最近在看一些经典的论文,想要动手复现其中的代码,无奈自己水平过于低,总感觉对于神经网络的理解不够深入,于是想补一下相关的知识。 首先附上这本书的PDF与相关资源 ①首先来观察生物大脑中的基本单元——神经元。 可以参考这篇博客中关于感知机的局限性、多层感知机、从感知机到神经网络的解释。 举一个小的神经网络为例: ①输入 权重的初始值有很多的选择,这里按照书上讲的,方便后面程序的理解。 ①框架代码: 输出: 书中也给出了①如何识别自己的手写数字,将图像改为28*28像素,具体操作见书上P190
便找到了《Python神经网络编程》这本书,若稍微有些基础看起来很快,看完之后给我的感觉是对于神经网络的基本知识、神经网络背后的核心思想有了更深的理解,及时记录下来,方便自己学习。
链接:https://pan.baidu.com/s/1lcVimFBDDCYGTIi6xzxV_g
提取码:oiv7
关于神经网络的理解
1.关于神经元,神经网络的解释
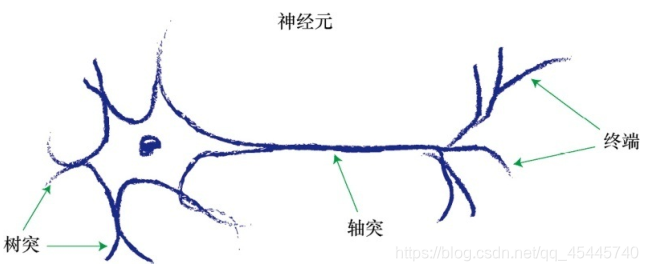
虽然神经元有各种形式,但是所有的神经元都是将电信号从一端传输到另一端,沿着轴突,将电信号从树突传到树突。然后,这些信号从一个神经元传递到另一个神经元。这就是身体感知光、声、触压、热等信号的机制。来自专门的感觉神经元的信号沿着神经系统,传输到大脑,而大脑本身主要也是由神经元构成的。
②那机器怎么做才能有这种功能?
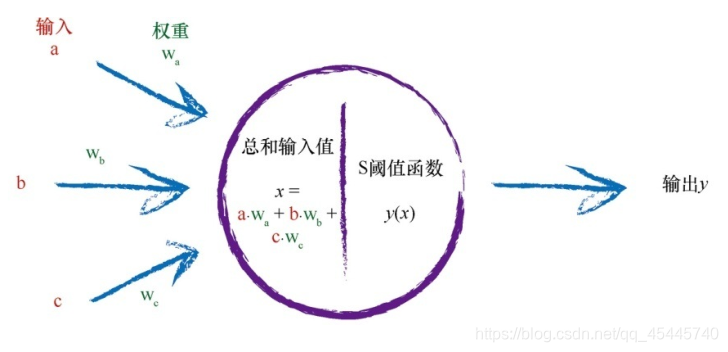
上图中的神经元功能可以简化为如下这幅图:

可以发现神经元的工作原理可以理解为它接受了一个电信号输入,输出另一个电信号。这看起来,似乎与分类或预测的机器一模一样,这些机器也是接受了一个输入,进行一些处理,然后弹出一个输出。
③激活函数的作用
在看神经网络相关的书时,总会少不了激活函数,那激活函数的作用是什么?
生物大脑中的神经元,对于某些外部刺激的时候,不会立即得到反馈,就好比走在路上,很远处看到一辆汽车向你驶来,可能不会在意,但如果离你越来越近,得到的反馈与作出的反应就更剧烈,这似乎其中有一个刺激神经元的度量。
观察表明,神经元不会立即反应,而是会抑制输入,直到输入增强,强大到可以触发输出。你可以这样认为,在产生输出之前,输入必须到达一个阈值。就像水在杯中——直到水装满了杯子,才可能溢出。直观上,这是有道理的——神经元不希望传递微小的噪声信号,而只是传递有意识的明显信号。下图说明了这种思想,只有输入超过了阈值(threshold),足够接通电路,才会产生输出信号。
