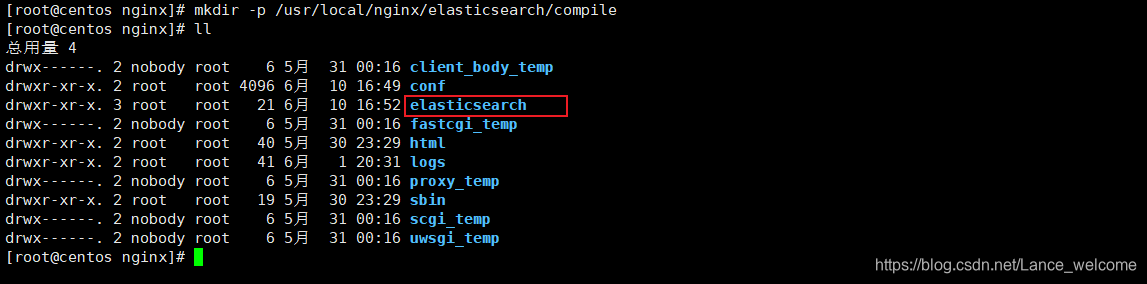
cd elasticsearch/compile/ 目录下创建 compile_dict.txtvim compile_dict.txt , 随便自定义词条添加

重启 Nginx
nginxnginx -s reload

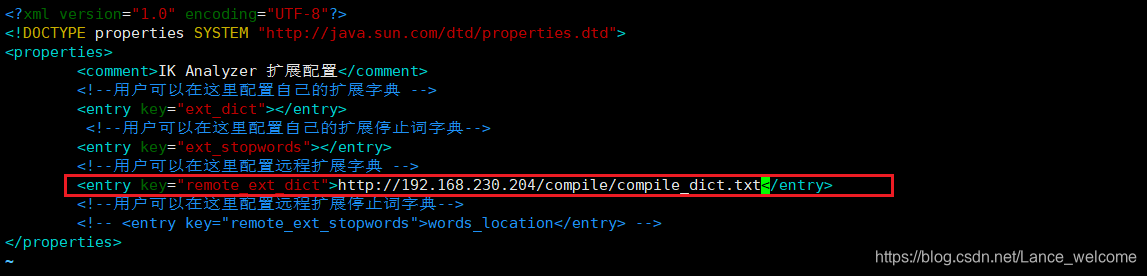
第二步:在ik分词器中引用远程词库
cd /usr/share/elasticsearch/plugins/ik-analyzer/config/
vim IKAnalyzer.cfg.xml 配置文件引入刚才自定义的字典文件
重启elasticsearch服务
systemctl restart elasticsearch.service

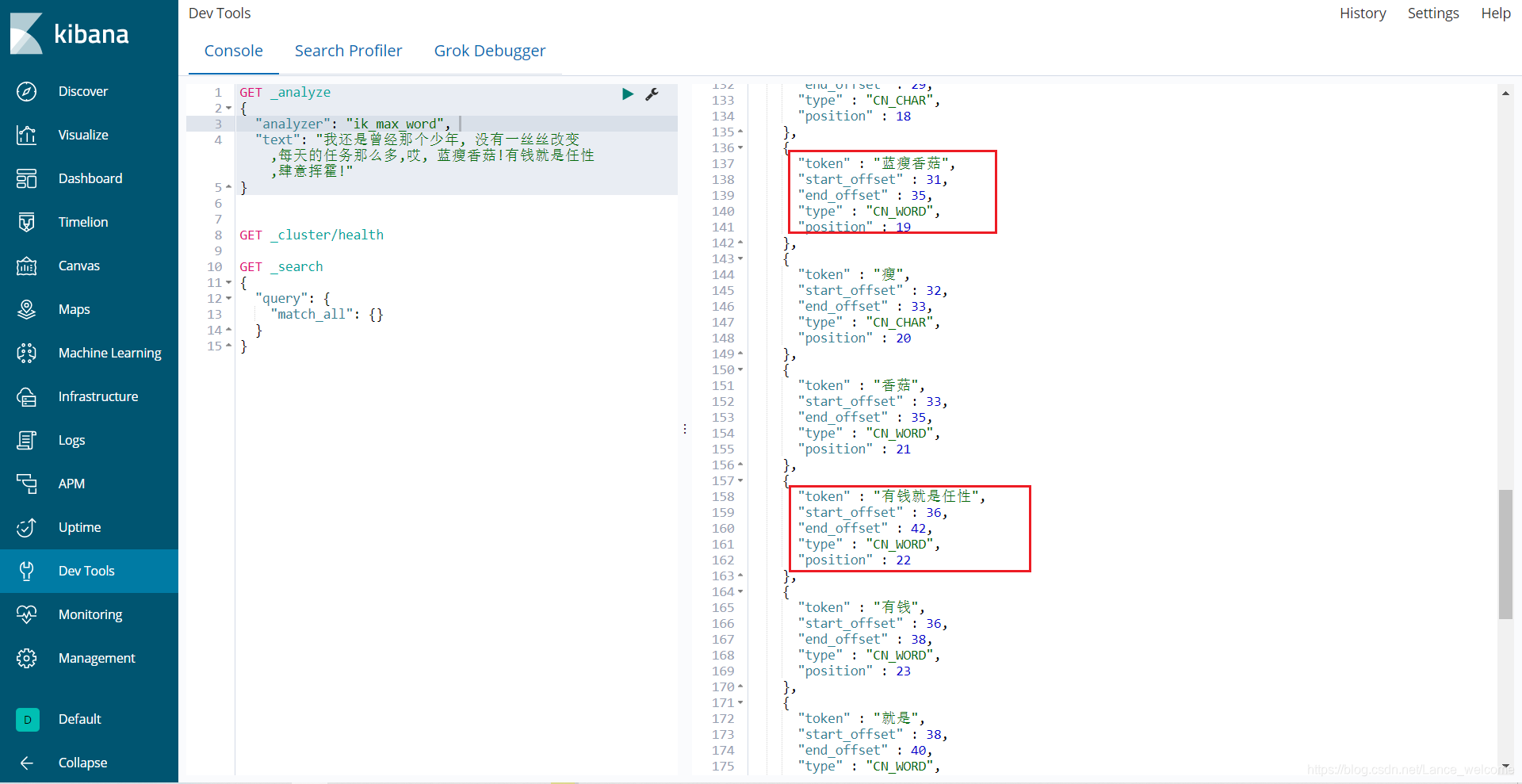
添加新词条后,es只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:POST {index}/_update_by_query?conflicts=proceedelasticsearch基本操作
说明
cluster
整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。
node
集群中的一个节点,一般只一个进程就是一个node
shard
分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。
index
索引。相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。
type
类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。
document
文档。类似于rdbms的 row、面向对象里的object
field
字段。相当于字段、属性
mappings
映射。字段的数据类型、属性、是否索引、是否存储等特性
索引(indices)----------------------Databases 数据库 类型(type)--------------------------Table 数据表 文档(Document)----------------------Row 行 字段(Field)-------------------------Columns 列 public class Movie { String id; String name; Double doubanScore; List<Actor> actorList; } public class Actor{ String id; String name; } { “id”:”1”, “name”:”operation red sea”, “doubanScore”:”8.5”, “actorList”:[ {“id”:”1”,”name”:”zhangyi”}, {“id”:”2”,”name”:”haiqing”}, {“id”:”3”,”name”:”zhanghanyu”} ] } 索引操作(indeces)
查询索引
GET /_cat/indices?v
字段名
含义说明
health
green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status
是否能使用
index
索引名
uuid
索引统一编号
pri
主节点几个
rep
从节点几个
docs.count
文档数
docs.deleted
