在真正介绍Lucene之前,需要简单了解一下全文检索技术。Lucene和全文检索技术的关系——前者是后者的工具,也就是说Lucene是实现全文检索的工具之一。除了Lucene之外,还会很多其它实现全文检索的技术。 目前很多大型的网站,都离不开搜索。比如京东、天猫、淘宝等各大电商网站,美团、58同城等生活服务类平台,百度、google等搜索引擎更不用说。 将文档、其它文本文件内容加载到内存进行关键字匹配,在数据量特别大时,显得力不从心。 对数据库的性能要求较高,虽然能够保证对大量数据的检索,但是检索速度无法保证。 百度百科对全文检索的定义: 全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。 我们从这个定义可以看出,全文检索是围绕全文数据库展开的。 以百度搜索为例。 整体流程类似于下方的简化模型: Lucene目前非常流行。Lucene之所以好用,是因为它是一个工具包的概念。最初是由Doug Cutting开发的,在SourceForge的网站上提供下载。在2001年9月作为高质量的开源Java产品加入到Apache软件基金会的Jakarta家族中。随着每个版本的发布,这个项目得到明显的增强,也吸引了更多的用户和开发人员。 (1)原生Java语言开发,所以天然具备跨平台的能力,对Java的整合也比较友好。 目前就介绍这么多,后面会在全文检索这个系列更新更多其它内容。
搜索背景
搜索数据的特点主要有几大方面:数据量庞大、要求速度快、要求搜索准确。而其中大数据的特点有4个V:Volume(大量)、Variety(多样)、Velocity(高速)、Value(价值)。
随着互联网的发展,人们对搜索的质量、速度的要求在不断提升,直接推动了搜索技术的改良和升级。传统搜索技术的瓶颈
文件系统检索
数据库检索
全文检索技术
定义
检索系统架构
一个完整的检索系统,包含三大部分:
(1)数据采集:将分散的数据进行收集,比如网页、日志、各类文档。
(2)数据整理:将无序散乱的数据进行整理计算,变为结构化的数据,并将整理的结构化数据通过分词技术、索引算法建立索引数据库。
(3)检索系统:提供搜索服务,通过一系列其它web技术,对全文数据库的数据进行数据查询返回,供用户使用。
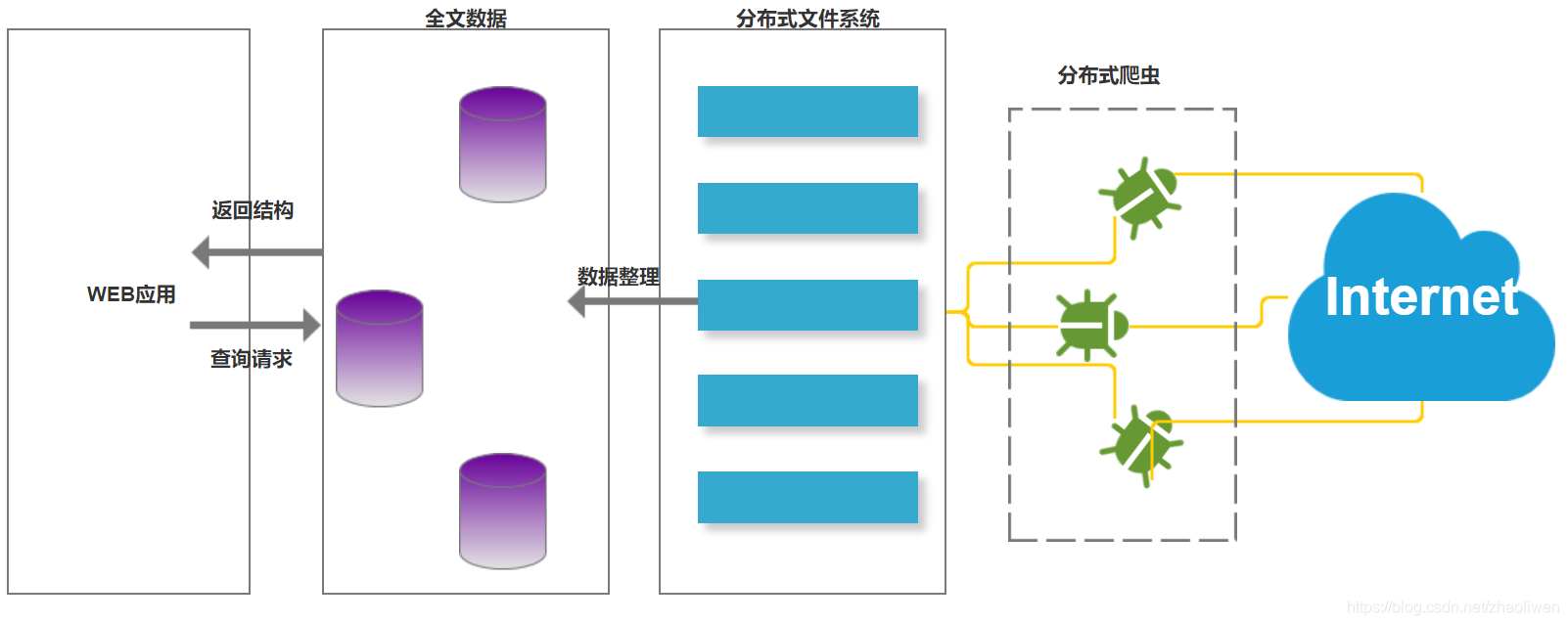
爬虫在互联网上抓取数据到文件系统,然后对文件系统中的数据进行整理,创建出索引,最后为上层Web应用提供数据来源。Lucene介绍
什么是Lucene
Lucene是全文检索技术的一个工具包,为全文索引技术的开发提供支持。换句话讲,Lucene是全文搜索技术,但是全文检索技术就不一定是Lucene。Lucene的特点
(2)全文检索数据库中,索引数据结构的占比不大于数据信息的20%。
(3)提供了丰富的检索功能:
等等。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 320
320