在计算机科学中,数据结构(data structure)是计算机中存储、组织数据的方式。大多数数据结构都由数列、记录、可辨识联合、引用等基本类型构成。数据结构可透过程式语言所提供的数据类型、引用及其他操作加以实现。一个设计良好的数据结构,应该在尽可能使用较少的时间与空间资源的前提下,支援各种程式执行。不同种类的数据结构适合不同种类的应用,部分资料结构甚至是为了解决特定问题而设计出来的。正确的数据结构选择可以提高演算法的效率(请参考演算法效率)。在电脑程式设计的过程中,选择适当的数据结构是一项重要工作。许多大型系统的编写经验显示,程式设计的困难程度与最终成果的质量与表现,取决于是否选择了最适合的数据结构。 通用数据结构:数组、链表、树、哈希表 编写一段计算机程序一般都是实现一种已有的方法(大多与编程语言无关)来解决某个问题。在计算机科学领域,用算法来描述一种有限、确定、有效的并适合使用计算机程序来实现的解决问题的方法。学习算法的主要原因是它们可以解决许多计算机资源,甚至可以让我们完成以下本不可能完成的任务。但是为一项任务选择合适的算法是困难的,我们需要关注各个算法的之间的性能差异,使得选择的算法能够具有最小的资源消耗。 数据结构是对在计算机内存中(有时在磁盘中)的数据的一种安排。数据结构包括数组、链表、栈、二叉树、哈希表等。算法对这些结构中的数据进行各种各样的处理,例如,查找一条特殊的数据项或对数据进行排序等。著名的瑞士计算机科学家N.Wirth曾经提出:算法+数据结构=程序。 线性表是最简单也是最常用的一种数据结构,它的最基本的特点是每个数据元素最多只能有一个直接前驱,一个直接后继;只有第一个数据元素没有直接前驱,最后一个数据元素没有直接后继。 线性表的顺序存储(向量存储)结构中,线性表中结点存放的物理顺序与逻辑顺序完全一致。数据存储的逻辑位置由数组的下标决定,相邻的元素之间具有相邻的存储位置。 单向链表 1.顺序存储结构一般要求数据存放的物理和逻辑地址连续;链式存储结构数据存放地址可连续也可不连续。所以在线性表长度没有确定的情况下,一般采用链式存储结构,反之,选择顺序存储结构。 堆栈和队列是两种特殊的线性表,堆栈主要的特点是只能在栈顶操作,遵循先进后出的原则;而队列只能在一端插入元素。另外一端删除元素,遵循先进先出的运算原则。 栈(堆栈)是限制在表的一端进行插入和删除运算的线性表。一般来说,能够进行插入、删除运算的这一端为栈顶,另一端称为栈底。每次删除元素的操作又称为弹出(pop),将元素插入又称为压入(push)。 表达式一般有中缀表达式、后缀表达式以及前缀表达式三种表示形式。平时我们使用的一般是中缀表达式,但中缀表达式在计算机中存储计算时比较麻烦,所以计算机内存储表达式时,一般采用后缀或者前缀表达式。 队列(先进先出)的操作是在两端进行,其中一端只能进行插入,该端称为队列的对尾;而另外一端只能进行删除,该端称为队列的对首。 a.置空队;//构造一个空队列 顺序存储结构。当头尾指针相等时队列为空。在非空队列里,头指针始终指向队头前一个位置,而尾指针始终指向队尾元素的实际位置 在循环队列中进行出队、入队操作时,头尾指针仍要加1,朝前移动。只不过当头尾指针指向向量上界(MaxSize-1)时,其加1操作的结果是指向向量的下界0。除非向量空间真的被队列元素全部占用,否则不会上溢。因此,除一些简单的应用外,真正实用的顺序队列是循环队列。故队空和队满时头尾指针均相等。因此,我们无法通过front=rear来判断队列“空”还是“满”。 数组是数据结构的基本结构形式,是一种顺序式的结构。