注:本篇文章在最后标出的作者的博文基础上进行了完善补充,同时把一些博主亲身操作中的坑都写了出来,一个小白三天的踩坑之路,希望你们能快速的做完这个实验。 安装VMware station,在VMware station中安装Ubuntu系统,搭建Hadoop伪分布系统。这里推荐一个网站,我就是跟着这个一步步做过来的。 话不多说,附上网站: PageRank的基础知识可以从这个博主这学习: 这里直接复制过去,自己写个java就可以进行下一步工作了。 注:这里有个坑需要注意,之前 最后打开part-r-00000文件,这就是最终的输出结果。我们可以看到,各个网页的pagerank值都发生了变化,从输出结果上看,C的pagerank值最大,且并未陷入蜘蛛陷阱,这与实际理论相符。 有时候明明已经删掉了output文件夹,再次运行还是显示output文件夹已存在,再找了好久解决方法终于找到了 这里是格式化HDFS文件的所有数据,在删除了output文件夹之后有时候下次运行还是会报错,在格式化之后就能再次运行了。 如果虚拟机里的hdfs有重要文件的话不要冲动。 文章纯手打,如有错误请指正 注:本文部分文字说明引用自同实验的王老师,感谢这位博主的辛勤付出。
PageRank算法在Hadoop伪分布式下的运行(完整版)分布式数据库实验
第一部分 虚拟机搭建Hadoop伪分布式环境
厦大Hadoop搭建教程
划重点,来了
接下来是踩坑补充:
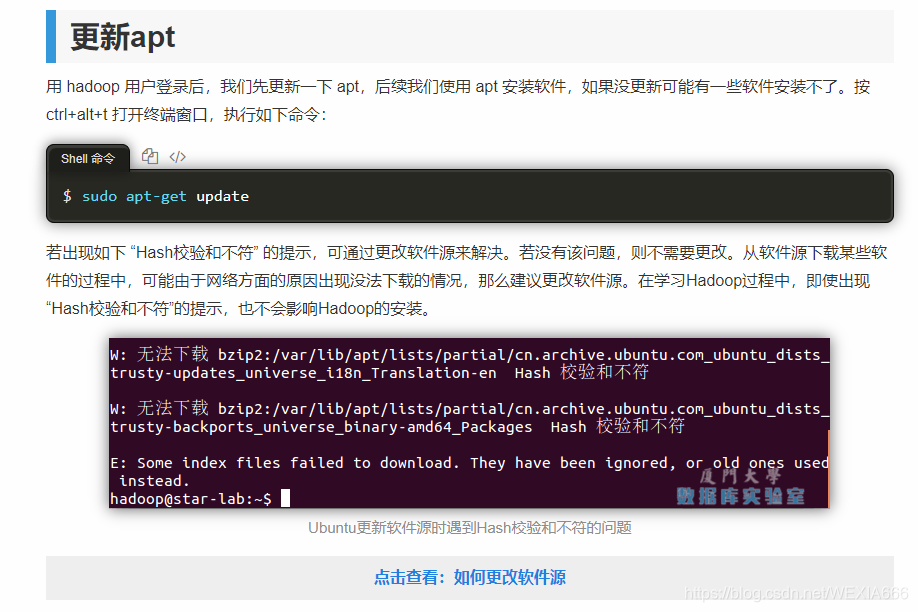
这里我在update的时候,速度慢到怀疑人生,我在换镜像的时候又会网络报错,后来发现无论哪个镜像都会报错,然后在update的时候会出现E: Problem executing scripts APT::Update::Post-Invoke-Success ‘if /usr/bin/test -w /var/的错误
这里提供解决方法:
update报错解决方法
亲测好像一个叫什么ftp的镜像很快。
8u162就是jdk1.8.0_162
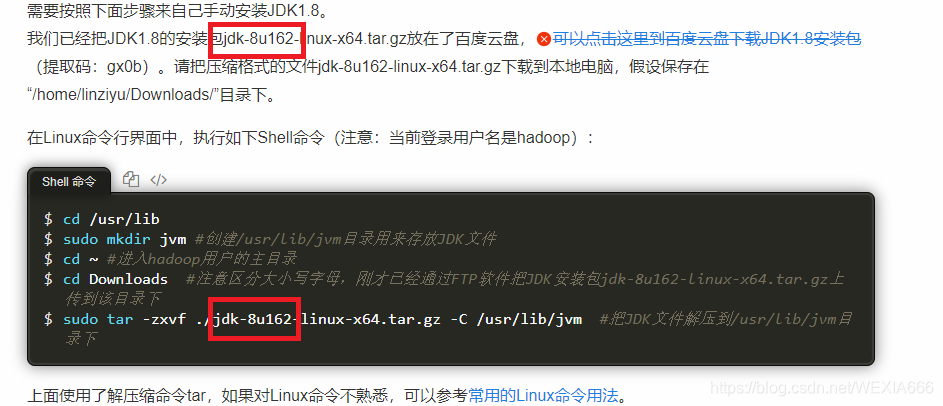

这里就直接写在顶部的最前面,别慌
附上网址:环境变量配置
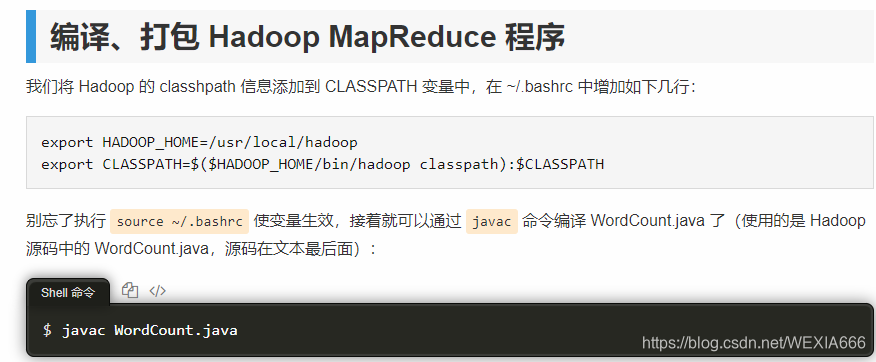
将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,这才是最终的 大功告成。自此,第一部分结束。第二部分 PageRank基础知识及源代码
PageRank基础知识
这里再补充一点小问题,有人可能会不知道这个输入样本是什么:
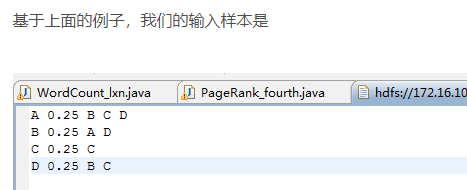
其实很简单,你只要自己新建一个txt,然后里面输入这个就行,中间空一格就行,正好让它读入。
