本项目旨在使用聚类算法对110个城市进行分类与排序,以寻找客观真实的城市分层方法、支持业务运营与决策。 数据集来源于某互联网公司,特征值标签已做脱敏处理。数据集尺寸为111行×5列,第一行为标题行,其余110行为实例。 首先,由于数据集呈现分类变量与数值变量混合的特点,本次数据分析将采用以下两种算法并在分析结束后进行对比择优: 其次,数值型变量b、c、d的量纲明显不等,为避免量纲影响距离计算中不同变量的权重,需要对变量b、c、d进行处理。由于不知道是否符合正态分布,在这里使用归一化而非标准化。 最后,由于机器无法理解业务场景,算法本身无法对不同聚类进行排序。在找到合理聚类方法后需要人工构建一个聚类评价指标以实现排序。 本项目基于python 3.7.3,使用的库包括pandas、numpy、sklearn、matplotlib、seaborn、kmodes,具体代码详见附录。 预处理步骤包括: 处理结束后的数据集如下所示(仅展示前五行为例): 城市 a_1 a_2 a_3 a_4 a b c d 三亚 0 0 1 0 3 0.016206 0.009198 0.00757 上海 1 0 0 0 1 1 1 1 东莞 0 0 1 0 3 0.314485 0.187345 0.299205 中山 0 0 0 1 4 0.109215 0.060833 0.057343 临沂 0 0 0 1 4 0.106044 0.035673 0.018547 注1:python中计数从0开始计,所以横轴数值为聚类数量-1 注2:此方法结果具有随机性,有时会产生不止一个肘点,存在最优解和次优解。为确保k=3为最优解,此过程被运行了十次,最后验证最优解众数为3。 为实现聚类排序,首先调取了每个聚类的质点: Centroids(Min-max Scaled) Centroids(原数据) Cluster a b c d a b c d Count 0 4 0.05 0.02 0.01 4 3853.19 6638.98 56.46 48 1 2 0.66 0.52 0.59 2 38517.47 178333.07 3119.33 6 2 2 0.31 0.17 0.15 2 18678.75 60002.46 785.96 24 3 3 0.10 0.04 0.03 3 7053.54 16004.42 148.87 32 此处需要基于业务理解构建一个 其中, 经计算,每个聚类的 Cluster Score Ranking 0 0.04 4 1 1.40 1 2 0.95 2 3 0.42 3 经检视,聚类1、2、3、0非常接近常规认知中的一、二、三、四线城市,证明排序合理。 经过使用k-prototype算法和构建聚类评价指标 城市 a b c d cluster cluster_tag in-cluster_score in-cluster_ranking 上海 1 57874 342463 5286 1 tier1 1.510 1 北京 2 40210 182647 3457 1 tier1 1.162 2 深圳 3 37620 160159 3228 1 tier1 1.116 3 苏州 2 34424 117925 1871 1 tier1 0.897 4 广州 3 29242 105356 2288 1 tier1 0.875 5 杭州 2 31735 161448 2586 1 tier1 0.834 6 城市 a b c d cluster cluster_tag in-cluster_score in-cluster_ranking 东莞 3 18958 64856 1583 2 tier2 0.587 1 南京 2 23572 84459 1266 2 tier2 0.592 2 南昌 2 10282 36616 639 2 tier2 0.260 3 厦门 1 15059 70708 1073 2 tier2 0.369 4 合肥 2 18372 75802 724 2 tier2 0.377 5 哈尔滨 2 16126 29936 332 2 tier2 0.377 6 嘉兴 2 10918 35879 370 2 tier2 0.228 7 大连 2 13676 31977 358 2 tier2 0.311 8 天津 2 25428 65309 1010 2 tier2 0.649 9 宁波 2 21712 64354 928 2 tier2 0.538 10 常州 2 12683 29769 355 2 tier2 0.290 11 成都 3 30619 95611 918 2 tier2 0.681 12 无锡 2 18622 42607 632 2 tier2 0.463 13 武汉 2 21566 92360 1399 2 tier2 0.541 14 沈阳 2 23688 67889 735 2 tier2 0.543 15 泉州 2 15615 63454 761 2 tier2 0.346 16 温州 1 22346 72011 903 2 tier2 0.527 17 湖州 2 6299 17706 156 2 tier2 0.118 18 福州 1 15067 82398 1031 2 tier2 0.327 19 西安 3 23634 57532 1118 2 tier2 0.645 20 重庆 3 31119 76562 656 2 tier2 0.701 21 金华 2 15317 48394 568 2 tier2 0.346 22 长沙 2 19307 77104 822 2 tier2 0.416 23 青岛 2 18305 