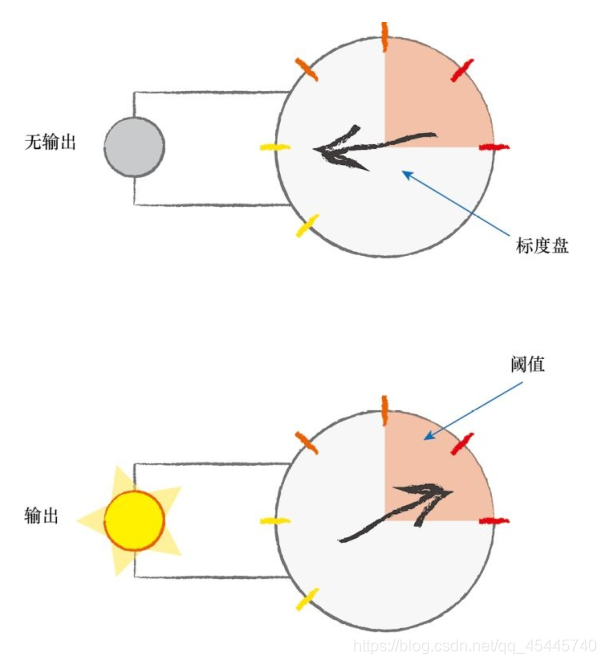
上图可知,虽然这个函数接受了输入信号,产生了输出信号,但是我们要将某种称为激活函数的阈值考虑在内。在数学上,有许多激活函数可以达到这样的效果。可能有人觉得将神经元表示为线性函数不行吗?虽然这是个好主意,但是不可以这样做。生物神经元与简单的线性函数不一样,不能简单地对输入做出的响应,生成输出。也就是说,它的输出不能采用这种形式:输出=(常数*输入)+(也许另一常数)。
这里采用Sigmoid函数。(当然采用tanh、relu、leakyrelu、softmax等函数都可以)
网上关于sigmoid介绍的很详细。
PS:激活函数的作用:对于输入信号进行过滤的作用,若是输入太小,则忽略不计,若是达到了你设定的阈值,则神经元(节点)作出反馈。
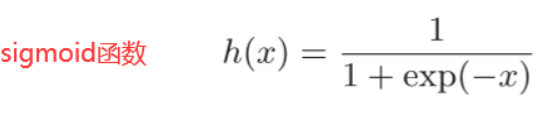
2.为何神经网络需要很多个节点
3.神经网络的工作原理:前向传播
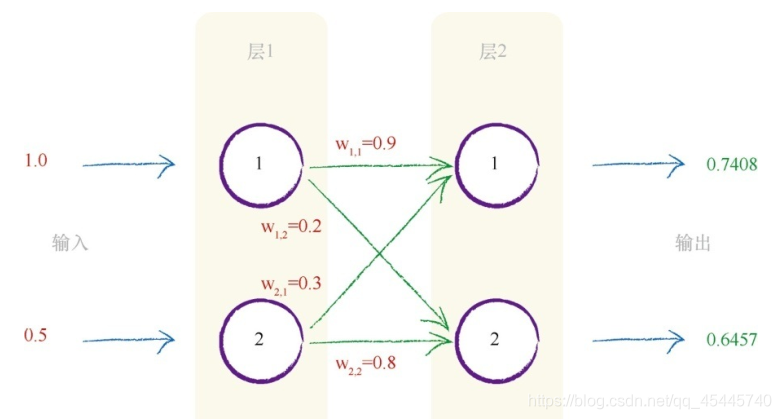
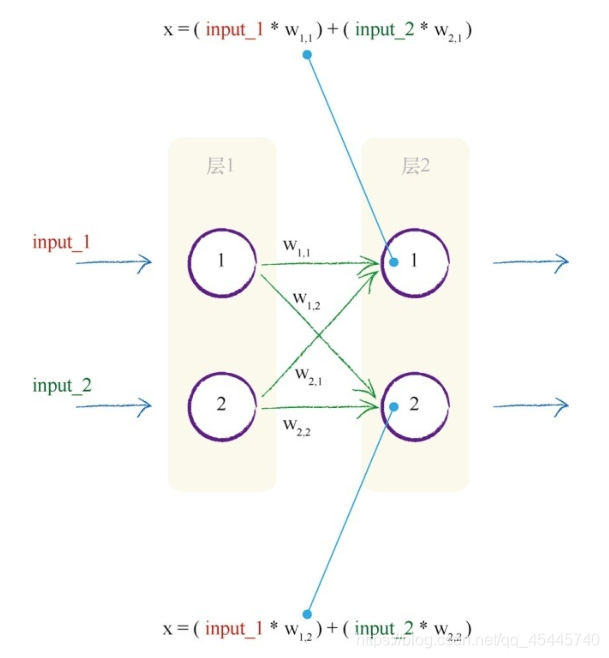
(上图中:两个输入值分别为1.0和0.5。这些值输入到这个较小的神经网络,每个节点使用激活函数,将输入转变成输出。还将使用先前的Sigmoid函数y = 1/(1 + e−x ),其中神经元输入信号的总和为x ,神经元输出为y)
权重:即上图中的w1,1,w1,2,w2,1,w2,2 ,可以理解为各个神经元节点对于外部输入的敏感程度,w1,1 表示上层中的节点1到下层中的节点1之间的权重值。这里的权重值随机设置的,随着分类器学习各个样本,随机值就可以得到改进。对于神经网络链接的权重而言,这也是一样的。
计算过程:
第一层节点是输入层,这一层不做其他事情,仅表示输入信号。也就是说,输入节点不对输入值应用激活函数。这没有什么其他奇妙的原因,自然而然地,历史就是这样规定的。神经网络的第一层是输入层,这层所做的所有事情就是表示输入,仅此而已。
第一层输入层很容易,此处,无需进行计算。