存储的是同一类型的数据结构,使用数组时需要定义数组的大小和存储数据的数据类型。数组分为一维数组和多维数组。 广义表是线性表的扩展,具体定义为n个元素的有限集合(元素可以为原子元素或者可以再分的元素)。广义表一般采用链式存储方式。 树是一种非线性结构。定义:树是N个结点的有限集合,其唯一关系具有下列属性:集合中存在唯一的一个结点,称为树根,该结点没有前驱,除根节点外,其余结点分为M和互不相交的集合牟其中每一个集合都是一棵树,并称其为根的子树。 二叉树是由n个结点组成的有限集合,此集合要么为空,要么由一个根节点加上两颗分别称为左、右子树的,互不相交的二叉树组成。 1.二叉树第i层上的结点数最多为2^(i-1); 顺序存储结构 二叉树的遍历是抽取二叉树中各个数据值,其遍历是以递归的方式进行的,主要有前序遍历,中序遍历以及后序遍历三种方式。 图的基本知识可查看我的另一篇博客数据结构学习笔记——图 排序是计算机程序设计中的一种重要操作,如果数据能够根据某种规则排序,就能大大提高数据处理算法的效率。 插入排序的基本思想是:每次将一个待排序的记录按照其关键字的大小插入到前面已经排好序的子文件的适当位置,直到全部记录插入完成为止。 基本思想:假设待排序的记录存放在数组R[1,2,…n]中,排序过程中,R被分成两个子区间R[1,2,…i]和R[i+1,…n],其中R[1,2,…i]是已经排好序的有序区;R[i+1,…n]是当前尚未排序的部分。将当前无序区的第一个记录R[i+1]插入到有序区R[1,2,…i]适当的位置,使得R[1,2,…i+1]变为新的有序区域,每次插入一个元素,直到所有的数据有序为止。 基本思想:先去定一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组内进行插入排序;然后,取第二个增量d2<d1,重读上述的分组和排序,直到所取得增量dt=1,即所有的巨鹿放在同一组中进行直接插入排序为止。 交换排序的基本思想是:凉凉比较待排序记录的关键字,发现两个记录的次序相反时即进行交换,直到没有反序的记录为止。主要有冒泡排序和快速排序。 基本思想:设想被排序的记录关键字保存在数组R[1,2,…n]中,将每个记录R[i]看作是重量为R[i].key的气泡。根据轻气泡不能再重气泡之下的原则,从下往上草庙数组R;凡是扫描到违反本原则的轻气泡,就使其向上“漂浮”。如此反复进行,直到最后任何两个气泡都是轻者在上,重者在下。 快速排序采用了一种分治的策略:将原问题分解为若干个规模更小凡是结构与原问题相似的子问题,递归的解决这些子问题。然后将这些子问题的解组合为原问题的解。 选择排序的基本思想是:每一趟从待排序的记录中选出关键字最小的记录,顺序放在已排好序的子文件的最后,直到全部记录排序完毕。主要有两种选择排序方法:直接选择排序和堆排序。 直接选择排序的基本思想是:第一次从R[0]-R[n-1]中选取最小值,与R[0]交换,第二次从R[1]-R[n-1]中选取最小值,与R[1]交换,…,第i次从R[i-1]-R[n-1]中选取最小值,与R[i-1]交换,…,第n-1次从R[n-2]~R[n-1]中选取最小值,与R[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列。 堆排序是利用完全二叉树进行排序的方法,有大根堆和小根堆之分。 对于一组待排序数据,首先按堆的定义建立初始堆(大根堆或小根堆); 归并排序是将两个或者两个以上的有序表组合成一个新的有序表。