56769 526 2 tier2 0.393 24 城市 a b c d cluster cluster_tag in-cluster_score in-cluster_ranking 三亚 3 2025 4000 42 3 tier3 0.023 1 九江 3 4582 8585 56 3 tier3 0.080 2 南宁 3 9909 23157 361 3 tier3 0.237 3 南通 3 10861 29783 219 3 tier3 0.216 4 台州 3 11892 27683 221 3 tier3 0.250 5 吉林 3 4658 6652 31 3 tier3 0.083 6 咸阳 3 3754 5903 49 3 tier3 0.065 7 太原 3 7675 16814 248 3 tier3 0.175 8 惠州 3 9378 29550 448 3 tier3 0.220 9 扬州 3 6396 16309 141 3 tier3 0.122 10 新乡 3 4417 6036 58 3 tier3 0.084 11 泰州 3 5609 15036 57 3 tier3 0.089 12 济南 3 13485 32222 297 3 tier3 0.293 13 淄博 3 4308 9902 68 3 tier3 0.071 14 湛江 3 3243 6016 36 3 tier3 0.048 15 潍坊 3 8754 20406 201 3 tier3 0.184 16 烟台 3 7611 15206 110 3 tier3 0.152 17 珠海 3 4775 12372 116 3 tier3 0.085 18 盐城 3 7908 21129 113 3 tier3 0.143 19 石家庄 3 13750 29776 462 3 tier3 0.339 20 绍兴 3 7073 22799 188 3 tier3 0.130 21 芜湖 3 4555 11467 63 3 tier3 0.072 22 荆州 3 3325 4988 20 3 tier3 0.050 23 营口 3 3574 5605 19 3 tier3 0.055 24 蚌埠 3 2961 6873 38 3 tier3 0.039 25 赣州 3 7994 16110 172 3 tier3 0.171 26 郑州 3 18906 42977 432 3 tier3 0.432 27 银川 3 6829 10248 149 3 tier3 0.153 28 镇江 3 6047 20610 101 3 tier3 0.092 29 长春 3 12492 22492 208 3 tier3 0.279 30 黄石 3 2118 4601 22 3 tier3 0.020 31 齐齐哈尔 3 4850 6836 18 3 tier3 0.085 32 城市 a b c d cluster cluster_tag in-cluster_score in-cluster_ranking 中山 4 7305 21639 305 0 tier4 0.161 1 临沂 4 7125 13044 100 0 tier4 0.143 2 乌鲁木齐 4 1825 858 5 0 tier4 0.020 3 佛山 4 11138 33369 560 0 tier4 0.277 4 佳木斯 1 3781 6769 20 0 tier4 0.057 5 兰州 4 5566 10263 128 0 tier4 0.115 6 包头 4 2032 1750 27 0 tier4 0.027 7 呼伦贝尔 4 2499 2107 5 0 tier4 0.034 8 呼和浩特 4 3444 3478 63 0 tier4 0.066 9 唐山 4 4240 5776 25 0 tier4 0.073 10 商丘 4 4619 5356 17 0 tier4 0.083 11 大同 4 2213 2399 8 0 tier4 0.026 12 大庆 2 4379 4913 12 0 tier4 0.077 13 威海 2 5125 10654 83 0 tier4 0.094 14 安阳 4 2582 2371 21 0 tier4 0.038 15 宜昌 4 3298 3941 15 0 tier4 0.052 16 宝鸡 4 2565 1789 12 0 tier4 0.038 17 宿迁 4 3054 5249 19 0 tier4 0.042 18 岳阳 4 2784 3660 13 0 tier4 0.039 19 延边 4 3315 4166 6 0 tier4 0.050 20 开封 4 3523 2555 8 0 tier4 0.060 21 徐州 4 8302 16204 87 0 tier4 0.163 22 揭阳 2 4710 11208 90 0 tier4 0.082 23 日照 4 1190 2352 4 0 tier4 -0.002 24 昆明 4 8389 18251 177 0 tier4 0.176 25 景德镇 1 2304 5690 63 0 tier4 0.029 26 柳州 4 2279 4194 4 0 tier4 0.022 27 桂林 4 3379 4137 23 0 tier4 0.055 28 江门 4 2978 5948 27 0 tier4 0.040 29 泸州 4 2023 2084 5 0 tier4 0.021 30 洛阳 4 4999 4765 38 0 tier4 0.099 31 济宁 4 6007 11411 93 0 