我把这个博主的源代码整合了一下,然后改成PageRank了,原博主的是PageRank_fourthimport java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class PageRank { public static class PRMapper extends Mapper<Object,Text,Text,Text>{ private String id; private float pr; private int count; private float average_pr; public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ StringTokenizer str = new StringTokenizer(value.toString());//对value进行解析 id = str.nextToken();//id为解析的第一个词,代表当前网页 pr = Float.parseFloat(str.nextToken());//pr为解析的第二个词,转换为float类型,代表PageRank值 count = str.countTokens();//count为剩余词的个数,代表当前网页的出链网页个数 average_pr = pr/count;//求出当前网页对出链网页的贡献值 String linkids ="&";//下面是输出的两类,分别有'@'和'&'区分 while(str.hasMoreTokens()){ String linkid = str.nextToken(); context.write(new Text(linkid),new Text("@"+average_pr));//输出的是<出链网页,获得的贡献值> linkids +=" "+ linkid; } context.write(new Text(id), new Text(linkids));//输出的是<当前网页,所有出链网页> } } public static class PRReduce extends Reducer<Text,Text,Text,Text>{ public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{ String lianjie = ""; float pr = 0; /*对values中的每一个val进行分析,通过其第一个字符是'@'还是'&'进行判断 通过这个循环,可以 求出当前网页获得的贡献值之和,也即是新的PageRank值;同时求出当前 网页的所有出链网页 */ for(Text