大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语— 此篇为大家带来的是Oozie的简单介绍及部署。 此部分所需jar包等博主已经打包上传到百度云如有需要,请自行下载 顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个) 定时触发workflow 绑定多个Coordinator 下图为Oozie定义的工作流程 控制流节点一般都是定义在工作流开始或者结束的位置,比如start,end,kill等。以及提供工作流的执行路径机制,如decision,fork,join等。 负责执行具体动作的节点,比如:拷贝文件,执行某个Shell脚本等等。 部署Oozie用的是CDH版本的。因为阿帕奇官网给的Oozie只有原始版版本的需要编译才能进行使用。 https://hadoop002:11000/oozie 本次的就到这里了, 好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
链接:https://pan.baidu.com/s/1H3BvKEftWKitjDf2EhX44g
提取码:96a7

一. 什么是Oozie

Oozie英文翻译为:驯象人。一个基于工作流引擎的开源框架,由Cloudera公司贡献给Apache,提供对Hadoop MapReduce、Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。主要用于定时调度任务,多任务可以按照执行的逻辑顺序调度。二. Oozie的功能模块介绍
2.1 模块

2.2 常用节点
三. Oozie的部署
3.1 部署Hadoop(CDH版本)
1. 上传及解压缩

[bigdata@hadoop002 oozie]$ mkdir /opt/module/cdh [bigdata@hadoop002 oozie]$ tar -zxvf hadoop-2.5.0-cdh5.3.6.tar.gz -C /opt/module/cdh/ 
/opt/module/cdh/hadoop-2.5.0-cdh5.3.62. 修改Hadoop配置
[bigdata@hadoop002 hadoop]$ vim slaves // 需要添加的内容 hadoop002 hadoop003 hadoop004
// 首先先获取 JAVA_HOME [bigdata@hadoop002 hadoop]$ echo $JAVA_HOME /opt/module/jdk1.8.0_144 // 所要修改的部分 export JAVA_HOME=/opt/module/jdk1.8.0_144 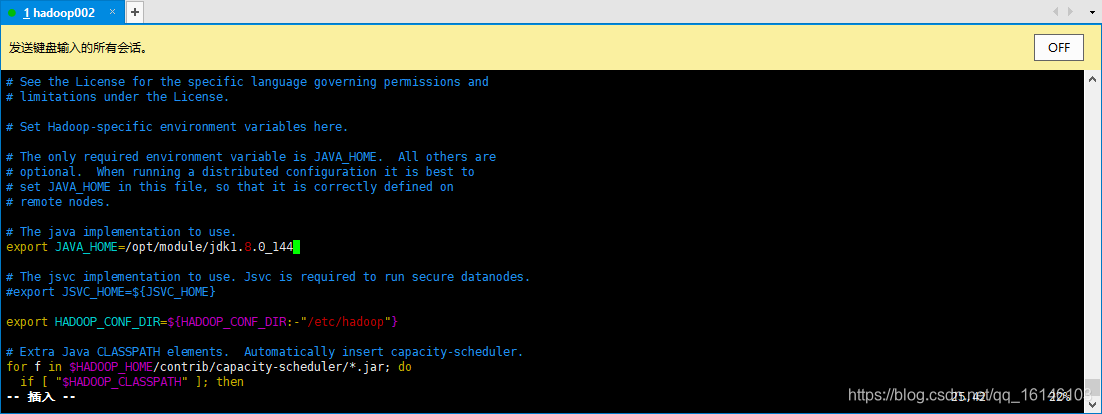
// 同 export JAVA_HOME=export JAVA_HOME=/opt/module/jdk1.8.0_144 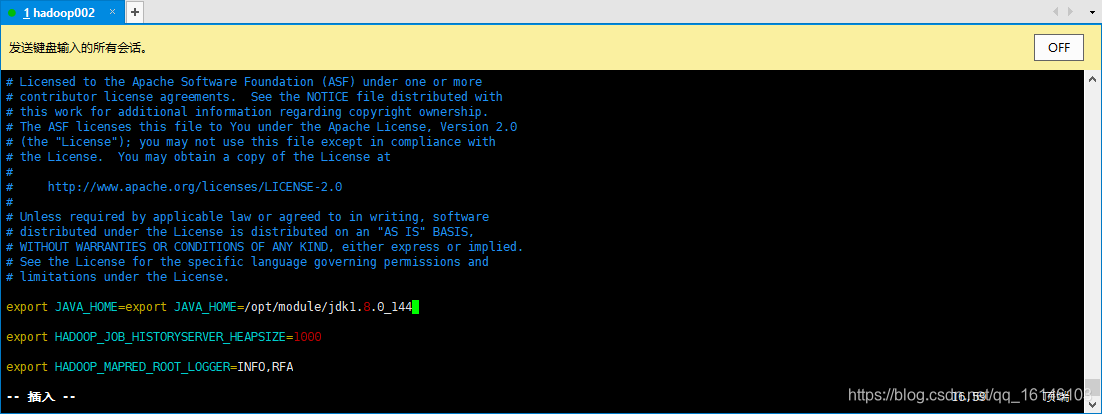
// 改这一行 export JAVA_HOME=/opt/module/jdk1.8.0_144 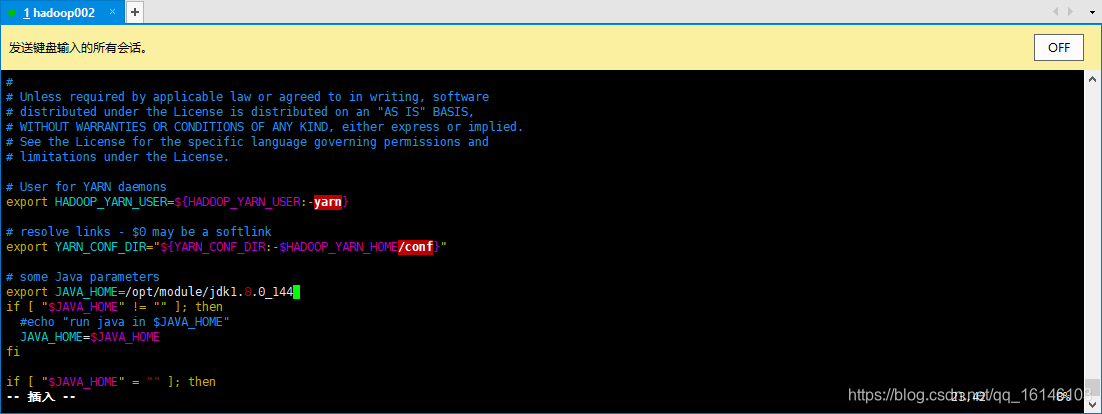
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop002:8020</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/cdh/hadoop-2.5.0-cdh5.3.6/data/tmp</value> </property> <!