文档被删了多少
store.size
整体占空间大小
pri.store.size
主节点占
创建索引
PUT /索引名
{ "settings": { "number_of_shards": 3, "number_of_replicas": 2 } }

GET /hello
GET /*删除索引
DELETE /索引库名映射配置(_mapping)
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
PUT /索引库名/_mapping/类型名称 { "properties": { "字段名": { "type": "类型", "index": true, "store": true, "analyzer": "分词器" } } }
ik_max_word或者ik_smart发起请求:
PUT hello/_mapping/goods { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "images": { "type": "keyword", "index": "false" }, "price": { "type": "long" } } } { "acknowledged" : true } 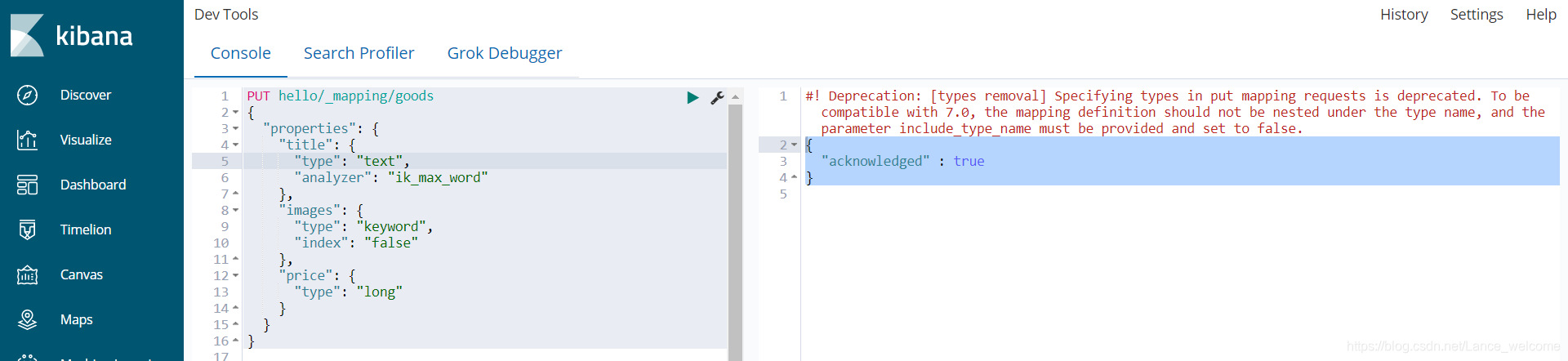
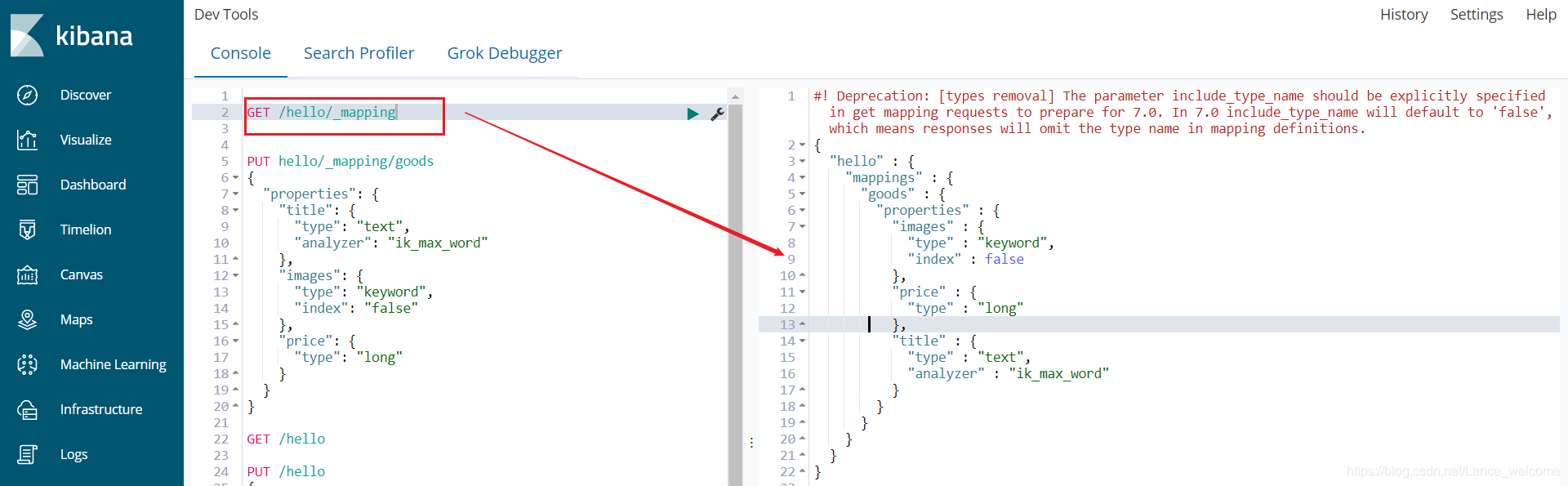
查看映射关系
GET /索引库名/_mapping
字段属性详解
index
store
_source的属性中。而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。_source以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。新增文档(document)
语法POST /索引库名/类型名 { "key":"value" } POST /hello/goods { "title": "华为P40PRO", "images": "https://res.vmallres.com/pimages/detailImg/2020/05/06/30876E629D665CE7DA18C13A3C7E7D150F469AC8AEC0A4E6.jpg", "price": 4488 } 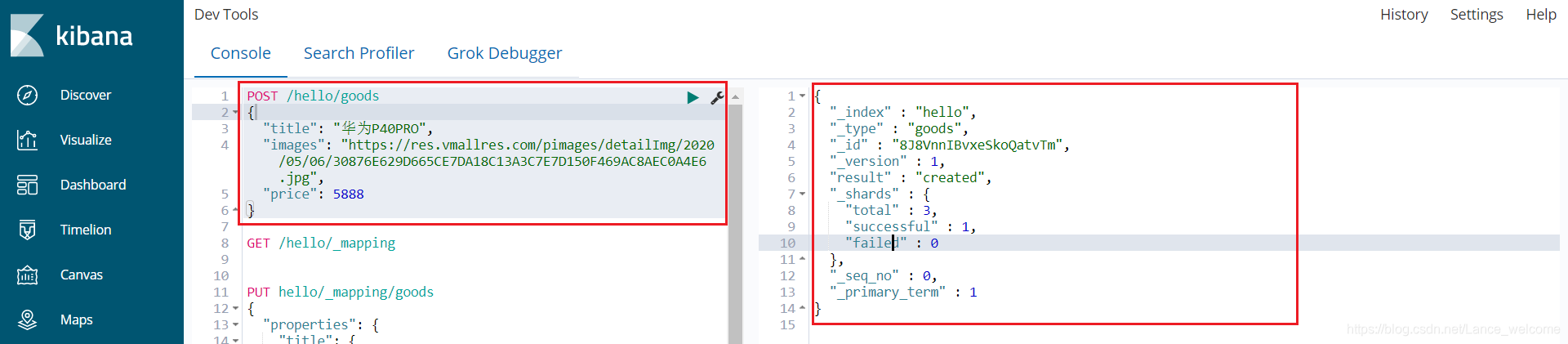
查询看看结果:
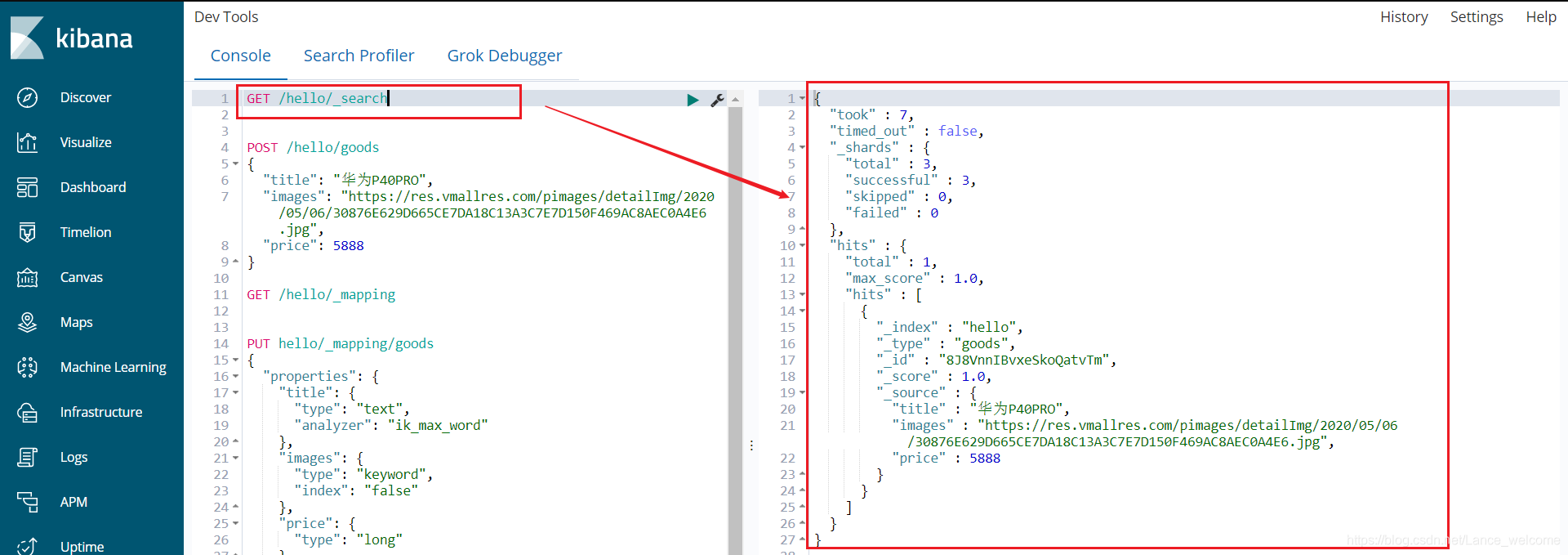
_source:源文档信息,所有的数据都在里面。_id:这条文档的唯一标示,与文档自己的id字段没有关联自定义id
POST /索引库名/类型/id值 { ... } 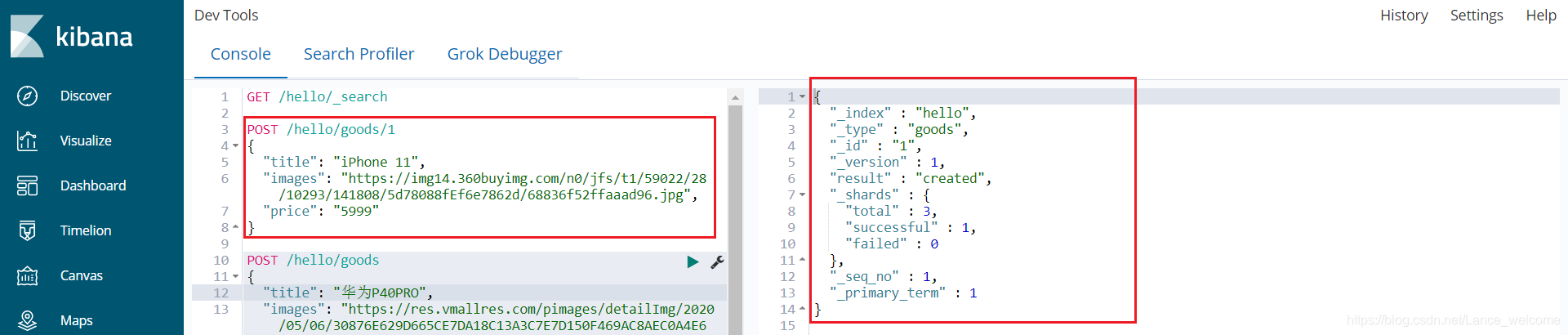
查询得到两条数据:iPhone 11 手机的id是我们指定的id
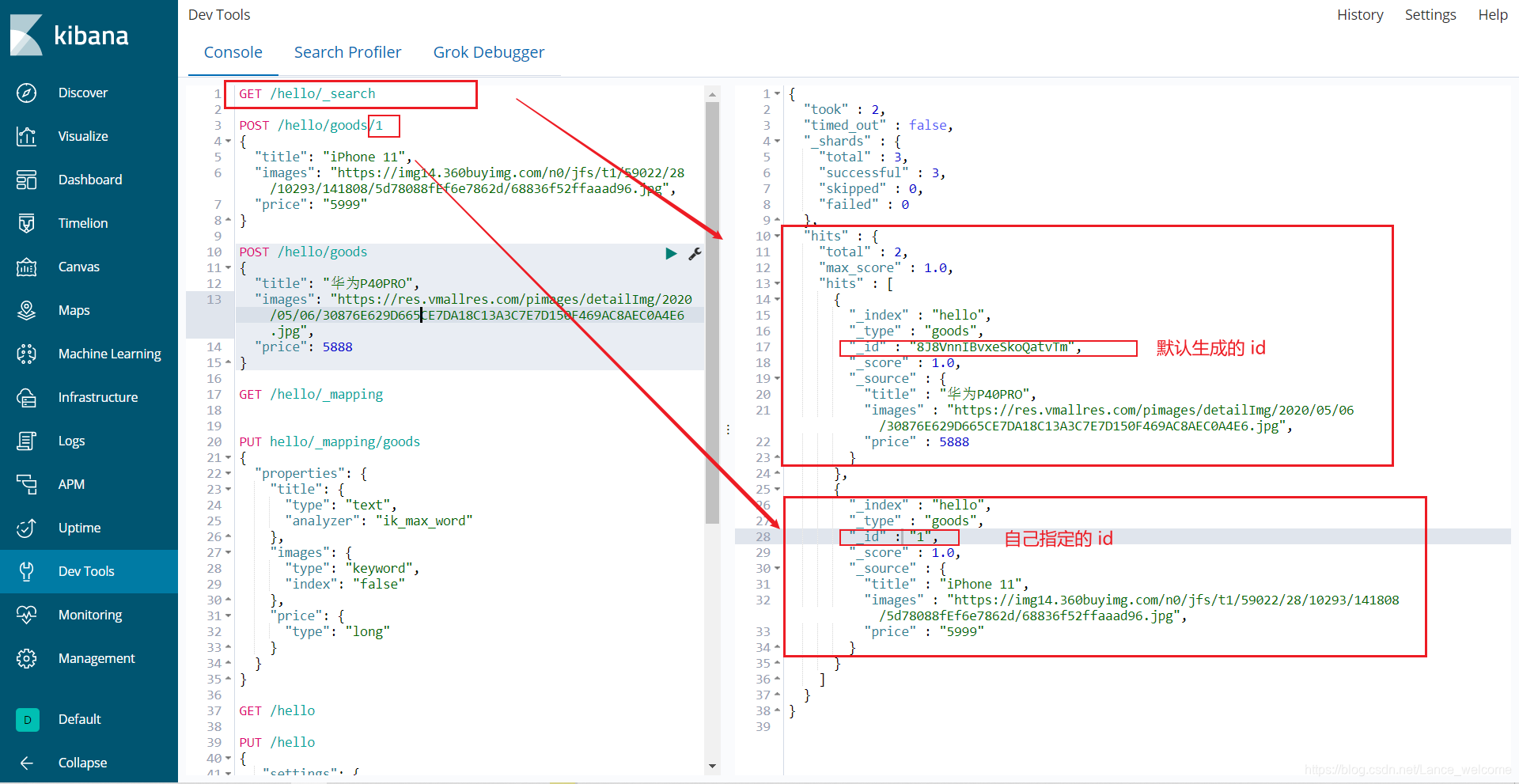
智能判断
POST /hello/goods/2 { "title":"小米手机", "images":"https://image.jd.com/12479122.jpg", "price":2899, "stock": 200, "saleable":true, "attr": { "category": "手机", "brand": "小米" } }
来看结果:GET /atguigu/_search
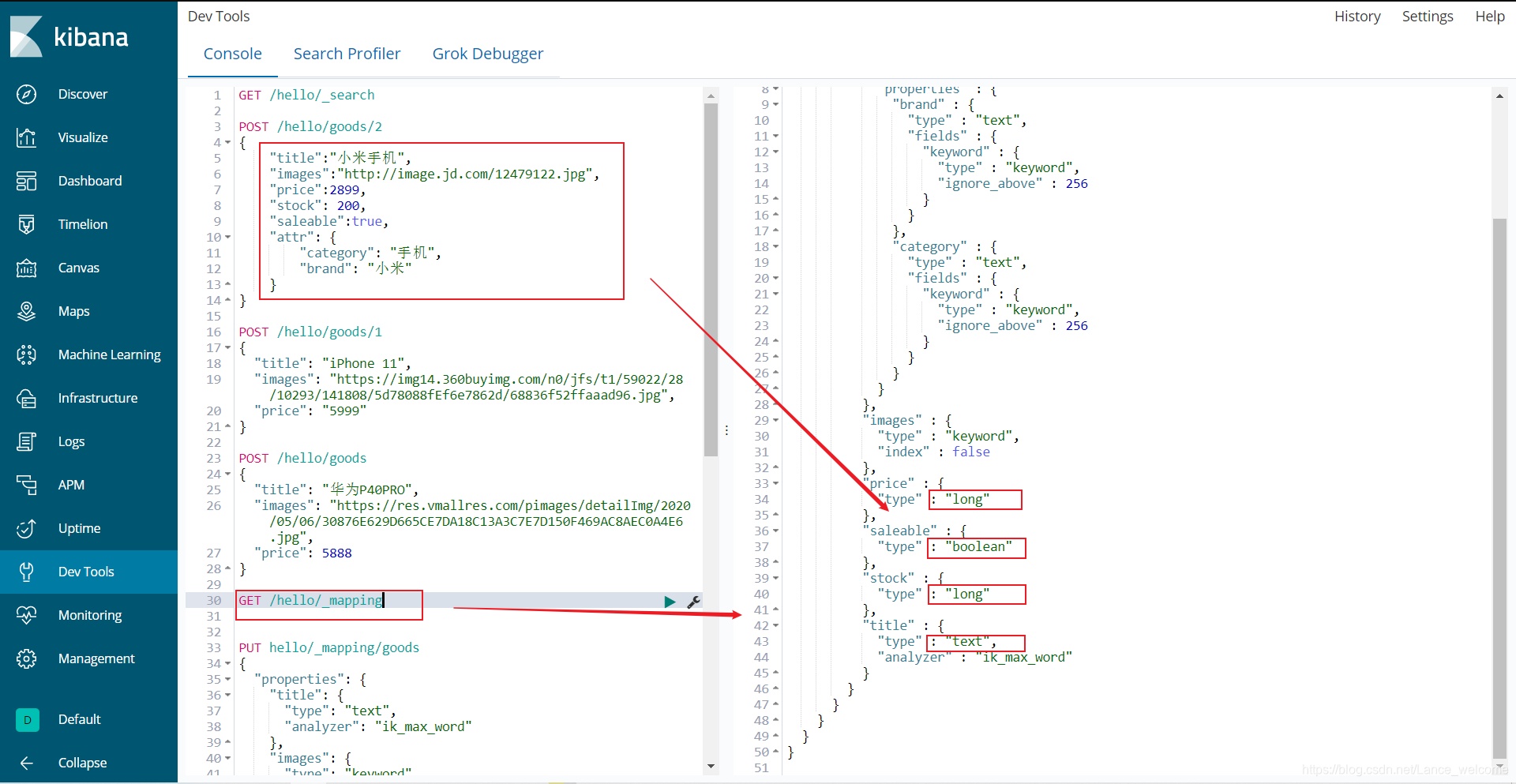
