有 ABC
字节–最大映射
一、题目描述
n 个字符串,每个字符串都是由 A-J 的大写字符构成。现在你将每个字符映射为一个 0到9 中的数字,不同字符映射为不同的数字。这样每个字符串就可以看做一个整数,唯一的要求是这些整数必须是正整数且它们的字符串不能有前导零。现在 问你怎样映射字符 才能使得这些字符串表示的整数之和最大?
输入描述:每组测试用例仅包含一组数据,每组数据第一行为一个正整数 n , 接下来有 n 行, 每行一个长度不超过 12 且仅包含大写字母 A-J 的字符串。 n 不大于 50, 且至少存在一个字符不是任何字符串的首字母。
输出描述:输出一个数,表示最大和是多少。 输入例子1: 2 ABC BCA 输出例子1: 1875 二、分析
这道题是已知n个字符串,现在把字符串中每个字符映射为0到9中到某个数字,把每个字符串变成一个整数,最后使得n个字符串组成到正整数之和最大(正整数不能为小数、不能出现前导0)利用权重来计算
BCA
设 table = A B C D E F G H I J
个位权值 为 1;
十位权值 为 10;
百位权值 为 100;
依次类推*10, 没有出现的字母权值为 0;
则 A 的权重为 100 + 1 = 101
B 的权重为 10 + 100 = 110
C 的权重为 1 + 10 = 11
D – J 的权重为 0
即 依照 table 的字母排列顺序,权重表为
weight = 101 110 11 0 0 0 0 0 0 ;
进而得到
映射值表
ret = 8 9 7 0 0 0 0 0 0 ;
将 (权重表 x 映射表),然后再累加起来就是题目要的答案
则这些数的和为 (101 * 8) + (110 * 9) + (11 * 7) + 0 + … + 0 = 1875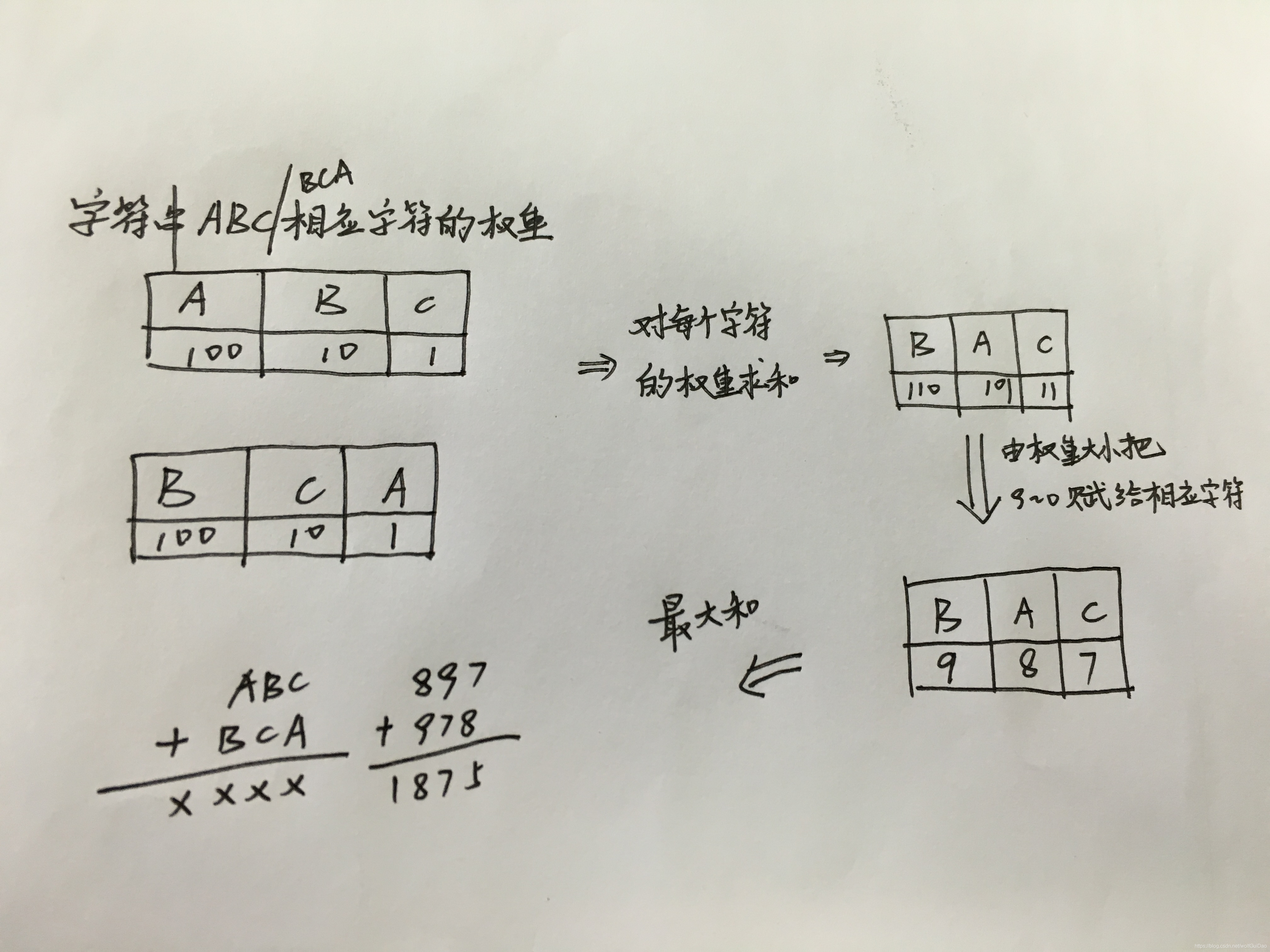
三、代码
#include<iostream> #include<vector> #include<string> #include<set> #include<algorithm> #include<map> using namespace std; //自定义比较方式 bool cmp(pair<char, long>a, pair<char, long>b) { return a.second > b.second; } int main() { int n; while(cin>>n) { //保存字母和权值 map<char, long long> m; set<char> f; //保存首字母 for(int i=0;i<n;i++) { string s; cin>>s; long long b = 1; //倒着遍历把所有的字符和权值保存到m当中 for(string::reverse_iterator it=s.rbegin();it<s.rend();it++) { m[*it] += b; b *= 10; } //记录该字符串的首字符,因为题目要求不能有前导0出现 f.insert(s[0]); } vector<pair<char, long long> >v(m.begin(), m.end()); //排序 sort(v.begin(), v.end(), cmp); int i = v.size() - 1; // 所有字母出现时,找到没有出现在首字母中权重最小的字母 while(v.size() == 10 && i >= 0 && f.find((v[i]).first) != f.end()) { i--; } //保存结果 unsigned long long res = 0; if(i != (v.size() - 1)) { // 最小字母赋值0,删除即可 v.erase(v.begin() + i); } int b = 9; for(int j = 0;j < v.size();j++) { res += b * v[j].second; b--; } cout<<res<<endl; } return 0; }