val:values){ if(val.toString().substring(0,1).equals("@")){ pr += Float.parseFloat(val.toString().substring(1)); } else if(val.toString().substring(0,1).equals("&")){ lianjie += val.toString().substring(1); } } pr = 0.8f*pr + 0.2f*0.25f;//加入跳转因子,进行平滑处理 String result = pr+lianjie; context.write(key, new Text(result)); } } public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); FileSystem hdfs = FileSystem.get(conf); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } String pathIn0 = otherArgs[0]; String pathOut = otherArgs[1]; for(int i=1;i<41;i++){ //加入for循环 Job job = Job.getInstance(conf,"page rank"); job.setJarByClass(PageRank.class); job.setMapperClass(PRMapper.class); job.setReducerClass(PRReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(pathIn0)); FileOutputFormat.setOutputPath(job, new Path(pathOut)); pathIn0 = pathOut;//把输出的地址改成下一次迭代的输入地址 pathOut = pathOut+i;//把下一次的输出设置成一个新地址。 job.waitForCompletion(true);//把System.exit()去掉 } } } 第三部分 PageRank算法在Hadoop伪分布式下的运行
javac PageRank.java 
2. 生成jar文件jar cvf ./pagerank.jar ./*.class 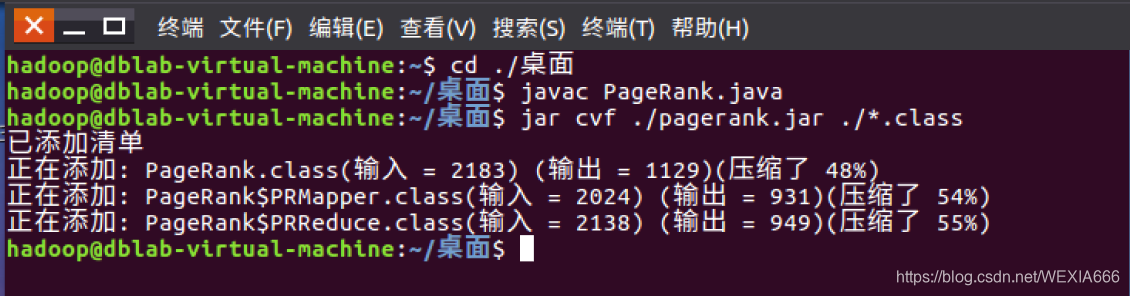
1.进入Hadoop路径下2.启动Hadoop伪分布式环境,命令如下图所示cd /usr/local/hadoop ./sbin/start-dfs.sh 终端输入jps可以看节点开启状态 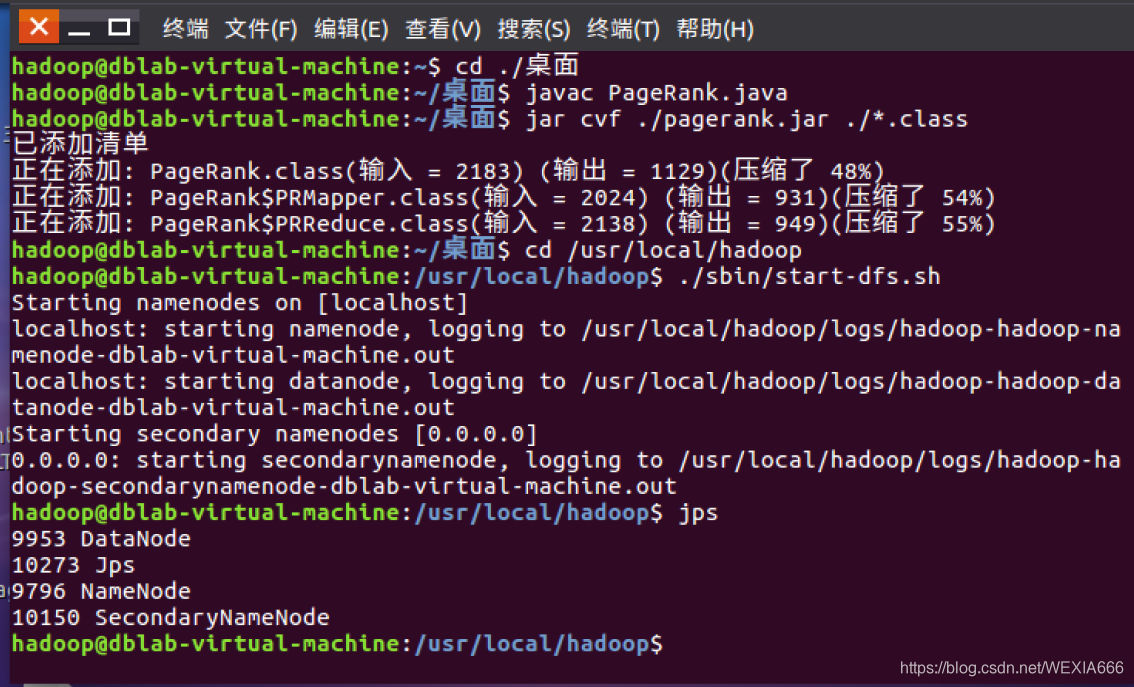