-- Oozie Server的Hostname --> <property> <name>hadoop.proxyuser.bigdata.hosts</name> <value>*</value> </property> <!-- 允许被Oozie代理的用户组 --> <property> <name>hadoop.proxyuser.bigdata.groups</name> <value>*</value> </property> </configuration> 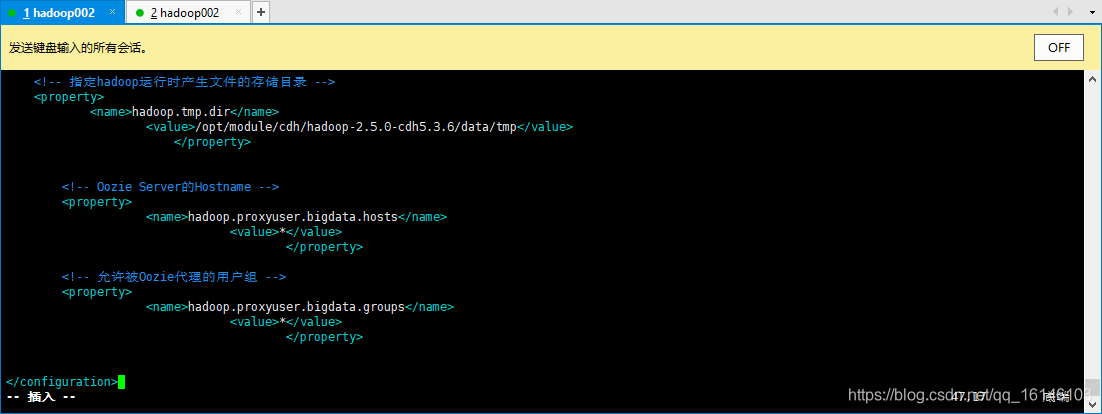
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop004:50090</value> </property> </configuration>
// 先修改文件名 [bigdata@hadoop002 hadoop]$ mv mapred-site.xml.template mapred-site.xml <configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop002:10020</value> </property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop002:19888</value> </property> </configuration>
