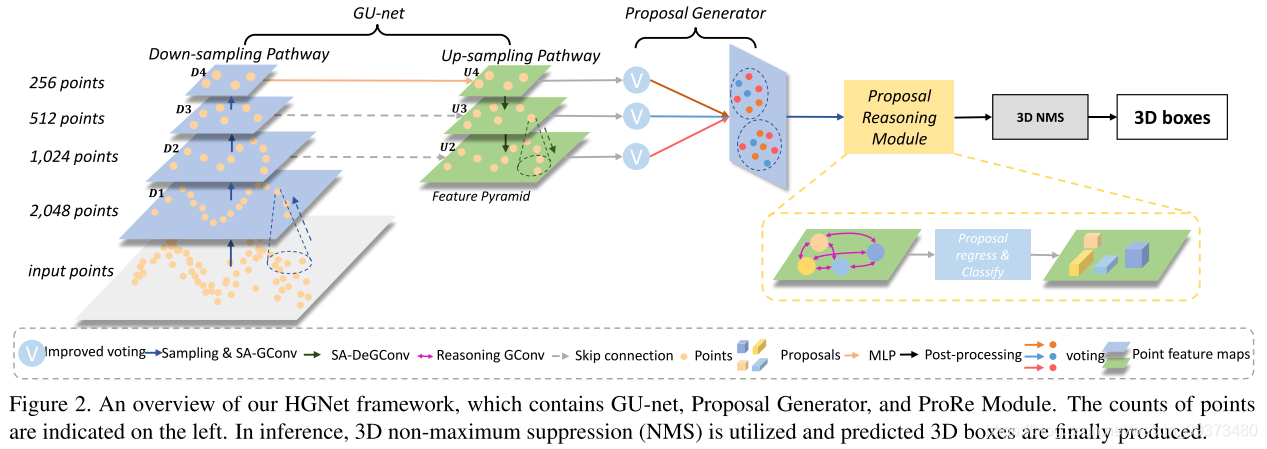
这篇论文主要以VoteNet作为backbone,并在上面提出了一系列改进。由下图可以看出:(1)其将votenet中的PointNet++换成了特征捕捉能力更强的GCN。(2)在up-sample的多层每一层都接上voting模块,整合了多个尺度的特征。(3)在proposal之间也使用GCN来增强特征的学习能力。
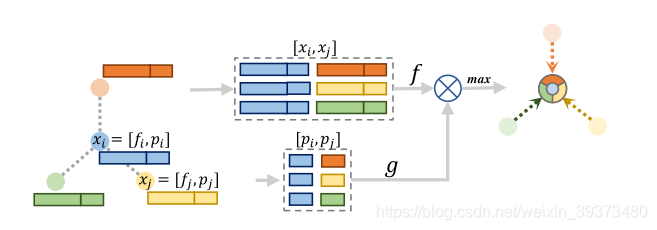
(1)本文提出了一个Shape-attentive Graph Convolutions,并且将这个卷积同时用在了down-sampling pathway和up-sampling pathway中。这实际上与2019CVPR的GACNet和PointConv之类没有本质的区别。其具体的公式如下:
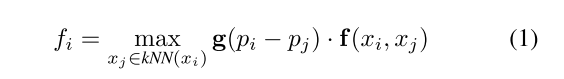
其中g是一个MLP,将3维的相对位置输出成一维的接sigmoid的权重。
, 其中
为相对位置,
为拼接操作。
(2)本文提出了一个Proposal Reasoning Module,在proposal之间学习其特征之间的交互。其具体公式如下:
