这里附上WIN10利用docker toolbox搭建hadoop和spark集群的方法
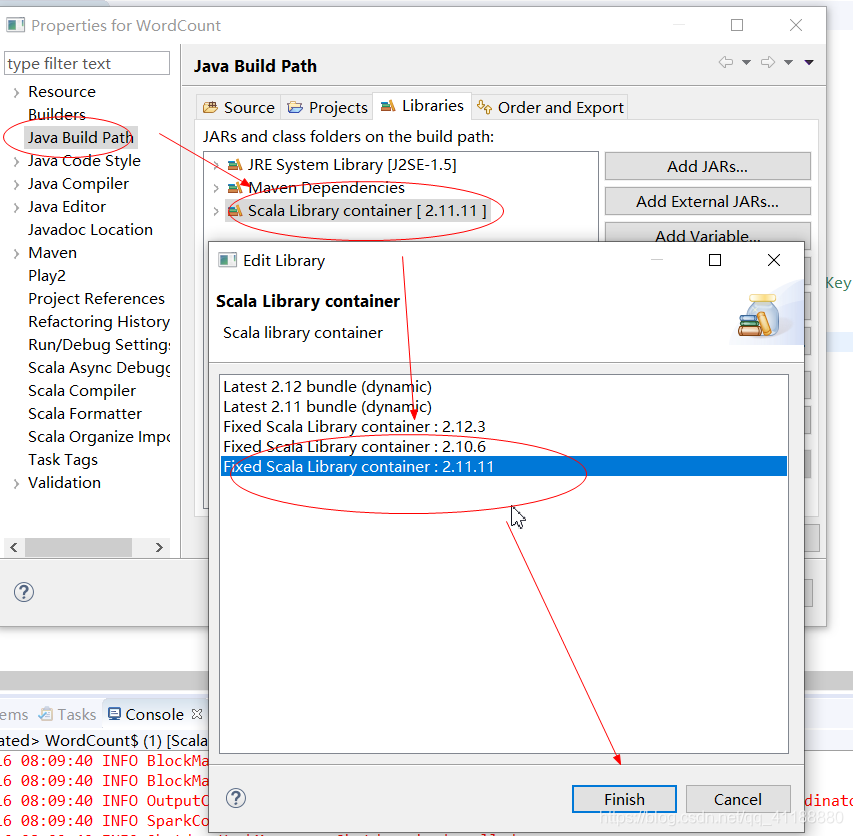
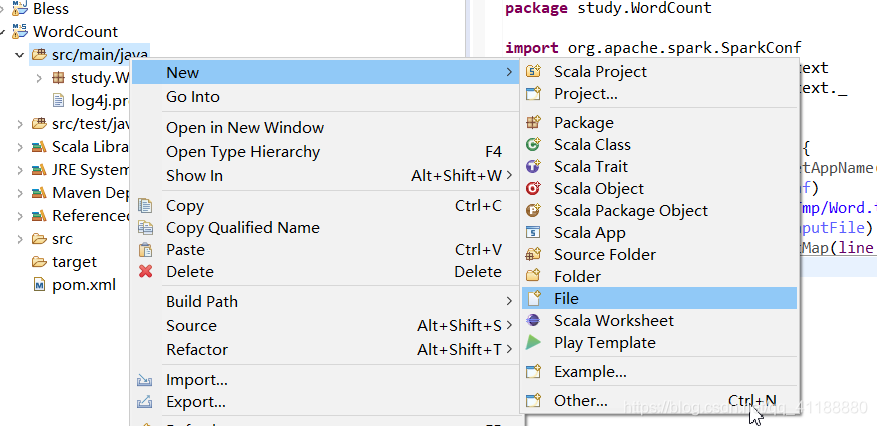
Win:双击可执行文件 请参考菜鸟教程,这里不多介绍。 注意:该步骤非必须,如果使用Scala IDE自带的scala可以直接跳过 将压缩包找一个目录解压 在系统变量中添加SCALA_HOME及安装目录,在PATH里添加% powershell里输入命令 链接:https://pan.baidu.com/s/1p5Xh7lw8clIw1VdIDWVbTQ 找个目录解压 在系统变量中添加HADOOP_HOME及安装目录,在PATH里添加 输入命令 (1)下载插件 maven的安装请参考这篇文章中安装maven的前5步。 下载链接 我的解压目录是E:/eclipse-scala (1)打开窗口—》偏好 (5)Apple and Close (1)新建工程 (2)新建maven工程 (4)设置ID和版本等,完成创建 (5)添加scala属性 (6)修改pom.xml (7)如下图这样编辑pom.xml (8)新建scala object (9)设置属性 (10)设置scala库 (12)将这段代码复制进去 (1)在scala文件里输入如下代码 (2)运行结果 (3)集群运行后续步骤 在本地磁盘创建words.txt,将本地文件上传至namenode子容器 git bash 切换到namenode子容器 上传容器中的words.txt到hdfs /user目录下 Git bash 切换到spark-master子容器 执行jar包
Win10 Spark集群本地开发环境搭建
一、安装Java
1.下载java
2.安装java
Linux:解压压缩包3.配置环境变量
二、安装scala
1.下载scala
2.安装scala
3.配置scala环境变量
%SCALA_HOME%bin4.验证安装
scala -version验证
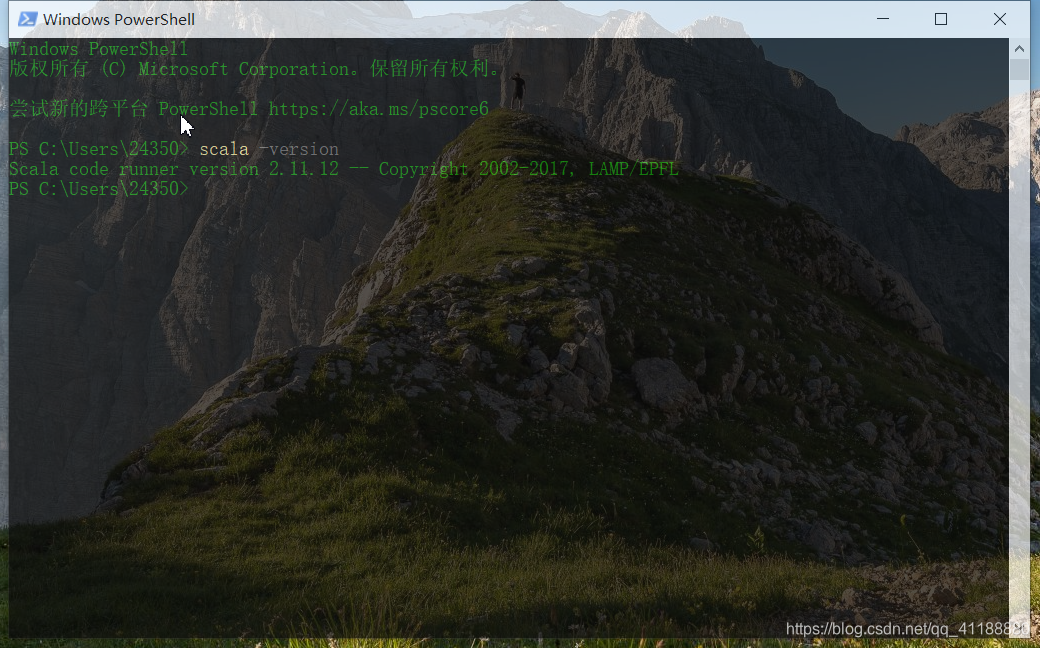
三、安装Hadoop
1.下载hadoop2.7.7
提取码:pqer2.解压hadoop
3.配置hadoop环境变量
%HADOOP_HOME%bin和%HADOOP_HOME%sbin4.验证安装
hadoop version验证
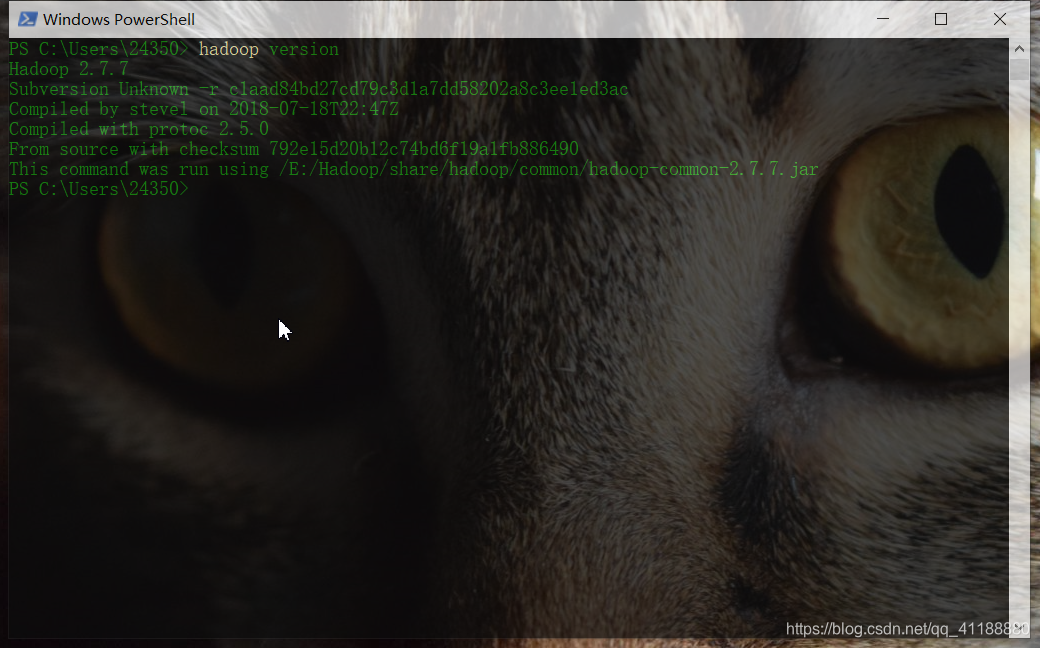
5.配置hadoop插件