<configuration> <!-- Site specific YARN configuration properties --> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop003</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 任务历史服务 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop002:19888/jobhistory/logs/</value> </property> </configuration>
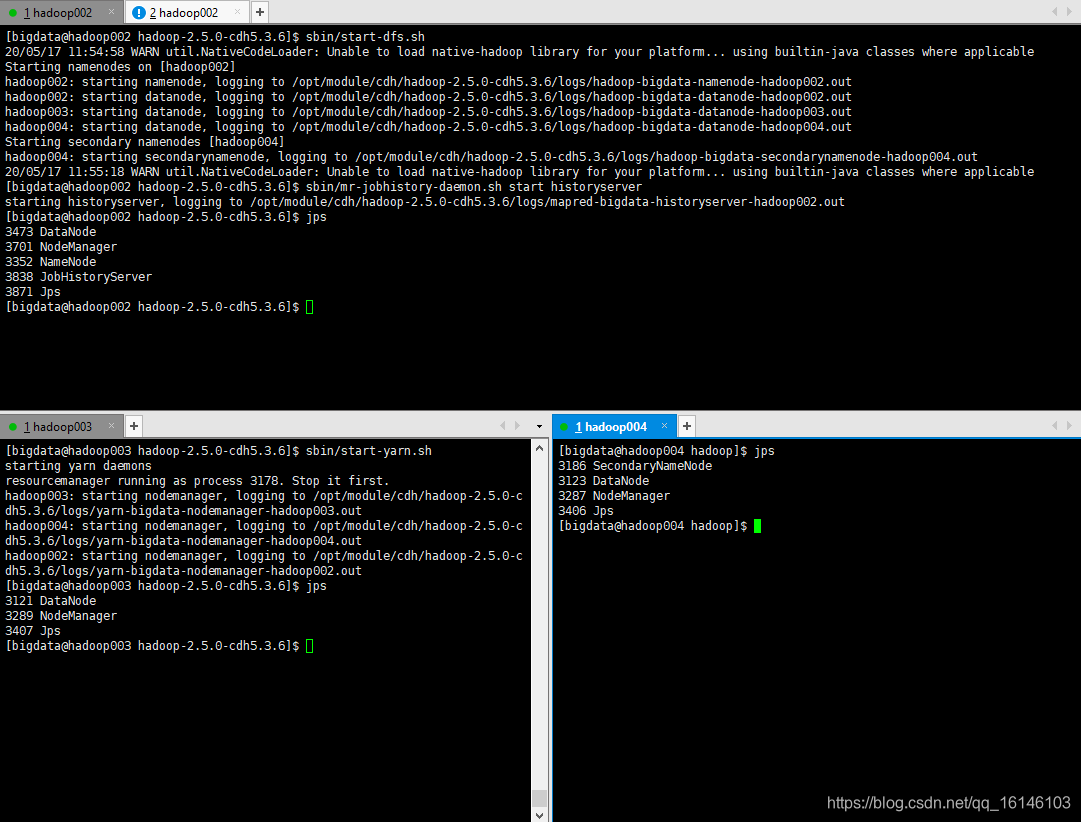
// 首次启动需要格式化namenode [bigdata@hadoop002 hadoop]$ cd /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/ [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hdfs namenode -format // 都要格式化 // 正常情况下是不会出现其他状况的直接成功 // 重启Hadoop集群 // 注意:需要开启JobHistoryServer, 最好执行一个MR任务进行测试。 [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ sbin/start-dfs.sh [bigdata@hadoop003 hadoop-2.5.0-cdh5.3.6]$ sbin/start-yarn.sh [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ sbin/mr-jobhistory-daemon.sh start historyserver 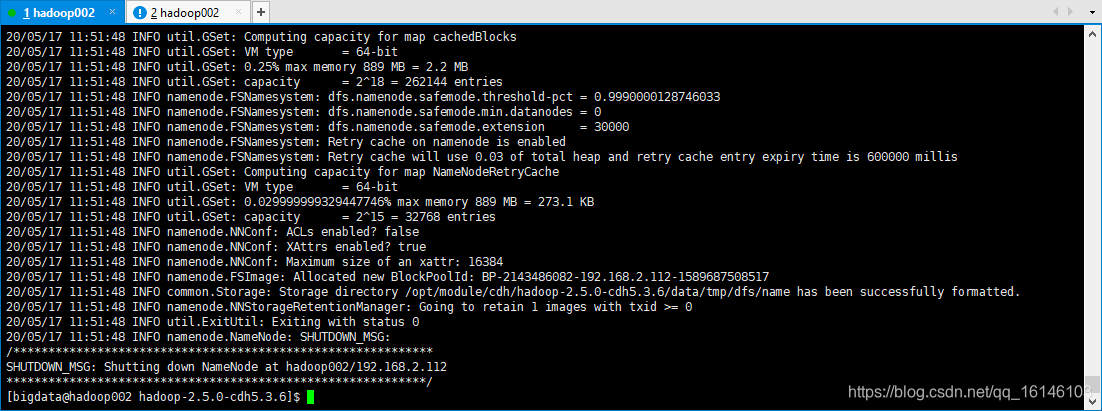
