OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。 1、Windows版本Tesseract各版本下载,本教程用的版本是tesseract-ocr-w64-setup-v5.0.0.20190623(【注意】要3.0以上才支持中文)。 2、各版本对应字库要识别简体中文需要下载chi_sim.traindata字库(【注意】根据版本下载对应字库)。 3、jTessBoxEditor官网下载,用来训练字库的,带FX的版本才支持中文。 4、各位打不开链接的朋友,看这里: 链接:https://pan.baidu.com/s/1ViyFSR9CjXVy8b7mQeTISQ 这个就不截图了 安装完成后我们配置环境变量 1、配置系统环境变量 tesseract-ocr-Home C:Program FilesTesseract-OCR path : 加上新配置的信息 ;%tesseract-ocr-Home% 2、配置字库-后期JAVA API要使用 TESSDATA_PREFIX C:Program FilesTesseract-OCRtessdata 备注:将下载好的字库放到Tesseract-OCR项目的tessdata文件夹里面。 在cmd窗口输入tesseract -v,配置成功如下图: 例如我的图片识别就是: 1、执行命令: 2、原图片: 3、识别结果: 这一期就先这样了
一:简介
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修改bug、优化,重新发布。二:下载
项目github地址:Tesseract
提取码:m87b 三:安装
四:配置环境变量
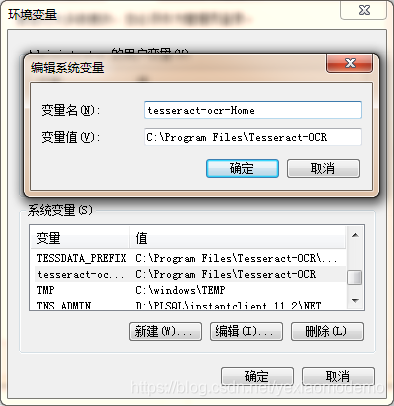
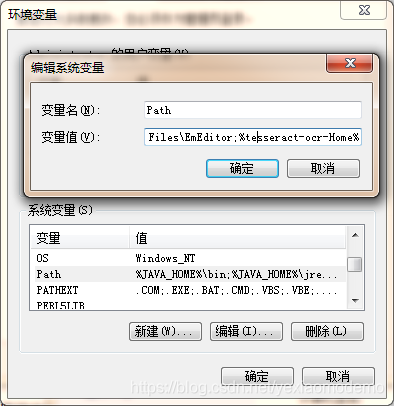
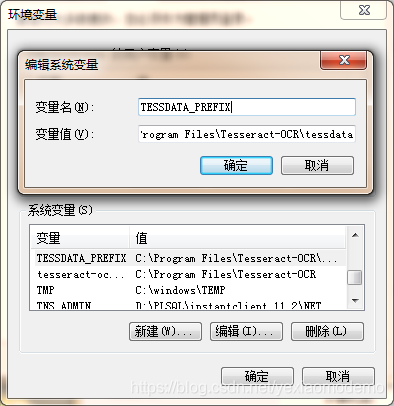
五:验证安装的效果
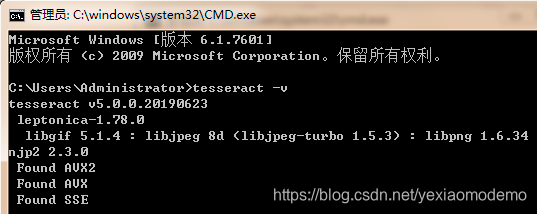
六:识别-看看识别的效果
1、tesseract 图片名称 生成的结果文件的名称 字库
tesseract test.png result -l eng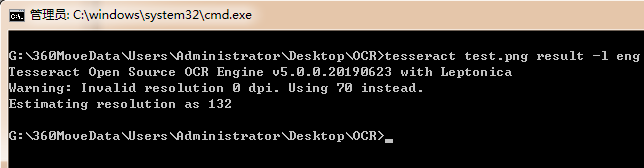
![]()
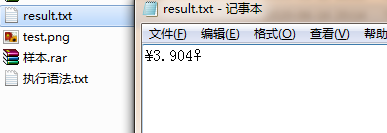
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 1836
1836