GET /atguigu/_mapping修改数据
整体覆盖
PUT /hello/goods/2 { "title":"超米手机", "images":"https://image.jd.com/12479122.jpg", "price":2999, "stock": 200, "saleable":true, "attr": { "category": "手机", "brand": "小米" } } GET /hello/goods/2

这种方式必须有所有字段,否则会导致更新后的数据字段缺失。更新字段
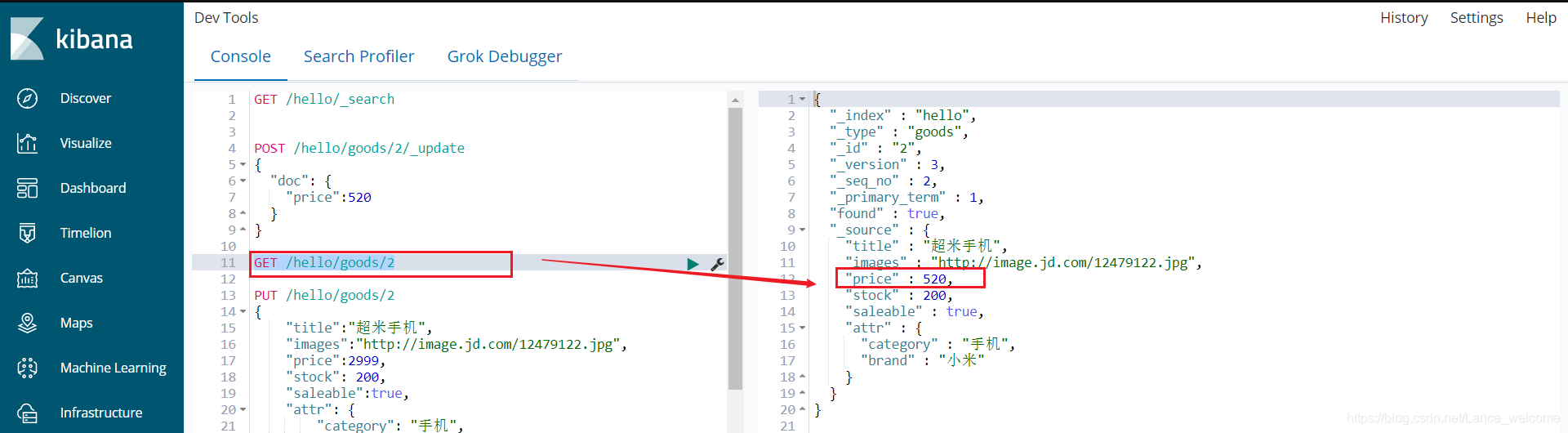
语法:POST /{index}/{type}/{id}/_update { "doc": { 字段名: 字段值 } } 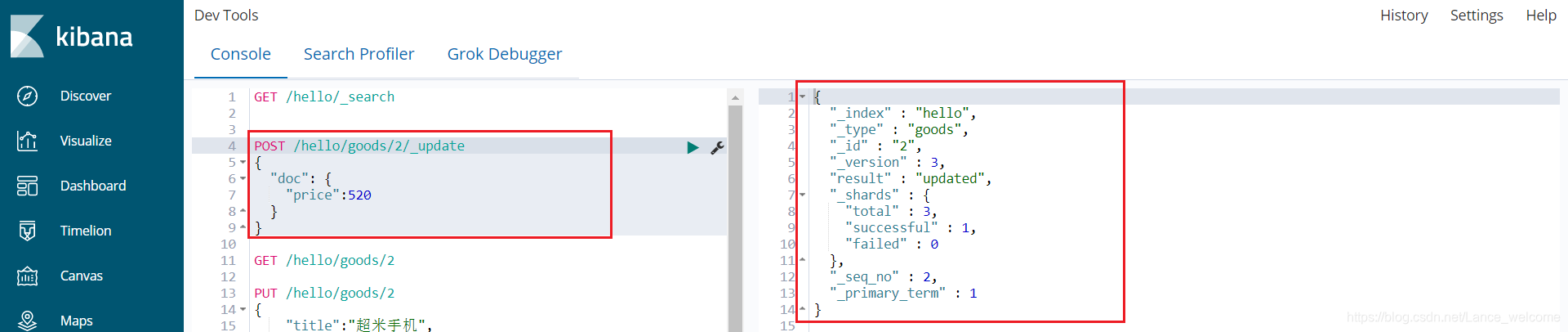
查询更新后的结果
删除数据
语法DELETE /索引库名/类型名/id值
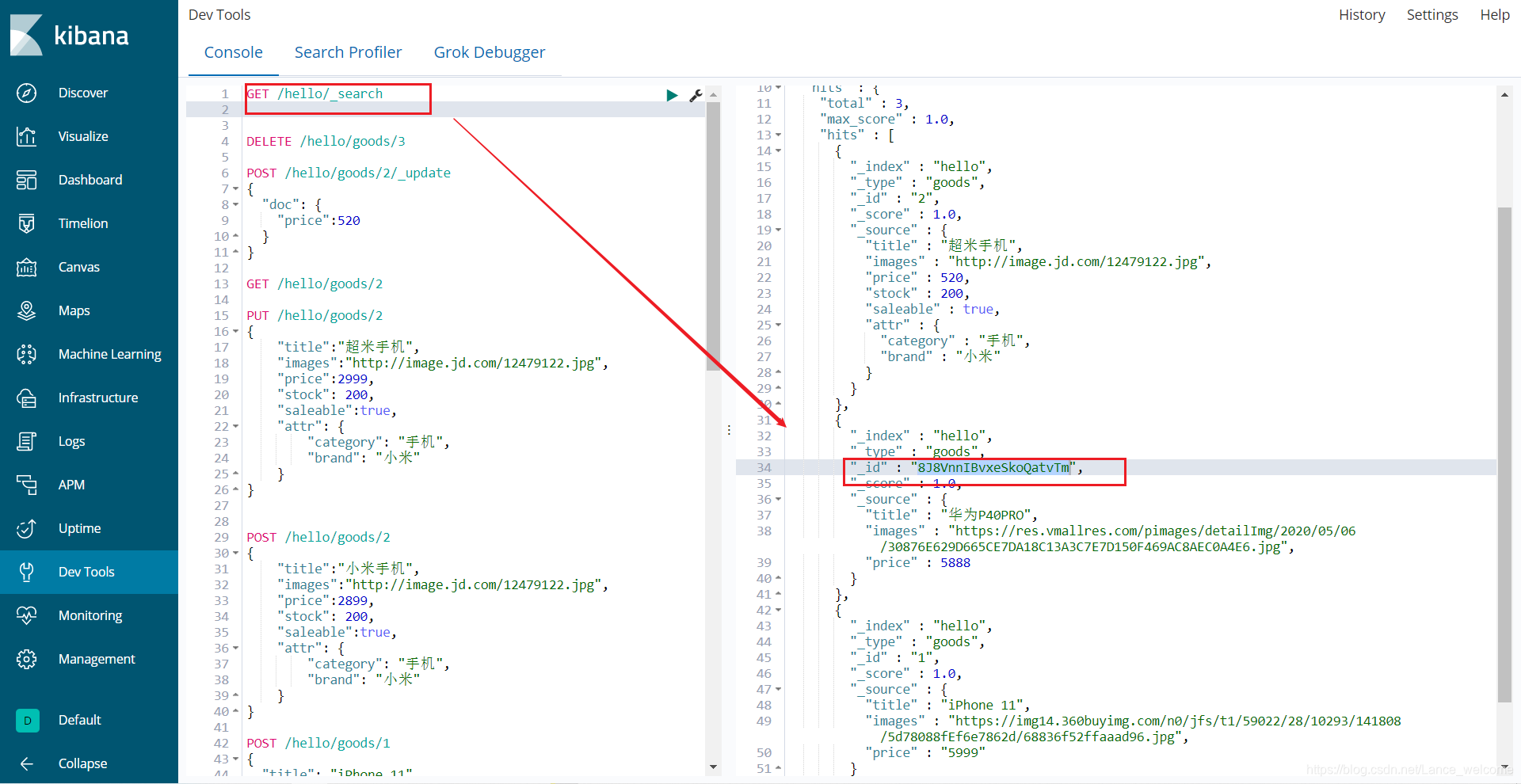
删除完成 ,就剩两条记录了
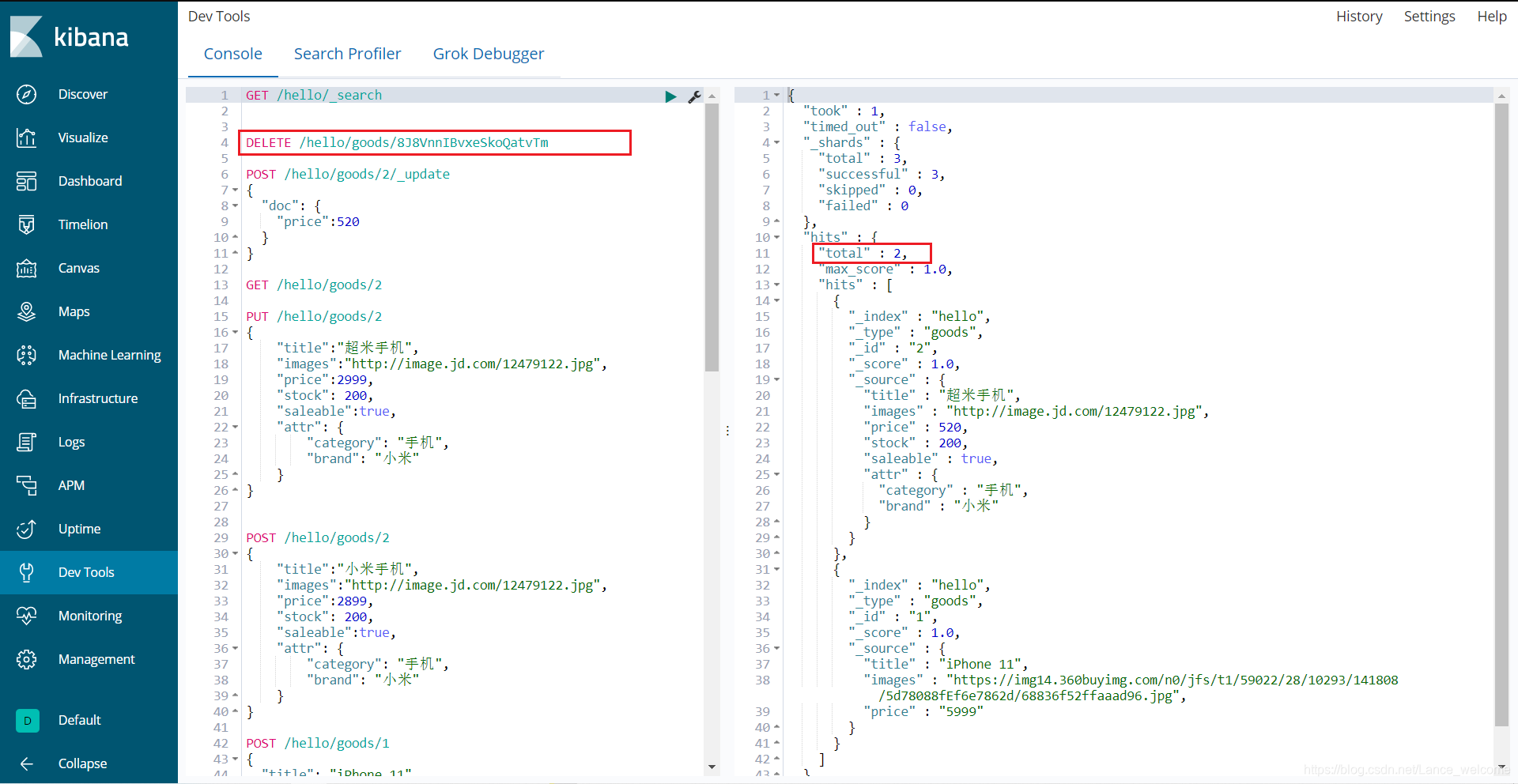
查询
GET /{index}/_search GET /{index}/{type}/{id} 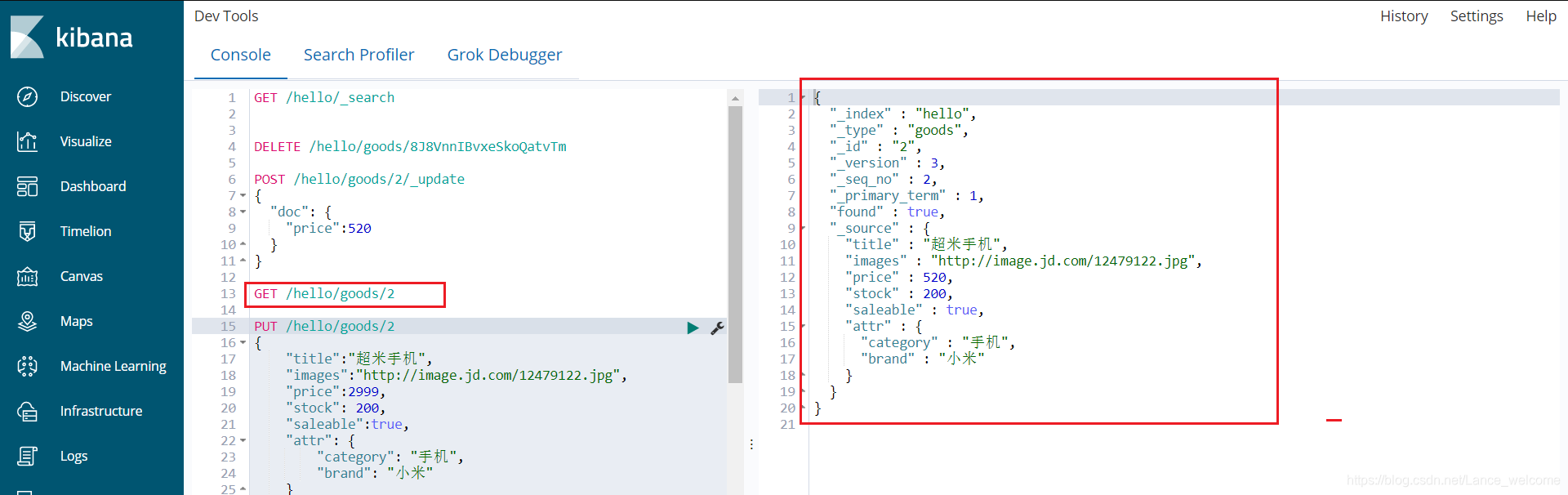
除了上述简单查询之外。elasticsearch作为搜索引擎,最复杂最强大的功能就是搜索查询功能。包括:匹配查询、词条查询、模糊查询、组合查询、范围查询、高亮、排序、分页等等查询功能。GET /索引库名/_search { "query":{ "查询类型":{ "查询条件":"查询条件值" } } }
match_all, match,term , range 等等
数据准备
POST /hello/goods/_bulk {"index":{"_id":1}} { "title":"小米手机", "images":"https://image.jd.com/12479122.jpg", "price":1999, "stock": 200, "attr": { "category": "手机", "brand": "小米" } } {"index":{"_id":2}} {"title":"超米手机", "images":"https://image.jd.com/12479122.jpg", "price":2999, "stock": 300, "attr": { "category": "手机", "brand": "小米" } } {"index":{"_id":3}} { "title":"小米电视", "images":"https://image.jd.com/12479122.jpg", "price":3999, "stock": 400, "attr": { "category": "电视", "brand": "小米" } } {"index":{"_id":4}} { "title":"小米笔记本", "images":"https://image.jd.com/12479122.jpg", "price":4999, "stock": 200, "attr": { "category": "笔记本", "brand": "小米" } } {"index":{"_id":5}} { "title":"华为手机", "images":"https://image.jd.com/12479122.jpg", "price":3999, "stock": 