指令系统属于物理机和虚拟机的边界,在操作系统和机器语言的分界面。 在CPU种存放操作数有三种存储单元:堆栈,累加器,通用寄存器。我们的指令无非就是围绕着操作数转的,所以分为堆栈指令系统,累加器指令系统,通用寄存器指令系统,但目前堆栈和累加器这两种指令系统已经被淘汰了,当前都是通用寄存器指令系统。 那么在通用寄存器指令系统中,也有细分为两种:RR(寄存器-寄存器),RM(寄存器-存储器)。而当前只有RR型成为主流,为什么我们需要尽量把操作数放在寄存器呢? 首先寄存器肯定比存储器要快,其次能够使用更少的地址位数就能访问到操作属,可以减少指令长度。我们之后所学习到的指令系统都是RR型的。 这是老生常谈的问题了,寻址方式的终极目标,是能够表达出: 在对编译器进行调查,发现:偏移寻址和立即数寻址是用的最频繁的。 对指令系统设计的话,我们需要根据之前说的:以经常性事件为重点,我们会选择频率高的功能用硬件来实现,因为硬件速度快,但是灵活性差。对指令系统的要求是:完整,规整,正交,高效率,和兼容。完整的意思是指令系统能给基本的问题解法给答案,保证能用这些指令组合能完成更多任务;正交的意思是各个字段独立,兼容指的是能够新增新指令。对于指令系统的操作分类可以精简到以下几类: 指令操作码的优化 考研需要牢记:赫夫曼树的构造,最短平均码长信息熵的计算,信息冗余度的计算,平均码长的计算的方法。 除了赫夫曼编码压缩法之外,还有等长拓展码的编码方式。这是模拟了数字进位的方法,我们有九个阿拉伯数字,但是数那么大,我们没有理由创造更多的数字,只能用位数来表达更多的信息。 比如说:3/3/3拓展码的编码法,我们每两个二进制位就要进位,那2/7编码法,在右边的位数可以最大 需要注意的是,把频率高的指令编码越短,这是无论哪种方法都要遵循的 下面是例子: 另外等长编码的到底多少位划分一个界限呢?这也是值得思考的问题 我们当然希望频率越高的码占据的位数越少,这是我们的目的。我们看上图的频率剧烈分割点在哪,不难看出在0.22和0.13频率之间出现了分界面,所以前两个我们划分2个,后面的7个大致相似,所以使用2/7编码。 看一个例子: 怎么理解,这里的地址码限定为12位,说的是一个地址码就12位,如果有2个地址,那就是24位了! 二地址共用掉24位作操作数地址,高位有8位作操作码。 再看一个例子: 解: 对于单地址指令的编码: 对于零地址指令的编码: 但是,如果我们的单地址指令有254条,剩下多一个数(256-254=2)的话,就变成: 指令操作数的优化 CISC方向 RISC方向 这是一个典型的RISC指令系统,MIPS64有32个通用寄存器(存放整形),32个浮点数寄存器(存放浮点数),在他的指令系统里面只有两种寻址方式,立即数寻址和偏移寻址,之前我们提到过,这两种方式是最常见的,其余的寻址方式都可以依赖这两个实现。在指令系统里面分为三类指令:I类(Load,store,分支指令,寄存器跳转指令),R类(运算指令),J类(控制指令,异常返回,程序跳转)。
第二话:指令系统的设计

导读目录:
指令系统结构的分类
寻址方式
,EA是有效地址。怎样把EA表示出来,可能因为位数不够的问题,我们要套娃套娃地才能表示出来。下面列举几种,首先先商定一些符号的使用:Reg[…]表示寄存器里的内容,Mem[…]表示存储器的内容。
add r1,r2 ,
add r1,6 ,
add r1,120[r2] ,
add r1,[r2] ,
add r1,(1000) ,
add r1,@[r2] ,

在存储器里面,有:字节,半字,单字,双字,我们如何去兼容这些单位呢?在真实的存储的时候,我们选择下图的B方案,这是一个你到底是想浪费时间还是浪费空间的矛盾问题。(当然浪费空间更好啦)
指令系统的设计和优化

控制指令的优化
控制指令是用来改变控制流的,分为四种:分支,跳转,调用,返回。所谓分支指的是条件跳转,返回必须有调用才有返回。根据数据调查,我们可以发现,分支的使用是最频繁的(如下图)。

