GitHub上YOLOv5开源代码的训练数据定义 代码地址:https://github.com/ultralytics/YOLOv5 训练数据定义地址:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data YOLOv5训练自定义数据 本指南说明了如何使用YOLOv5 训练自己的自定义数据集。 开始之前 copy此仓库,下载教程数据集,并安装requirements.txt依赖项,包括Python> = 3.7和PyTorch> = 1.5。 git clone https://github.com/ultralytics/yolov5 # clone repopython3 -c “from yolov5.utils.google_utils import gdrive_download; gdrive_download(‘1n_oKgR81BJtqk75b00eAjdv03qVCQn2f’,‘coco128.zip’)” # download datasetcd yolov5pip install -U -r requirements.txt 训练自定义数据 1.创建Dataset.yaml data / coco128.yaml是一个小型教程数据集,由COCO train2017 中的前128张图像组成。在此示例中,这些相同的128张图像用于训练和验证。coco128.yaml定义1)训练图像目录的路径(或带有训练图像列表的* .txt文件的路径),2)与的验证图像相同的路径,3)类数,4)类列表名称: #训练和Val的数据集(图像目录或* .txt与图像路径文件)训练: …/coco128/images/train2017/ VAL: …/coco128/images/train2017/ 类数量 #类名称名称: [“人”,“自行车”,“汽车”,“摩托车”,“飞机”,“公共汽车”,“训练”,“卡车”,“船”,“交通灯”, “消火栓” ”,“停车标志”,“停车计时器”,“长凳”,“鸟”,“猫”,“狗”,“马”,“绵羊”,“牛”, “大象”,“熊”,“斑马” ‘,‘长颈鹿’,‘背包’,‘雨伞’,‘手提包’,‘领带’,‘手提箱’,‘飞盘’,# parametersnc: 80 # number of classes <—————— UPDATE to match your datasetdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multiple # anchorsanchors: – [10,13, 16,30, 33,23] # P3/8 – [30,61, 62,45, 59,119] # P4/16 – [116,90, 156,198, 373,326] # P5/32 # yolov5 backbonebackbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 1-P1/2 [-1, 1, Conv, [128, 3, 2]], # 2-P2/4 [-1, 3, Bottleneck, [128]], [-1, 1, Conv, [256, 3, 2]], # 4-P3/8 [-1, 9, BottleneckCSP, [256, False]], [-1, 1, Conv, [512, 3, 2]], # 6-P4/16 [-1, 9, BottleneckCSP, [512, False]], [-1, 1, Conv, [1024, 3, 2]], # 8-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 12, BottleneckCSP, [1024, False]], # 10 ]# yolov5 headhead: [[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large) [-2, 1, nn.Upsample, [None, 2, ‘nearest’]], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 1, Conv, [512, 1, 1]], [-1, 3, BottleneckCSP, [512, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 16 (P4/16-medium) [-2, 1, nn.Upsample, [None, 2, ‘nearest’]], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 1, Conv, [256, 1, 1]], [-1, 3, BottleneckCSP, [256, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 21 (P3/8-small) [[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ] 使用Labelbox或CVAT等工具标记图像后,将标签导出为darknet格式,每个图像一个*.txt文件(如果图像中没有对象,则不需要*.txt文件)。*.txt文件规范如下: 每个对象一行 每一行是类x_center,y_center宽度高度格式。 框坐标必须是标准化的xywh格式(从0到1)。如果方框以像素为单位,请将x_center和宽度除以图像宽度,将y_center和高度除以图像高度。 类号是零索引的(从0开始)。 每个图像的标签文件应该可以通过在其路径名中将/image s/.jpg替换为/labels/.txt来定位。