400, "attr": { "category": "手机", "brand": "华为" } } {"index":{"_id":6}} { "title":"华为笔记本", "images":"https://image.jd.com/12479122.jpg", "price":5999, "stock": 200, "attr": { "category": "笔记本", "brand": "华为" } } {"index":{"_id":7}} { "title":"荣耀手机", "images":"https://image.jd.com/12479122.jpg", "price":2999, "stock": 300, "attr": { "category": "手机", "brand": "华为" } } {"index":{"_id":8}} { "title":"oppo手机", "images":"https://image.jd.com/12479122.jpg", "price":2799, "stock": 400, "attr": { "category": "手机", "brand": "oppo" } } {"index":{"_id":9}} { "title":"vivo手机", "images":"https://image.jd.com/12479122.jpg", "price":2699, "stock": 300, "attr": { "category": "手机", "brand": "vivo" } } {"index":{"_id":10}} { "title":"华为nova手机", "images":"https://image.jd.com/12479122.jpg", "price":2999, "stock": 300, "attr": { "category": "手机", "brand": "华为" } } 匹配查询(match)
GET /hello/_search { "query":{ "match_all": {} } }
query:代表查询对象match_all:代表查询所有条件匹配 模糊匹配
GET /hello/_search { "query": { "match": { "title": "小米手机" } } } 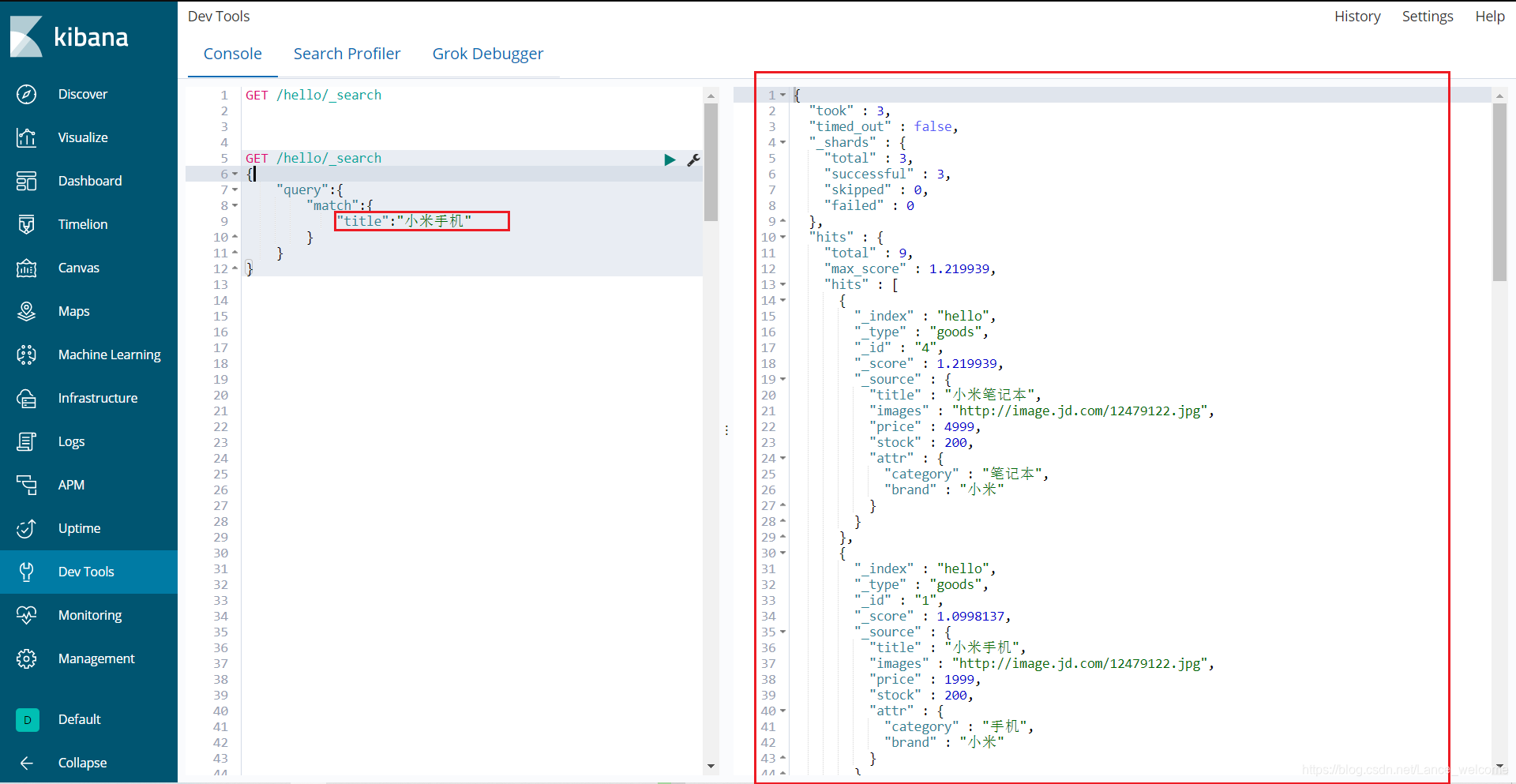
条件查询
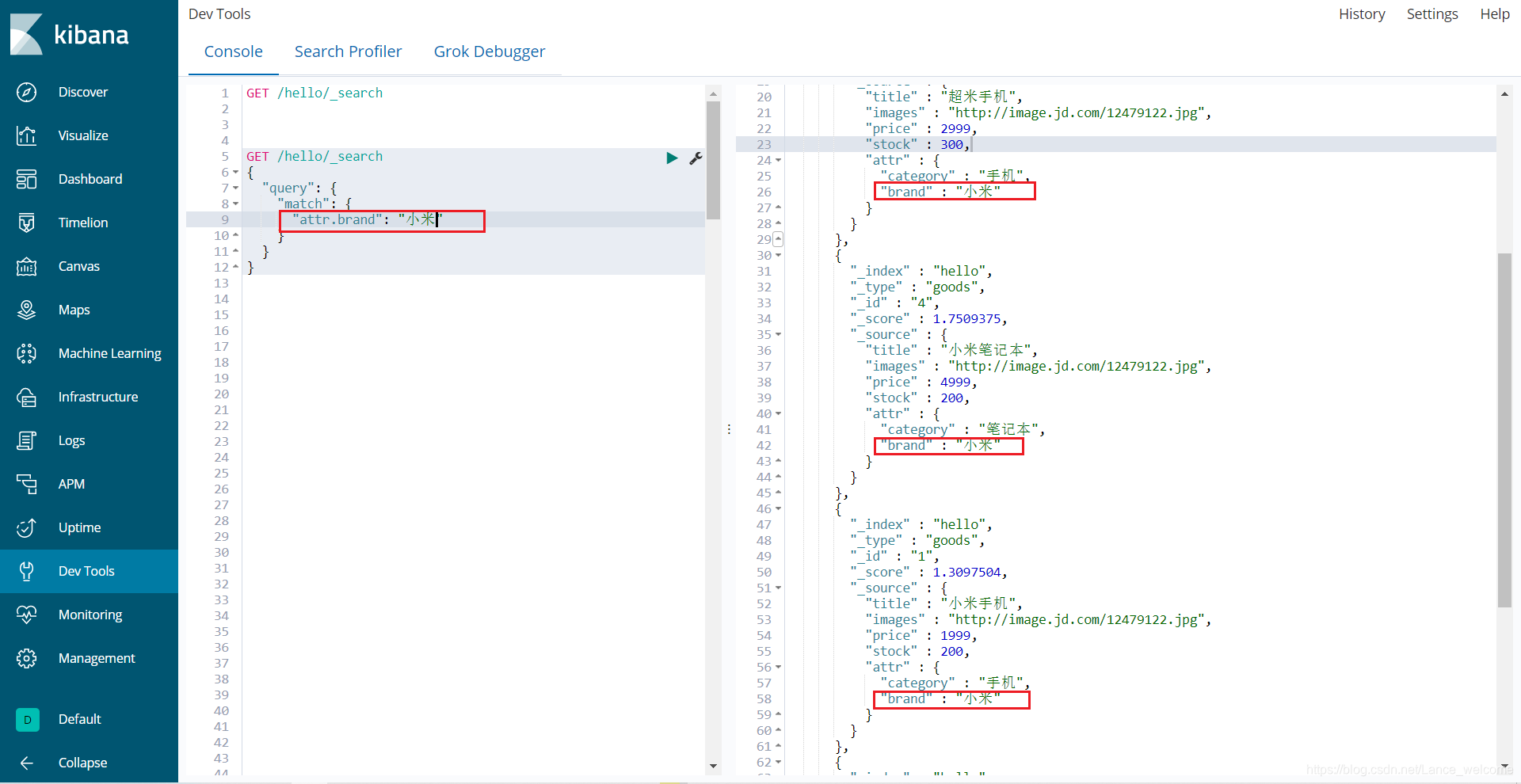
小米手机,而且与小米或者手机相关的都会查询到,说明多个词之间是or的关系。and,可以这样做:GET /hello/_search { "query": { "match": { "title": { "query": "小米手机", "operator": "and" } } } } 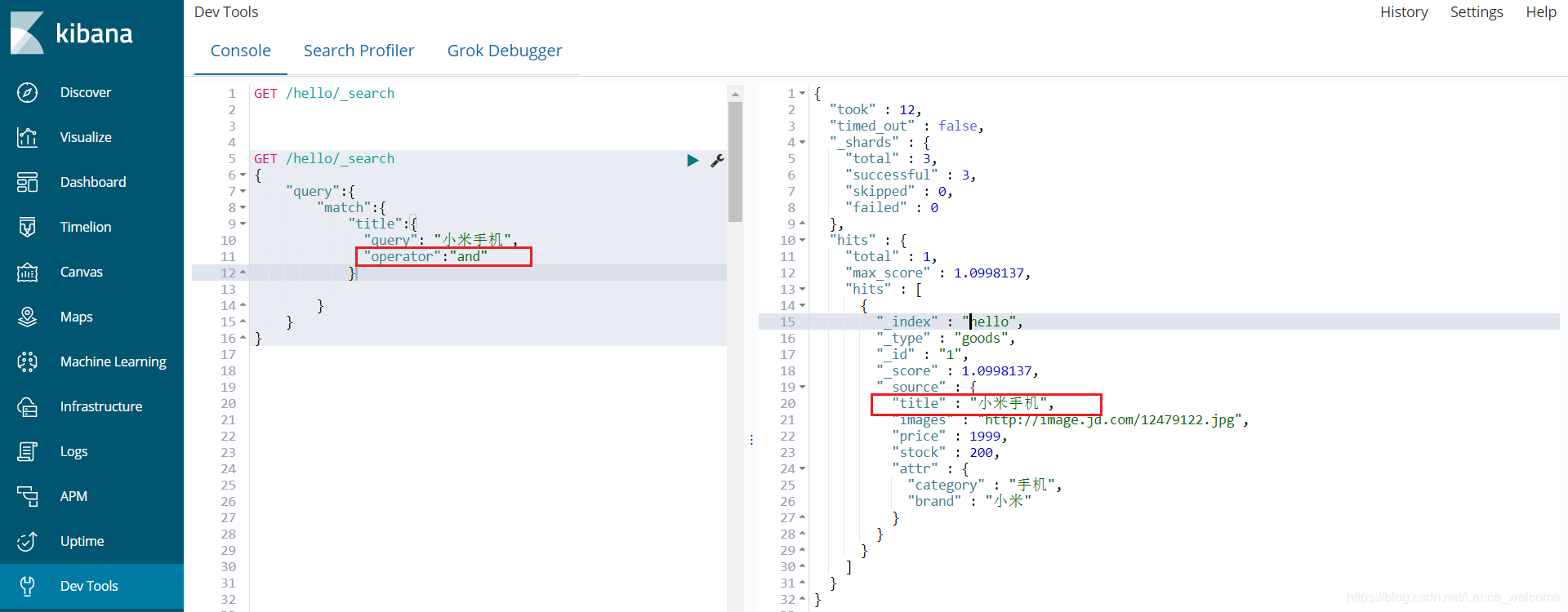
短句匹配
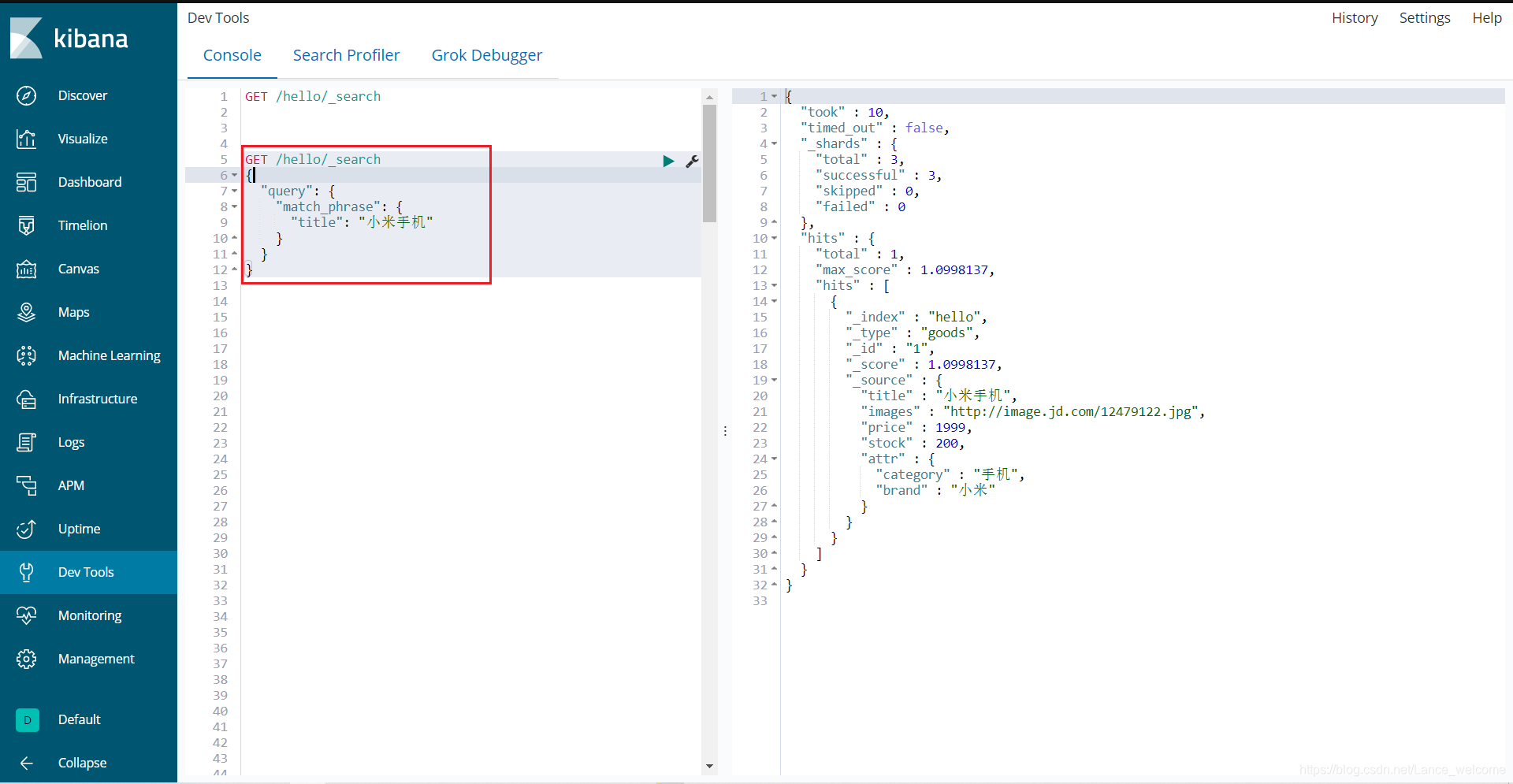
多字段匹配
match只能根据一个字段匹配查询,如果要根据多个字段匹配查询可以使用multi_match
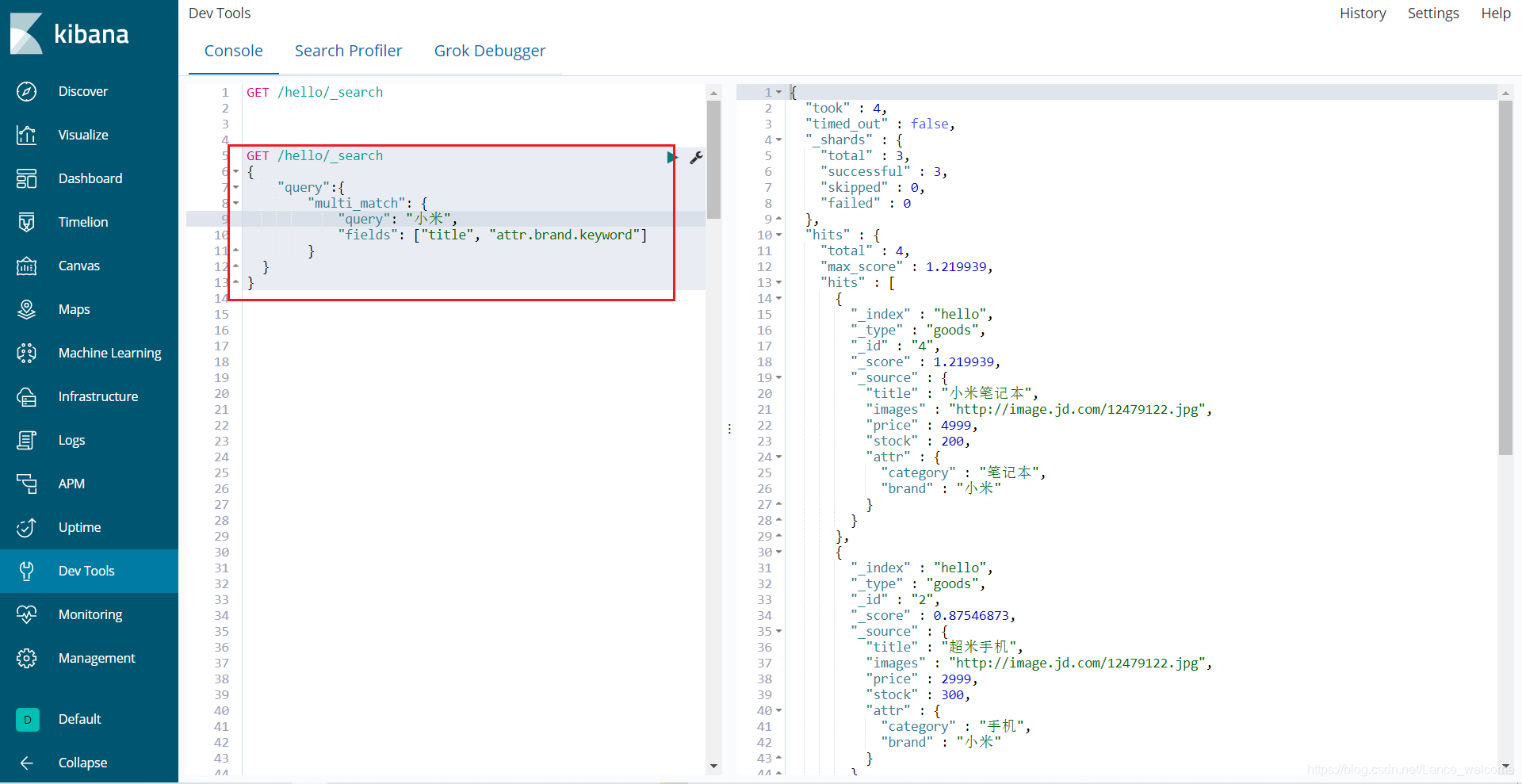
词条查询(term)
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串。GET /hello/_search { "query":{ "term":{ "price": 4999 } } } 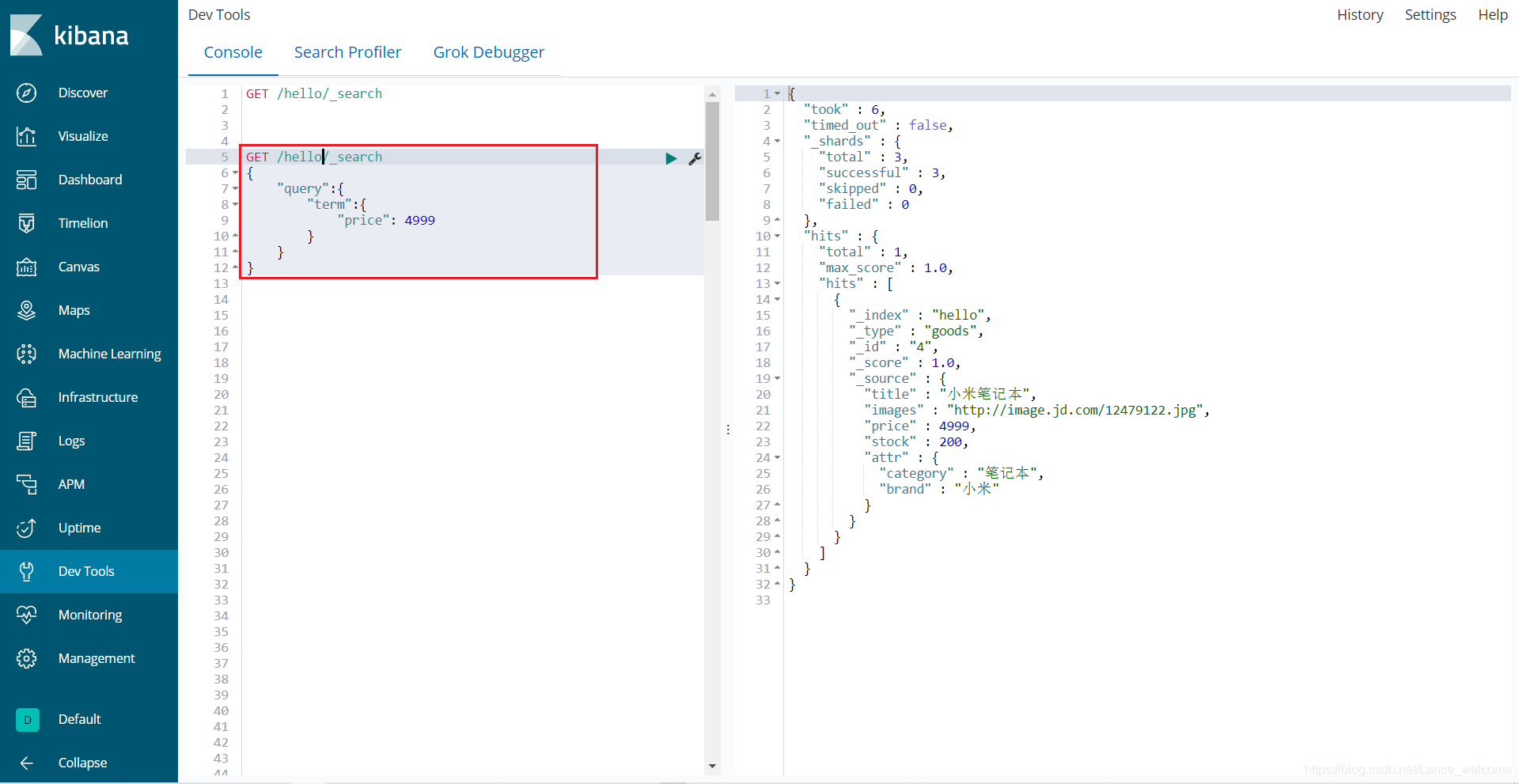
多词条查询