接下来的第二层,我们需要做一些计算。对于这一层的每个节点们需要算出组合输入。还记得Sigmoid函数y = 1 /(1 + e-x )吗?这个函数中的x表示一个节点的组合输入。此处组合的是所连接的前一层中的原始输出,但是这些输出得到了链接权重的调节。下图包括使用链接权重调节输入信号的过程。
因此,对于第二层的节点1。第一层输入层中的两个节点连接到了这个节点。这些输入节点具有1.0和0.5的原始值。来自第一个节点的链接具有0.9的相关权重,来自第二个节点的链接具有0.3的权重。因此,组合经过了权重调节后的输入,如下所示:
x = (第一个节点的输出链接权重)+(第二个节点的输出链接权重)
x =(1.0 * 0.9)+(0.5 * 0.3)
x = 0.9 + 0.15
x = 1.05
我们不希望看到:不使用权重调节信号,只进行一个非常简单的信号相加1.0 + 0.5。
权重是神经网络进行学习的内容,这些权重持续进行优化,得到越来越好的结果。
现在,已经得到了x =1.05,这是第二层第一个节点的组合调节输入。最终,我们可以使用激活函数y = 1 /(1 + e -x )计算该节点的输出。答案为y = 1 /(1 + 0.3499)= 1/ 1.3499。因此,y = 0.7408。
第二层第二个节点的计算方法类比上面的计算过程。
矩阵的便捷
从一个非常简化的网络得到两个输出值,这个工作量相对较小。对于一个相对较大的网络,具有多于两层,每一层有4、8甚至100个节点的网络,其计算量就很复杂。这时候,可以借助计算机,通过矩阵之间的计算解决。
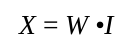
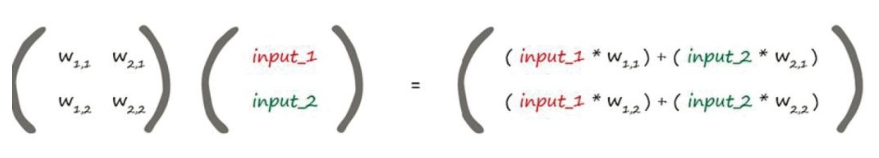
4.神经网络学习的途径:反向传播
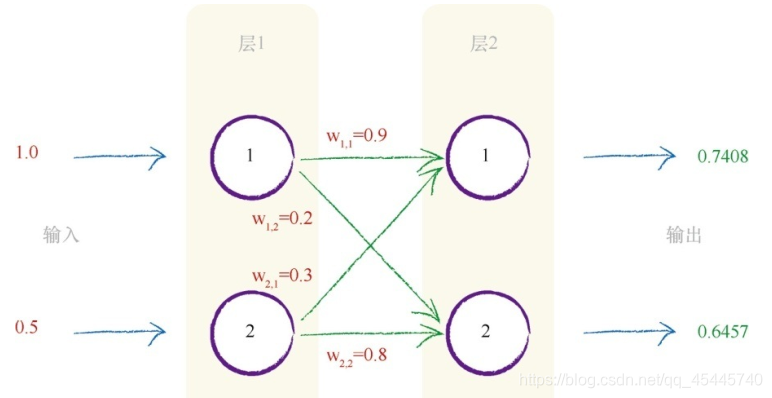
如上图,假设输入x1=1.0,x2=0.5,则输出为y1=0.7408,y2=0.6457,对于误差值(输出-输入),即神经网络的输出与实际输入的差别,神经网络通过这种误差,不断反馈给前面层的节点,从而让权重进行相应的修改(变大或变小),以便让输出无限接近于输入,这个过程称为反向传播,数学化后,给出一个损失函数的概念,即判断神经网络的准确程度(即误差值=(输出-输入)的绝对值,当误差小于你事先设定好了的阈值或者神经网络学习的次数小于事先设置的次数大小,则神经网络停止学习),也就是神经网络不断进行学习的原因。
