知道什么是Selenium Selenium是一个用于Web应用程序测试的工具 此案例为自动打开百度,搜索“前端” 注意:全程自动,无需控制,我们可以用代码操控它来注册,登录,等等。 首先selenium如何抵制反爬:反爬机制只是针对爬虫的,例如:检查请求头、检查IP的请求频率(过高则封杀)等手段,而selenium打开的就是一个自动化的浏览器,和用户正常使用并无差别,所以再厉害的反扒技术,也无法将它干掉。 此案例为爬取拉勾网某地区所有的职位信息(此信息有服务器反爬保护) 注意:在翻页时会碰到,页面元素请求在art-templete模板渲染之前(无法获取元素),导致报错(抛异常)。 解决方案: 总结:利用selenium可以做好多自动化的事情,解放咱的双手 写在最后:爬虫神通广大,用途也非常广泛,主要目的是为了实现自动化程序,解放咱的双手。帮助我们自动获取一些数据,测试软件,甚至自动操作浏览器做很多事情,但使用爬虫时我们需要注意,把它用在得当的地方。同时,在爬取目标网站之前,建议大家浏览该网站的robots.txt文件(url后输入
目标
会使用Selenium
了解反爬机制
会使用Selenium抵制反爬
Selenium反爬案例1. 什么是Selenium
它可以真实的模拟浏览器,为爬虫开辟了良好的环境2. Selenium的基本使用