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
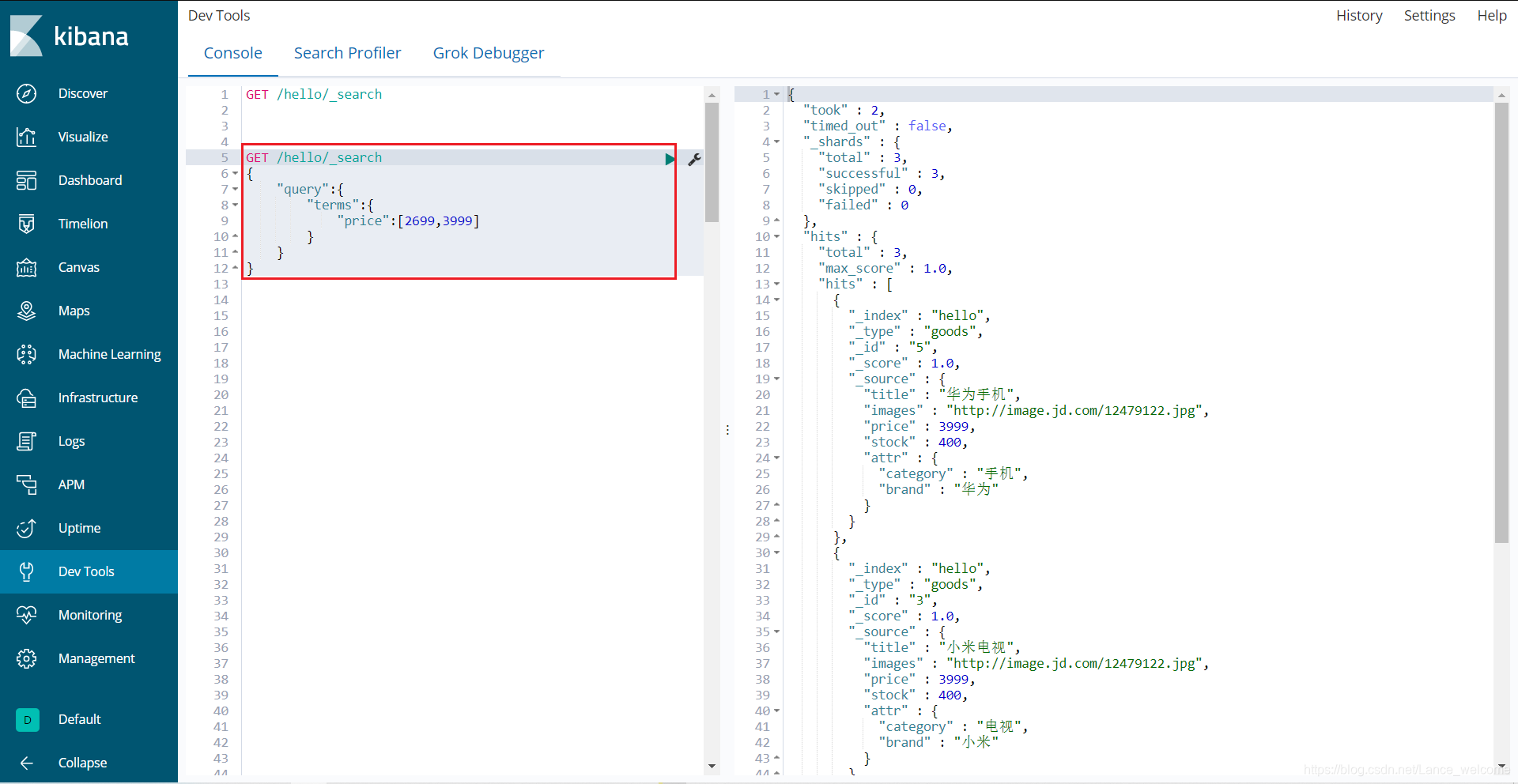
范围查询(range)
range 查询找出那些落在指定区间内的数字或者时间GET /hello/_search { "query":{ "range": { "price": { "gte": 1000, "lt": 3000 } } } } 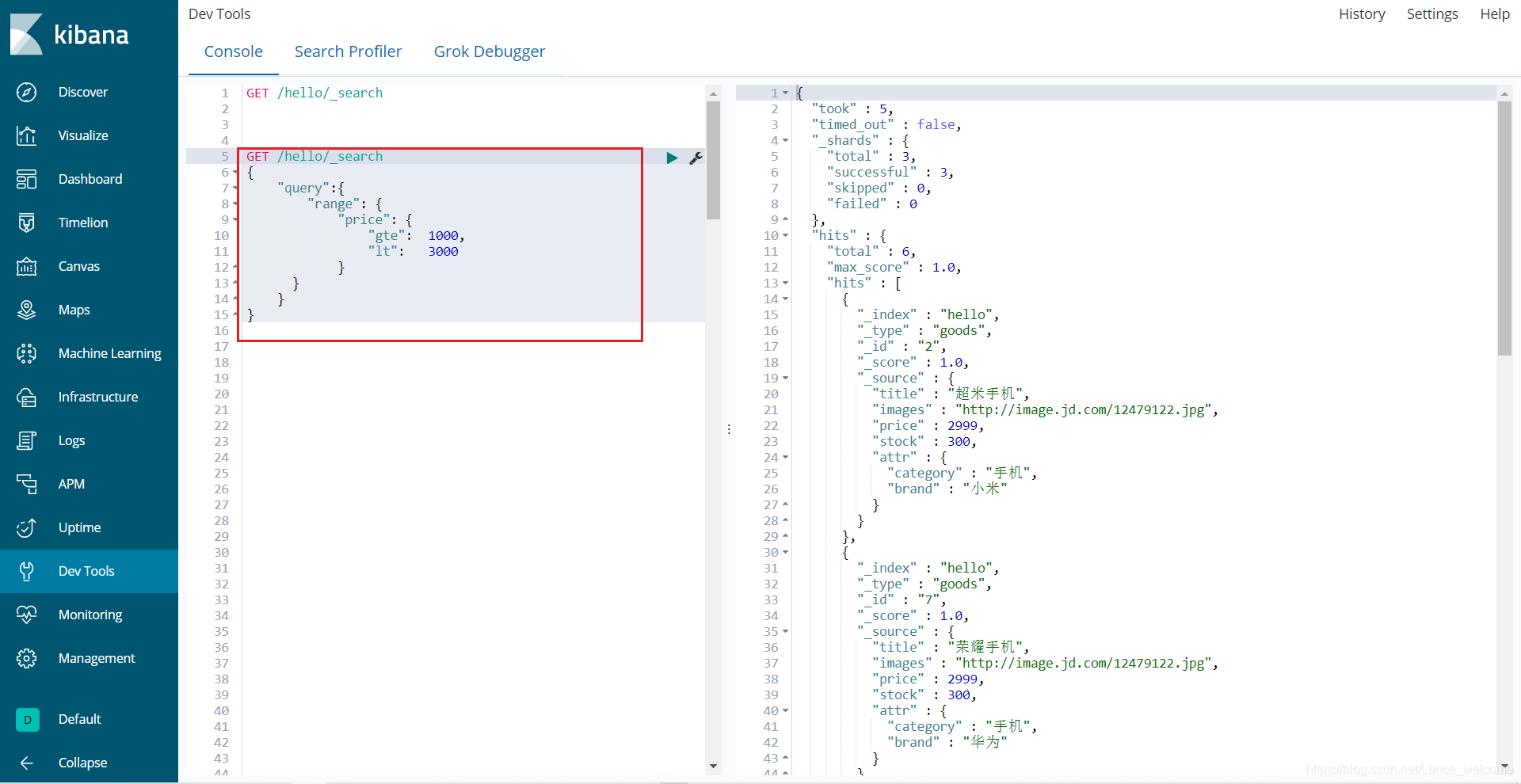
range查询允许以下字符:
操作符
说明
gt
大于
gte
大于等于
lt
小于
lte
小于等于
模糊查询(fuzzy)
fuzzy 允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2:GET /atguigu/_search { "query": { "fuzzy": { "title": "oppe" } } } 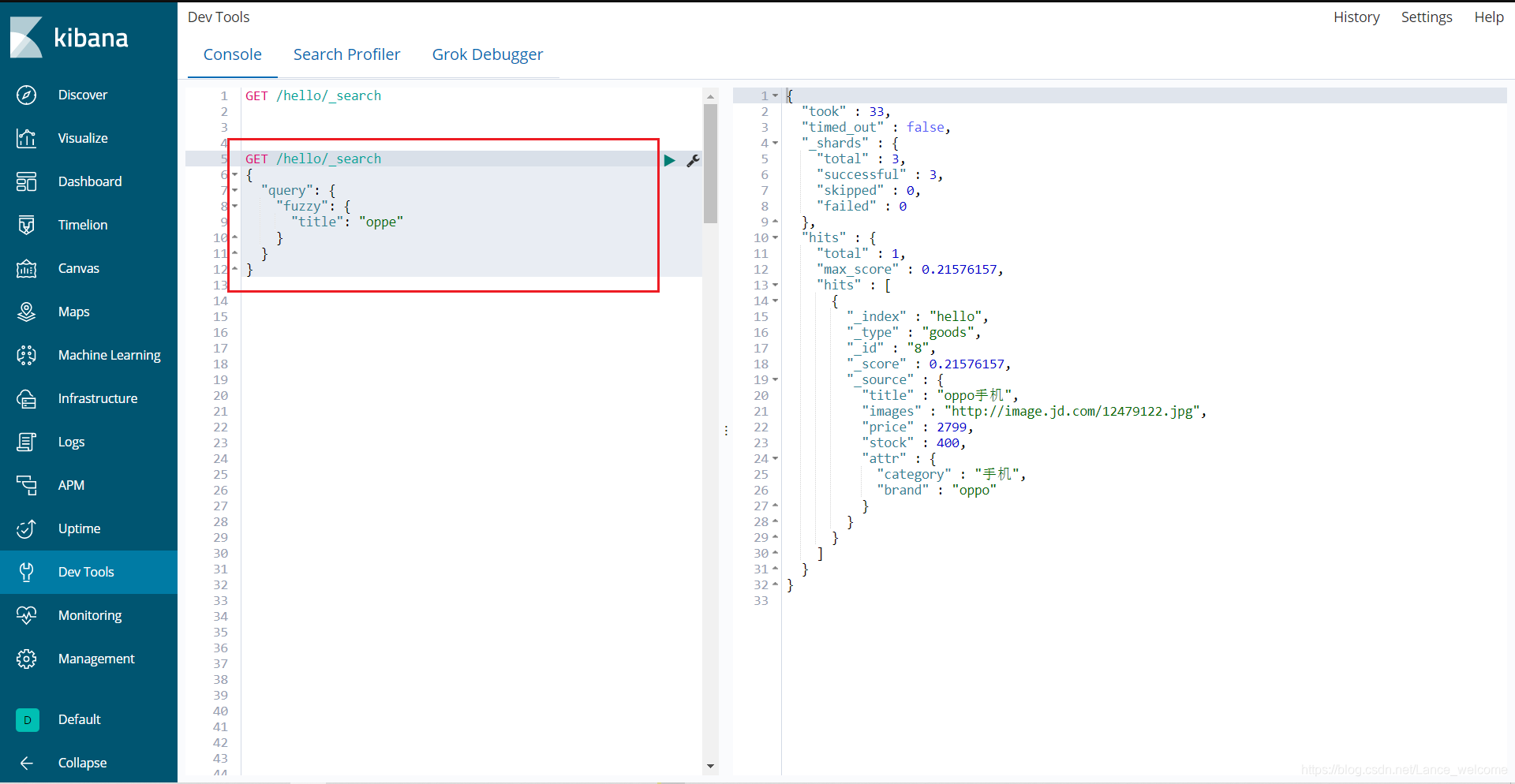
上面的查询,也能查询到apple手机GET /hello/_search { "query": { "fuzzy": { "title": { "value": "oppe", "fuzziness": 1 } } } } fuzziness来指定允许的编辑距离:
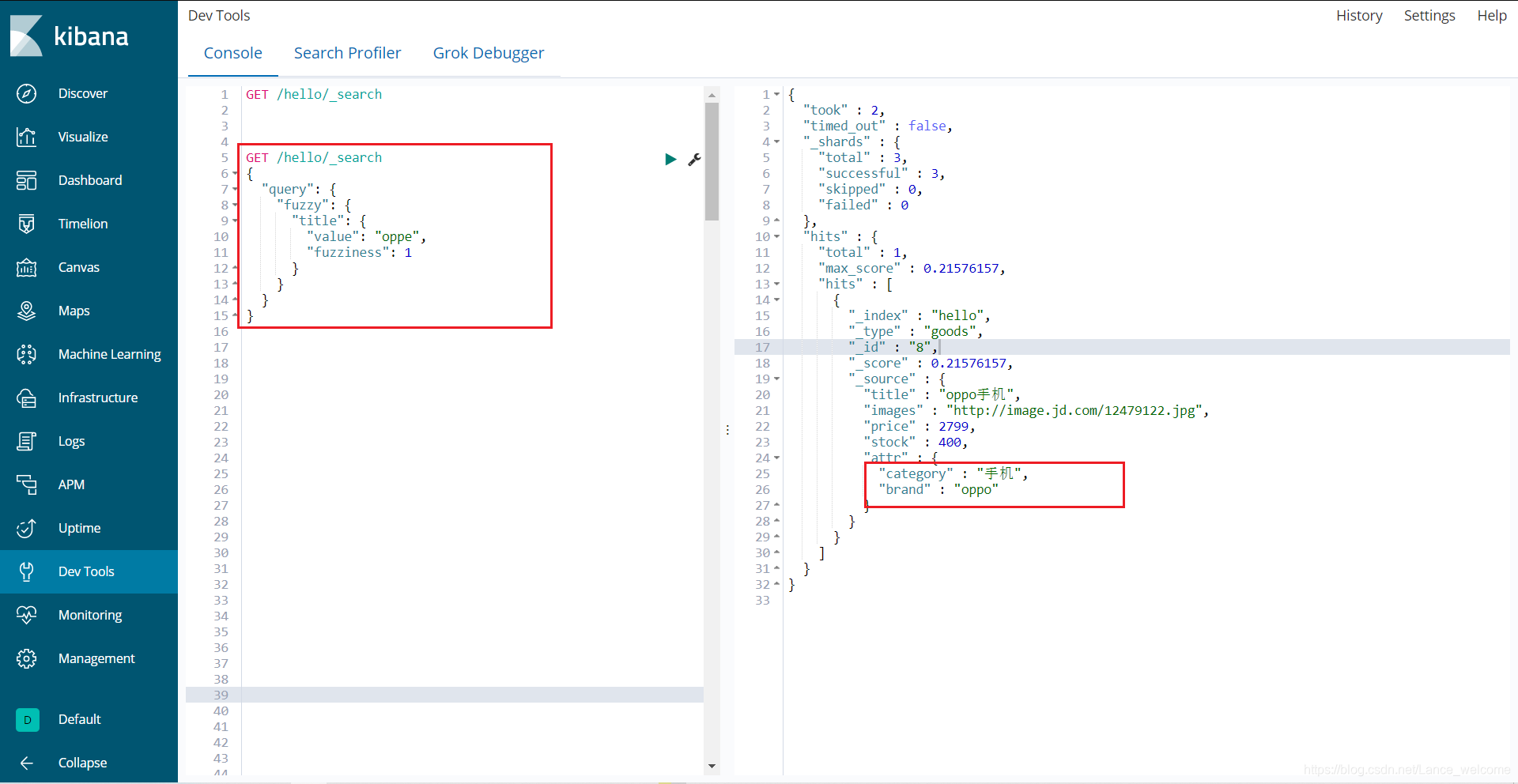
编辑距离:从错误的词到正确词条需要修改的次数。例如:oppe—>oppo,需要修改一次,编辑距离就是1。布尔组合(bool)
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合GET /hello/_search { "query":{ "bool":{ "must": [ { "range": { "price": { "gte": 1000, "lte": 3000 } } }, { "range": { "price": { "gte": 2000, "lte": 4000 } } } ] } } } 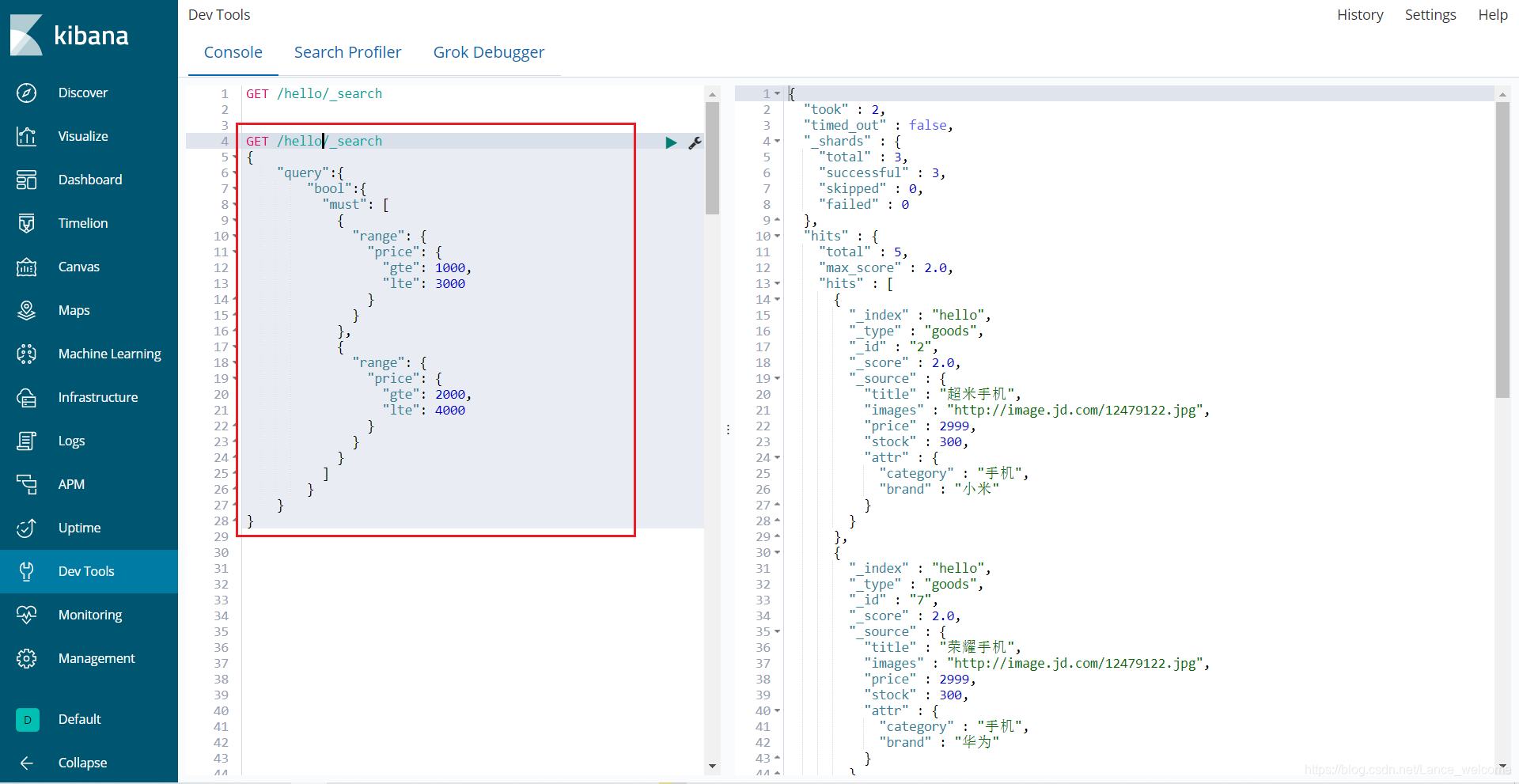
注意:一个组合查询里面只能出现一种组合,不能混用过滤(filter)
filter方式:GET /hello/_search { "query": { "bool": { "must": { "match": { "title": "小米手机" } }, "filter": { "range": { "price": { "gt": 2000, "lt": 3000 } } } } } } 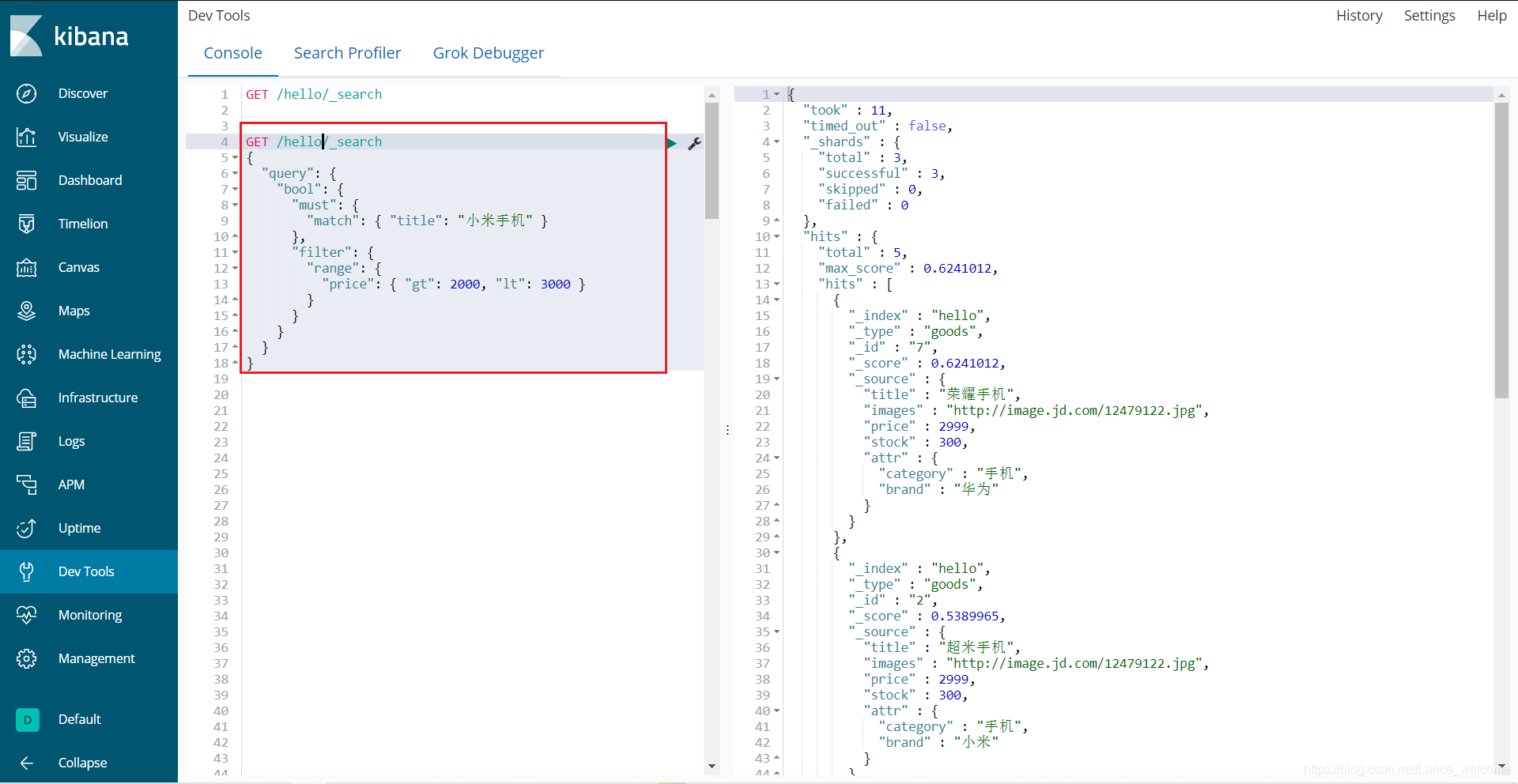
注意:filter中还可以再次进行bool组合条件过滤。排序(sort)
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式GET /hello/_search { "query": { "match": { "title": "小米手机" } }, "sort": [ { "price": { "order": "desc" } }, { "_score": { "order": "desc"} } ] } 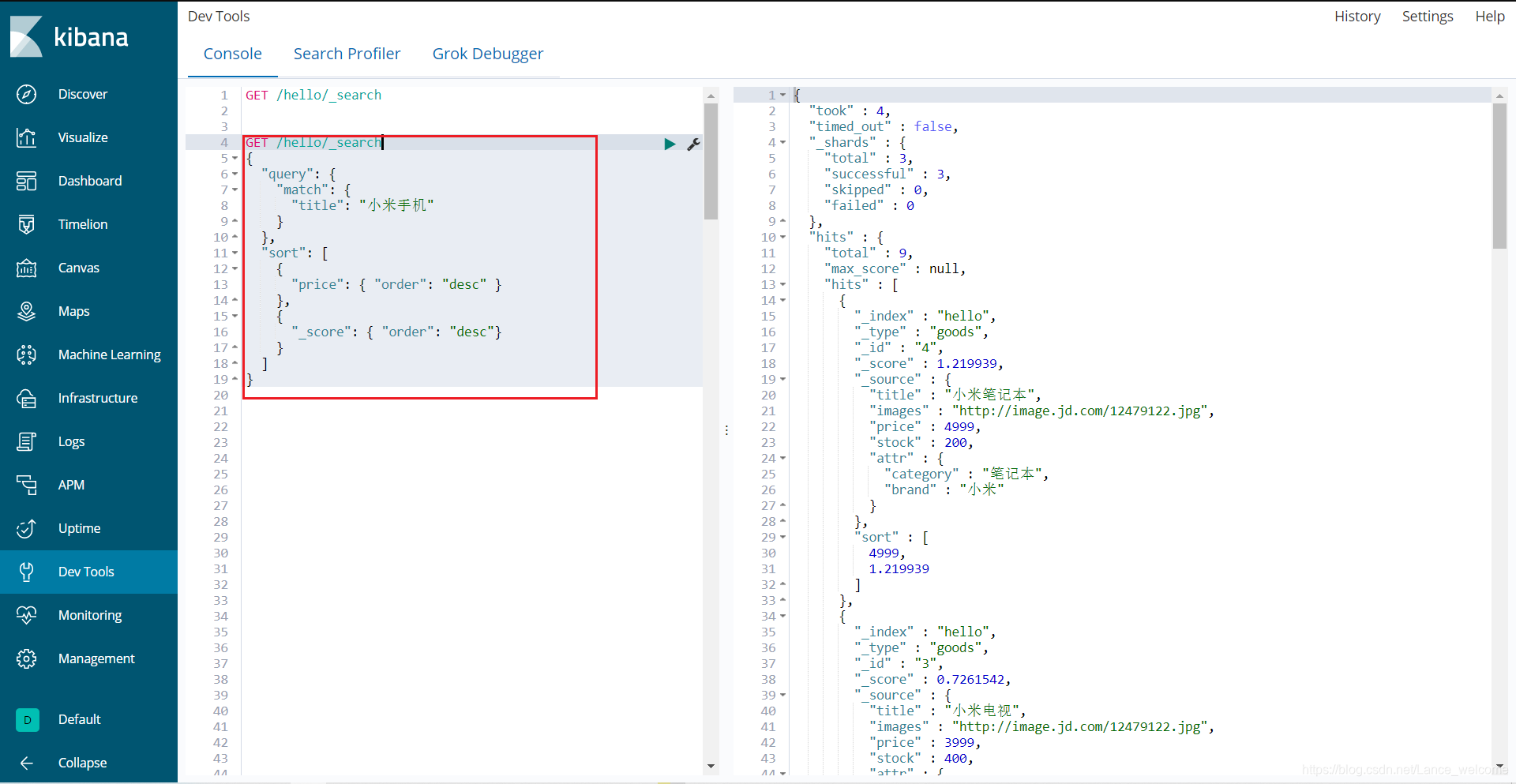
分页(from/size)
GET /hello/_search { "query": { "match": { "title": "小米手机" } }, "from": 2, "size": 2 } 高亮(highlight)
