大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语— 此篇为大家带来的是Oozie的使用。 目标:使用Oozie调度Shell脚本 使用Oozie执行多个Job调度,过程如下图 下图为流程图 目标:使用Oozie调度MapReduce任务 好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/

一. Oozie调度shell脚本
大体过程如下:
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ mkdir oozie-apps/ [bigdata@hadoop002 oozie-apps]$ mkdir shell [bigdata@hadoop002 oozie-apps]$ cd shell/
// 定义工作流程 [bigdata@hadoop002 shell]$ touch workflow.xml // [bigdata@hadoop002 shell]$ touch job.properties 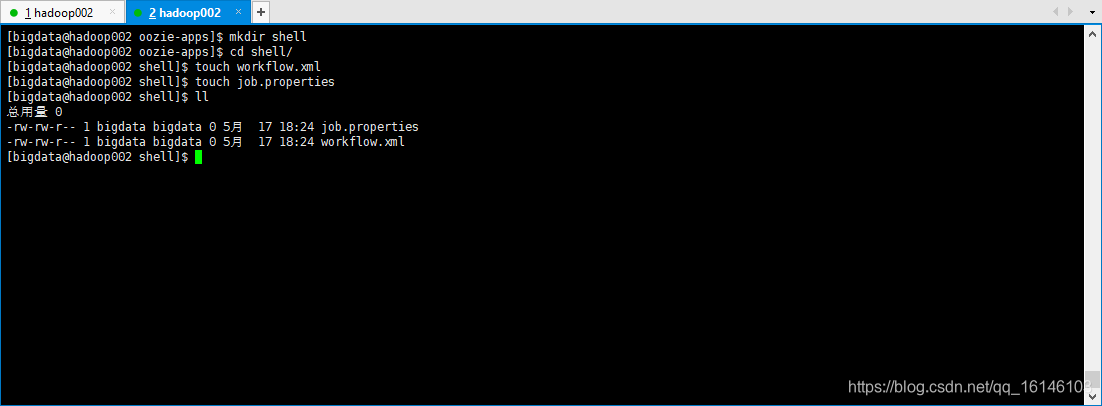
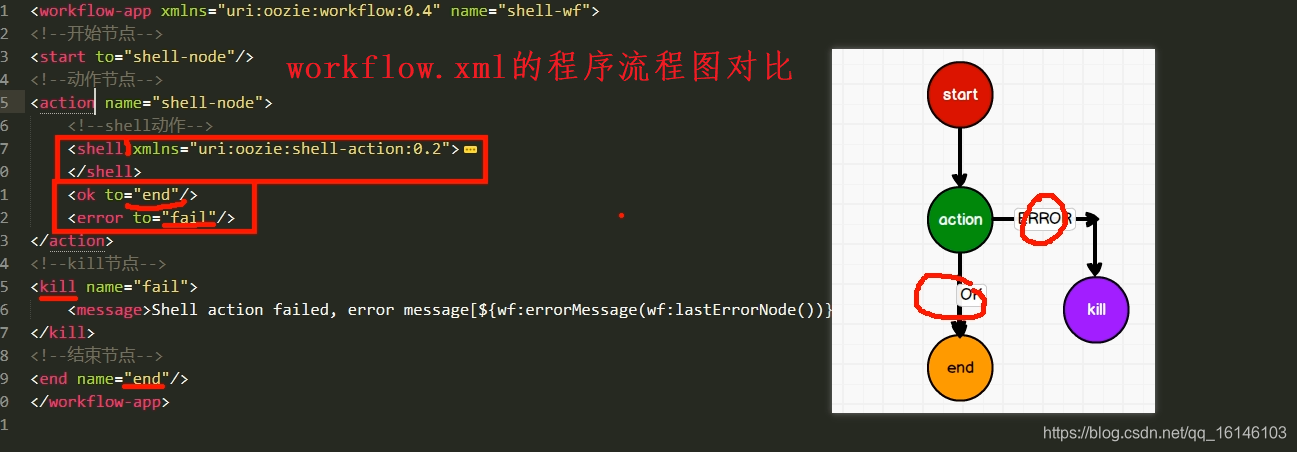
// 1. job.properties #HDFS地址 nameNode=hdfs://hadoop002:8020 #ResourceManager地址 jobTracker=hadoop003:8032 #队列名称 queueName=default examplesRoot=oozie-apps oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell // 2. workflow.xml <workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf"> <!--开始节点--> <start to="shell-node"/> <!--动作节点--> <action name="shell-node"> <!--shell动作--> <shell xmlns="uri:oozie:shell-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <!--要执行的脚本--> <exec>mkdir</exec> <argument>/opt/module/d</argument> <capture-output/> </shell> <ok to="end"/> <error to="fail"/> </action> <!--kill节点--> <kill name="fail"> <message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <!--结束节点--> <end name="end"/> </workflow-app>
[bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop fs -put /opt/module/oozie-4.0.0-cdh5.3.6/oozie-apps/ /user/bigdata
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop002:11000/oozie -config oozie-apps/shell/job.properties -run 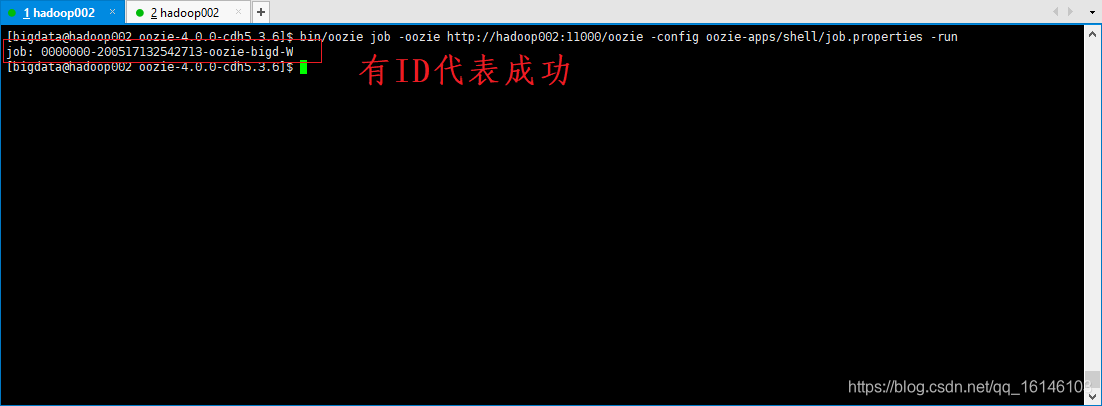
web端查看
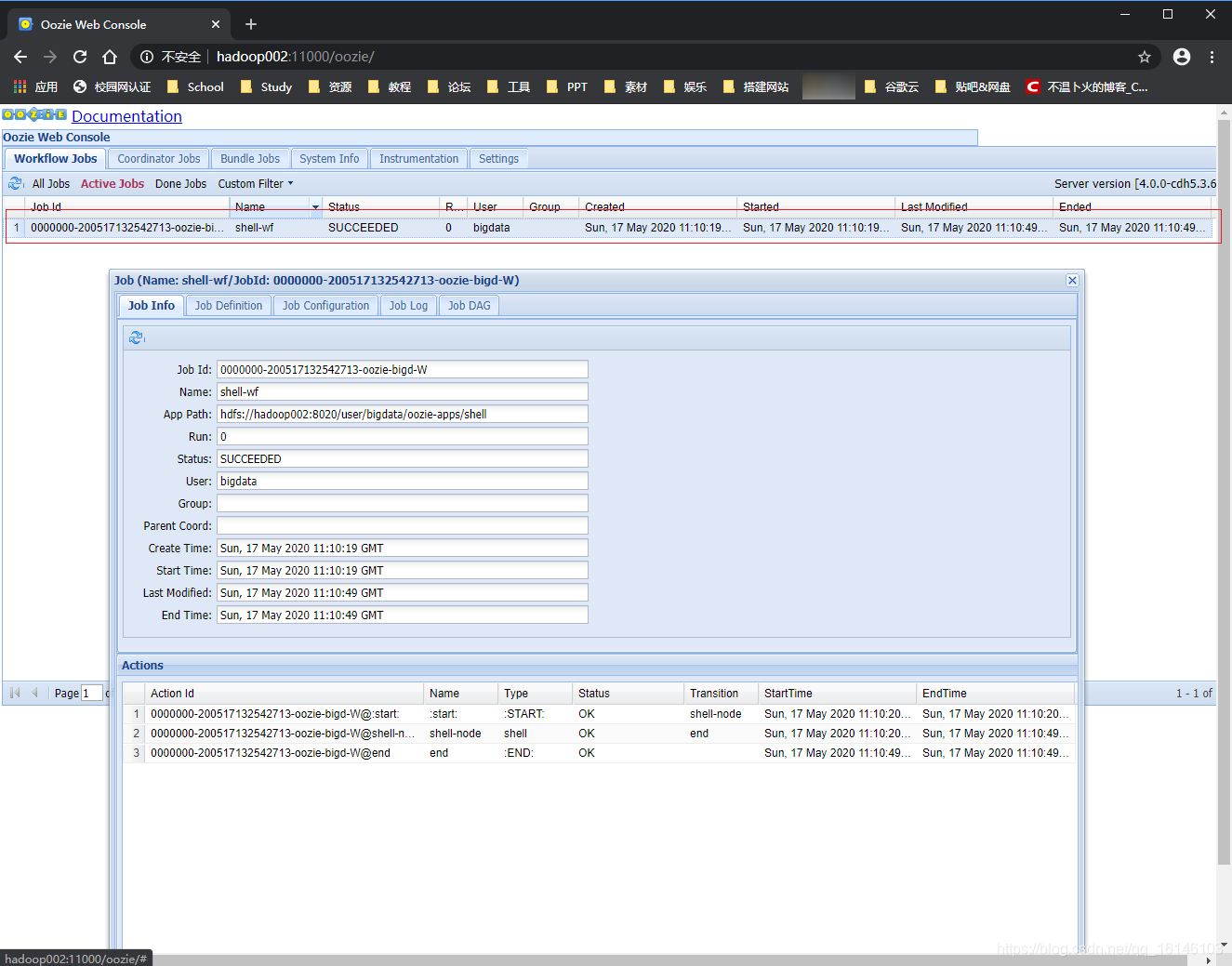
程序流程图对比
二. Oozie逻辑调度执行多个Job
[bigdata@hadoop002 oozie-apps]$ mkdir xshell [bigdata@hadoop002 oozie-apps]$ cd xshell/ [bigdata@hadoop002 xshell]$ touch workflow.xml [bigdata@hadoop002 xshell]$ touch job.properties 
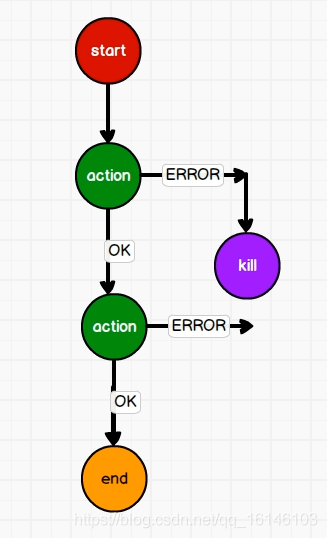
// 1. job.properties nameNode=hdfs://hadoop002:8020 jobTracker=hadoop003:8032 queueName=default examplesRoot=oozie-apps oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/xshell // 2. workflow.xml <workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf"> <start to="p1-shell-node"/> <action