chrome为例,注意两者版本号最好一致)
将下载的包进行解压,把.exe文件放入项目根目录
官方文档地址:https://www.npmjs.com/package/selenium-webdriver2.1 Selenium的小demo
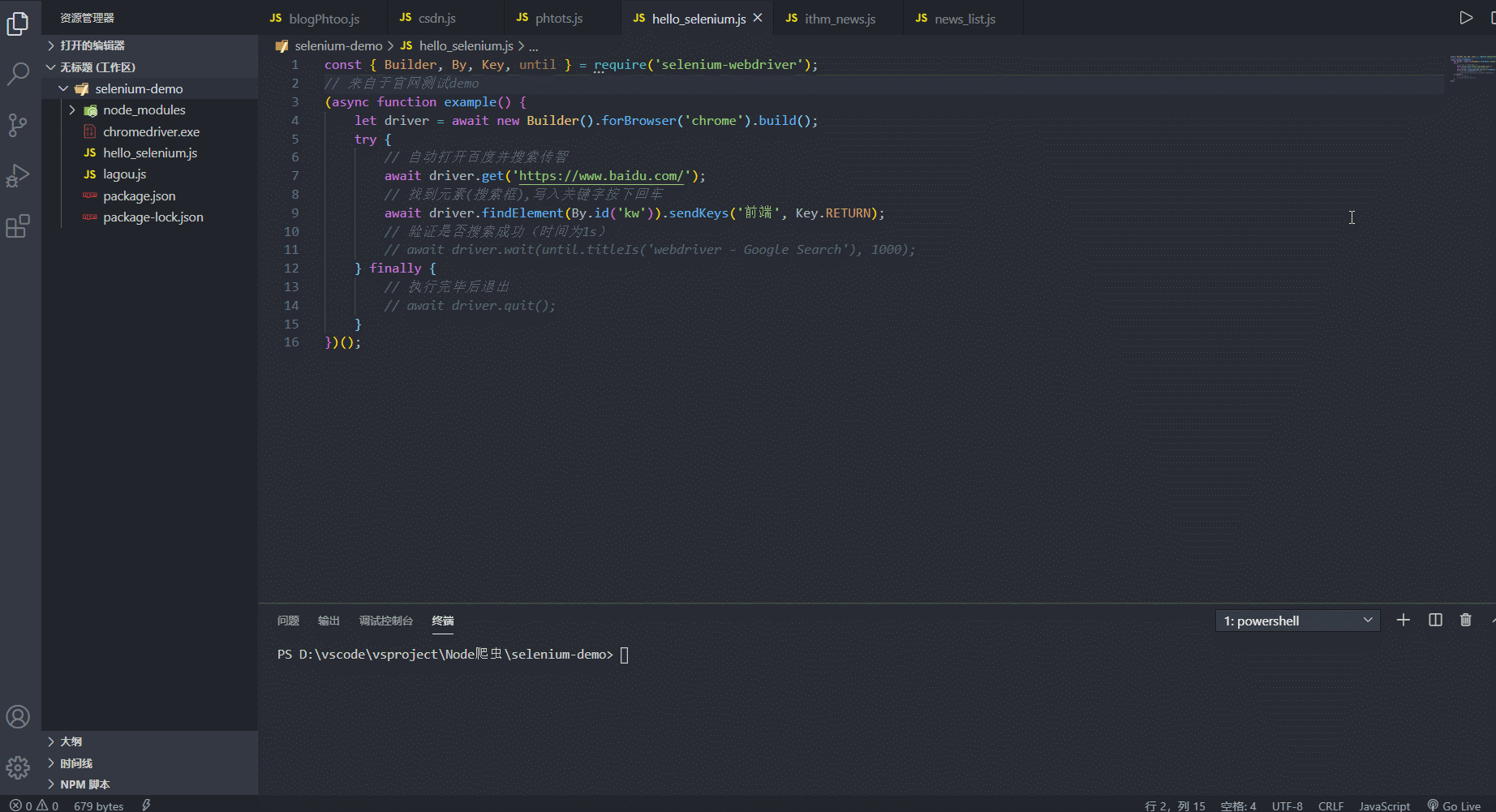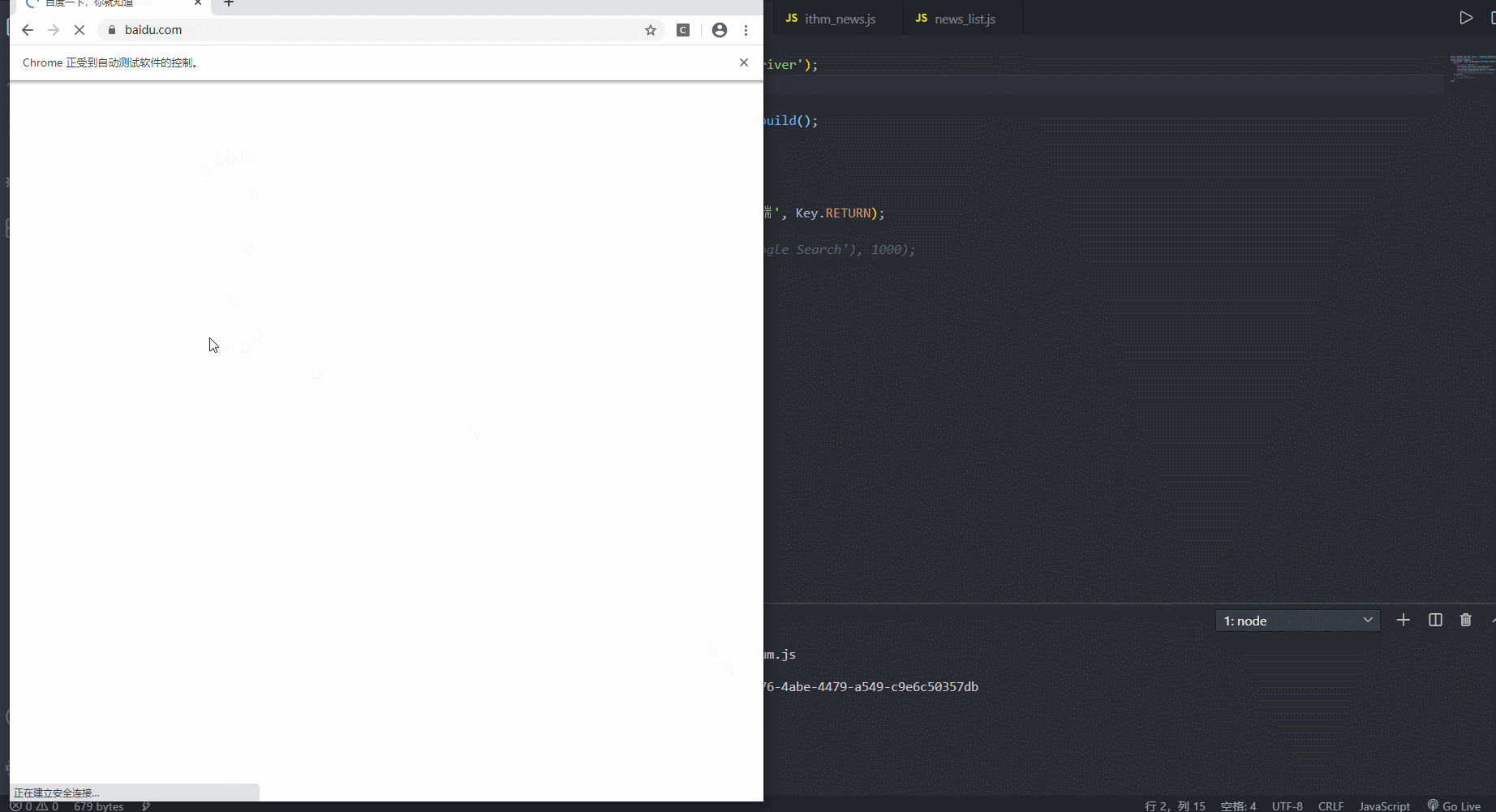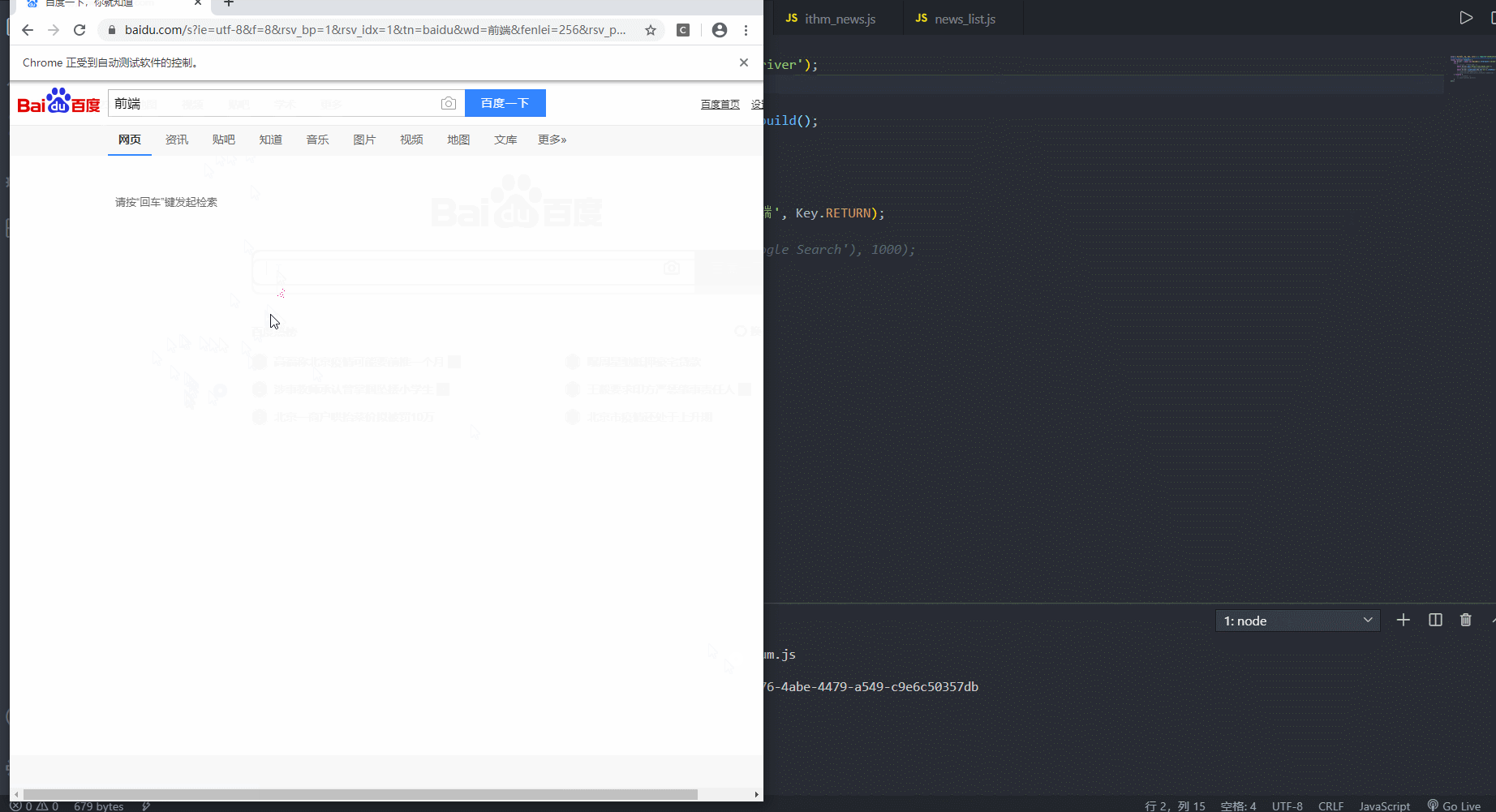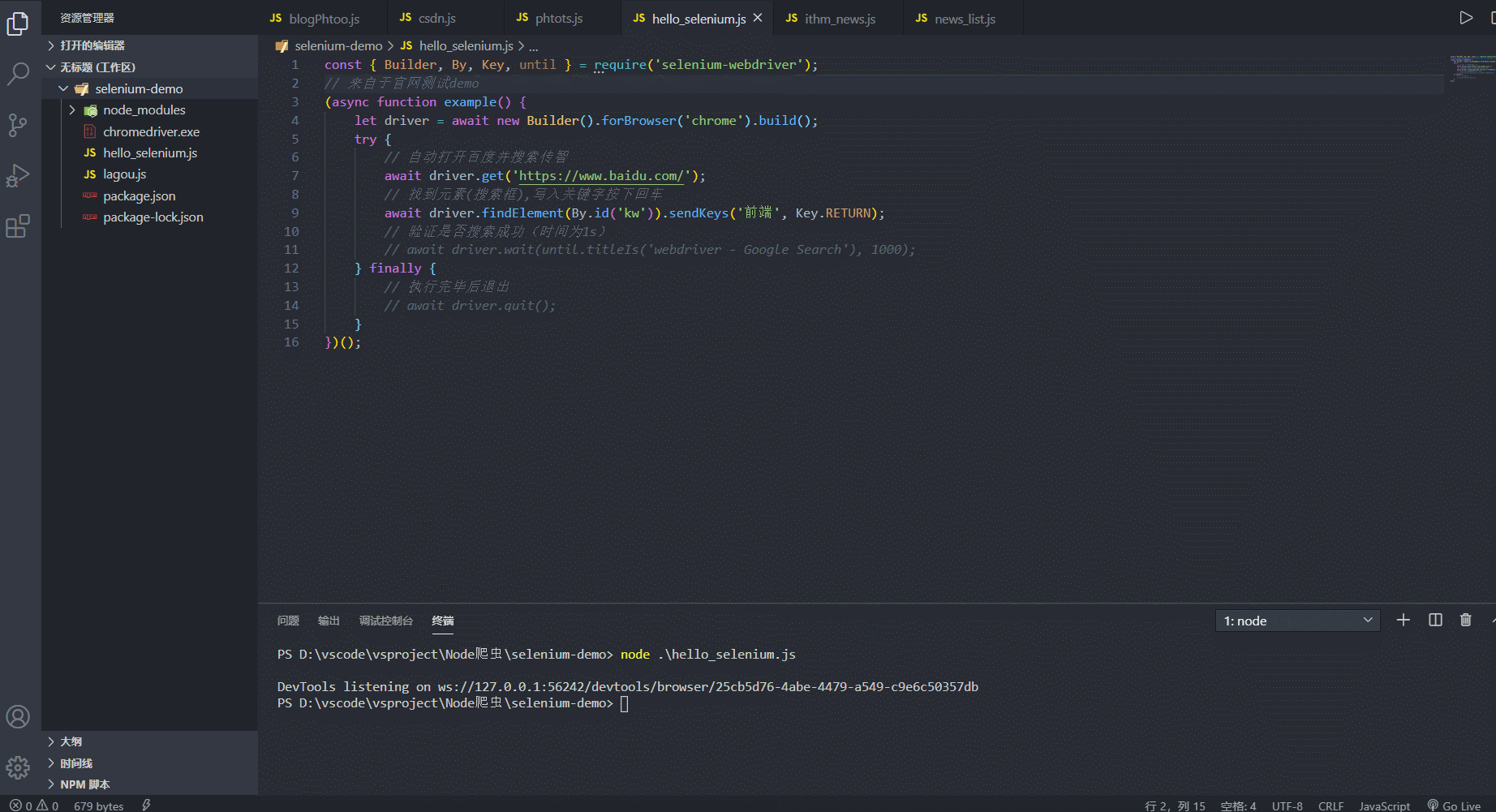
const { Builder, By, Key, until } = require('selenium-webdriver'); // 来自于官网测试demo (async function example() { let driver = await new Builder().forBrowser('chrome').build(); try { // 自动打开百度并搜索传智 await driver.get('https://www.baidu.com/'); // 找到元素(搜索框),写入关键字按下回车 await