发现:高亮的本质是给关键字添加了<em>标签,在前端再给该标签添加样式即可。
GET /hello/_search { "query": { "match": { "title": "小米" } }, "highlight": { "fields": {"title": {}}, "pre_tags": "<em>", "post_tags": "</em>" } } 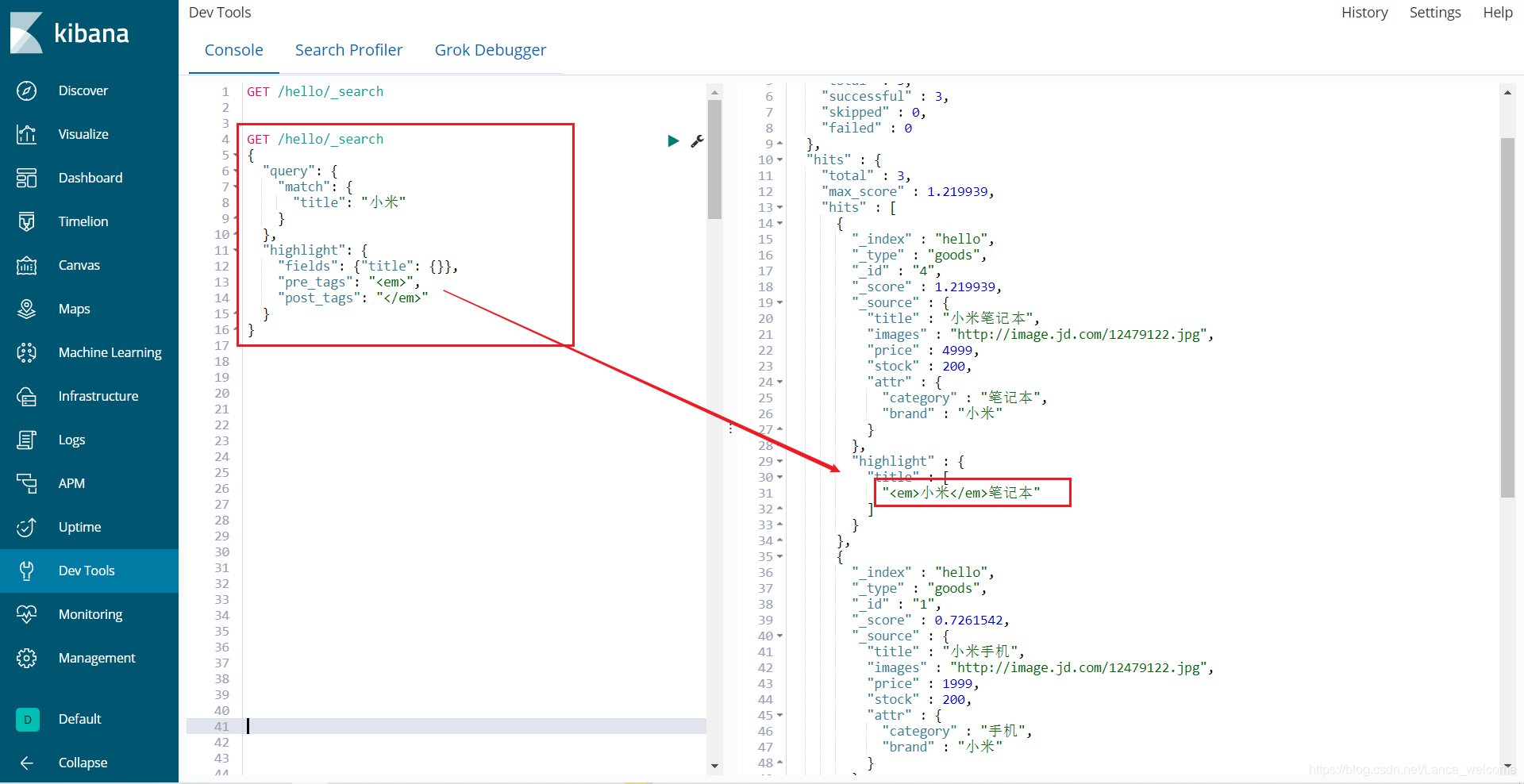
fields:高亮字段结果过滤(_source)
_source的所有字段都返回。_source的过滤GET /hello/_search { "_source": ["title","price"], "query": { "term": { "price": 2699 } } } 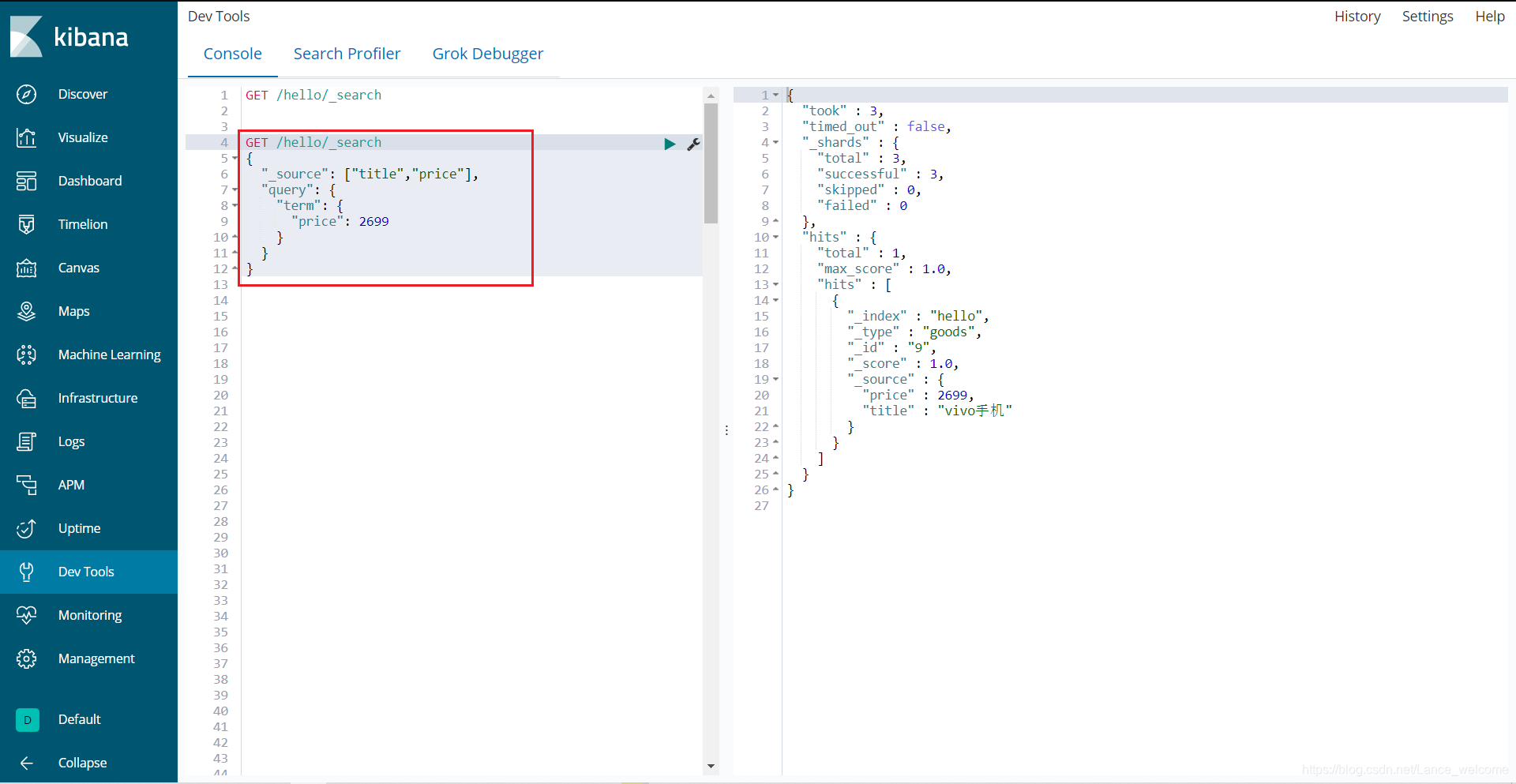
返回结果,只有两个字段:聚合(aggregations)
基本概念
桶,一个叫度量:桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
度量
聚合为桶
attr.brand.keyword来划分桶GET /hello/_search { "size" : 0, "aggs" : { "brands" : { "terms" : { "field" : "attr.brand.keyword" } } } } 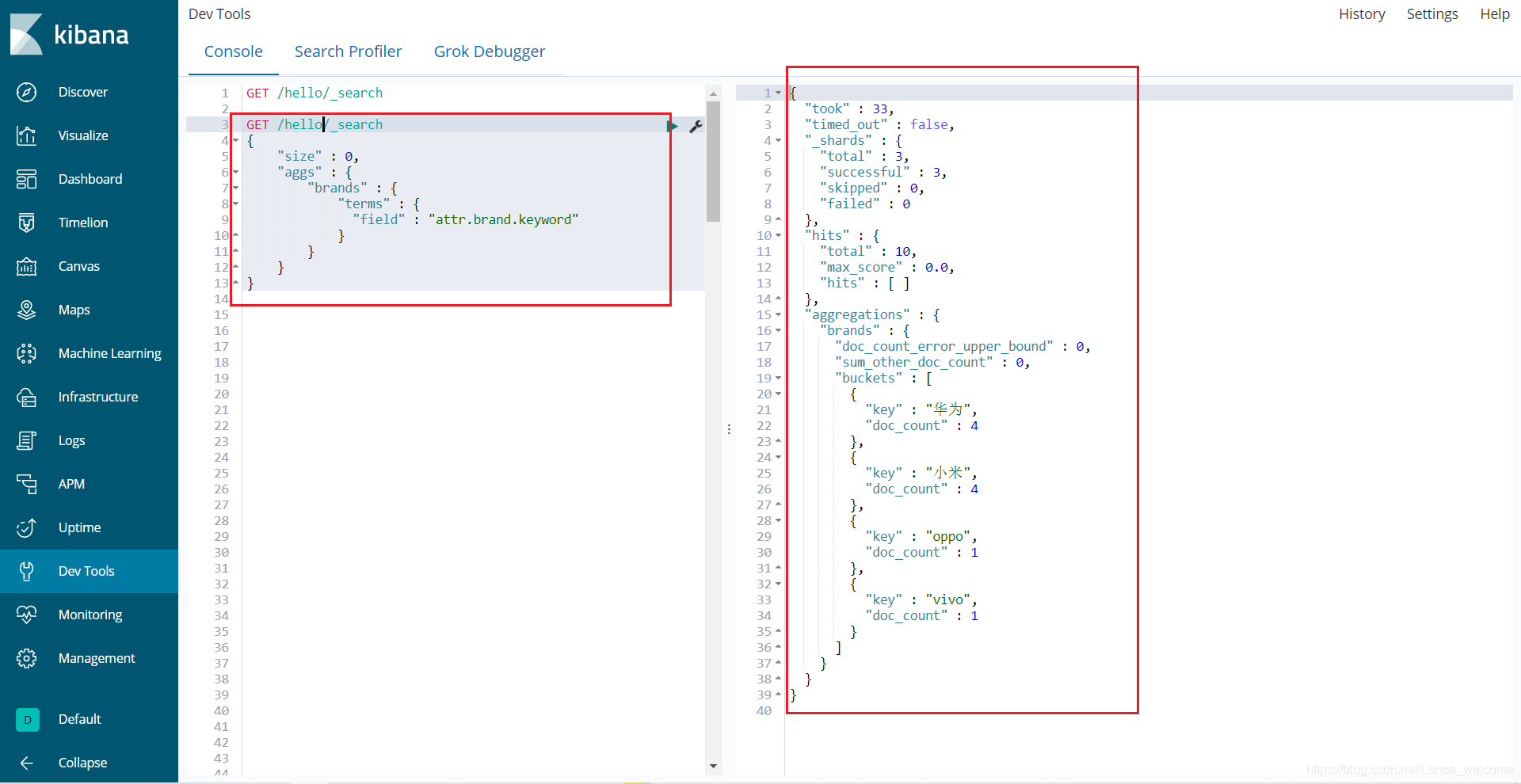
桶内度量
使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行GET /hello/_search { "size" : 0, "aggs" : { "brands" : { "terms" : { "field" : "attr.brand.keyword" }, "aggs":{ "avg_price": { "avg": { "field": "price" } } } } } } 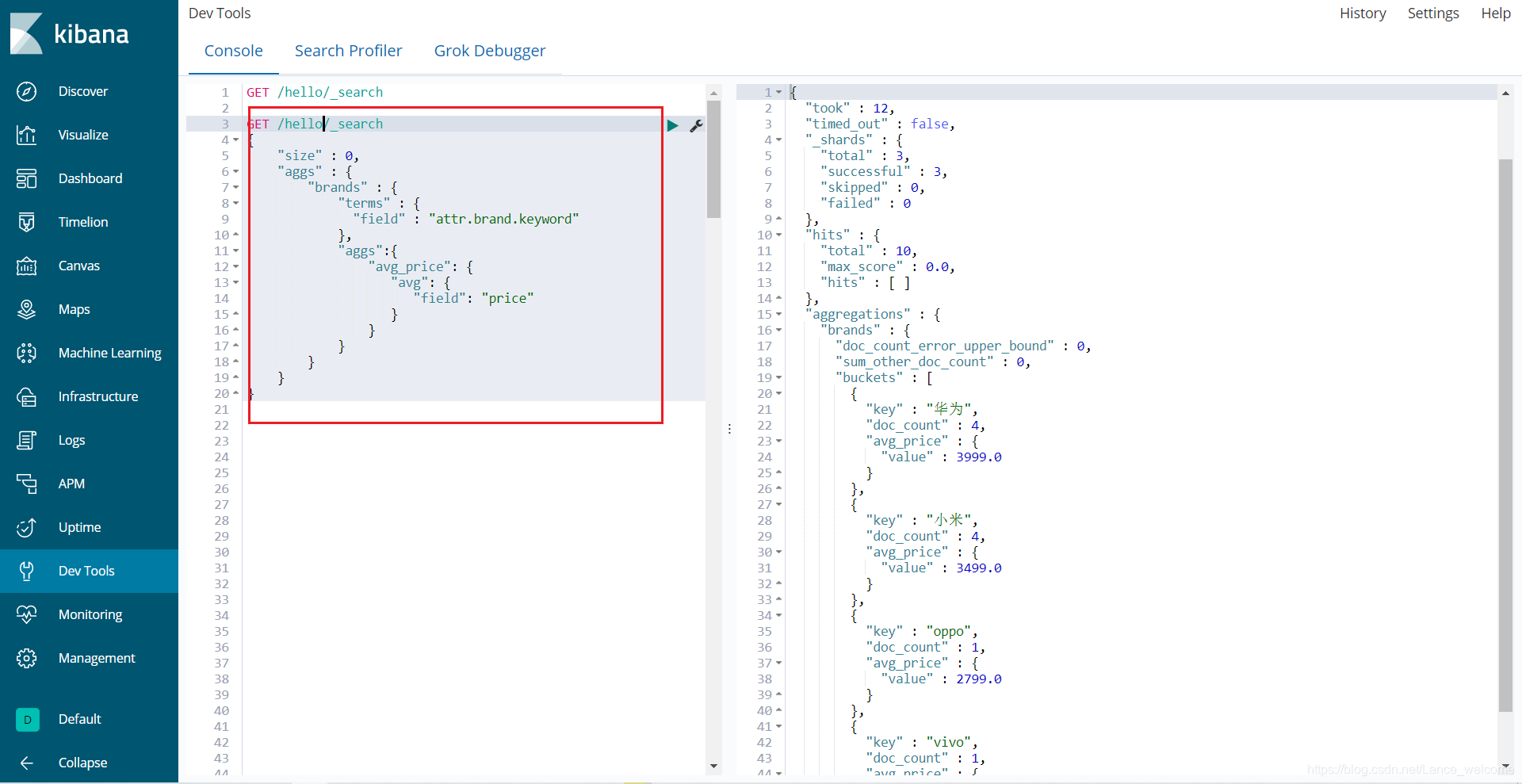
度量也是一个聚合桶内嵌套桶
attr.category.keyword字段再进行分桶GET /hello/_search { "size" : 0, "aggs" : { "brands" : { "terms" : { "field" : "attr.brand.keyword" }, "aggs":{ "avg_price": { "avg": { "field": "price" } }, "categorys": { "terms": { "field": "attr.category.keyword" } } } } } } 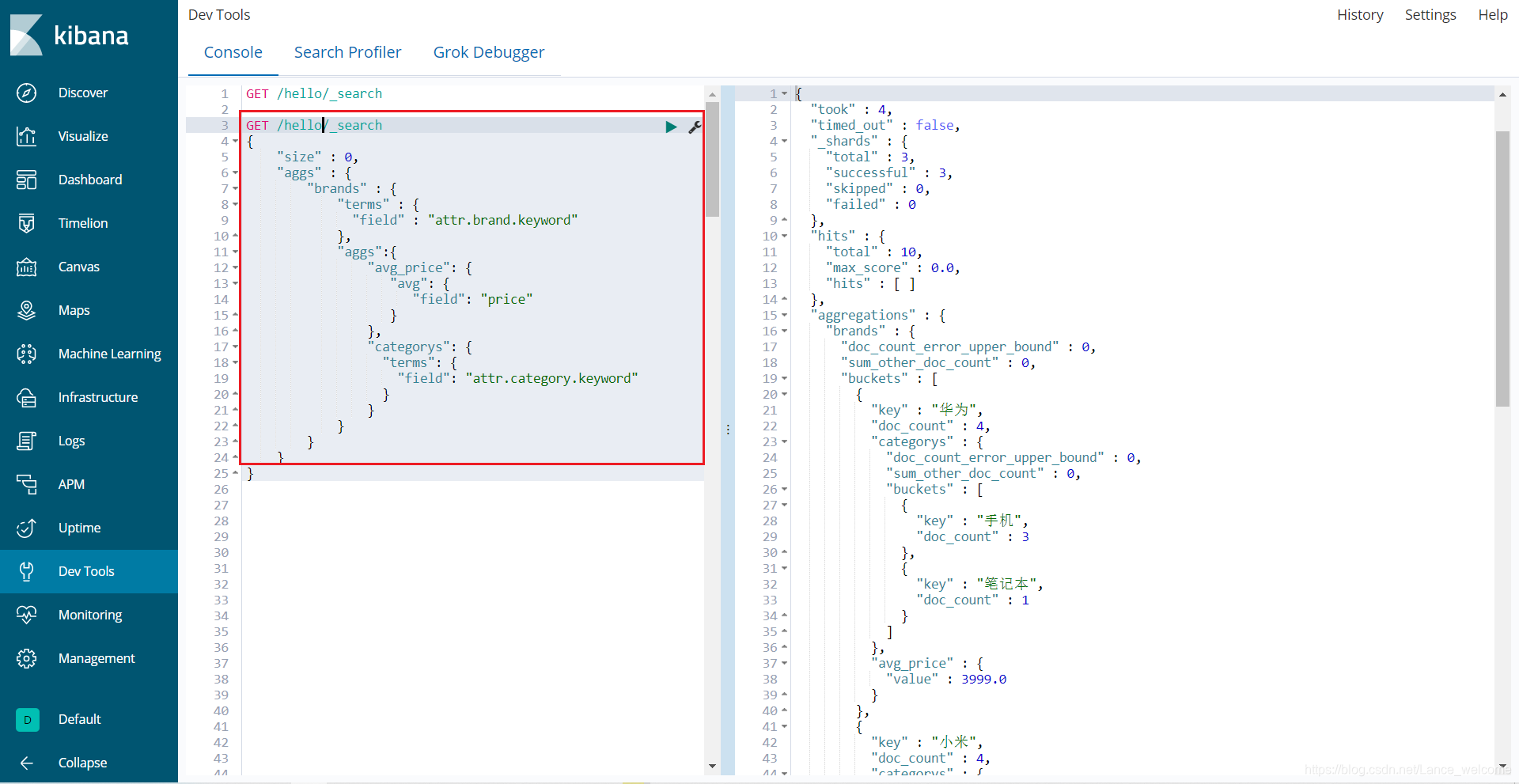
categorys被嵌套在原来每一个brands的桶中。attr.category.keyword字段进行了分组
Java客户端(jest)
<!-- Java 操作 elasticsearch 的客户端 --> <dependency> <groupId>io.searchbox</groupId> <artifactId>jest</artifactId> <version>6.3.1</version> </dependency> <!-- elasticsearch 驱动包 --> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.8.3</version> </dependency>