大佬模版版解法#include <iostream> #include <algorithm> #include <string> #include <vector> #include <math.h> #include <assert.h> #include <cstring> using namespace std; typedef unsigned long long ULL; // 最大要计算 12 位的正整数,所以还是用一个大点的类型吧 // 依据权重表 weight, 得到映射表 ret (即: 排位) // 比如: // // | table | A | B | C | D | E | F | G | H | I | J | // |-------|--------|----------|----|--------|-------|------|---|-----|-----|------| // | weight|10000001| 1010001 | 20 | 100000 | 10000 | 1000 | 1 | 100 | 110 | 1000 | // |-------|--------|----------|----|--------|-------|------|---|-----|-----|------| // | ret | 9 | 8 | 1 | 7 | 6 | 5 | 0 | 2 | 3 | 4 | // void map_weight(ULL* weight, int* ret, const int n = 10) { // // 排位算法: // 初值都为 9 // C(10, 2) : 从10个数中挑选两个数。 // 比较这两个数:谁小谁减一,相等的话随便挑选一个减一 // assert(n == 10); for (int i = 0; i < n; ++i) { ret[i] = 9; } for (int i = 0; i < n; ++i) { if (weight[i] == 0) { ret[i] = 0; continue; } for (int j = i + 1; j < n; ++j) { if (weight[j] == 0) { ret[j] = 0; continue; } if (weight[i] < weight[j]) { ret[i]--; } else { ret[j]--; } // 因为映射不能重复, // 所以当 weight[i] == weight[j] 权重相等时, // 随意挑选一个减一即可。 // 例如: 'A' 和 'B' 权重值相等,但不能都映射为 9 // 此时,随意挑选一个使其映射值 减一 即可 9, 8 } } } // 判断给定的字符 c 是否在 input 中有作为首字符出现 bool is_header(const char c, const vector<string>& input) { const size_t len = input.size(); for (size_t i = 0; i < len; ++i) { if (c == input[i][0]) return true; } return false; } // 依据给定的值,在映射表 ret 中查找对应的下标 (可进一步优化) int get_pos(const int value, const int* ret, const int n = 10) { for (int i = 0; i < n; ++i) { if (value == ret[i]) return i; } return -1; } // 因为不能有 0 开头的数字,所以要修正一下映射表 ret void fixed_ret(int *ret, char *table, const vector<string>& input, const int n = 10) { int pos_0 = get_pos(0, ret); assert(pos_0 >= 0); if (! is_header(table[pos_0], input)) return; // 当前序列需调整 // 依次查找 最小非开头的映射值 i int opt_pos = -1; for (int i = 1; i < n; ++i) { int pos = get_pos(i, ret); assert(pos >= 0); if (! is_header(table[pos], input)) { // 找到了最小的不是 table[pos] 打头的值 i 了 // 记下下标即可 opt_pos = pos; break; } } if (opt_pos == -1) { // 没有找到合适的值。