链接:https://pan.baidu.com/s/1GhhpPlttjXEy55gQop-ExQ
提取码:p5y4
(2)将hadoop.dll放到系统文件的Windows下的System32文件下。winutils放置在hadoop的bin目录下。四、安装maven
五、安装Scala IDE
1.下载Scala IDE
注意:截止到2020-06-15,官网已经不再提供scala的eclipse插件安装方式,以后是否会恢复不可预知。

2.解压zip包
3.配置maven工程
(2)这样,那样,再这样
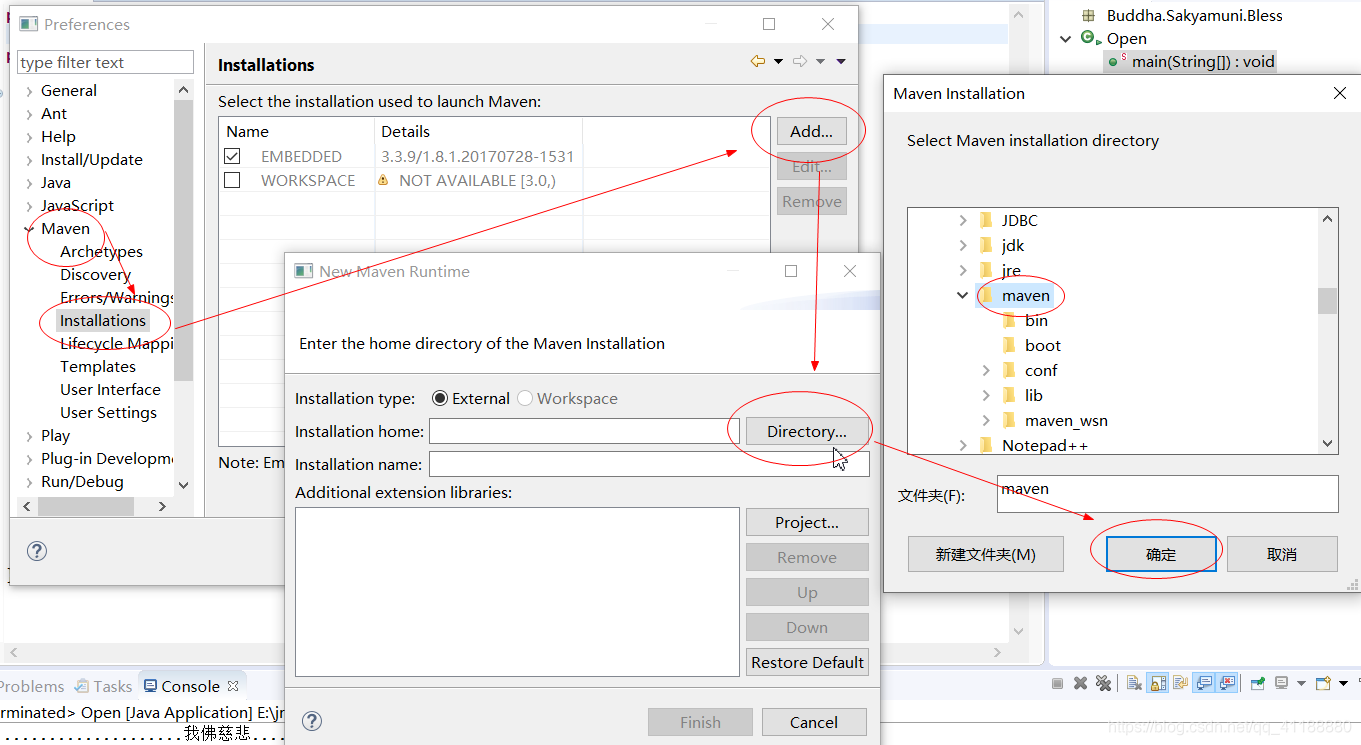
(3)那样,这样,最后这样
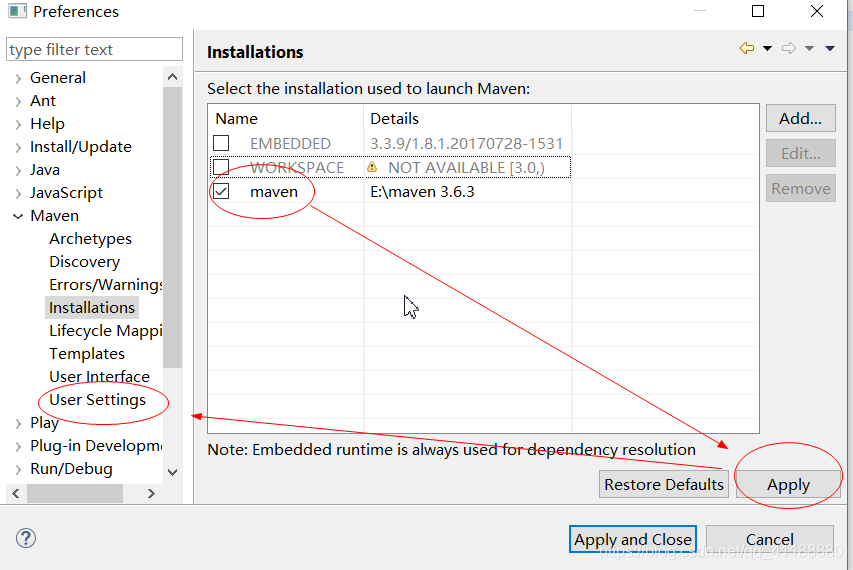
(4)更改settings.xml为用户自定义(maven安装时修改过的那个maven设置文件)
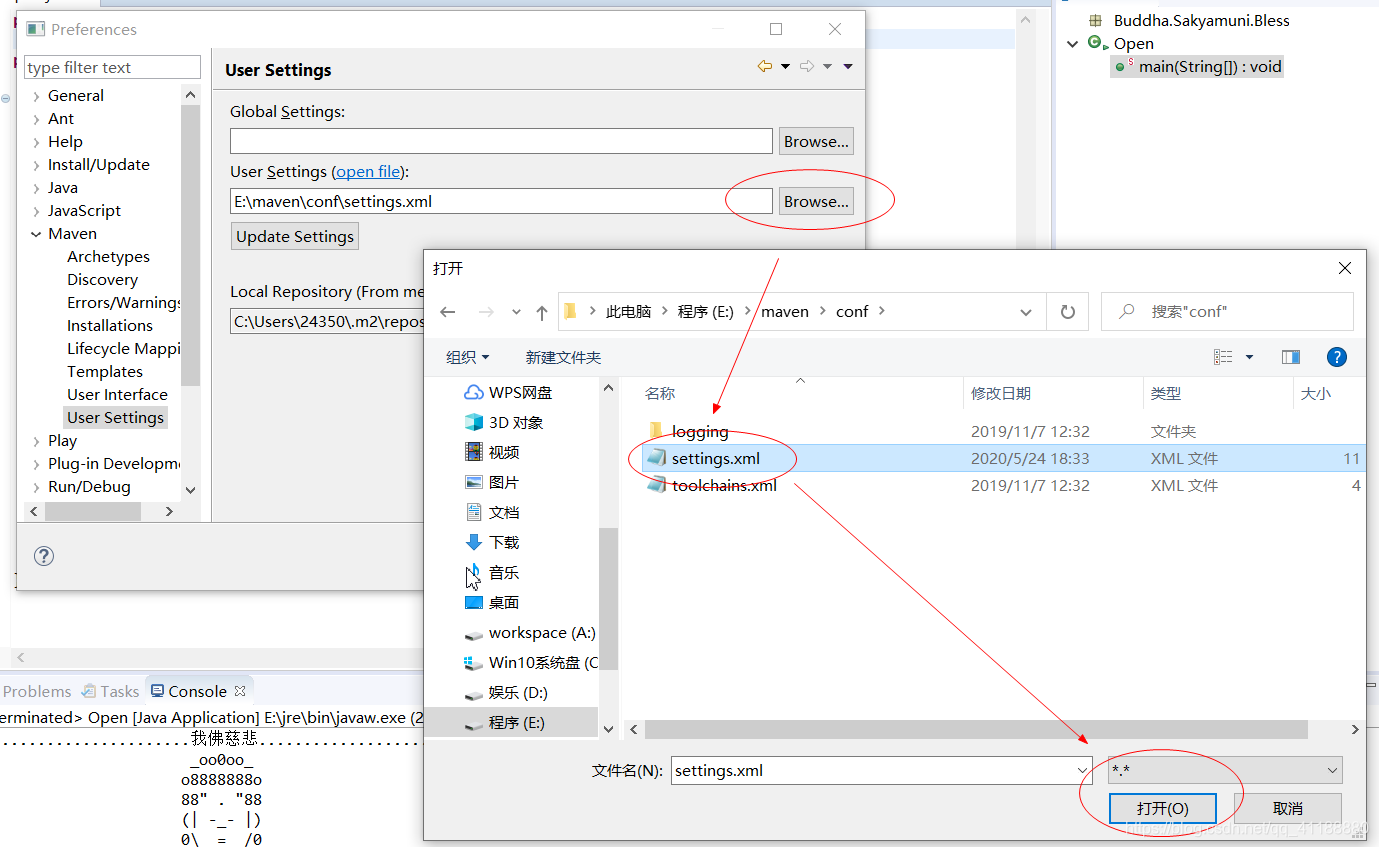
六、利用maven创建Spark工程并使用scala编程
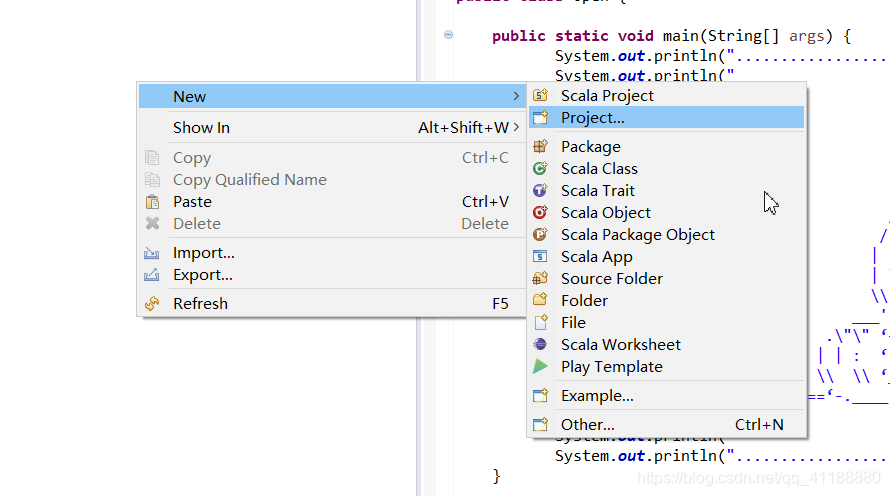
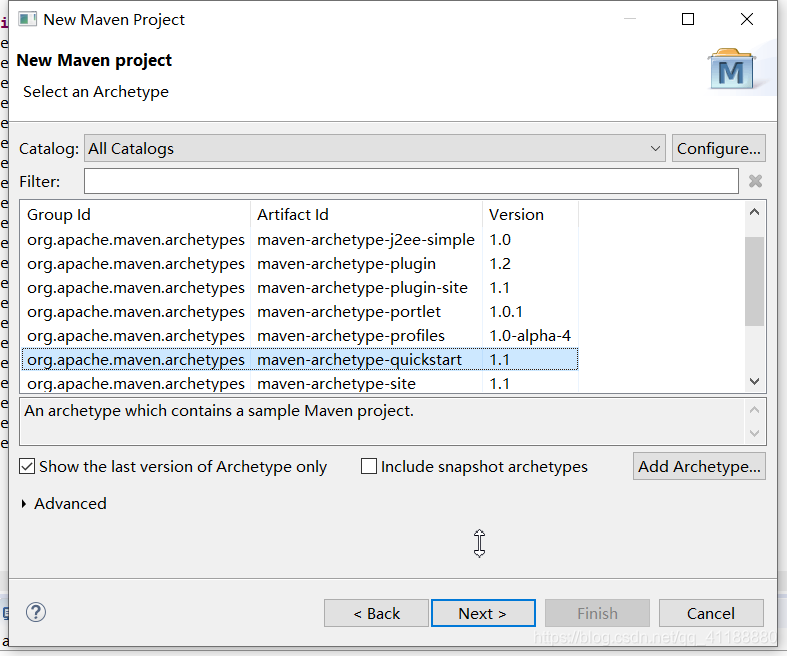
1.创建工程