其基本思想是:先将N个数据看成N个长度为1的表,将相邻的表成对合并,得到长度为2的N/2个有序表,进一步将相邻的河滨,得到长度为4的N/4个有序表,以此类推,直到所有数据均合并成一个长度为N的有序表为止。 概念:给定一个值K,在含有n个结点的表中找出关键字等于给定值K的结点。若找到,则查找成功,返回该结点的信息或该结点在表中的位置,否则查找失败,返回相关的指示信息。 基本思想:从表的一端开始,顺序扫描线性表,依次扫描到结点关键字和给定的K值相比较,若当前扫描到的结点关键字与K相等,则查找成功;若扫描结束后,仍未找到关键字等于K的结点,则查找失败 是一种效率较高的查找方法,基本思想:先确定待查找记录所在的范围(区间),然后逐步缩小范围直到找到或者找不到该记录为止。 是一种将顺序查找和二分查找相结合的一种查找方法:把线性表分成若干块,块和块之间有序,但每一块内的结点可以无序。基本思想是:确定被查找的结点所在的块(采用二分查找)后,对该块中的结点此阿勇顺序查找。 《数据结构与算法分析——Java语言描述》
数据结构基本概念总结
数据结构与算法
数据结构
数据结构知识点概览
专用数据结构:栈、队列、优先级队列
排序:插入排序、希尔排序、快速排序、归并排序、堆排序
图:邻接矩阵、邻接表
外部存储:顺序存储、索引文件、B-树、哈希方法算法
数据结构与算法之间的关系
线性表
线性表的顺序存储结构
线性表中插入和删除元素(存在大量的数据元素移动)的时间复杂度都为O(N),而查找某个元素的时间复杂度为O(1)。线性表的链式存储结构
用一组任意的存储单元来依次存放线性表的结点,这组存储单元既可以是连续的,也可以是不连续的。因此,链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址。单向链表不需要事先估计存储空间大小。
对于链式分配线性表,整个链表的存取不许是从头指针开始,头指针指示链表中第一个结点的存储位置。最后一个元素没有后继,其结点的指针为“空”(null)。
在使用单链表结点时,必须完成以下三个步骤:(修改两个指针)
1.创建一个新结点;
2.为该结点赋值,将当前元素的next域赋给新结点的next域;
3.当前结点的前驱的next域要指向新插入的节点。
在删除单链表结点时,需要将当前结点的直接前驱结点的next域指向被删除结点的直接后继结点。(删除及诶单指示将结点从链表中删除,该结点仍然存在)
在单链表中,指针是单一的方向,结点的查找只能从前往后查找,不可反向查找,所以在插入、删除结点时,需要利用结点的前驱结点的指针。因此,单向链表中的头结点非常重要,不可丢失。
循环链表
循环链表又称为循环现行链表,其存储结构基本与单向链表相同。它将单向链表中最后一个结点的指针域的null变成指向第一个结点,逻辑上形成一个环形,可以解决单向链表中单方向查找的缺点。相对于单向链表而言,其优点是在不增加任何空间的情况下,已知任意结点的地址,可以找到链表中的所欲结点。
循环链表插入和删除元素的时间复杂度也都是O(N),插入和删除元素基本上也和单向链表一样,只是查找时的判别条件不同(循环判断条件用curr.next()!=head来替换单向链表的curr.next()!=null)。
双链表
双链表在单向链表的基础上,在每个结点中增加了一个指向其前驱的指针域,这样可以从表中快速确定一个结点的前驱。
插入元素:(修改四个指针)
1.申请新结点,同事给新结点的数据域、两个指针域赋值;
2.将当前结点的next域指向新结点;
3.将当前结点的直接后继的前驱指针指向新结点。