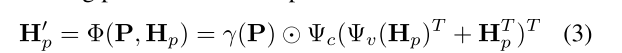
其中
是proposal的特征
,P记录它们之间的坐标相对位置,
和
都是一维卷积,而
是内积操作。其本质是一个注意力机制的模块。
他们不仅使用mAP去衡量,还是用了coefficient of variation for AP (cvAP)去衡量捕捉不同物体的适应能力,具体公式如下:
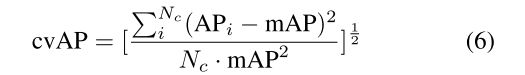
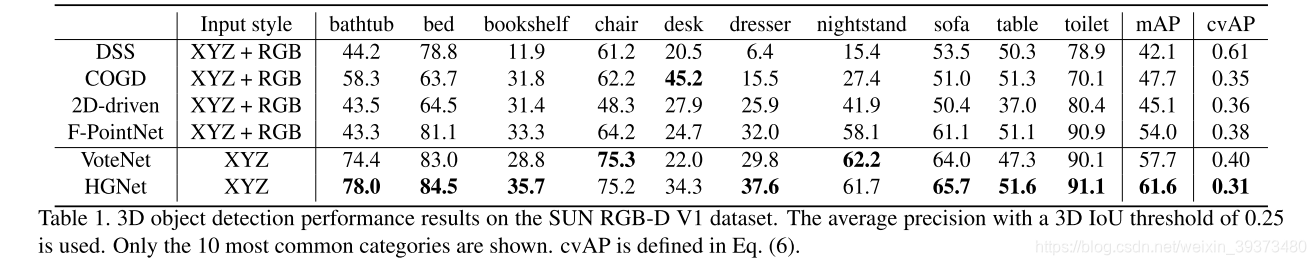
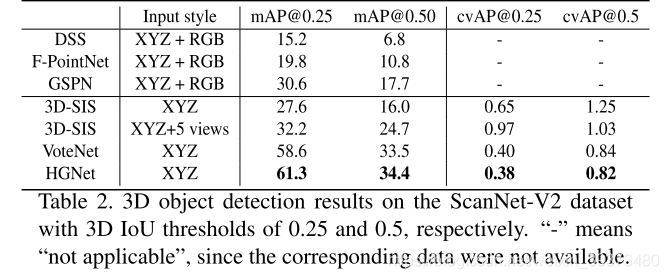
他们的结果在两个数据集上都比VoteNet要更好。
本文先指出之前的3D detection工作的不足,Point-based的方法encode的能力不够,而voxel-based的方法又很难平衡voxel-size(精度)和速度之间的关系。本文提出了一种新的基于点云的三维物体检测的统一网络:混合体素网络(HVNet),通过在点级别上混合尺度体素特征编码器(VFE)得到更好的体素特征编码方法,从而在速度和精度上得到提升。