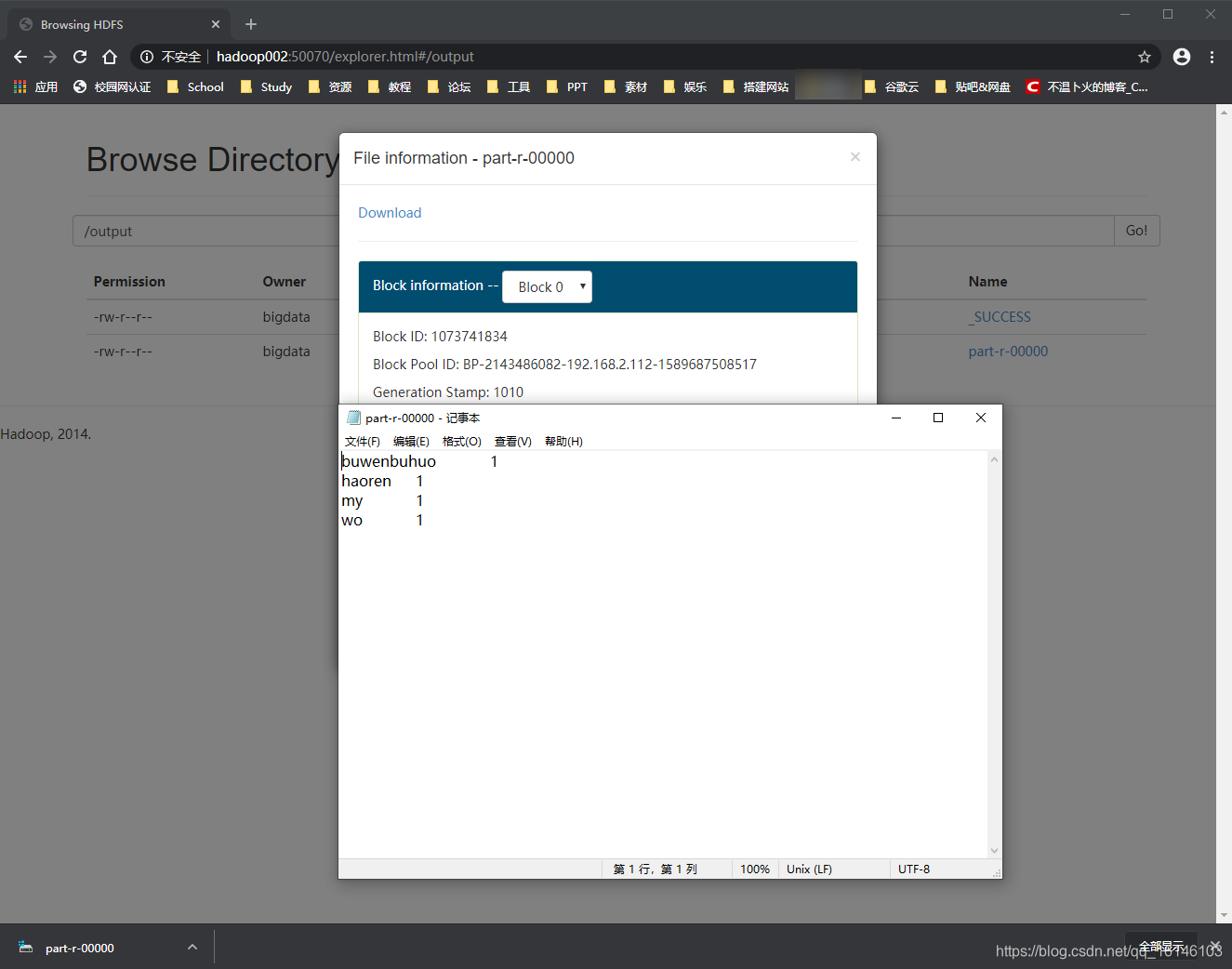
// 测试 // 1. 创建文件(hdfs) [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop fs -mkdir /input // 创建文档 [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ vim buwenbuhuo.txt // 填写内容 my buwenbuhuo wo haoren // 上传到HDFS上 [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop fs -put buwenbuhuo.txt /input // 运行例子 [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /input /output 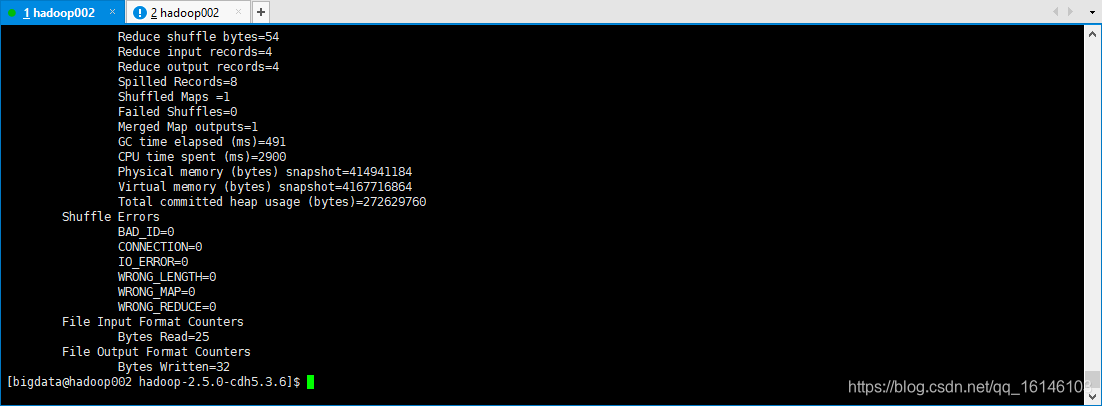
3.2 部署Oozie
1. 解压Oozie
[bigdata@hadoop002 software]$ tar -zxvf software/oozie/oozie-4.0.0-cdh5.3.6.tar.gz -C ./ 
2. 在oozie根目录下解压oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz
// 完成后Oozie目录下会出现hadooplibs目录。 [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ tar -zxvf oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz -C ../ 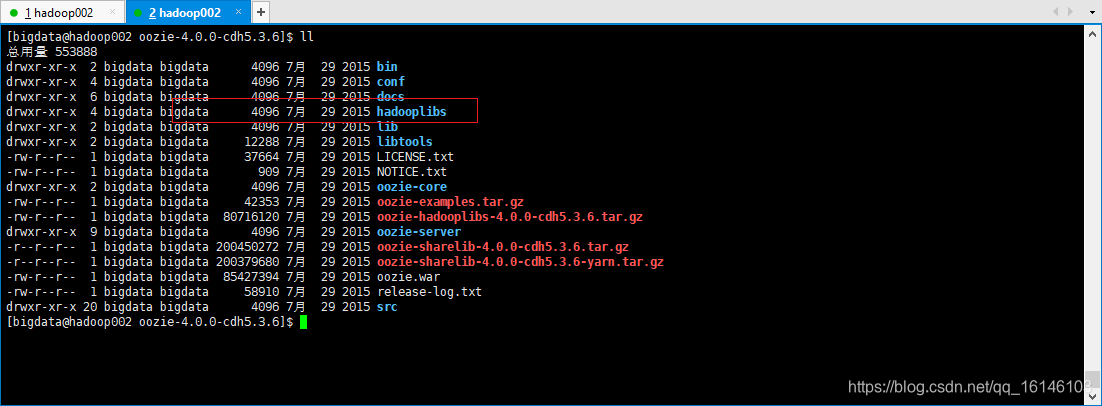
3. 在Oozie目录下创建libext目录
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ mkdir libext/ 4. 拷贝依赖的Jar包
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ cp hadooplibs/hadooplib-2.5.0-cdh5.3.6.oozie-4.0.0-cdh5.3.6/* libext/
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ cp /opt/software/oozie/mysql-connector-java-5.1.27-bin.jar libext/ 5. 将ext-2.2.zip拷贝到libext/目录下
// ext是一个js框架,用于展示oozie前端页面 [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ cp /opt/software/oozie/ext-2.2.zip libext/ 6. 修改Oozie配置文件
属性:oozie.service.JPAService.jdbc.driver 属性值:com.mysql.jdbc.Driver 解释:JDBC的驱动 属性:oozie.service.JPAService.jdbc.url 