思考实现分支指令,我们有几种方法,第一,我们可以用一个寄存器来存储比较结果,第二,利用ALC里面的一个位来表示,第三另外设置一个新的指令来判断。根据速度等因素的考虑,我们会使用第一种(用寄存器来存储比较结果,也就是我们在汇编使用的flag寄存器)
这个我们最熟悉就是赫夫曼压缩法了。基本思想是我们用短的码表示发生频率高的事件,用长的码表示发生频率低的事件。我们需要构造赫夫曼树就能完成整个编码过程。
之外,我们还需要知道信息熵的计算,平均码长计算,信息冗余度计算。
需要注意的是平均码长和最短平均码长不是一种东西!,信息熵的是用来表示某个信息能带来多少信息量,通俗说就是度量信息量的有多少计算。
是7。

n1/n2/n3编码到底怎样编出来的呢?
以3/3/3为例

2/7编码:

15/15/15编码:

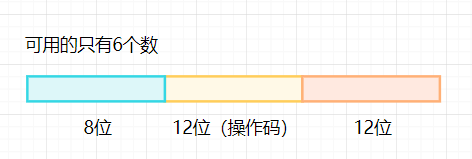
一个计算机系统采用32位单字长指令,地址码是12位,如果定义了250条二地址指令,那么还有多少条条单地址指令?

共有
种操作码状态,现在只用了250种,因此,还有6个可以供下一个扩展用,一地址码就意味着有中间12位可以做操作码,于是根据乘法原理:
。
思考这种问题,我们需要从多地址指令开始想起。
某处理机的指令系统要求:三地址指令4条,单地址指令255条,零地址指令16条,指令字长12位,每个地址码长3位,问此时能用拓展编码为操作码编码吗?假如单地址是254条呢?
对于三地址指令的编码:
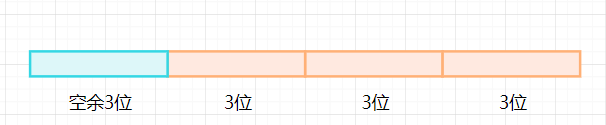
操作码有三位,能表示的操作状态数量是
种,因为需要4条,所以剩下空余数4个。
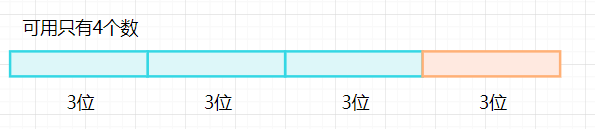
操作码能有6位,根据乘法原则:
条,也就说最多能表示256种状态,需要单地址指令255个,剩下一个数。
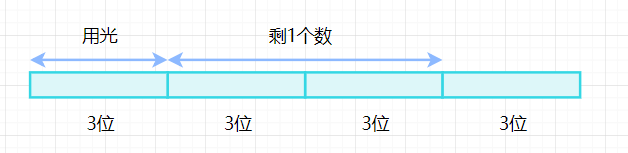
操作码有3位,能表示
条,剩下的一个数根据乘法原则
,所以不够编码零地址指令了。

操作码有3位,能表示
条,剩下多的一个数,根据乘法原则
,就够用来对零地址指令编码了。
考虑操作数,我们不妨想一下,我们怎样区分数据类型呢?有两种方法,第一是在操作码里面指出,第二是在存储的数据里面带一个Tag,第二种方法需要的空间和动态检测数据类型花费的资源太大了,所以我们都是用第一种方法,直接在操作码指出数据的类型。两种方向的指令系统发展
这是朝着利用更多硬件实现更多的指令的方向,能实现的功能越多越好,那拓展的都是些什么指令呢?第一是算术拓展,像求根号,sin,cos,tan,求指数那些,第二是增强数据传输指令的功能,比如传双字和半字的优化,大量数据传送的优化等,第三是对循环语句的优化,根据测试程序的调查显示循环体有1-3条语句的情况占据70%,也就说循环体一般很短,设置专门的循环指令,比如Loop,第四是根据高级语言来优化,在高级语言里面有一些常用的,会直接变成机器指令,加快速度。
这是朝着越简洁越工整越好的方向发展的,CISC的方向最大的问题是芯片面积过大(因为需要实现的硬件功能需要太多了)MIPS指令系统简述

请观察rs和rt为什么是五位,那是因为寄存器有32个嘛。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 1万+
1万+