整个HVNET包括:HVFE特征提取模块;2D卷积模块;以及检测模块,用来输出最后的预测结果。下图中第一行是HVNet的整个结构。
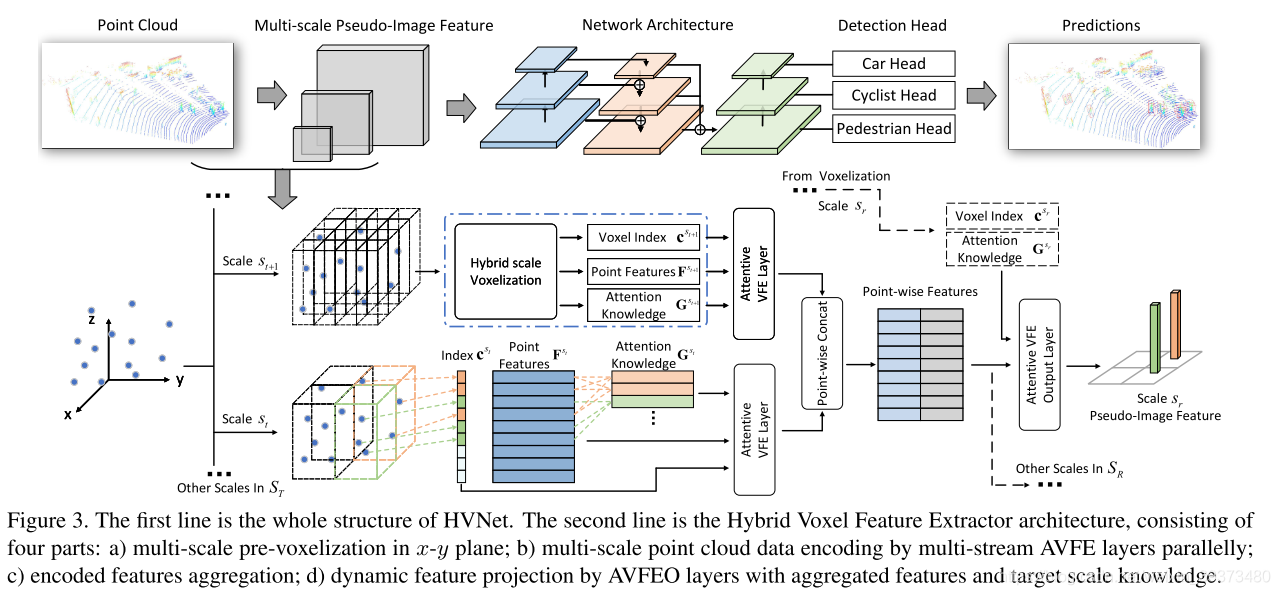
HVFE特征提取模块
第二行是混合体素特征提取器的结构,由四部分组成:
a) x-y平面多尺度预体素化;
b) 并行多流的注意力机制体素特征编码层(AVFE)编码多尺度点云特征;
c) 编码特征聚合;
d) 注意力机制体素特征编码输出层(AVFEO)层结合聚合特征和目标尺度信息进行动态特征投影。
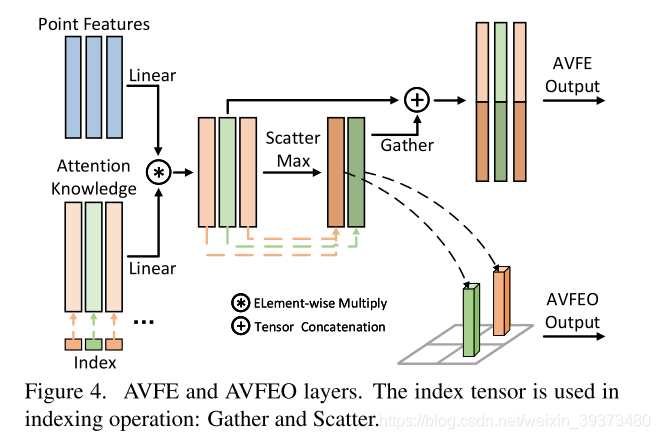
AVFEO层用于将不同尺度的特征通过注意力机制映射到固定的尺度去,如上图所示。不同尺度的feature map最后拼接输入给下一个模块。
2D卷积模块
2D 卷积部分,他们利用HVFE layer提出的多尺度的feature map,在特征图上面也进行多尺度的融合。由于点云的稀疏性和特征图的低分辨率性,他们提出了尺度融合金字塔网络(FFPN)来进行进一步的特征融合。多尺度特征首先在主干网络中浅层融合,然后在提出的FFPN网络中进行深度融合。