属性值:jdbc:mysql://hadoop002:3306/oozie 解释:oozie所需的数据库地址 属性:oozie.service.JPAService.jdbc.username 属性值:root 解释:数据库用户名 属性:oozie.service.JPAService.jdbc.password 属性值:199712 解释:数据库密码 属性:oozie.service.HadoopAccessorService.hadoop.configurations 属性值:*=/opt/module/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop 解释:让Oozie引用Hadoop的配置文件 // 下图为我们所要修改的地方 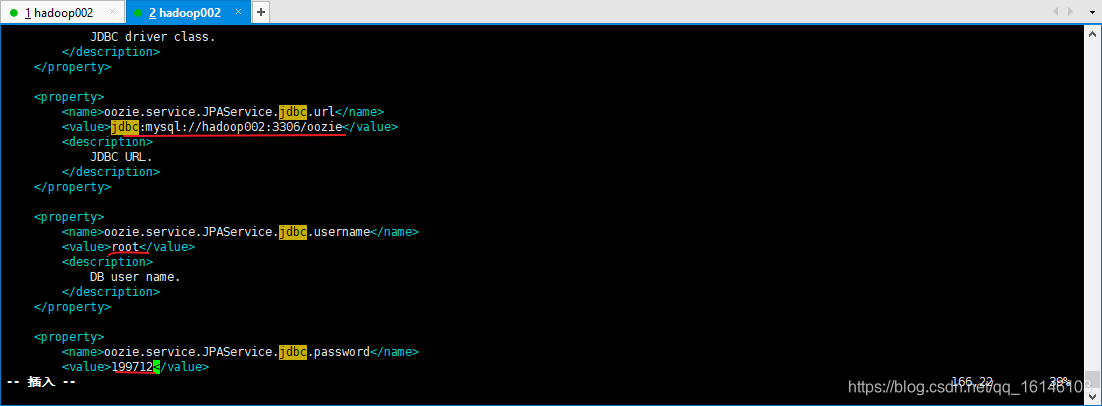
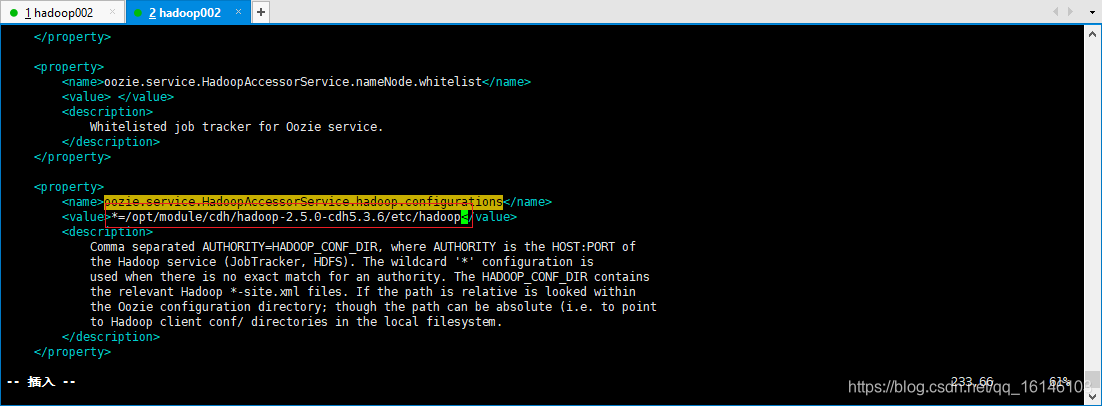
7. 在Mysql中创建Oozie的数据库
[bigdata@hadoop002 opt]$ mysql -uroot -p199712 mysql> create database oozie; 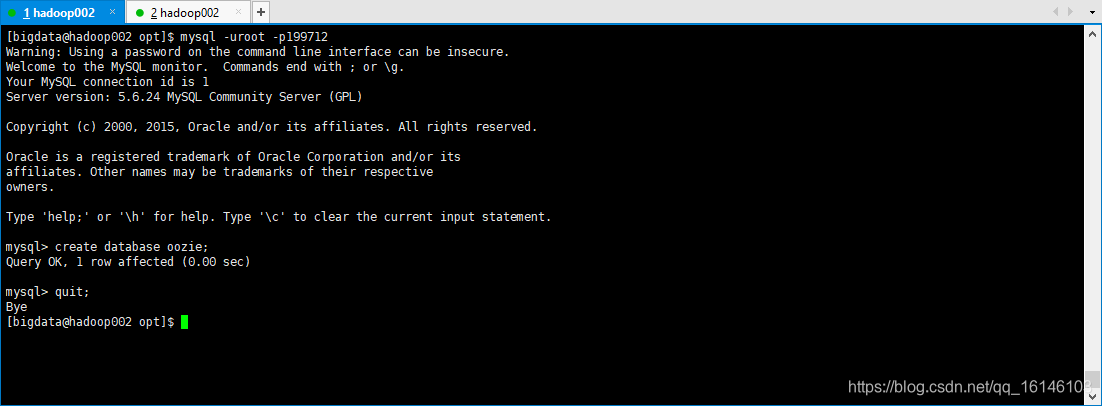
8. 初始化Oozie
// 提示:yarn.tar.gz文件会自行解压 [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozie-setup.sh sharelib create -fs hdfs://hadoop002:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz 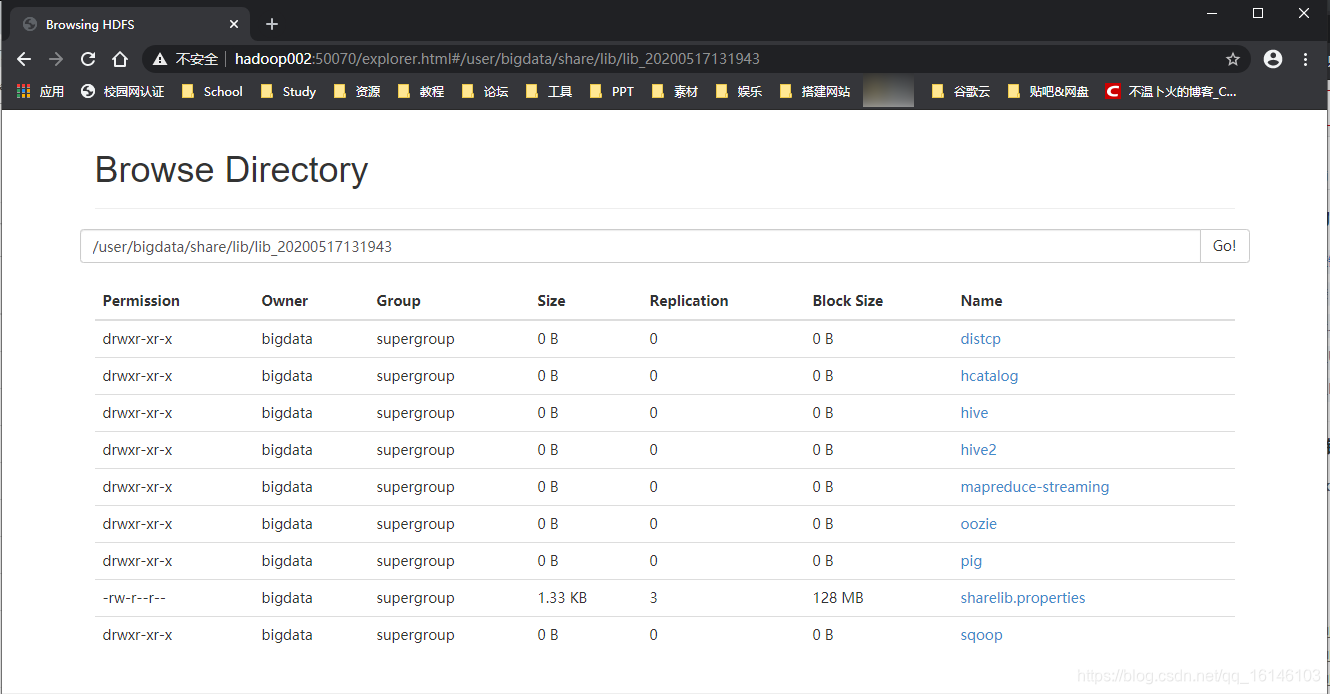