图像和标签对的示例如下: dataset/images/train2017/000000109622.jpg # imagedataset/labels/train2017/000000109622.txt # label 一个有5个人的标签文件示例(所有0类): 根据下面的示例组织您的train和val图像和标签。注意/coco128应该在/yolov5目录旁边。确保coco128/labels文件夹位于coco128/images文件夹旁边。 从./models文件夹中选择一个模型。在这里,选择yolov5s.yaml,最小和最快的型号。请参阅的自述表,了解所有型号的完整比较。一旦您选择了一个模型,如果您没有训练COCO,请更新yaml文件中的nc:80参数,以匹配步骤1中数据集中的类数。 **# parametersnc: 80 # number of classes <—————— UPDATE to match your datasetdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multiple 5.训练 运行以下训练命令以训练coco128.yaml5个时期。您可以通过传递从零开始训练yolov5,也可以–cfg yolov5s.yaml –weights ”通过传递匹配的权重文件从预训练的检查点进行训练:–cfg yolov5s.yaml –weights yolov5s.pt。 # Train yolov5s on coco128 for 5 epochs 6.可视化 训练开始后,查看train*.jpg图像以查看训练图像,标签和增强效果。请注意,镶嵌数据加载器用于训练(如下所示),这是由Ultralytics开发并在YOLOv4中首次使用的新数据加载概念。如果这些图像中的标签不正确,则说明您的数据标签不正确,应重新访问2.创建标签。
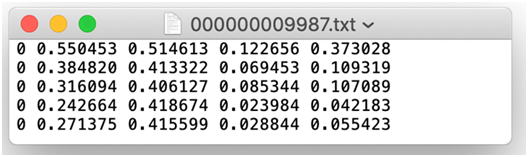
3. 组织目录
**
# anchors
anchors: – [10,13, 16,30, 33,23] # P3/8 – [30,61, 62,45, 59,119] # P4/16 – [116,90, 156,198, 373,326] # P5/32
# yolov5 backbone
backbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 1-P1/2 [-1, 1, Conv, [128, 3, 2]], # 2-P2/4 [-1, 3, Bottleneck, [128]], [-1, 1, Conv, [256, 3, 2]], # 4-P3/8 [-1, 9, BottleneckCSP, [256, False]], [-1, 1, Conv, [512, 3, 2]], # 6-P4/16 [-1, 9, BottleneckCSP, [512, False]], [-1, 1, Conv, [1024, 3, 2]], # 8-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 12, BottleneckCSP, [1024, False]], # 10 ]
# yolov5 head
head: [[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 12 (P5/32-large) [-2, 1, nn.Upsample, [None, 2, ‘nearest’]], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 1, Conv, [512, 1, 1]], [-1, 3, BottleneckCSP, [512, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 16 (P4/16-medium) [-2, 1, nn.Upsample, [None, 2, ‘nearest’]], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 1, Conv, [256, 1, 1]], [-1, 3, BottleneckCSP, [256, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], # 21 (P3/8-small) [[], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
$ python train.py –img 640 –batch 16 –epochs 5 –data ./data/coco128.yaml –cfg ./models/yolov5s.yaml –weights ‘’

在第一个阶段完成后,查看test_batch0_gt.jpg以查看测试批次0地面真相标签:

并查看test_batch0_pred.jpg以查看测试批次0的预测:

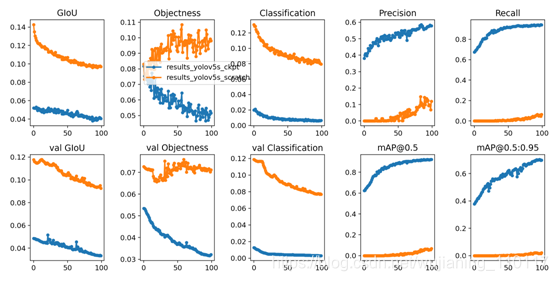
训练损失和绩效指标将保存到Tensorboard以及results.txt日志文件中。训练完成后results.txt绘制results.png。results.txt可以用绘制部分完成的文件from
utils.utils import plot_results; plot_results()。在这里,显示从coco128到100个纪元训练的yolov5,从零开始(橙色),从预训练的yolov5s.pt权重(蓝色)开始:
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









