1. 简述多级Flume架构 2. 简述Kafka数据采集架构 Kafka包括Consumers、Broker、Producers 3. Topic可以分很多区,这些分区有什么作用 作为并行处理单元,使Kafka有能力高效的处理大量数据 4. 在Kafka架构中ZooKeeper如何实现数据管理 Apache Kafka主要利用ZooKeeper解决分布式应用中遇到的数据管理问题,如名称服务、状态同步服务、集群管理、分布式应用配置项的管理等 ZooKeeper的数据管理通过多个Broker协同工作,Producer和Consumer部署在各个业务逻辑中被频繁的调用都是通过ZooKeeper管理协调请求和转发。通过ZooKeeper管理实现了高性能的分布式消息发布订阅系统 1. 基于同构存储的数据迁移和基于异构存储的数据迁移差别有哪些 2. ETL构建数据仓库包含哪些关键流程 3. 简述Sqoop的数据导入和数据导出的过程 导出流程: 4. 查阅相关资料,利用Kettle实现数据迁移
第三章:大数据采集架构
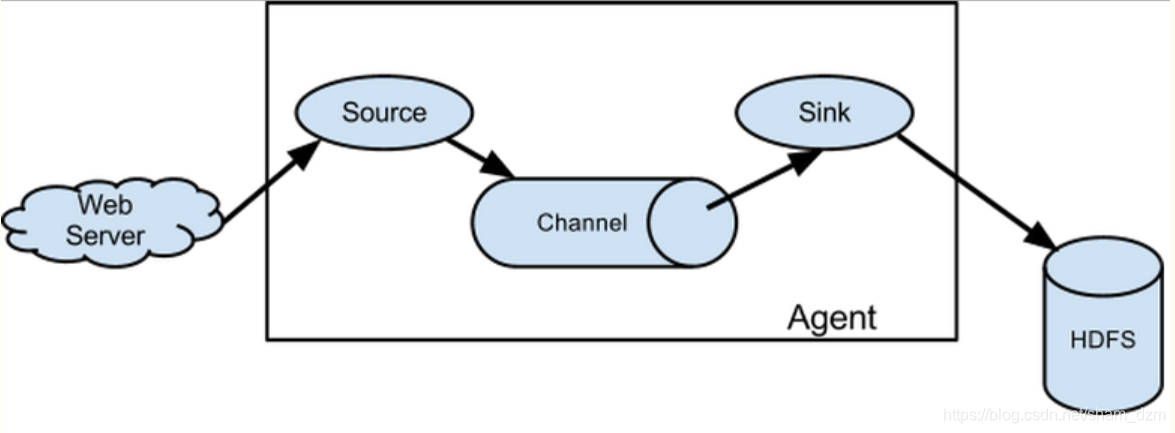
Flume Agent包括Sourse、Channel、Sink
第四章:大数据迁移技术
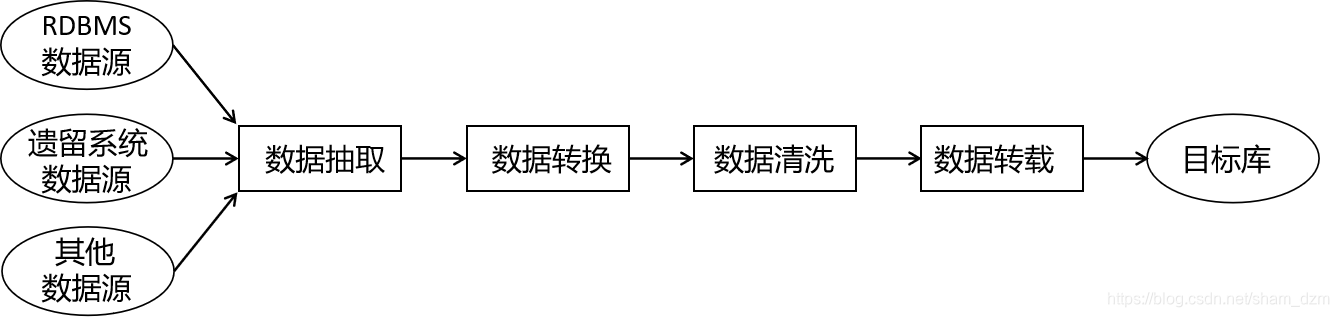
导入流程:
(1)读取要导入数据的表结构
(2)读取参数,设置好job
(3)调用mapreduce执行任务
导入过程的逆向过程
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 5350
5350