删除结点的步骤:
1.修改当前结点的next域;
2.修改当前结点的后继结点和前驱结点指针
查找元素:与单向链表的查找基本一致
双链表可以直接删除当前指针所指向的节点。而不需要像单向链表中,删除一个元素必须找到其前驱。因此在插入数据时,单向链表和双向链表操作复杂度相同,而删除数据时,双向链表的性能优于单向链表。但是双向链表比单向链表使用的空间更多(2倍)。线性表两种存储结构的比较
2.顺序表的存储空间是静态分配的,在执行程序之前一般必须确定它的存储规模;若线性表的长度变化较大,则存储规模难以预先确定。所以当线性表的长度变化较大,难以估计其存储规模时,一般采用动态链表作为存储结构比较好;若存储规模较小,并且线性表的长度固定,这时一般选择顺序存储结构。
3.若对线性表的操作主要是进行查找,很少做插入和删除操作时,采用顺序存储结构比较好(删除和插入需要对元素进行大量的移动);若在线性表中需要做较多的插入和删除操作时,选择链式存储结构。栈和队列
堆栈
堆栈是一种特殊的线性表,所以堆栈的存储结构一般也有两种:顺序存储结构和链式存储结构。
顺序栈
顺序栈是顺序线性表实现的简化。基本的运算有:判断堆栈空、堆栈初始化、判断堆栈满(一般是循环的递归调用、大数据结构的局部变量导致的),入栈元素、出栈元素、取出栈顶元素。入栈需要的步骤:堆栈初始化,判断栈满,不满才能插入元素;出栈需要的步骤:判断栈空,不为空才能对元素出栈。
链式栈
插入和删除操作仅限制在链头位置上进行。栈顶指针就是链表的头指针。通常不会出现栈满的情况。 不需要判断栈满但需要判断栈空。
应用1.数制转换(十进制数和d进制数之间的转换)
2.表达式转换(中缀,前缀,后缀)
利用堆栈处理中缀表达式的步骤:
1.设置两个堆栈,一个操作数堆栈一个运算符堆栈;
2.初始时堆栈为空,读取表达式,只要读到操作数,就将其压入操作数栈;
3.读取到运算符时,将新运算符和栈顶运算符的优先级比较,如果新的运算符的优先级高于栈顶运算符的优先级,将新运算符压入运算符堆栈;否则取出栈顶的运算符,同时取出操作数堆栈中的两个操作胡进行计算,计算结果压入操作数堆栈;
4.重复(2)、(3))步骤,直到整个表达式计算结束为止,此时操作数堆栈中的结果就是表达式的计算结果。
将中缀表达式转换为后缀(前缀)表达式的转换原则:
1.从左至右读取一个中序表达式;
2.若读取的是操作数,则直接输出;
3.若读取的是运算符,分3种情况:
a.该运算符为左括号“(”,则直接存入堆栈;
b.该运算符为右括号“)”,则输出堆栈中的运算符,直到取出左括号为止;
c…读取到运算符为非括号时,将新运算符和栈顶运算符的优先级比较,如果新的运算符的优先级高于或者等于栈顶运算符的优先级,将新运算符压入运算符堆栈;否则取出栈顶的运算符。
4.当表达式已经读取完成,而堆栈中海油运算符时,则依次序取出运算符,直到堆栈为空,由此得到的结果就是中缀表达式转换成的后缀表达式。递归
队列
队列的基本运算
a.判队空;//对空返回真
a.判队满;//队满返回真,仅限于顺序存储结构
a.入队;//队非满时,从从对尾插入元素
a.出队;//队非空时,从从对首删除元素
a.取队首元素;//返回队首元素,不修改队首指针
队列的存储也具有顺序存储以及链式存储两种顺序队列
链式队列
数组和广义表
数组
广义表
树
树是递归结构,在树的定义中又用到了树的概念:树是由根节点和若干棵子树构成的。二叉树
二叉树的性质
2.高度为k的二叉树最多有2^i-1个结点;
3.对任何二叉树T,设n0,n1,n3分别表示度数为0,1,2的结点个数,则n0=n2+1;