3. 在application.properties中添加配置# 指定连接 es 的服务器IP + prop spring.elasticsearch.jest.uris=http://192.168.230.204:9200 # jest 客户端连接 es 的超时时间 spring.elasticsearch.jest.connection-timeout=10S # jest 客户端操作 es 时的超时时间 spring.elasticsearch.jest.read-timeout=5s # 集群情况下 #spring.elasticsearch.jest.uris[0]=http://192.168.230.204:9200 #spring.elasticsearch.jest.uris[1]=http://192.168.230.204:9200
public class User { private String username; private String password; private Integer age; }
添加
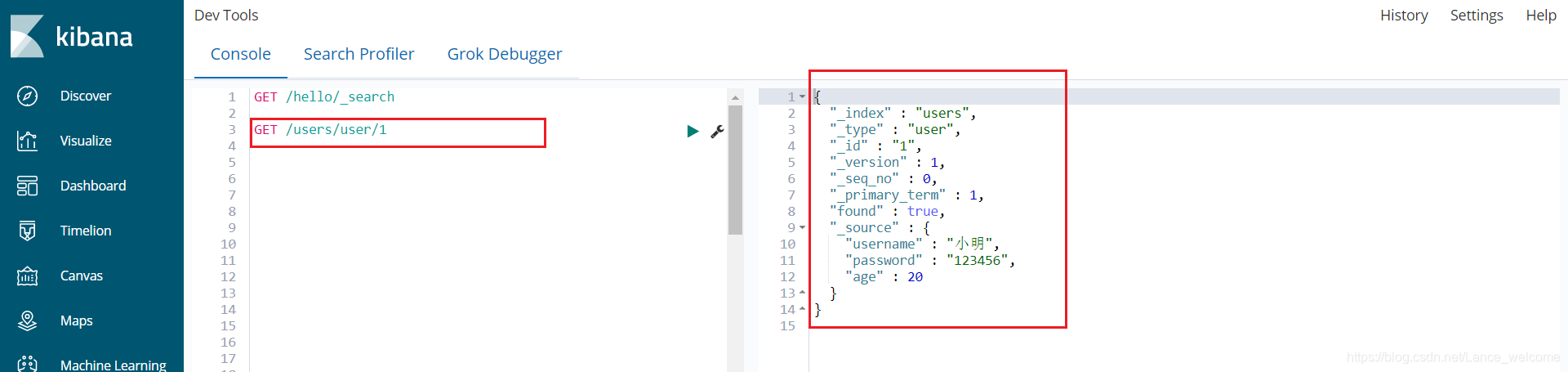
@Test public void insert() throws IOException { User user = new User("小明", "123456", 20); // index : 表示索引库, type : 指定表名, id : 插入数据的 id 值 [如果不写,会默认生成一个uuid] Index action = new Index.Builder(user).index("users").type("user").id("1").build(); DocumentResult result = jestClient.execute(action); System.out.println("result = " + result.toString()); } 结果 : result = Result: {"_index":"users","_type":"user","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}, isSucceeded: true, response code: 201, error message: null
更新
@Test public void update() throws IOException { User user = new User("小明", "1949688", 26); Index action = new Index.Builder(user).index("users").type("user").id("1").build(); DocumentResult result = jestClient.execute(action); System.out.println("result = " + result.toString()); } 结果 : result = Result: {"_index":"users","_type":"user","_id":"1","_version":3,"result":"updated","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1}, isSucceeded: true, response code: 200, error message: null 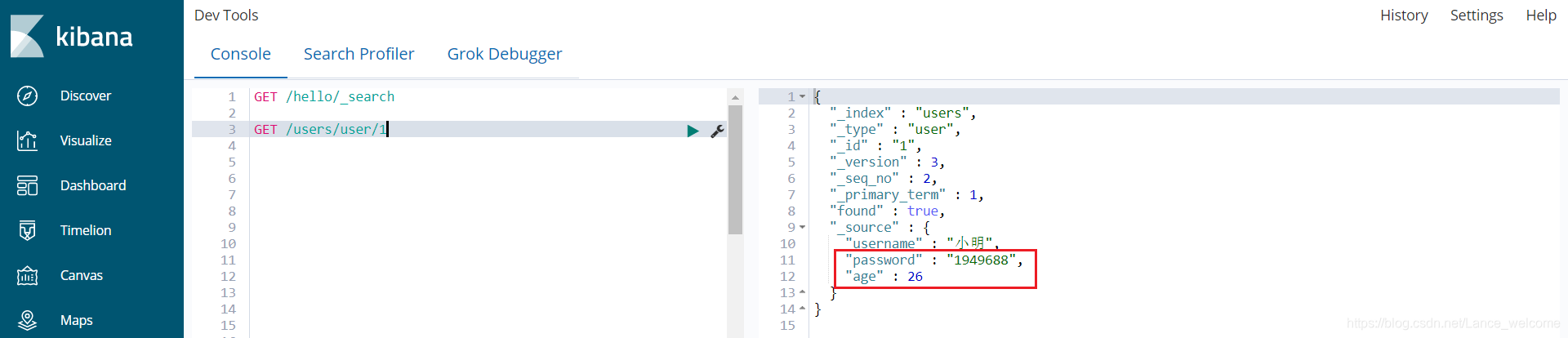