name="p1-shell-node"> <shell xmlns="uri:oozie:shell-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>mkdir</exec> <argument>/opt/module/d1</argument> <capture-output/> </shell> <ok to="forking"/> <error to="fail"/> </action> <action name="p2-shell-node"> <shell xmlns="uri:oozie:shell-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>mkdir</exec> <argument>/opt/module/d2</argument> <capture-output/> </shell> <ok to="joining"/> <error to="fail"/> </action> <action name="p3-shell-node"> <shell xmlns="uri:oozie:shell-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>mkdir</exec> <argument>/opt/module/d3</argument> <capture-output/> </shell> <ok to="joining"/> <error to="fail"/> </action> <action name="p4-shell-node"> <shell xmlns="uri:oozie:shell-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>mkdir</exec> <argument>/opt/module/d4</argument> <capture-output/> </shell> <ok to="end"/> <error to="fail"/> </action> <fork name="forking"> <path start = "p2-shell-node"/> <path start = "p3-shell-node"/> </fork> <join name="joining" to="p4-shell-node"/> <kill name="fail"> <message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name="end"/> </workflow-app>

[bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop fs -rm -r -f /user/bigdata/oozie-apps/ [bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hadoop fs -put /opt/module/oozie-4.0.0-cdh5.3.6/oozie-apps/ /user/bigdata/ 
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop002:11000/oozie -config oozie-apps/xshell/job.properties -run 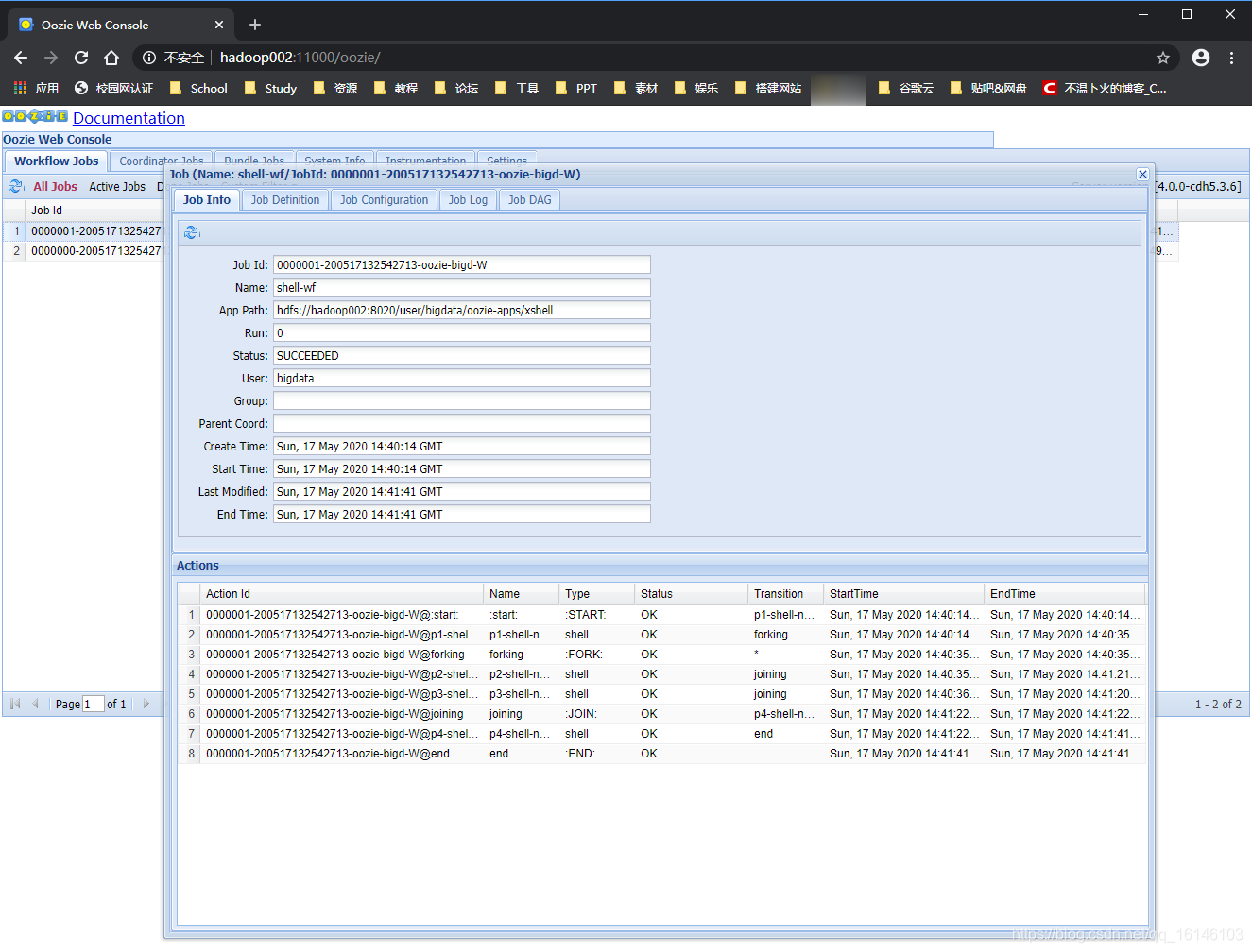
三. Oozie调度MapReduce任务
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ tar -zxvf oozie-examples.tar.gz 
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ cd examples/ [bigdata@hadoop002 examples]$ cd apps/ 
[bigdata@hadoop002 apps]$ cp -r map-reduce/ ../../oozie-apps/ [bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ cd oozie-apps/ // 删除多余的这两个文件,暂时用不到 [bigdata@hadoop002 map-reduce]$ rm job-with-config-class.properties workflow-with-config-class.xml // 官方案例jar包 [bigdata@hadoop002 map-reduce]$ cp /opt/module/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar lib/ 
