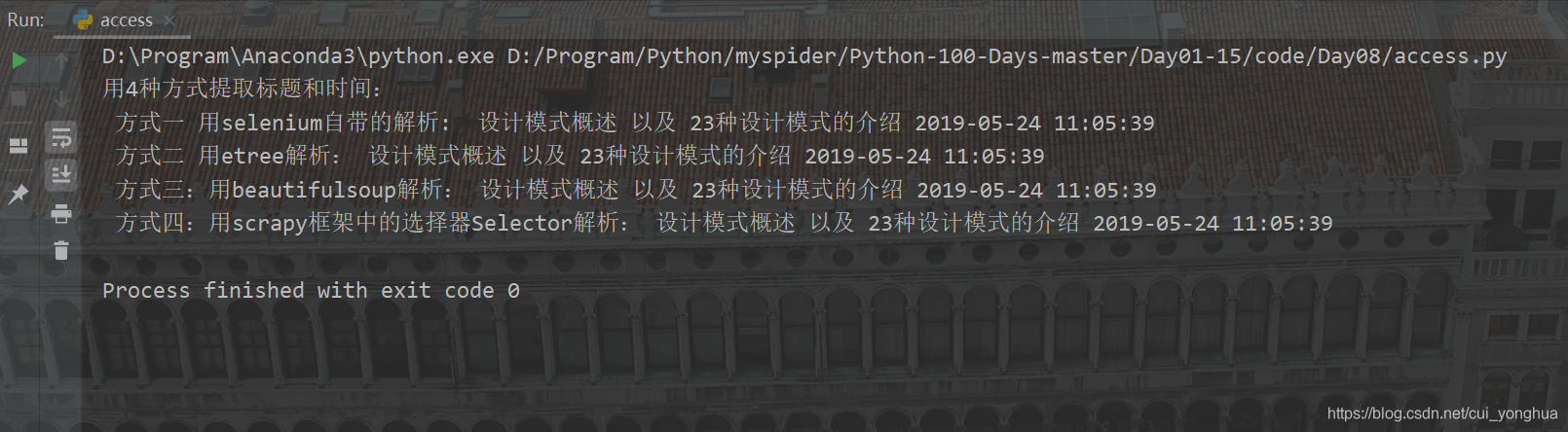
为了方便susu学习selenium,下面代码用selenium爬取博客文章的标题和时间,并用selenium自带的解析,etree,bs4,scrapy框架自带的selector等4种方式来解析网页数据; 当然,请求库还可以使用urllib,requests;也可以用aiohttp来实现异步爬取,用Splash实现动态渲染页面的抓取。 执行结果如下图:
# -*- encoding: utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options from lxml import etree from bs4 import BeautifulSoup from scrapy import Selector def selenium_test(url): # 设置无头浏览器,字符编码,请求头等信息,防止反爬虫检测 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('lang=zh_CN.UTF-8') UserAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36' chrome_options.add_argument('User-Agent=' + UserAgent) browser = webdriver.Chrome(chrome_options=chrome_options) browser.get(url) print('用4种方式提取标题和时间:') # 解析数据 方式一:用selenium自带的解析 title = browser.find_element_by_xpath('//h1[@class="title-article"]').text publish_time = browser.find_element_by_xpath('//div[@class="bar-content"]/span[@class="time"]').text print(' 方式一 用selenium自带的解析: ', title, publish_time) # 解析数据 方式二:用etree selector = etree.HTML(browser.page_source) title = selector.xpath('//h1[@class="title-article"]/text()')[0] publish_time = selector.xpath('//div[@class="bar-content"]/span[@class="time"]/text()')[0] print(' 方式二 用etree解析:', title, publish_time) # 解析数据 方式三:用beautifulsoup soup = BeautifulSoup(browser.page_source, 'lxml') title = soup.find('h1', {'class': 'title-article'}).text publish_title = soup.find('div', {'class': 'bar-content'}).find('span', {'class': 'time'}).text print(' 方式三:用beautifulsoup解析:', title, publish_title) # 解析数据 方式四:用scrapy框架中的选择器Selector selector = Selector(text=browser.page_source) title = selector.xpath('//h1[@class="title-article"]/text()').extract_first() publish_time = selector.xpath('//div[@class="bar-content"]/span[@class="time"]/text()').extract_first() article_list = selector.xpath('//div[@class="markdown_views prism-atom-one-dark"]').extract() article = ''.join(article_list) if len(article_list) > 0 else None print(' 方式四:用scrapy框架中的选择器Selector解析:', title, publish_time) # 可以把博客文章保存到本地,然后用浏览器打开,会发现博客文章和网页上的结构是一样的 # with open('article.html', 'w') as f: # f.write(article) selenium_test(url='https://blog.csdn.net/cui_yonghua/article/details/90512943')
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 1900
1900