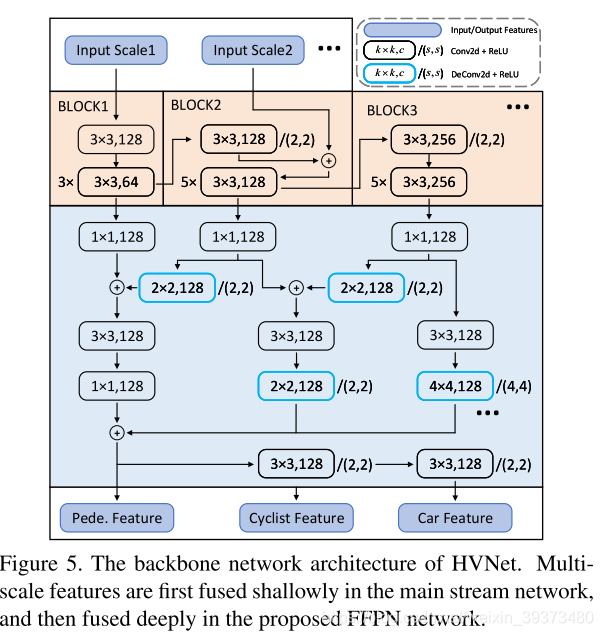
检测模块
利用不同层的feature map感受野不同的特性,对不同的层设计相应的anchor box进行预测。具体来说,对于不同层的feature map,在detection head部分只会对相对应的尺度的类别进行预测,这样的方式可以有效减少类别间的混淆。
这篇论文提出的方法在KITTI上面达到了不错的水平,尤其是小物体(cyclist),比第二名高了2个点,这也部分说明了他们方法的合理性。
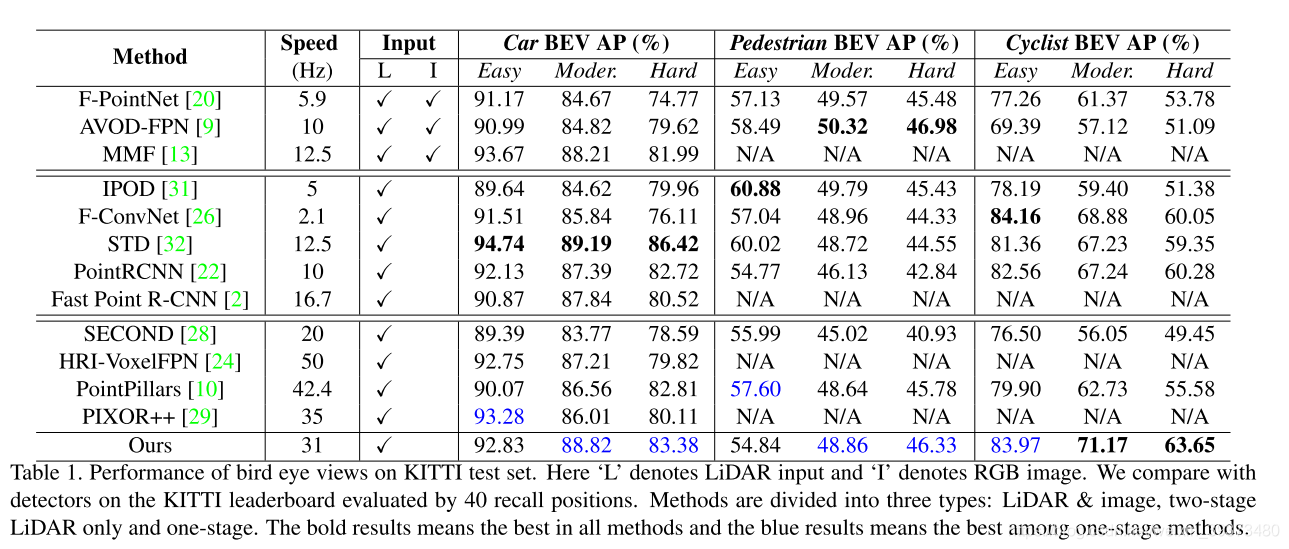
并且作为一个单阶段的模型,其运行速度也很快,如下图所示:

基于点云的3D目标检测具有非常重要的应用价值,尤其是在自动驾驶领域,使用LiDAR传感器获得的3D点云数据刻画了周围环境,3D目标检测能够比单纯使用RBG摄像头提供更多的目标信息(不仅有位置,而且有距离)。
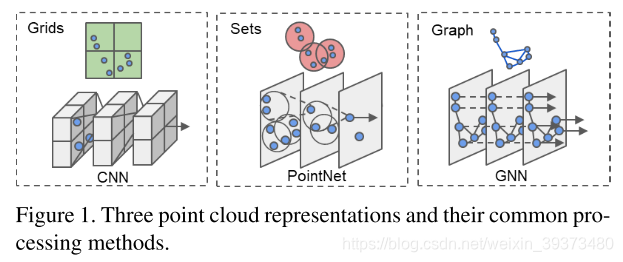
该文作者指出,以往一些使用CNN的方法处理点云数据时往往需要在空间划分Grids,会出现大量的空白矩阵元素,并不适合非密集数据的点云。而近来出现的类似PointNet的方法对点云数据进行分组和采样,取得了不错的结果,但计算代价太大。如下图:
Point-GNN方法主要分三个阶段:
(1)图构建
(2)GNN目标检测
(3)bounding box合并与打分
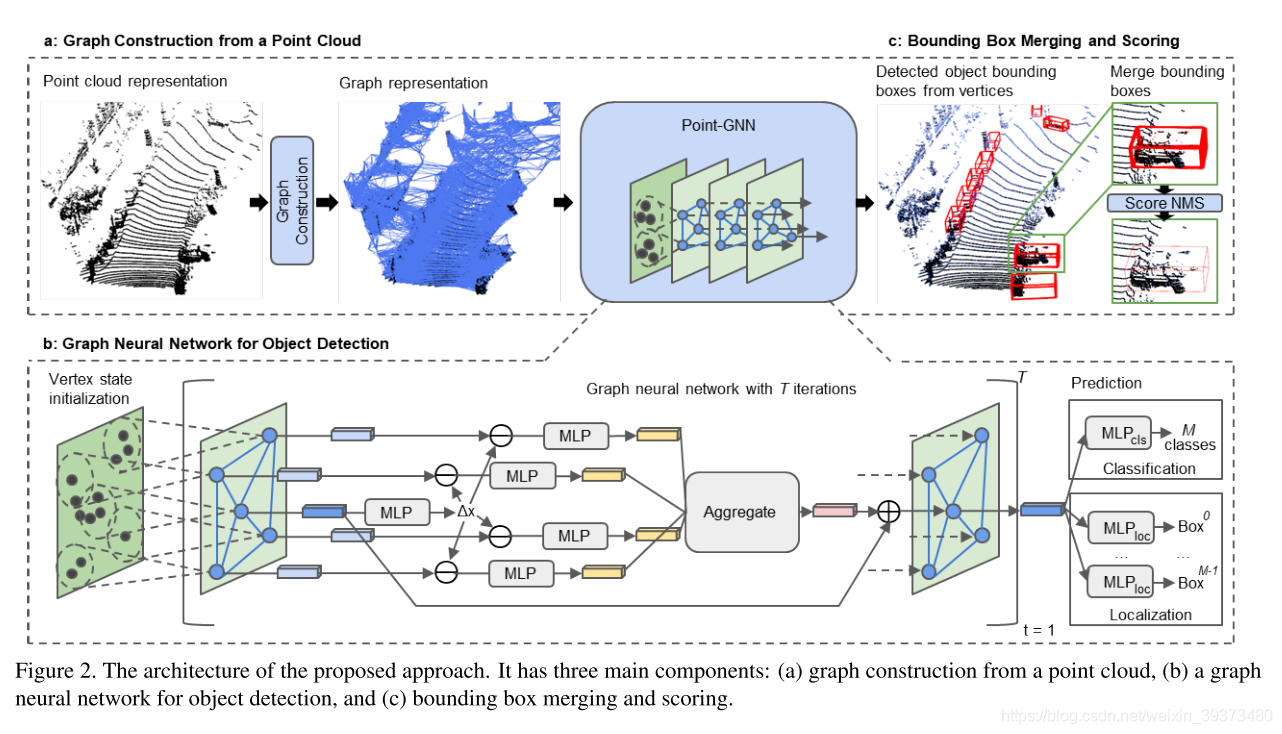
图构建阶段,根据点云中某一点和以其为中心固定半径距离的近邻构建图,图中每个顶点特征不仅包括其3D位置信息也包括一个固定长度状态值向量(反应其近邻关系)。因为点云中含有大量的点,作者并不是对每一个点都构建进图,而是事先进行了体素下采样,降低了数据处理的规模。
GNN目标检测阶段,对构建的图,使用多层感知机(MLP)进行特征提取和聚合,这个过程重复T次,最后对每个顶点使用MLP进行目标类别的分类和位置的回归。
Bounding box合并与打分,对上一步得到的众多的目标bounding box进行合并(同一个目标可能在多个顶点被检测出来),因为上一步的分类分数不能代表bounding box定位精度,使用重叠bounding box的聚类来改进。算法如下:具体来说,就是通过NMS并不是筛选bbox,而是通过他们的IoU和overlap占体素的占比
去加权融合。