(用例有问题) return; } // 调整开始 // 比 ret[opt_pos] 小的值都加1,最后再将 ret[opt_pos] 置 0 for (int i = 0; i < n; ++i) { if (ret[i] < ret[opt_pos]) { ret[i]++; } } ret[opt_pos] = 0; } template<typename T> void show(const T& arr) { for (auto& v : arr) { cout << v << ' '; } cout << endl; } void check(const string& input_str) { for (auto& s : input_str) { assert(s >= 'A' && s <= 'J'); } } int main() { int n; cin >> n; assert(n > 0 && n <= 50); vector<string> input(n); for (int i = 0; i < n; ++i) { cin >> input[i]; const size_t len = input[i].size(); assert(len <= 12); check(input[i]); } // 输入完毕,并完成合法性检查 char table[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'}; ULL weight[10] = {0}; // 权重表:A - J 每个字母的权重 // 遍历 input[], 统计权重 // 算法: // // 设 // 个位权值 为 1 // 十位权值 为 10 // 百位权值 为 100 // 依次类推, 没有出现的字母权值为 0 // // 统计每个字母的累计权重值 // // 例如输入两组数据: // // ABC // BCA // // 则 A 的权重为 100 + 1 = 101 // B 的权重为 10 + 100 = 110 // C 的权重为 1 + 10 = 11 // D - J 的权重为 0 // // for (int i = 0; i < n; ++i) { ULL w = pow(10, input[i].size() -1); for (auto& v : input[i]) { weight[v - 'A'] += w; w /= 10; } } #ifdef DEBUG cout << endl << "weight = "; show(weight); #endif //DEBUG // 依据权重高低依次映射 9 ~ 0 // // 将统计而来的 权重表进行 排位,最高权重的映射为 9, // 最小权重的映射为 0。 int ret[10]; map_weight(weight, ret, 10); #ifdef DEBUG cout << "ret = "; show(ret); #endif //DEBUG // 修正 映射表, 因为 不能有 0 开头的数字 // // 算法:检查当前映射表中 ret ,映射为 0 的字母是否在 input 中打头 // 若不打头什么也不做; // 若打头,则将不打头的最小映射值 变更为 0, // 比刚才发现的最小映射值小的所有映射值加 1 // // 比如 映射表为 9 1 0 7 8 6 2 5 4 3 // 此时 0 对应的字母是 talble[2] 即 'C' // 如果 'C' 有当过头字母,则需要修正映射表, // 再如, 'B' 也出现过打头,但 'G' 没有出现过打头的情况,则映射表修正如下 // 9 2 1 7 8 6 0 5 4 3 // fixed_ret(ret, table, input); #ifdef DEBUG cout << "after fixed:nret = "; show(ret); #endif //DEBUG // 计算结果 // // 将 (权重表 x 映射表),然后再累加起来就是题目要的答案 // // 例如 // // 输入例子: // ABC // BCA // // 设 table = A B C D E F G H I J // // 则 // 权重表 // weight = 101 110 11 0 0 0 0 0 0 0 // 进而得到 // 映射值 // ret = 8 9 7 0 0 0 0 0 0 0 // // 则这些数的和为 // // (101 * 8) + (110 * 9) + (11 * 7) = 1875 // ULL sum = 0; for (int i = 0; i < 10; ++i) { sum += ((ULL)weight[i] * (ULL)ret[i]); } cout << sum << endl; return 0; }
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 443
443