①如何学习来自多个节点的权重
当输出和误差是多个节点共同作用的结果时,如何更新链接权重呢?下图详细阐释了这个问题。
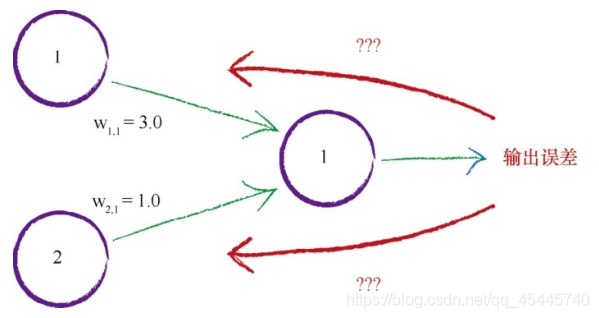
当只有一个节点前馈信号到输出节点,事情要简单得多。如果有两个节点,如何使用输出误差值呢?使用所有的误差值,只对一个权重进行更新,这种做法忽略了其他链接及其权重,毫无意义。多条链接都对这个误差值有影响。只有一条链接造成了误差,这种机会微乎其微。如果我们改变了已经“正确”的权重而使情况变得更糟,那么在下一次迭代中,这个权重就会得到改进,因此神经网络并没有失去什么。
一种思想:在所有造成误差的节点中平分误差,如下图所示:
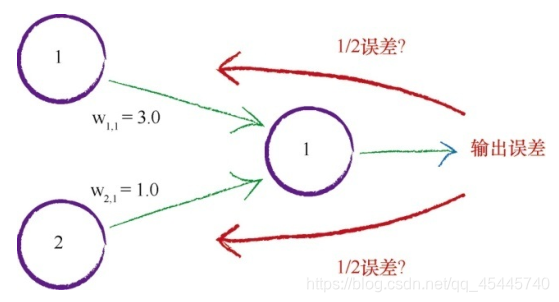
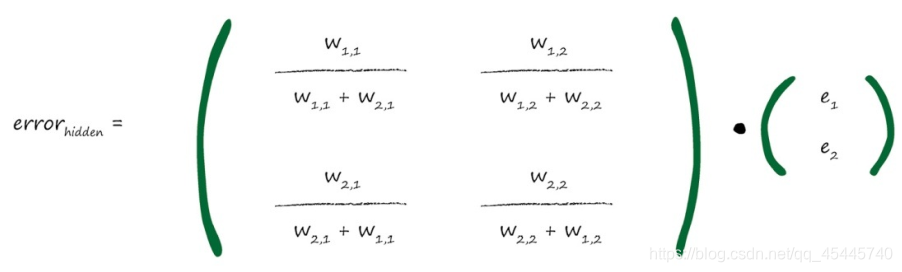
另一种思想:不等分误差。与前一种思想相反,该思想认为较大链接权重的连接分配更多的误差。为什么这样做呢?这是因为这些链接对造成误差的贡献较大。下图详细阐释了这种思想。
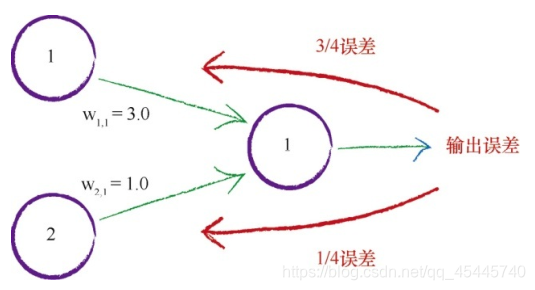
此处,有两个节点对输出节点的信号做出了贡献,它们的链接权重分别是3.0和1.0。如果按权重比例分割误差,那么我们就可以观察到输出误差的3/4应该可以用于更新第一个较大的权重,误差的1/4 可以用来更新较小的权重。
我们可以将同样的思想扩展到多个节点。如果我们拥有100个节点链接到输出节点,那么我们要在这100条链接之间,按照每条链接对误差所做贡献的比例(由链接权重的大小表示),分割误差。
将不等分思想用矩阵表示其计算过程:
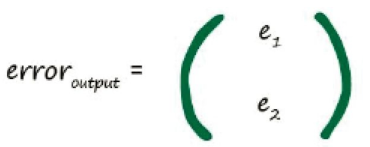
②实际中更新权重的方法
对于上面提到了两个思想,我们都没有采纳。
到目前为止,已经理解了让误差反向传播到网络的每一层。为什么这样做呢?原因就是,我们使用误差来指导如何调整链接权重,从而改进神经网络输出的总体答案。
但是,这些节点都不是简单的线性分类器。这些稍微复杂的节点,对加权后的信号进行求和,并应用了S阈值函数,将所得到的结果输出给下一层的节点。因此,如何才能真正地更新连接这些相对复杂节点链接的权重呢?