tier4 0.117 32 海口 4 4678 17398 148 0 tier4 0.074 33 淮北 4 1105 1636 8 0 tier4 -0.001 34 淮安 4 4921 8405 34 0 tier4 0.085 35 牡丹江 1 4140 5646 20 0 tier4 0.070 36 秦皇岛 4 2449 2005 18 0 tier4 0.035 37 绵阳 4 2895 4501 28 0 tier4 0.042 38 肇庆 4 2932 5465 47 0 tier4 0.044 39 舟山 1 2430 6081 40 0 tier4 0.027 40 西宁 4 1710 1616 19 0 tier4 0.017 41 贵阳 4 4506 7772 181 0 tier4 0.104 42 赤峰 4 3819 3971 19 0 tier4 0.066 43 运城 4 2850 1866 3 0 tier4 0.044 44 连云港 4 3454 6768 40 0 tier4 0.052 45 通辽 4 1702 1491 2 0 tier4 0.014 46 遵义 4 4835 5303 28 0 tier4 0.091 47 鞍山 4 3555 6398 12 0 tier4 0.051 48
1. 分析目标
2. 数据集
3. 方法论
4. 预处理
5. 分析过程
5.1 K-means

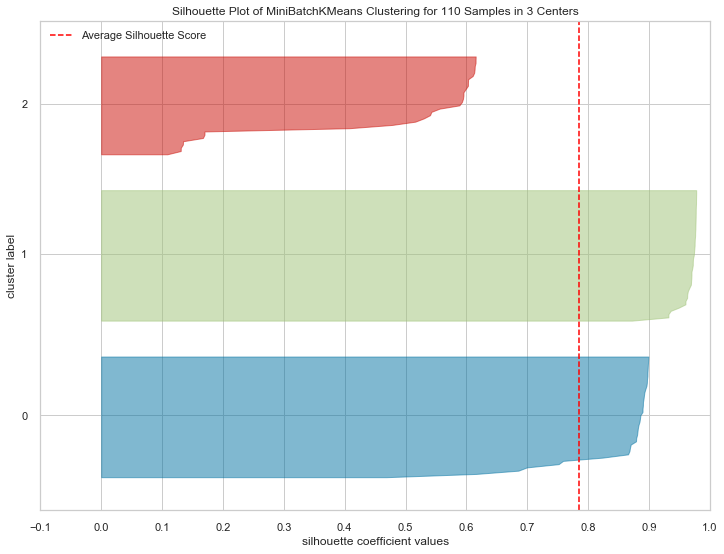

5.2 K-prototype
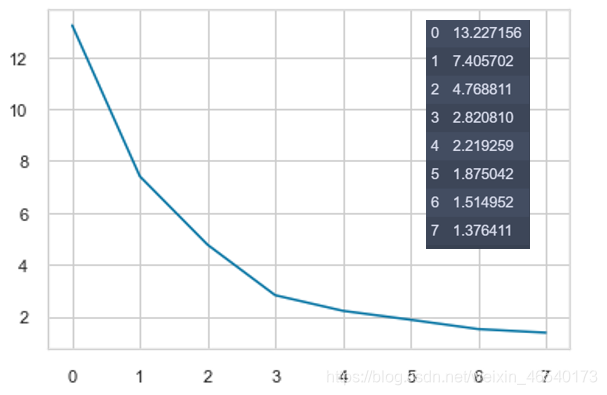
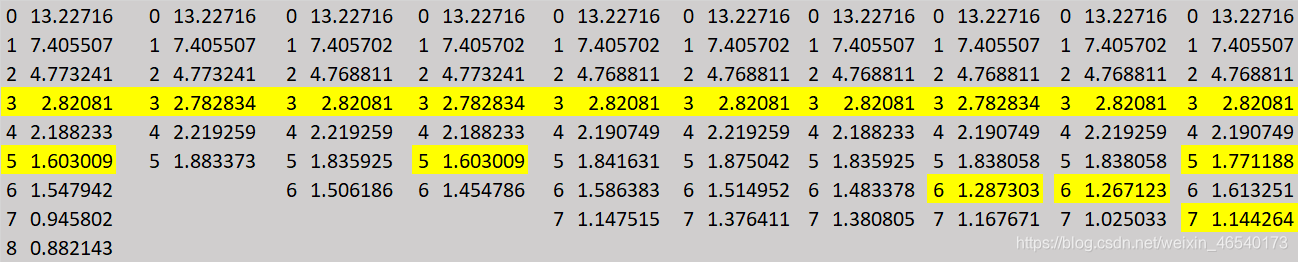
6. 聚类排序
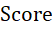 作为聚类评价指标。四个特征值的业务重要程度一致,因此需要采用等权重计算每个特征值的
作为聚类评价指标。四个特征值的业务重要程度一致,因此需要采用等权重计算每个特征值的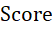 ,但是变量c对总
,但是变量c对总 的贡献为负。但是,考虑到量纲的影响,仍需使用归一化的b、c、d作为其
的贡献为负。但是,考虑到量纲的影响,仍需使用归一化的b、c、d作为其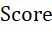 。如果将a作为数值型变量进行考量,也应当进行归一化处理,并且应注意数值越大实际上对
。如果将a作为数值型变量进行考量,也应当进行归一化处理,并且应注意数值越大实际上对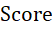 的贡献越低。综上所述,
的贡献越低。综上所述,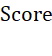 的构建方法如下:
的构建方法如下:
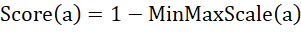



 及排名如下:
及排名如下:
7. 结论
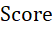 ,成功将110个城市分为四个聚类及聚类排序。同时运用评价指标
,成功将110个城市分为四个聚类及聚类排序。同时运用评价指标 ,结合归一化数据可对个体城市实现细粒度上的评价,从而得到每个聚类内部的城市排名情况或跨四个聚类的总体城市排名:
,结合归一化数据可对个体城市实现细粒度上的评价,从而得到每个聚类内部的城市排名情况或跨四个聚类的总体城市排名:
附录:代码
K-means:
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" %matplotlib inline import pandas as pd import numpy as np from sklearn import preprocessing from sklearn.cluster import KMeans from sklearn.cluster import MiniBatchKMeans from yellowbrick.cluster import KElbowVisualizer from yellowbrick.cluster import SilhouetteVisualizer from yellowbrick.cluster import InterclusterDistance from yellowbrick.model_selection import LearningCurve import matplotlib.pyplot as plt import seaborn as sns sns.set_style("whitegrid") sns.set_context("notebook") df = pd.read_csv('practice_2_clustering_with_cat.csv') df.head() df['a'] = df['a'].astype(object) dummies = pd.get_dummies(df['a'], prefix='a') bcd = df.iloc[:, 2:5] min_max_scaler = preprocessing.MinMaxScaler() x_scaled = min_max_scaler.fit_transform(bcd) X_scaled = pd.DataFrame(x_scaled,columns=bcd.columns) X_scaled = pd.concat([X_scaled,dummies], axis=1,) # Elbow method 手肘法 plt.figure(figsize=(12,9)) model = KMeans() visualizer = KElbowVisualizer(model, k=(1,8)) visualizer.fit(X_scaled) visualizer.show() model=MiniBatchKMeans(n_clusters=3) model.fit(X_scaled) print("Predicted labels ----") model.predict(X_scaled) df['cluster'] = model.predict(X_scaled) plt.figure(figsize=(12,9)) model=MiniBatchKMeans(n_clusters=3).fit(X_scaled) visualizer = SilhouetteVisualizer(model, colors='yellowbrick') visualizer.fit(X_scaled) visualizer.show() plt.figure(figsize=(12,9)) visualizer = InterclusterDistance(model, min_size=10000) visualizer.fit(X_scaled) visualizer.show() df = pd.concat([df,X_scaled], axis=1) dfK-prototype
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" %matplotlib inline import pandas as pd import numpy as np from sklearn import preprocessing from sklearn.cluster import KMeans from sklearn.cluster import MiniBatchKMeans from yellowbrick.cluster import KElbowVisualizer from yellowbrick.cluster import SilhouetteVisualizer from yellowbrick.cluster import InterclusterDistance from yellowbrick.model_selection import LearningCurve import matplotlib.pyplot as plt import seaborn as sns sns.set_style("whitegrid") sns.set_context("notebook") import numpy as np import pandas as pd from kmodes.kprototypes import KPrototypes %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns df = pd.read_csv('practice_2_clustering_with_cat.csv') df.head() df['a'] = df['a'].astype(object) X = df.iloc[:, 1:5] X.columns = ['a','b','c','d'] X.head() min_max_scaler = preprocessing.MinMaxScaler() bcd = X.iloc[:,1:4] x_scaled = min_max_scaler.fit_transform(bcd) X_scaled = pd.DataFrame(x_scaled,columns=bcd.columns) X = pd.concat([df['a'],X_scaled], axis=1) X_matrix = X.values cost = [] for num_clusters in list(range(1,9)): kproto = KPrototypes(n_clusters=num_clusters, init='Cao') kproto.fit_predict(X_matrix, categorical=[0]) cost.append(kproto.cost_) plt.plot(cost) pd.DataFrame(cost) kproto = KPrototypes(n_clusters=6, init='Cao') clusters = kproto.fit_predict(X_matrix, categorical=[0]) print('====== Centriods ======') kproto.cluster_centroids_ print() print('====== Cost ======') kproto.cost_ centroids = pd.concat([pd.DataFrame(kproto.cluster_centroids_[1]),pd.DataFrame(kproto.cluster_centroids_[0])], axis=1) centroids df['cluster'] = clusters df.head()
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 6718
6718