运行pagerank.jar文件和pagerank.txt文件分为以下几个步骤:1.创建input文件夹2.将PageRank.txt文件放入hdfs下面的input文件夹下3.把txt文件使用jar运行。
首先创建input文件夹,用于存放txt文件夹。运行程序必须都在hdfs路径环境下,因此命令如下:./bin/hdfs dfs -mkdir /input ./bin/hdfs dfs -put ~/桌面/PageRank.txt /input 
注:这里因为我之前已经创建了input文件夹,所以显示已经存在./bin/hdfs dfs -ls /input 第一个框中命令语句意思为:将桌面上的PageRank.txt文件放入input文件夹下,第二个语句意思是查看input文件夹下的文件列表,我们看到有一个PageRank.txt文件,就是我们刚刚移动的文件。打开桌面上的txt文件,显示下图内容。A 0.25 B C D,这句话的含义是总共有四个网页进行排序,因此每个pagerank初始值为0.25,B C D 表示通过A可以链接到的页面。很明显,到C的值是最大的,理论上C的输出pagerank值最大,而且C陷入了蜘蛛陷阱。 
最后使用txt文件运行jar文件,命令语句如下图所示。./bin/hadoop jar ~/桌面/pagerank.jar PageRank /input/PageRank.txt /output ./bin/hdfs dfs -ls /input的时候,可以看到

所以你在这的txt名称要跟白框里的名字一样,你再复现的时候有时候名字会变掉的
首先查看output路径下的文件,命令如下所示,显示结果发现有两个文件,其中一个为success文件,表示程序运行成功,另一个即为输出文件。./bin/hdfs dfs -ls /output ./bin/hdfs dfs -cat /output/part-r-00000 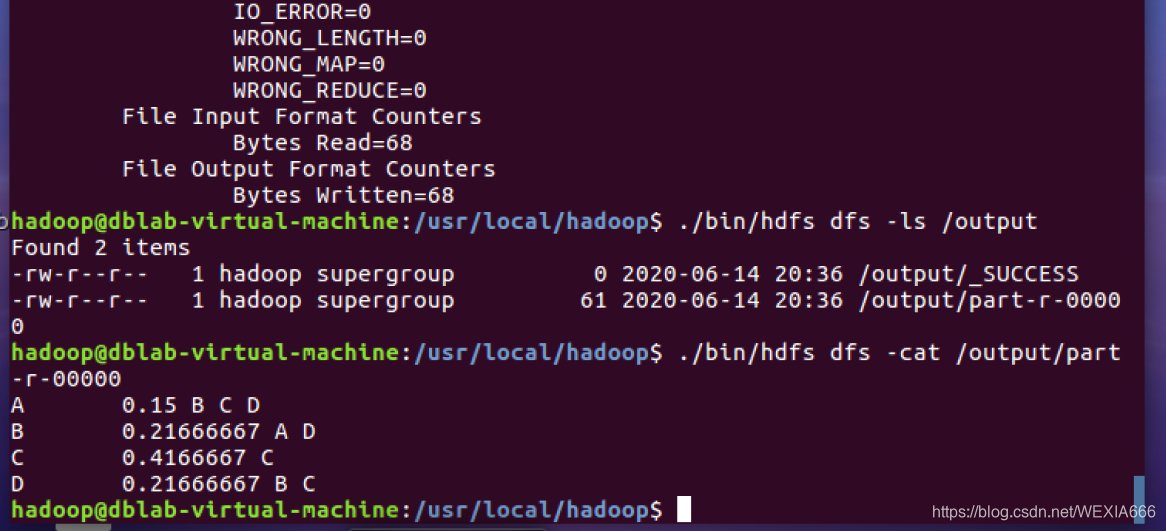
在最后查看完output文件的时候,需要删除掉output文件夹方便下次运行,运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。./bin/hdfs dfs -rm -r output ####关闭hadoop ./sbin/stop-dfs.sh rm -r ./tmp ####删除hdfs的缓存 ./bin/hdfs namenode -format ./sbin/start-dfs.sh
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 3390
3390