即使是一个只有3层、每层3个神经元的小小的神经网络,就像我们刚才使用的神经网络,也具有太多的权重和函数需要组合。在此情况下,你如何调整输入层第一个节点和隐藏层第二个节点之间链路的权重,以使得输出层第三个节点的输出增加0.5呢?即使我们碰运气做到了这一点,这个效果也会由于需要调整另一个权重来改进不同的输出节点而被破坏。
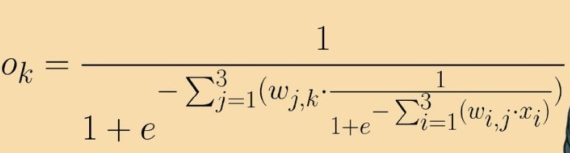
要意识到这件事情的重要性,请观察上面的表达式,这是一个简单的3层、每层3个节点的神经网络,其中输入层节点的输出是输入值和链接权重的函数。在节点i处的输入是xi ,连接输入层节点i到隐藏层节点j的链接权重为wi,j ,类似地,隐藏层节点j的输出是xj ,连接隐藏层节点j和输出层节点k的链接权重是wj,k 。
可以看到,对于3层每层3个节点的计算都这么复杂,若是更复杂的神经网络,这种暴力的方法不切实际。
③对此引出了梯度下降法
这里不做赘述,网上有很多讲梯度下降法的。
权重更新的公式:
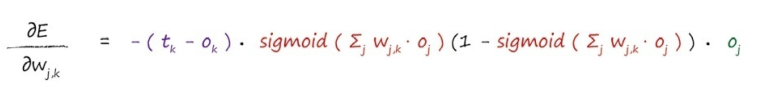
(其中:tk 是一个常数,即输入的目标值,ok 表示神经网络实际的输出值,wj,k 表示隐藏层与输出层之间的权重矩阵)
该公式的具体推导见《Python神经网络编程》书上的P98

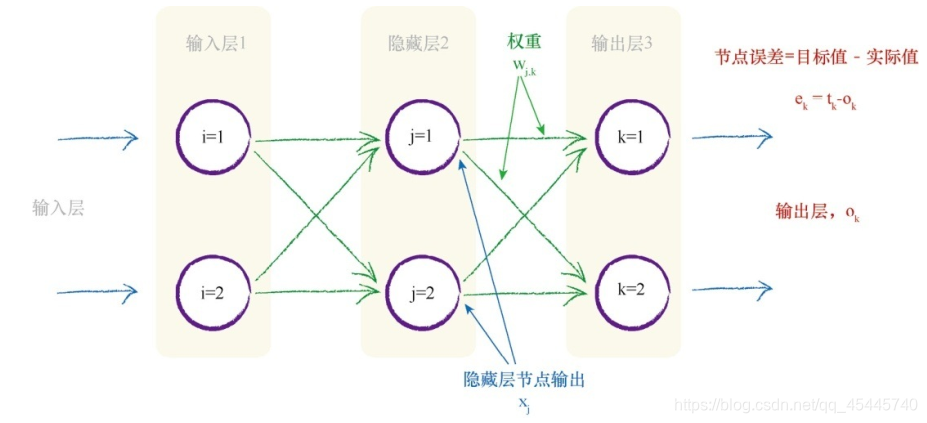
④对③中的公式进行优化

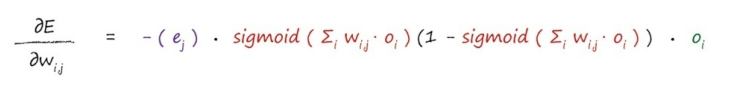
⑤学习率
对于权重参数的更新方法如下:

其中α表示学习率,可以理解为梯度下降法中每次移动的步长,可以调节这些变化的强度,确保不会超调。
最终的权重更新公式如下:

5.数据中输入与输出的标准化处理
观察下图的Sigmoid函数:
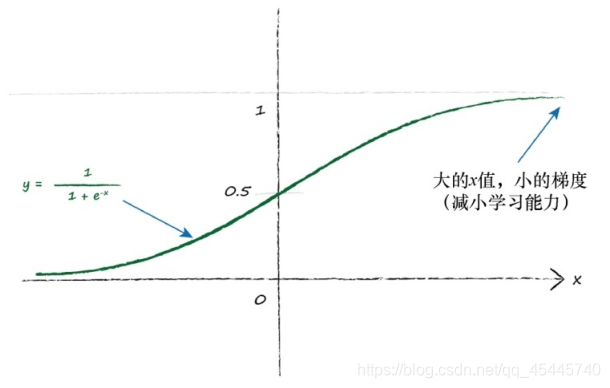
由图可知,如果输入变大,激活函数就会变得非常平坦。由于我们使用梯度学习新的权重,因此一个平坦的激活函数会出问题。
回头仔细观察关于权重变化的表达式。权重的改变取决于激活函数的梯度。小梯度意味着限制神经网络学习的能力。这就是所谓的饱和神经网络。这意味着,我们应该尽量保持小的输入。
有趣的是,这个表达式也取决于输入信号(oj ),因此,我们也不应该让输入信号太小。当计算机处理非常小或非常大的数字时,可能会丧失精度,因此,使用非常小的值也会出现问题。
一个好的建议是重新调整输入值,将其范围控制在0.0到1.0。输入0会将oj 设置为0,这样权重更新表达式就会等于0,从而造成学习能力的丧失,因此在某些情况下,我们会将此输入加上一个小小的偏移,如0.01,避免输入0带来麻烦。
②输出
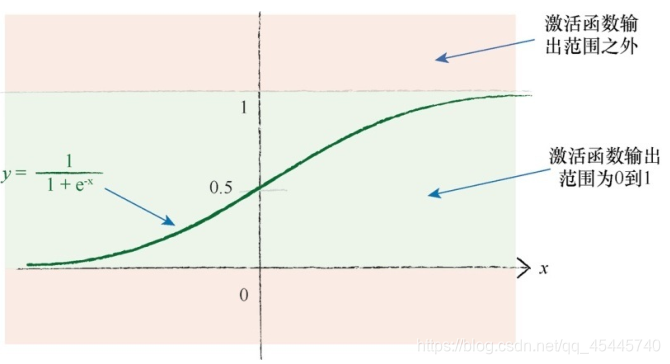
由上图可知,神经网络的输出是最后一层节点弹出的信号。如果我们使用的激活函数不能生成大于1的值,那么尝试将训练目标值设置为比较大的值就有点愚蠢了。(因为Sigmoid函数不能取到1.0,只能接近1.0,接近于0)
如果我们将目标值设置在这些不可能达到的范围,训练网络将会驱使更大的权重,以获得越来越大的输出,而这些输出实际上是不可能由激活函数生成的。这使得网络饱和,因此我们知道这种情况是很糟糕的。因此,我们应该重新调整目标值,匹配激活函数的可能输出,注意避开激活函数不可能达到的值。
虽然,常见的使用范围为0.0~1.0,但是由于0.0和1.0这两个数也不可能是目标值,并且有驱动产生过大的权重的风险,因此一些人也使用0.01~0.99的范围。(下面程序中会有体现)# 将输入数据进行归一化处理 inputs = (np.asfarray(all_values[1:]) / 255.0*0.99) + 0.016.关于权重的随机初始值
与输入和输出一样,同样的道理也适用于初始权重的设置。由于大的初始权重会造成大的信号传递给激活函数,导致网络饱和,从而降低网络学习到更好的权重的能力,因此应该避免大的初始权重值。我们可以从-1.0~+1.0之间随机均匀地选择初始权重。比起使用非常大的范围,比如说-1000~+1000,这是一个好得多的思路。
按照书上讲的,我们可以在一个节点传入链接数量平方根倒数的大致范围内随机采样,初始化权重。因此,如果每个节点具有3条传入链接,那么初始权重的范围应该在从-1/根号3到+1/根号3 ,即±0.577之间。如果每个节点具有100条传入链接,那么权重的范围应该在-1/根号100至 +1/根号100,即±0.1之间。