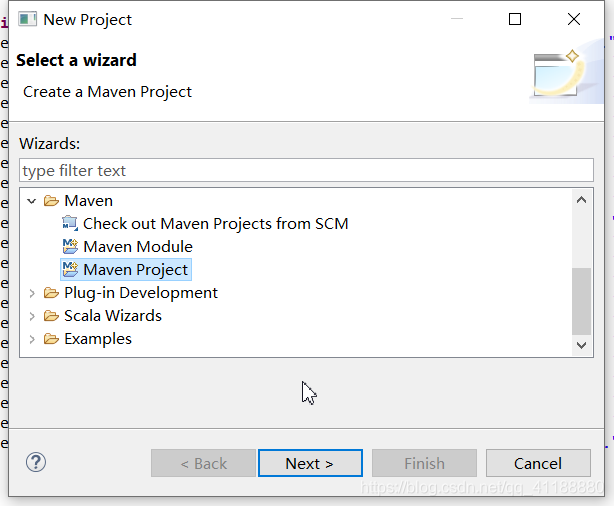
(3)使用默认工作地址,使用quickstart
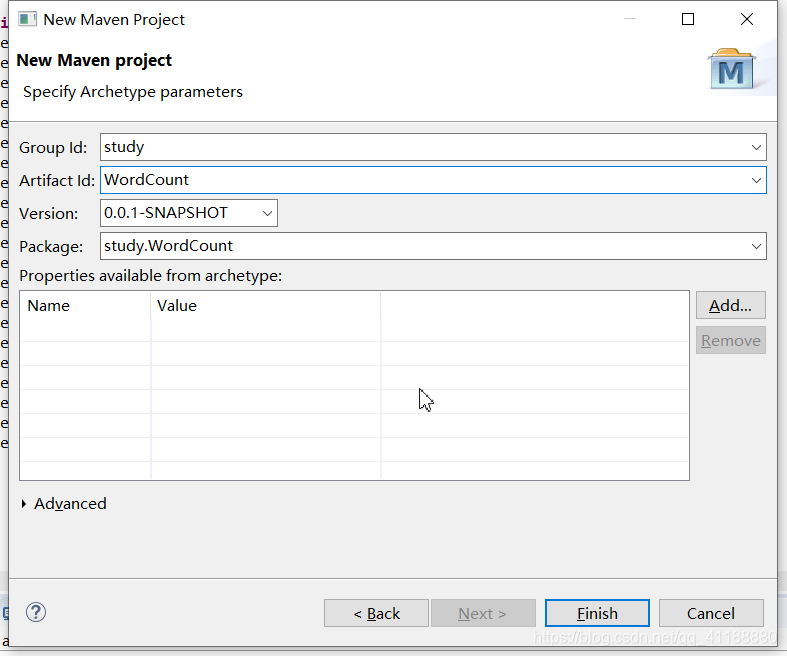
把下边的代码复制进pom.xml里<project xmlns="https://maven.apache.org/POM/4.0.0" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>study</groupId> <artifactId>WordCount</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>WordCount</name> <url>https://maven.apache.org</url> <mirror> <id>nexus</id> <mirrorOf>*</mirrorOf> <url>https://maven.aliyun.com/nexus/content/groups/public/</url> </mirror> <mirror> <id>nexus-public-snapshots</id> <mirrorOf>public-snapshots</mirrorOf> <url>https://maven.aliyun.com/nexus/content/repositories/snapshots/</url> </mirror> <!-- 设置公共属性 --> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.version>2.11</scala.version> <spark.version>2.1.0</spark.version> </properties> <!-- 设置第三方依赖库的资源服务器 --> <repositories> <repository> <id>maven-ali</id> <url>https://maven.aliyun.com/nexus/content/groups/public//</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> <checksumPolicy>fail</checksumPolicy> </snapshots> </repository> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>https://scala-tools.org/repo-releases</url> </repository> </repositories> <!-- 设置maven插件的资源服务器 --> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>https://download.eclipse.org/releases/indigo/</url> </pluginRepository> </pluginRepositories> <!-- 设置第三方依赖库 --> <dependencies> <!-- spark核心依赖包 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <!-- 单元测试依赖包 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> </dependencies> </project>
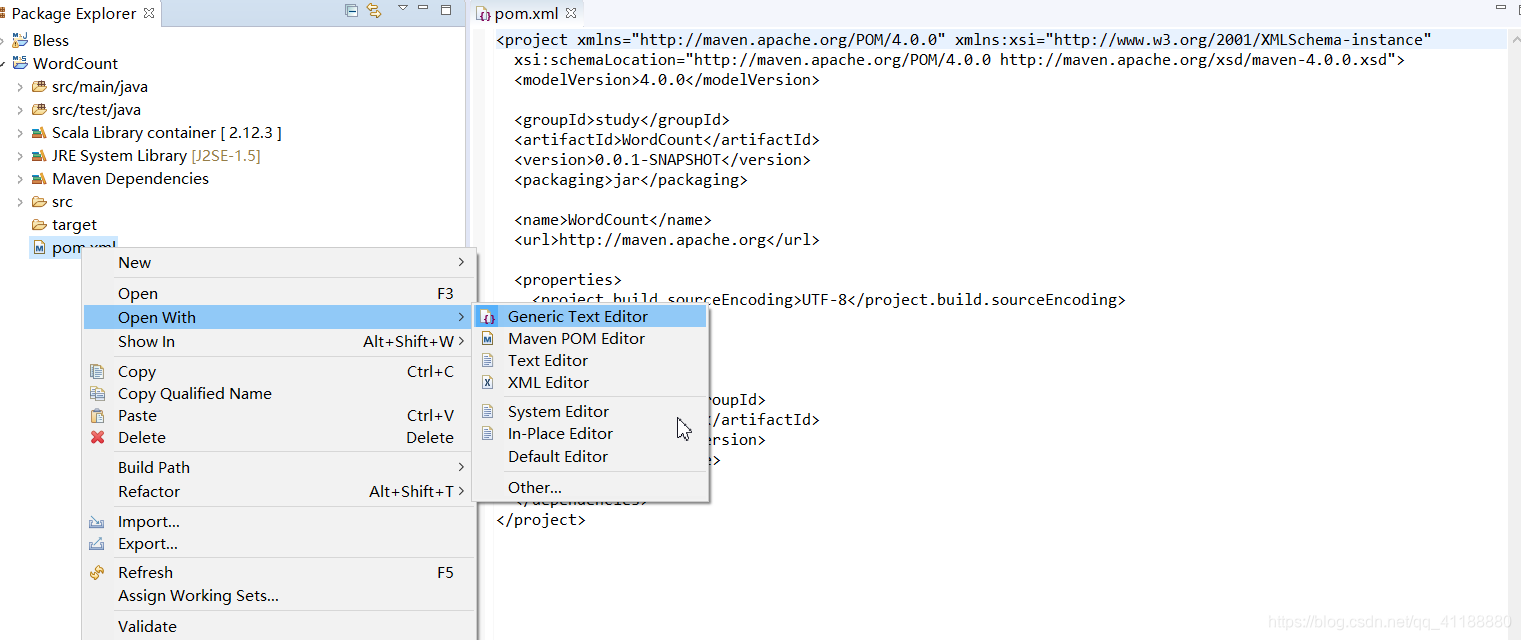
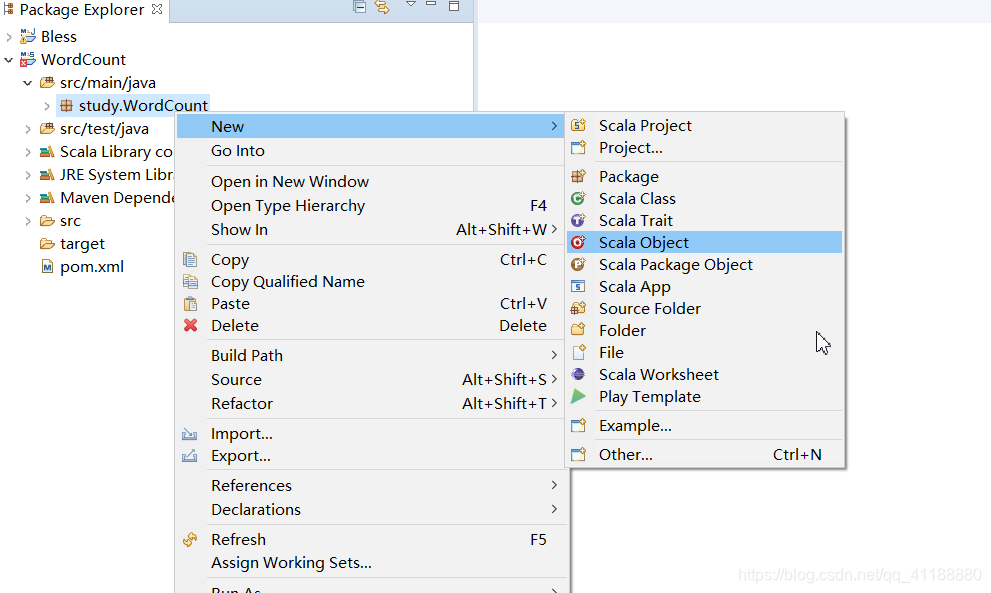

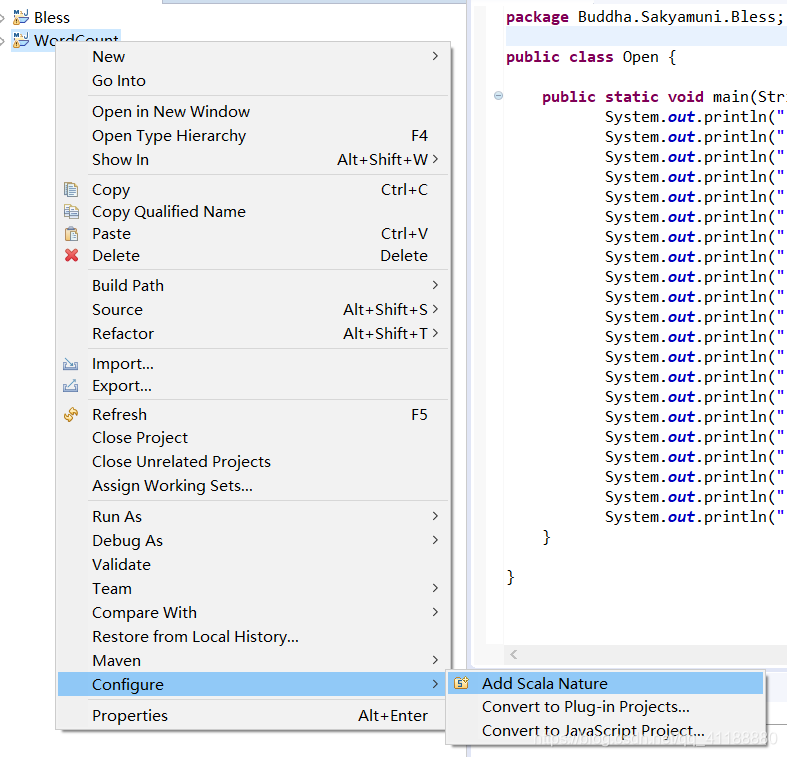
(11)新建一个文件并命名为log4j.properties
# Configure logging for testing: optionally with log file #log4j.rootLogger=debug,appender #log4j.rootLogger=info,appender log4j.rootLogger=error,appender #u8F93u51FAu5230u63A7u5236u53F0 log4j.appender.appender=org.apache.log4j.ConsoleAppender #u6837u5F0Fu4E3ATTCCLayout log4j.appender.appender.layout=org.apache.log4j.TTCCLayout 2.编写一个单词计数程序
注意:word.txt需要自己创建,这里为了方便演示没有使用hdfs的地址,如果想要在spark集群和hadoop集群里运行,请更换为hdfs地址,并设置outputpackage study.WordCount import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ object WordCount { def main(args:Array[String]) { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val inputFile = "file:///A:/Tmp/Word.txt" val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }

将程序打包,上传到docker容器(spark-master子容器根目录下)
命令:docker cp XXXXXXX.jar spark-master:/
命令:docker cp words.txt namenode:/
命令:winpty docker exec -it namenode bash
命令:hadoop fs –put words.txt /user
命令:winpty docker exec -it spark-master bash
命令:Spark/bin/spark-submit --class study.WordCount.WordCount --master spark://spark-master:7077 XXXXXXX.jar
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 3643
3643