4.具有n个结点的完全二叉树的高度为log2(n)+1;
5.非空满二叉树的叶节点数等于其分支结点数加1;
6.一颗非空二叉树空子树的数目等于结点数目加1.二叉树的存储结构
二叉树的顺序存储结构中只存储结点的值(数据域),不存储结点之间的逻辑关系,结点之间的逻辑关系由数组中下标的顺序来体现。
二叉树顺序存储的原则是:不管给定的二叉树是不是完全二叉树,都看作完全二叉树,即按照完全二叉树的层次次序(从上到下,从左到右)把各结点依次存入数组中。
顺序结构中,由某节点的存储单元地址可以推出其父亲、左儿子、右儿子及兄弟的地址。
顺序存储结构对于完全二叉树而言,既简单又节省存储空间,但是对于一般的二叉树,为了能用结点在数组中的相对位置标示结点之间的逻辑关系,也必须按照完全二叉树的形式来存储树中的结点,这会造成存储空间的浪费。
链式存储结构
二叉树的链式存储中每个结点由数据域和指针域两部分组成,二叉链存储法也叫孩子兄弟法,左指针指向左孩子,右指针指向右兄弟。而中序遍历的顺序是左孩子,根,右孩子。这种遍历顺序与存储结构不同,因此需要堆栈保存中间结果。而中序遍历检索二叉树时,由于其存储结构跟遍历顺序相符,因此不需要用堆栈。二叉树主要采取链式存储方式。二叉树的遍历
前序遍历
前序遍历是先遍历根节点,再遍历其左子树,最后遍历右子树
中序遍历
中序遍历是先遍历左子树,再遍历根节点,最后遍历右子树
后序遍历
前序遍历是先遍历左子树,再遍历其右子树,最后遍历根节点
层次遍历
层次遍历是指从二叉树的第一层(根节点)开始,从上至下逐层遍历,在同一层中,则按从左至右的顺序对结点逐个访问。
对一棵非空二叉树进行层次遍历可以按照如下步骤进行:
1.初始化一个队列
2.二叉树的根节点放入队列
3.重复步骤(4)-(7)直到队列为空
4.从队列中取出一个结点x
5.访问结点x
6.如果x存在左子节点,将左子节点放入队列
7.如果x存在右子节点,将右子节点放入队列图
排序
按照在排序过程中书都设计数据的内、外存交换来分来,排序大致分为两类:内部排序(排序过程共不涉及数据的内、外存交换)和外部排序。一般来说,捏排序适合记录个数不多的小文件中使用,外排序适合记录个数较多,不能够一次将其全部记录放入内存中的文件。
外排序分为:合并排序法,直接合并排序法
内排序分为:插入排序,选择排序,交换排序,归并排序,分配排序。插入排序
直接插入排序
直接插入排序是稳定的排序算法希尔排序
希尔排序时间性能优于直接插入排序,但它是一种不稳定的排序方法。交换排序
冒泡排序
冒泡排序是就地排序,且它是稳定的。快速排序
快速排序是非稳定的选择排序
直接选择排序
直接选择排序是不稳定的。堆排序
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
堆排序的基本思想:
取出堆顶元素(最大或最小),将剩余的元素继续调整成新堆,就得到次大或次小元素;
反复执行 1、2 ,直到全部元素排序成顺序或逆序,堆排序结束。
堆排序是不稳定的。归并排序
归并排序是一种稳定的排序。各个排序方法的时空复杂度
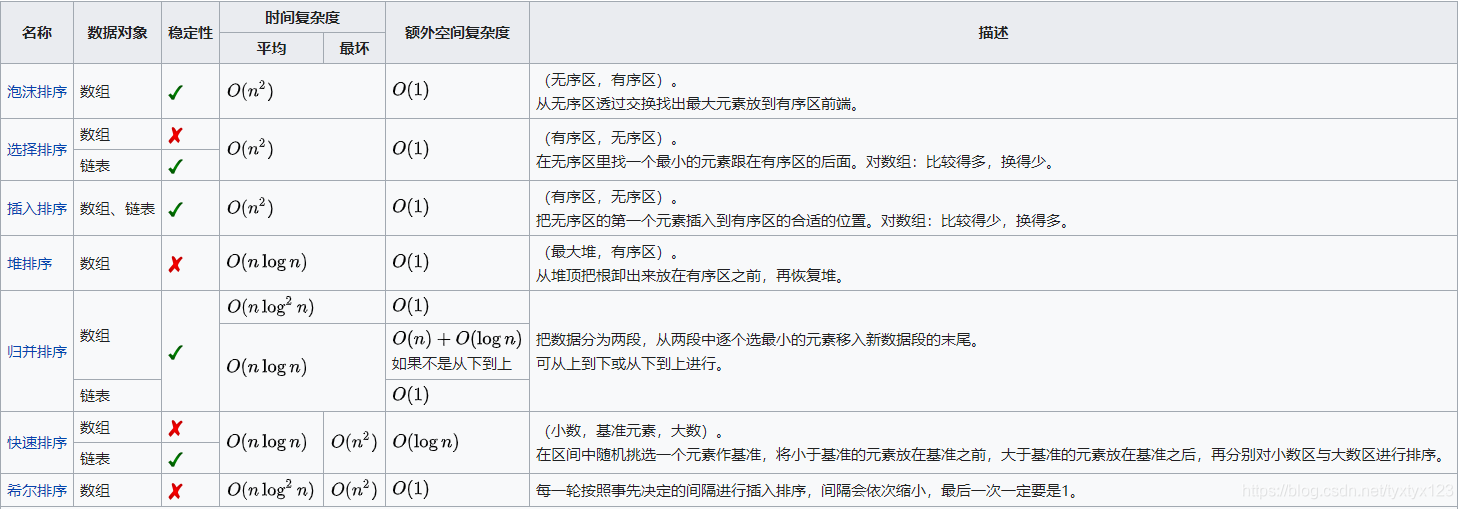
查找
线性表查找
顺序查找
存储结构要求:既适用于线性表的顺序存储结构,也适用于线性表的链式存储结构(使用单链表作存储结构时,扫描必须才能够第一个结点开始)二分查找
分块查找
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 473
473