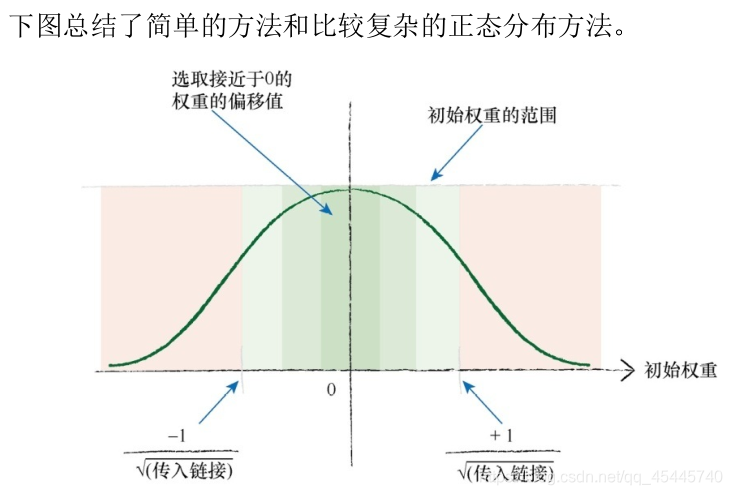
(下面程序中会有体现)# 初始化权重矩阵 # 数组中的权重是wij,含义是从上一层节点i到下一层的节点j # np.random.normal()三个参数,分别代表生成的高斯分布的随机数的均值、方差以及输出的size # 数组中的每个值减去0.5,这样,在效果上,数组中的每个值都成为了-0.5到0.5之间的随机值 # 使用正态概率分布采样权重,其中平均值为0,标准方差为节点传入链接数目的开方,即1/ 根号下传入链接数目 self.wih = np.random.normal(0.0,pow(self.hiddennotes,-0.5),(self.hiddennotes,self.inputnotes)) self.who = np.random.normal(0.0,pow(self.outputnotes,-0.5),(self.outputnotes,self.hiddennotes))实例:搭建一个神经网络
初始化函数——设定输入层节点、隐藏层节点和输出层节点的数量。
训练——学习给定训练集样本后,优化权重。
查询——给定输入,从输出节点给出答案。
PS:在训练神经网络的过程中有两个阶段,第一个阶段就是计算输出,如同query()所做的事情,第二个阶段就是反向传播误差,告知如何优化链接权重。将计算得到的输出与所需输出对比,使用差值来指导网络权重的更新。
query()函数接受神经网络的输入,返回网络的输出。
②权重

③用于更新节点j与其下一层节点k之间链接权重的矩阵形式的表达式
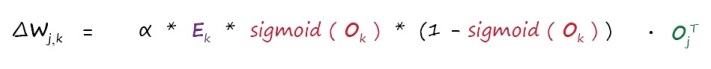
④关于优化神经网络的方法:
a.调整学习率
b.进行多次训练运行
c.改变网络的形状:修改隐藏层节点的数目
在尝试使用不同数目的隐藏层节点进行实验之前,让我们思考一下,如果这样做可能会发生什么情况。隐藏层是发生学习过程的层次。请记住,输入节点只需引入输入信号,输出节点只要送出神经网络的答案,是隐藏层(可以多层)进行学习,将输入转变为答案。这是学习发生的场所。事实上,隐藏层节点前后的链接权重具有学习能力。
如果隐藏层节点太少,比如说3个,那么你可以想象,这不可能有足够的空间让网络学习任何知识,并将所有输入转换为正确的输出。这就像要5座车去载10个人。你不可能将那么多人塞进去。计算机科学家称这种限制为学习容量。虽然学习能力不能超过学习容量,但是可以通过改变车辆或网络形状来增加容量。
如果有10 000个隐藏层节点,会发生什么情况呢?虽然我们不会缺少学习容量,但是由于目前有太多的路径供学习选择,因此可能难以训练网络。这也许需要使用10 000个世代来训练这样的网络。
随着增加隐藏层节点的数量,结果有所改善,但是不显著。由于增加一个隐藏层节点意味着增加了到前后层的每个节点的新网络链接,这一切都会产生额外较多的计算,因此训练网络所用的时间也显著增加了!因此,必须在可容忍的运行时间内选择某个数目的隐藏层节点。
⑤数据集MNIST的处理
打开其中一个训练集:

在这个文本中:
●第一个值是标签,即书写者实际希望表示的数字,如“5”或“9”。这是我们希望神经网络学习得到的正确答案。
●随后的值,由逗号分隔,是手写体数字的像素值。像素数组的尺寸是28乘以28,因此在标签后有784个值。
⑥将28*28的数组转化为图像
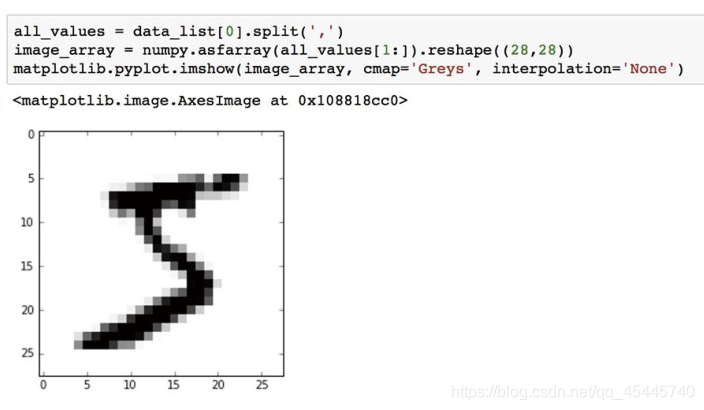
⑦numpy.asfarray()这个函数将文本字符串转换成实数,并创建这些数字的数组
https://blog.csdn.net/qq_36501722/article/details/87829743源程序及代码注释
# python制作自己的神经网络 # 代码为一个3层神经网络,使用MNIST数据集 import numpy as np import scipy.special # 调用sigmoid函数模块 import matplotlib.pyplot as plt # 定义神经网络类 class neuralNetwork(): '''初始化神经网络''' def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate): # 设置输入、隐藏、输出层的节点数 self.inputnotes = inputnodes self.hiddennotes = hiddennodes self.outputnotes = outputnodes # 学习率 self.lr = learningrate # 初始化权重矩阵 # 数组中的权重是wij,含义是从上一层节点i到下一层的节点j # np.random.normal()三个参数,分别代表生成的高斯分布的随机数的均值、方差以及输出的size # 数组中的每个值减去0.5,这样,在效果上,数组中的每个值都成为了-0.5到0.5之间的随机值 # 使用正态概率分布采样权重,其中平均值为0,标准方差为节点传入链接数目的开方,即1/ 根号下传入链接数目 self.wih = np.random.normal(0.0,pow(self.hiddennotes,-0.5),(self.hiddennotes,self.inputnotes)) self.who = np.random.normal(0.0,pow(self.outputnotes,-0.5),(self.outputnotes,self.hiddennotes)) # 激活函数为sigmoid函数 self.activation_function = lambda x: scipy.special.expit(x) '''训练神经网络''' def train(self,inputs_lists,targets_list): # 将输入列表转换为二维数组 inputs = np.array(inputs_lists,ndmin=2).T # ndmin=2表示二维数组 targets = np.array(targets_list,ndmin=2).T # 计算信号从输入层进入到隐藏层输入 hidden_inputs = np.dot(self.wih, inputs) # 计算从隐含层后出现的信号,经过sigmoid函数 hidden_outputs = self.activation_function(hidden_inputs) # 计算信号到最终的输出层 final_inputs = np.dot(self.who, hidden_outputs) # 计算从最终输出层出现的信号 final_outputs = self.activation_function(final_inputs) # 输出层误差为(目标-实际) output_errors = targets - final_outputs # 隐藏层误差是output_errors,按权重分割,在隐藏节点处重新组合 hidden_errors = np.dot(self.who.T,output_errors) # 更新隐藏层和输出层之间的链接的权重(按公式来) # np.transpose:对于二维 ndarray,transpose在不指定参数是默认是矩阵转置 self.who += self.lr * np.dot((output_errors*final_outputs * (1.0-final_outputs)),np.transpose(hidden_outputs)) # 更新输入层和隐藏层之间的链接的权重 self.wih += self.lr * np.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),np.transpose(inputs)) '''查询神经网络,用以预测测试集的输出结果''' def query(self,inputs_list): # 将输入列表转换为二维数组 inputs = np.array(inputs_list,ndmin=2).T # 计算信号到隐藏层 hidden_inputs = np.dot(self.wih,inputs) # 计算从隐含层后出现的信号,经过sigmoid函数 hidden_outputs = self.activation_function(hidden_inputs) # 计算信号到最终的输出层 final_inputs = np.dot(self.who,hidden_outputs) # 计算从最终输出层出现的信号 final_outputs = self.activation_function(final_inputs) return final_outputs # 输入层、隐藏层和输出层节点的数量 input_nodes = 784 # 28×28的结果,即组成手写数字图像的像素个数 hidden_nodes = 100 '''选择使用100个隐藏层节点并不是通过使用科学的方法得到的。