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/ooziedb.sh create -sqlfile oozie.sql -run 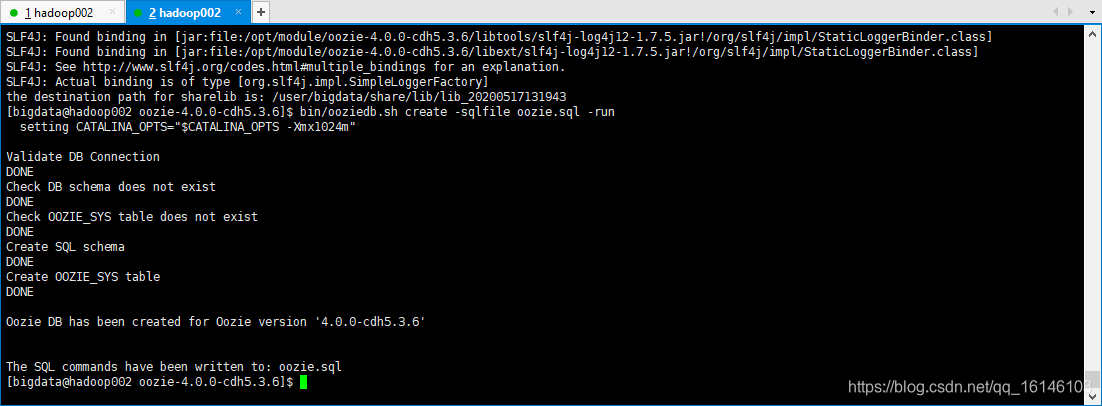
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozie-setup.sh prepare-war 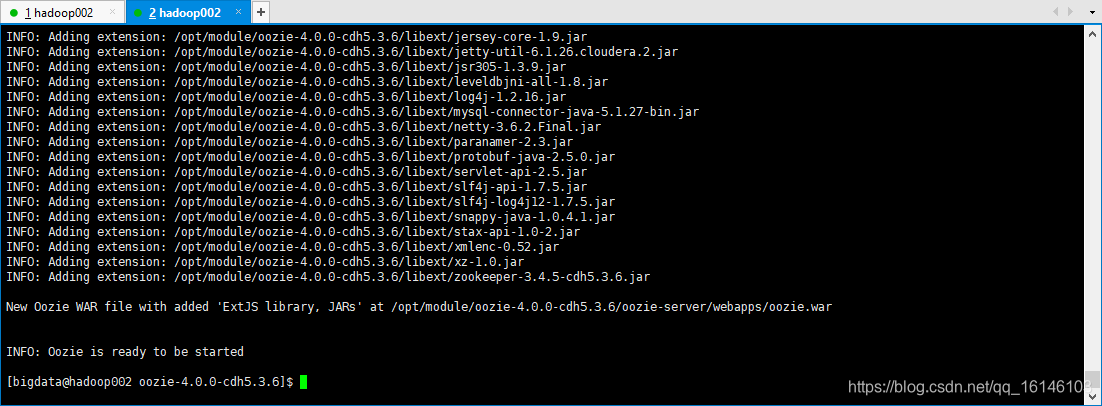
9. Oozie的启动与关闭
// 启动命令如下: [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh start // 关闭命令如下: [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh stop 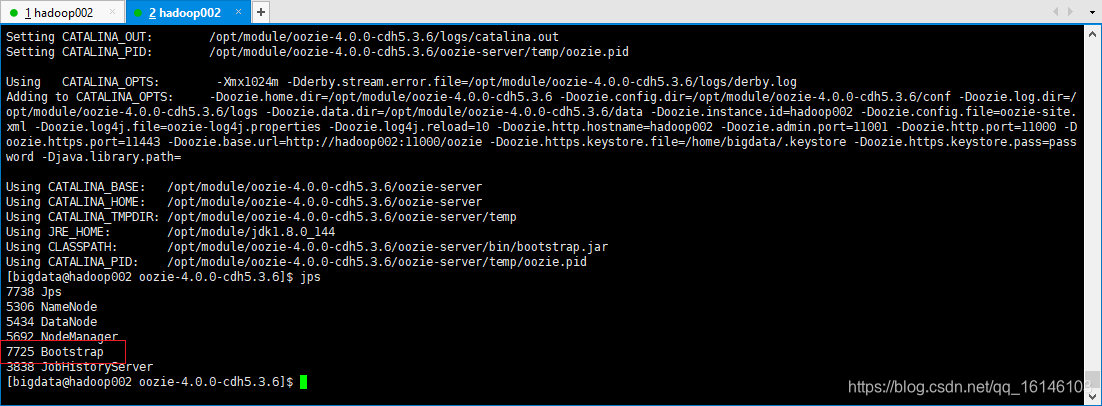
10. 访问Oozie的Web页面
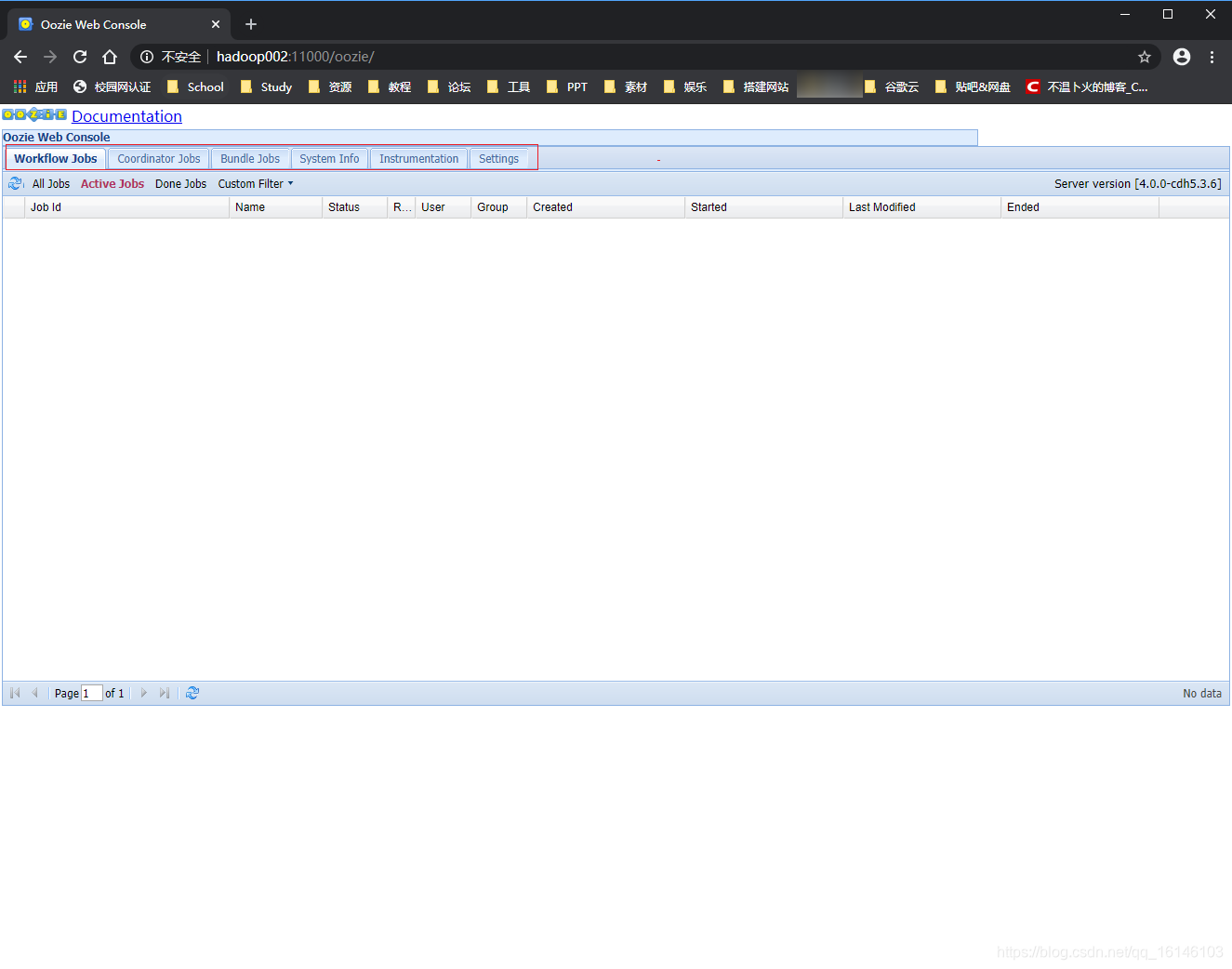
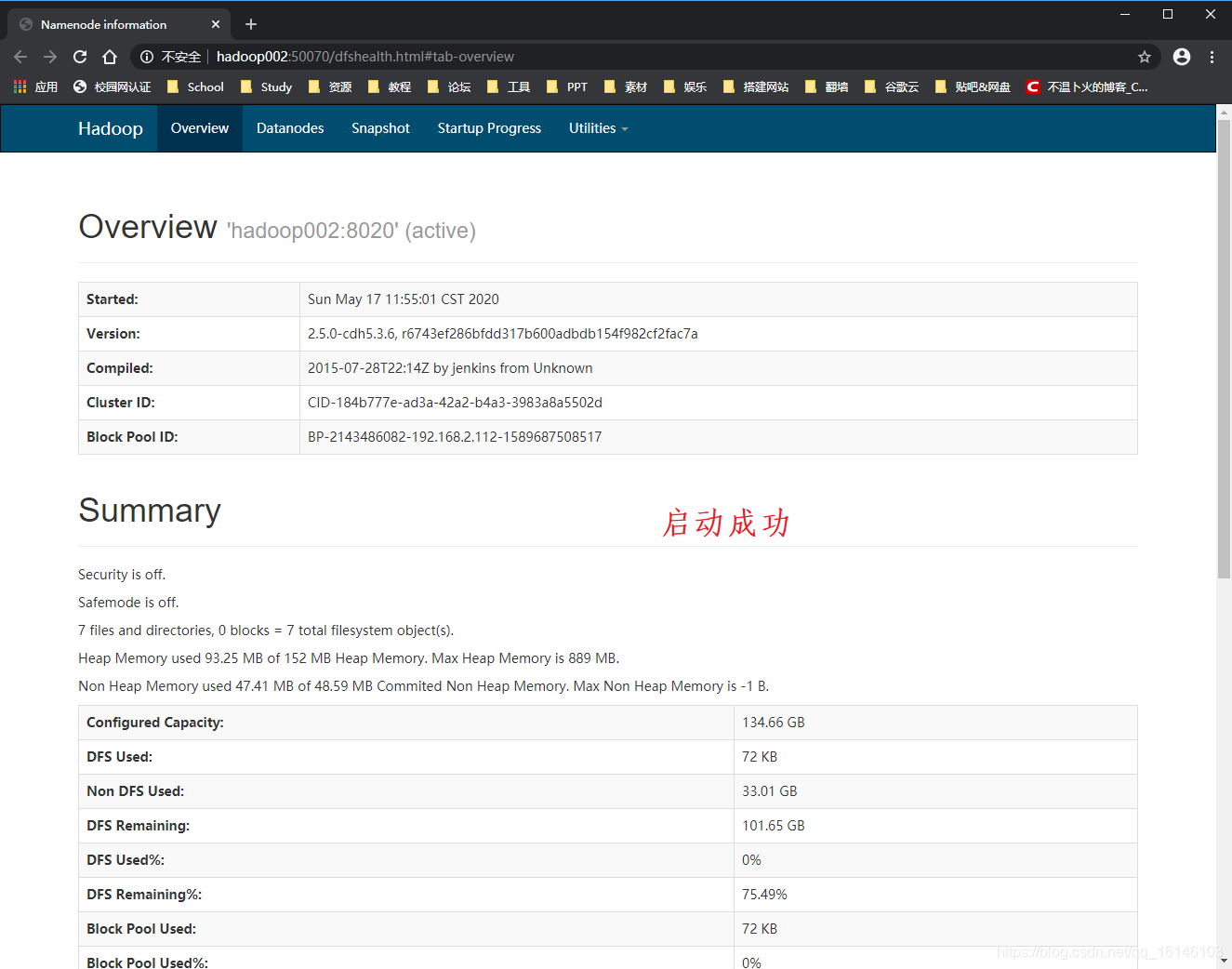
这样就大功告成了!!!

如果我的博客对你有帮助、如果你喜欢我的博客内容,请“” “评论”“”一键三连哦!听说的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。后不要忘了关注我哦!

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 134
134