查询
@Test public void query() throws IOException { // 查询表达式 String query="{n" + " "query": {n" + " "match_all": {}n" + " }n" + "}"; Search action = new Search.Builder(query).addIndex("users").addType("user").build(); SearchResult result = jestClient.execute(action); // 直接获取到结果集 List<User> userList = result.getSourceAsObjectList(User.class, false); System.out.println("userList = " + userList); System.out.println("-----------------------------------------------------------------"); // 获取查询到的结果集和其它信息 List<SearchResult.Hit<User, Void>> hits = result.getHits(User.class); hits.forEach(hit -> { System.out.println("hit.source = " + hit.source); }); } 结果 : userList = [User{username='小明', password='1949688', age=26}] ----------------------------------------------------------------- hit.source = User{username='小明', password='1949688', age=26} @Test public void queryById() throws IOException { Get user = new Get.Builder("users", "1").build(); DocumentResult result = jestClient.execute(user); System.out.println("result = " + result); } 结果: result = Result: {"_index":"users","_type":"user","_id":"1","_version":3,"_seq_no":2,"_primary_term":1,"found":true,"_source":{"username":"小明","password":"1949688","age":26}}, isSucceeded: true, response code: 200, error message: null 删除
@Test public void delete() throws IOException { Delete action = new Delete.Builder("1").index("users").type("user").build(); DocumentResult result = jestClient.execute(action); System.out.println(result.toString()); } 
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 14万+
14万+