driver.findElement(By.id('kw')).sendKeys('前端', Key.RETURN); // 验证是否搜索成功(时间为1s) // await driver.wait(until.titleIs('webdriver - Google Search'), 1000); } finally { // 执行完毕后退出 // await driver.quit(); } })(); 3. 反爬
3.1 反爬机制
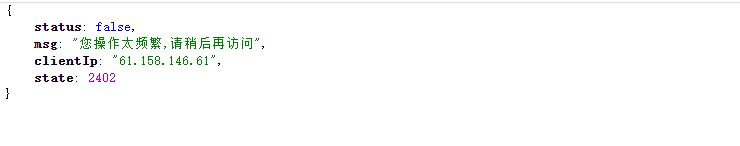
3.2 抵制反爬机制
4. Selenium抵制反爬
4.1 SeleniumAPI的学习
5. Selenium反爬案例
5.1 案例步骤
driver打开拉勾网主页杭州站点击一下dirver.findElement()找到所有条目项,根据需求分析页面元素,获取其文本内容
5.2 效果预览
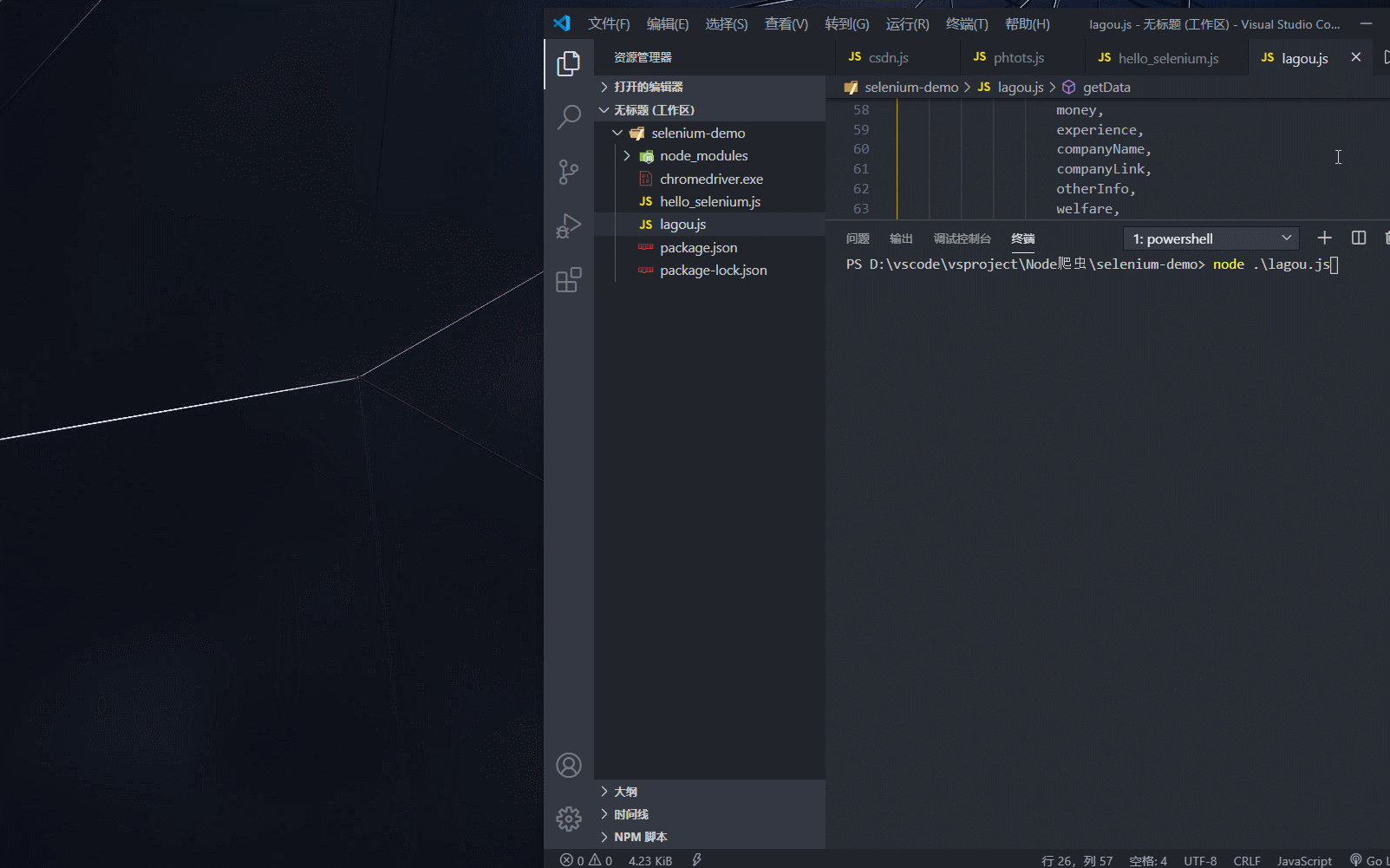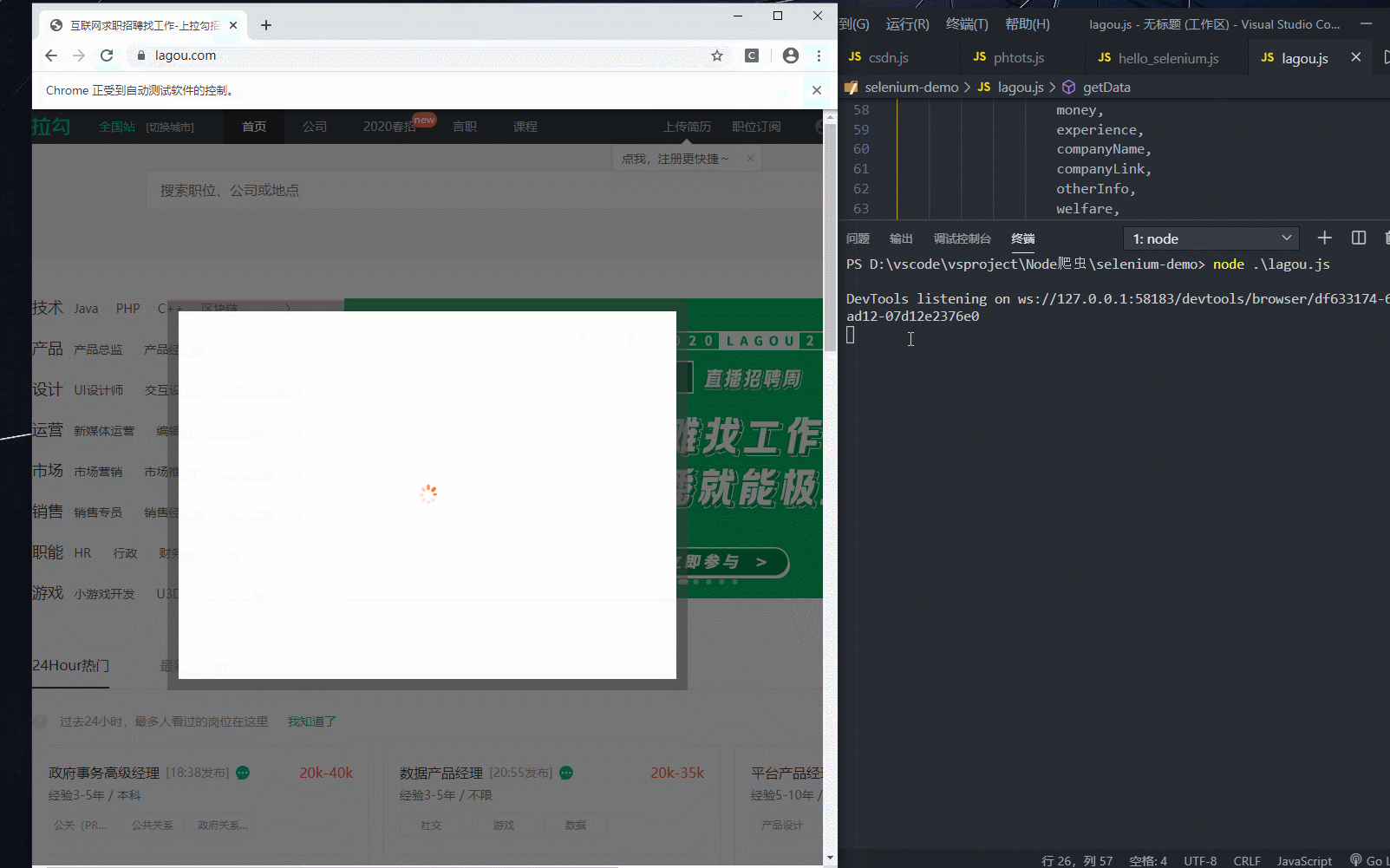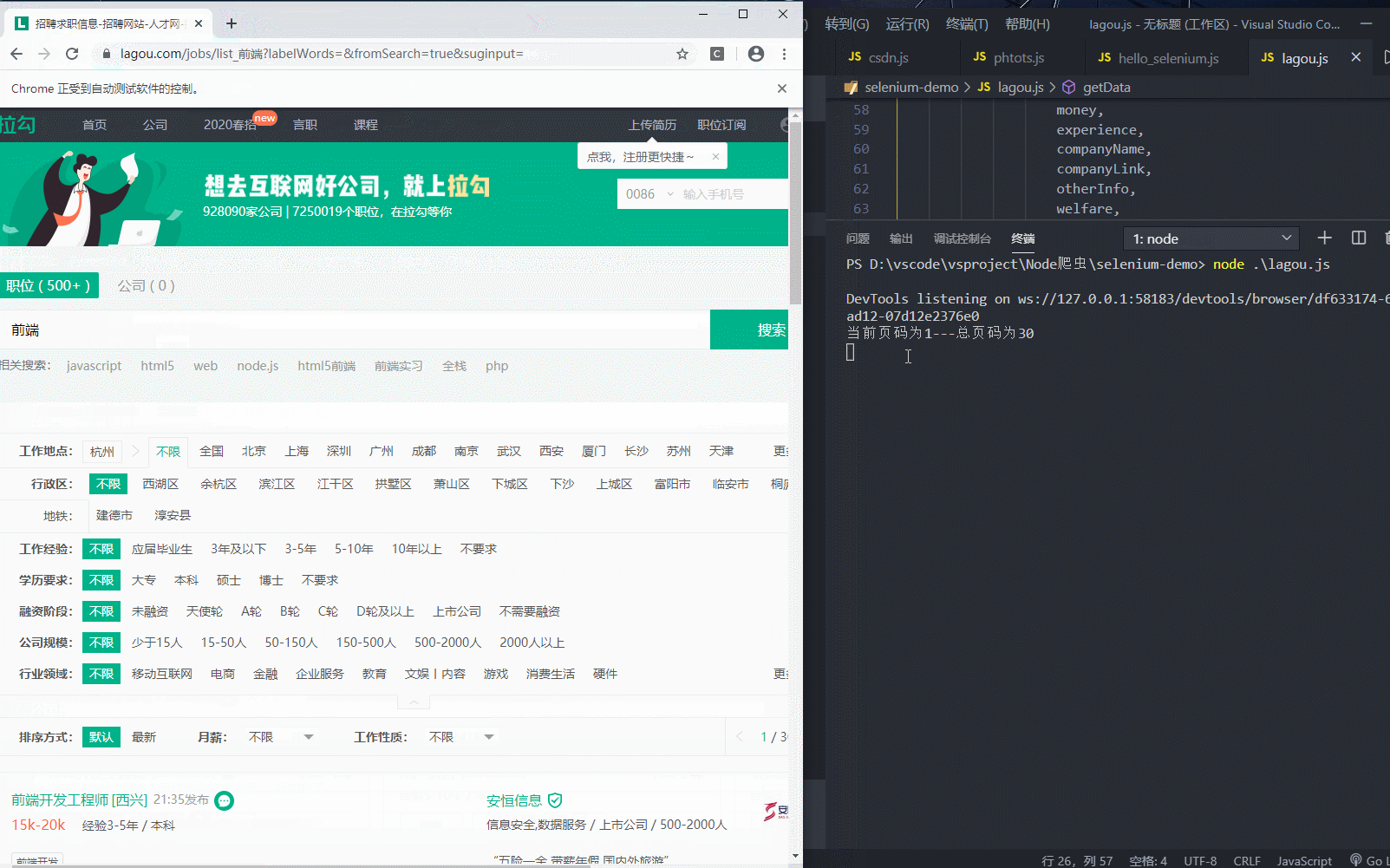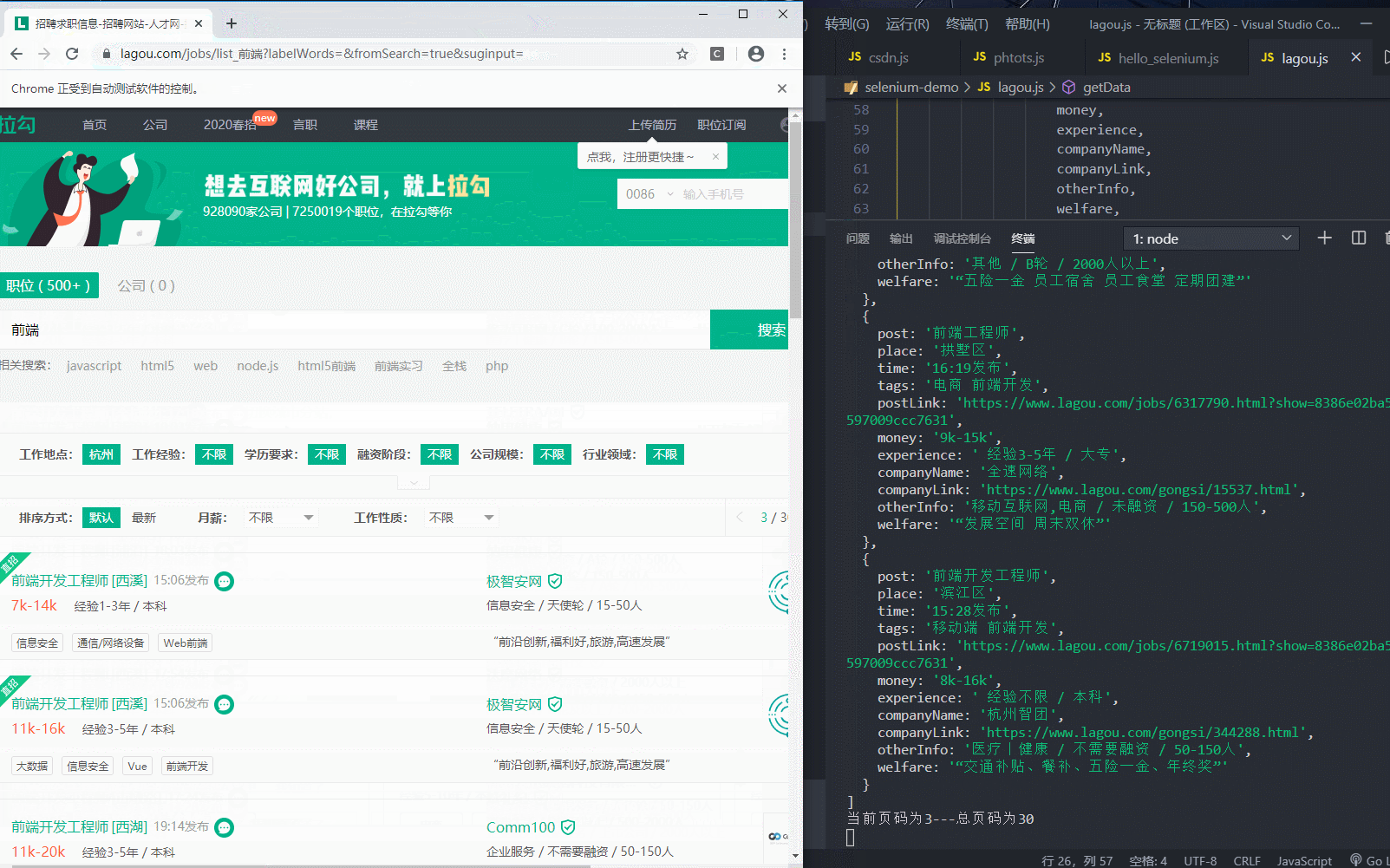