我们认为,神经网络应该可以发现在输入中的特征或模式, 这些模式或特征可以使用比输入本身更简短的形式表达,因此没有选择比784大的数字。通过选择使用比输入节点的数量小的值, 强制网络尝试总结输入的主要特点。但是,如果选择太少的隐藏层节点,那么就限制了网络的能力,使网络难以找到足够的 特征或模式,也就会剥夺神经网络表达其对MNIST数据理解的能力。给定的输出层需要10个标签,对应于10个输出层节点, 因此,选择100这个中间值作为中间隐藏层的节点数量,似乎有点道理。 这里应该强调一点。对于一个问题,应该选择多少个隐藏层节点,并不存在一个最佳方法。同时,我们也没有最佳方法选择 需要几层隐藏层。就目前而言,最好的办法是进行实验,直到找到适合你要解决的问题的一个数字。''' output_nodes = 10 learning_rate = 0.1 # 学习率 # 创建神经网络实例 n = neuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate) # 将mnist数据集的CSV文件加载到列表中 training_data_file = open("mnist_dataset_full/mnist_train.csv",'r') training_data_list = training_data_file.readlines() training_data_file.close() # epochs是训练数据集用于训练的次数 epochs = 5 # 训练神经网络 for e in range(epochs): # 检查训练数据集中的所有记录 for record in training_data_list: all_values = record.split(',') # 逗号分割列表中的数据 # 将输入数据进行归一化处理 # 将输入颜色值从0到255,缩放至0.01 到 1.0。然后,需要将所得到的输入乘以0.99, # 把它们的范围变成0.0 到0.99。接下来,加上0.01,将这些值整体偏移到所需的范围0.01到1.00。 inputs = (np.asfarray(all_values[1:]) / 255.0*0.99) + 0.01 # 创建目标的输出值(都是0.01,除了所需的标签为0.99,即正确标签) targets = np.zeros(output_nodes) + 0.01 # all_values[0]表示正确的目标标签 targets[int(all_values[0])] = 0.99 n.train(inputs,targets) # 将mnist测试数据CSV文件加载到列表中 test_data_file = open("mnist_dataset_full/mnist_test.csv",'r') test_data_list = test_data_file.readlines() test_data_file.close() # 测试神经网络 # 建一个计分器,如若正确的标签和预测的输出值一样,为1,否则为0 scorecard = [] for record in test_data_list: all_values = record.split(',') correct_label = int(all_values[0]) # 正确的标签值是每组数据的第一个数 inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 outputs = n.query(inputs) label = np.argmax(outputs) # 输出值中最大值的索引对应当前预测的标签值 if (label == correct_label): scorecard.append(1) else: scorecard.append(0) # 计算模型的得分情况 # np.array (默认情况下)将会copy该对象,而 np.asarray 除非必要,否则不会copy该对象 scorecard_array = np.asarray(scorecard) print("performance:{}".format(scorecard_array.sum() / scorecard_array.size))

②神经网络也可以通过标签值,生成一个手写数字的图像P194
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 9545
9545