// 1. job.properties nameNode=hdfs://hadoop002:8020 jobTracker=hadoop003:8032 queueName=default examplesRoot=oozie-apps #hdfs://hadoop002:8020/user/admin/oozie-apps/map-reduce/workflow.xml oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xml outputDir=map-reduce // 2. workflow.xml <workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf"> <start to="mr-node"/> <action name="mr-node"> <map-reduce> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <delete path="${nameNode}/output/"/> </prepare> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> <!-- 配置调度MR任务时,使用新的API --> <property> <name>mapred.mapper.new-api</name> <value>true</value> </property> <property> <name>mapred.reducer.new-api</name> <value>true</value> </property> <!-- 指定Job Key输出类型 --> <property> <name>mapreduce.job.output.key.class</name> <value>org.apache.hadoop.io.Text</value> </property> <!-- 指定Job Value输出类型 --> <property> <name>mapreduce.job.output.value.class</name> <value>org.apache.hadoop.io.IntWritable</value> </property> <!-- 指定输入路径 --> <property> <name>mapred.input.dir</name> <value>/input/</value> </property> <!-- 指定输出路径 --> <property> <name>mapred.output.dir</name> <value>/output/</value> </property> <!-- 指定Map类 --> <property> <name>mapreduce.job.map.class</name> <value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value> </property> <!-- 指定Reduce类 --> <property> <name>mapreduce.job.reduce.class</name> <value>org.apache.hadoop.examples.WordCount$IntSumReducer</value> </property> <property> <name>mapred.map.tasks</name> <value>1</value> </property> </configuration> </map-reduce> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name="end"/> </workflow-app>
[bigdata@hadoop002 hadoop-2.5.0-cdh5.3.6]$ bin/hdfs dfs -put /opt/module/oozie-4.0.0-cdh5.3.6/oozie-apps/map-reduce/ /user/bigdata/oozie-apps 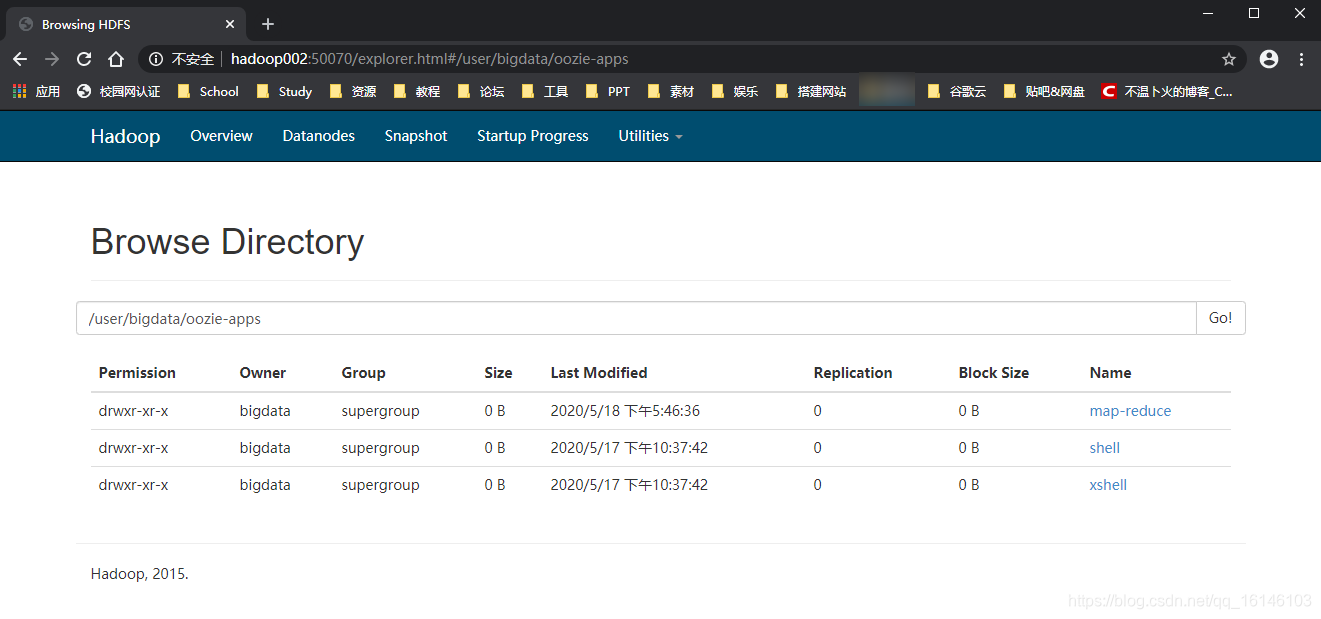
[bigdata@hadoop002 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop002:11000/oozie -config oozie-apps/map-reduce/job.properties -run // 下图为为正在跑的任务 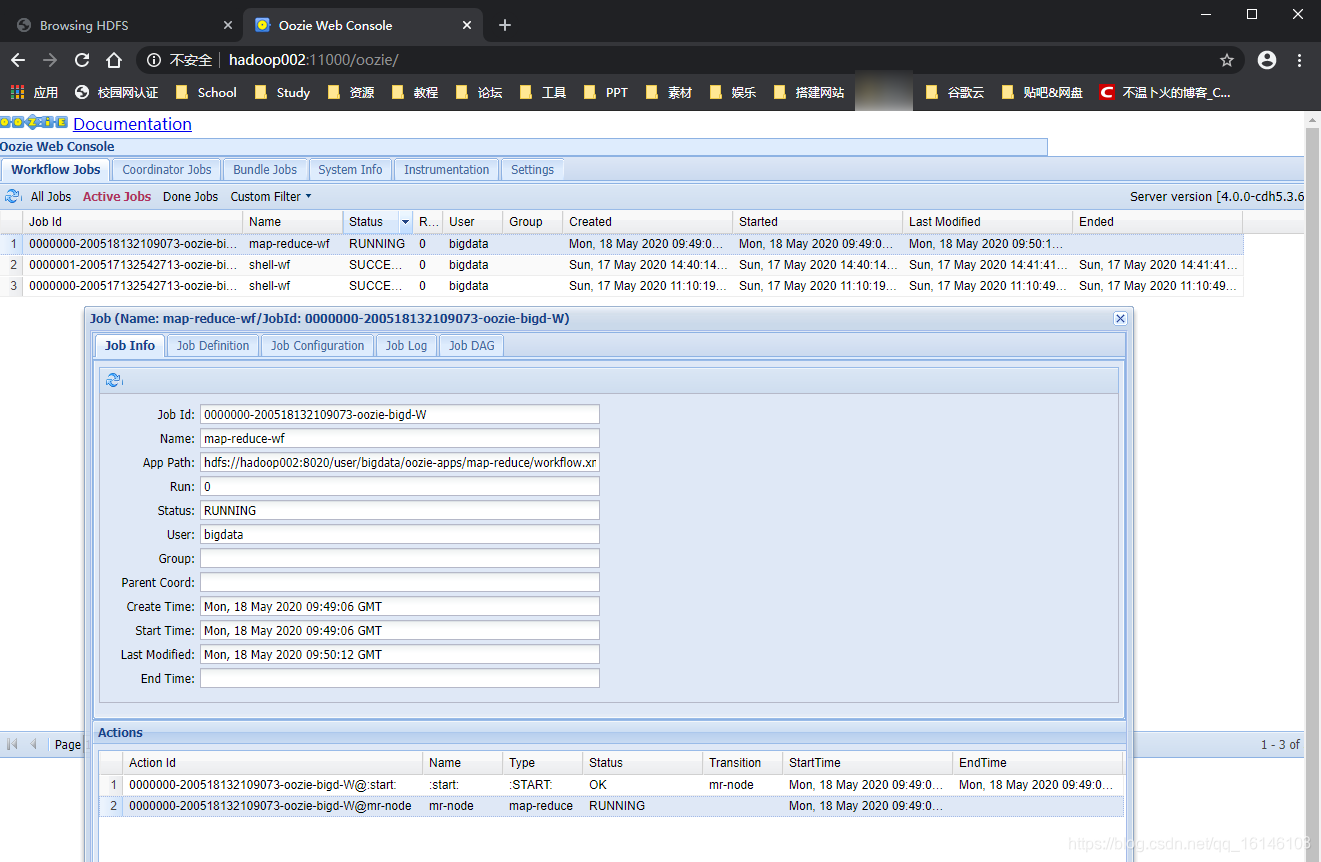
本次的就到这里了,

如果我的博客对你有帮助、如果你喜欢我的博客内容,请“” “评论”“”一键三连哦!听说的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。后不要忘了关注我哦!

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 137
137