5.3 代码
const { Builder, By, Key, until } = require('selenium-webdriver'); // 定义当前页码 let currentPage = 1; // 定义总页码(后面加分号,避免立即执行函数报错) let maxPage; (async function start() { let driver = await new Builder().forBrowser('chrome').build(); try { // 访问拉勾网 await driver.get('https://www.lagou.com/'); // 点击选择拉勾网弹窗内容(此处选择全国) await driver.findElement(By.css('#changeCityBox>ul.clearfix li:nth-child(3)')).click(); // 在搜索框中输入前端,进行信息展示 await driver.findElement(By.id('search_input')).sendKeys('前端', Key.RETURN); // 在搜索完页面抓取信息总页面 maxPage = await driver.findElement(By.css('.totalNum')).getText() getData(driver) } catch (e) { console.log(e.message) } })(); async function getData(driver) { // 打印当前页 console.log(`当前页码为${currentPage}---总页码为${maxPage}`); // 定义while循环(类死循环) while (true) { let noError = true; try { // 获取岗位信息模块 let items = await driver.findElements(By.css('.item_con_list .con_list_item')); // 通过for循环对信息逐条获取(原生for循环,避免开辟新函数使async冲突) // 定义空数组,接收循环得到的数据 let infors = []; for (let i = 0; i < items.length; i++) { let item = items[i] let post = await item.findElement(By.css('.list_item_top .p_top h3')).getText() let place = await item.findElement(By.css('.list_item_top .p_top .add em')).getText() let time = await item.findElement(By.css('.list_item_top .p_top .format-time')).getText() let tags = await item.findElement(By.css('.list_item_bot .li_b_l')).getText() let postLink = await item.findElement(By.css('.list_item_top .p_top .position_link')).getAttribute('href') let money = await item.findElement(By.css('.list_item_top .p_bot .money')).getText() let experience = await item.findElement(By.css('.list_item_top .p_bot .li_b_l')).getText(); // 把工作经验模块获得的文字中,多余的money信息替换为空 experience = experience.replace(money, '') let companyName = await item.findElement(By.css('.list_item_top .company .company_name')).getText() let companyLink = await item.findElement(By.css('.list_item_top .company .company_name>a')).getAttribute('href') let otherInfo = await item.findElement(By.css('.list_item_top .company .industry')).getText() let welfare = await item.findElement(By.css('.list_item_bot .li_b_r')).getText(); // 把获取的数据追加到数组(此处vscode快捷键(Shift+Alt+左键下移,选中多行),(shift+Ctrl+右箭头,选中所有属性),(粘贴完后,选中多行+end+逗号,ok)) infors.push({ post, place, time, tags, postLink, money, experience, companyName, companyLink, otherInfo, welfare, }) } console.log(infors); if (currentPage < maxPage) { // 页码自加 currentPage++; // 点击下一页 await driver.findElement(By.css('.pager_next')).click(); // 调用自身继续爬取 await getData(driver) } } catch (e) { // 此处抛出异常,让noError为false,继续循环爬取 // 此处异常为页面元素请求在art-templete模板渲染之前(无法获取元素) // console.log(e.message) if (e) noError = false } finally { // 爬到最后一页,无异常抛出,noError为true,跳出循环 if (noError) break } } }
6. 最后
/robots.txt),以确保自己爬取的数据在对方允许的范围之内。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 572
572