最近在读丁奇大佬的《MySQL实战45讲》,收获很大,所以准备跟着写一点笔记总结。 用户通过SQL访问数据的基本过程,就是:客户端-Server层-存储引擎层-磁盘。 客户端通过连接器与Sever层相连,SQL语句在Sever层中“畅游”一番后便知晓了用户想要干什么,然后,执行器操作数据引擎,进行存储/获取数据。 Server层除了图中各种“xx器”之外还含有MySQL中所有的内置函数(如:sum(),count()等),所有跨存储引擎的功能也都存在于此,比如说:存储过程,触发器,视图等。 存储引擎主要是:InnoDB、MyISAM、Memory三种,自MySQL5.5.5版本后InnoDB成为了MySQL的默认存储引擎。 选择存储引擎的SQL语句 输入以上信息之后,连接器会跟服务器建立连接,在完成经典的TCP握手后,连接器开始通过你输入的用户名和密码来进行身份认证,认证不成功会返回“Access denied for user”的错误,认证成功会在权限表中查询你所拥有的权限,进而给你相应的操作权力。 使用 show processlist 命令能够查询所有的连接,Commend这一行出现Sleep就表明这个连接处于空闲状态,如果长时间没有操作,这个连接就将在wait_timeout时间后断开,这个参数的默认值是8小时。 长连接是指连接成功后,客户端持续请求都一直使用的一个连接叫长连接。短连接是执行几次查询后就断开的连接,下次查询再重新建立一个连接。 建立连接的过程是复杂的,所以要尽量少建立连接,也就是尽量使用长连接。 如果全部使用长连接,MySQL会涨的特别快,有些资源只有再连接断开时才能释放,可能导致内存占用太大,被系统强行杀掉,造成MySQL异常重启。 一般解决这种问题有下面两个方案: MySQL缓存是个很鸡肋的东西,已经再MySQL 8.0版本后彻底删除。 MySQL缓存将他的查询请求的结果放在缓存中,当再次查询这个语句时从缓存里直接把之前的结果拿出来,效率就很高,但是表中每增加或修改一次数据都会造成缓存的失效导致维护成本很高。 下面是一个缓存查询的SQL 分析器主要功能就是 处理语法 和 解析查询,分析SQL中的每一个关键字,判断语法是否正确、语句中的表和列是否存在,且select后面的列名有没有歧义,比如说:user表和type表中都有name字段,那么select name from use,type是肯定通过不了的。 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。 就以下面为例 优化器会根据执行效率的不同选择更优者。其实在这里面我遇到和考虑了一些问题,主要是SQL语句层面的: 以前,一个同学跟我讲 where 后面的筛选条件的排序很重要,因为where后面的条件是顺序执行的,比如说下面一个查询。 从实际情况来看 age > 30 的学生很少,被筛选掉的可能更高,所以如果按照顺序执行的原则来说,讲age > 30放在and前面的选择才是好的选择。 但是!当我知道了优化器,我发现我想当然了,MySQL比我想象的更强大,它能够根据实际的情况来选择SQL执行的顺序 另外,在学习丁奇课程时上面那个例子的解释让我又有点迷茫了,是下面这段SQL 他说:“既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2 里面 d 的值是否等于 20…”。 我之前一直所认为的是 t1 与 t2表先连接成笛卡尔积之后才会通过 where 后面的条件进行筛选. 但是!!! 我又想当然了,在网上很多人给的执行顺序也是 from > join > on > where … 的执行顺序,但是实际上SQL 中 得join是使用一种为Nest Loop Join嵌套循环(具体文章请见). 优化器先会选择驱动表比如说当 t1中c=10的次数少于t2中d=20的次数那么选择器就会选择t1做驱动表,然后通过t1.c=10筛选出一行数据再在t2表中查找t2.d=20并且t1.id=t2.id的数据行,遍历完毕t2后,再重新在t1中查找符合t1.c=10的数据,依次交替,直到查询玩所有的数据。 我们写的SQL的表连接顺序,会尽量使用查询结果集最小的表作为驱动表(左表-自行理解),前提是连接顺序改变不会改变查询结果,然后按照优化后的顺序和其他的表逐渐连接查询。 也就是说left join连接并不一定是从左边关联到右边,也有可能是从右边关联到左边,left join仅仅是保证左侧表符合条件的记录会进入到结果集中。 进入执行器之后,先要判断一下你有没有操作这个表的权限,如果没有就会返回没有权限的错误,如果有就打开表,去调用存储引擎的接口。基本流程如下: 数据库的慢查询日志中会有一个rows_examined代表这个SQL语句执行过程中总共查询了多少行。
MySQL结构总览
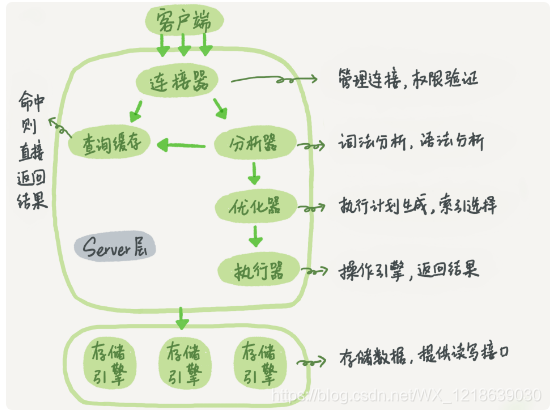
上面是MySQL的逻辑架构图,由它可见MySQL大致分为Sever层和存储引擎层。create table tableName(id int) engine=innodb; 连接器
mysql -h$ip -P$port -u$user -p 连接时间
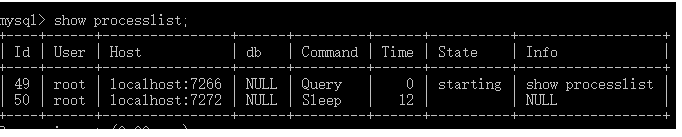
建立连接
1.定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。 2,如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。 查询缓存
mysql> select SQL_CACHE * from T where ID=10; 分析器
优化器
select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
select * from student where sex = '女' and age > 30 select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20; 执行器
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 195
195