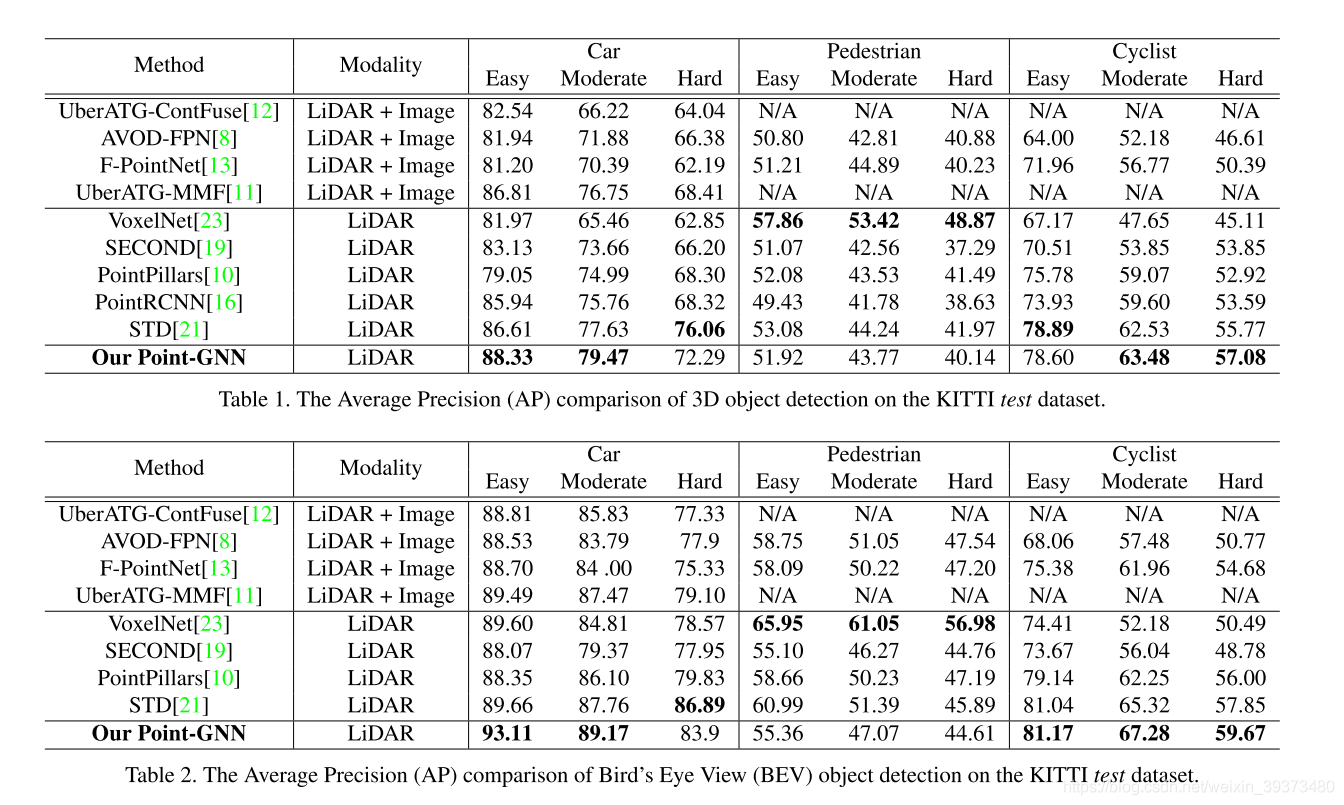
1)使⽤Lidar等传感器进⾏信息采集时,总是不可避免地遇到遮挡问题。⽽障碍物之 后的信息是不可⻅的(可能是free space,也可能被物体占据)。
2)和从Mesh上采集到的点云不同,Lidar数据实际上是2.5D的(因为有遮挡)。如果单纯把Lidar采集到的深度信息单纯地看作⼀个全3D的点云,那么⼈们就⽆法从中区分某个空⽩区域到底能否被sensor探测到(即visibility)。如下图。

3) 当前的detection⽅法都没有考虑到Lidar数据中的visibility,都将它看作纯3D的点 云。从⽽丢掉了数据中的visibility信息。
根据Lidar数据的采集原理(Ray casting):传感器朝着某个⽅向发出激光,激光碰到遮挡物后返回。根据TOF和激光⽅向便可以算出障碍点的xyz坐标。基于这个原理,在激光 出发到碰到障碍物之前的路程上,都是能确定为free space。 因此,作者提出现将空间离散化为voxel grid,然后从sensor的坐标出发,对点云中的每⼀个点进⾏ray casting,并对ray casting路径上的每⼀个voxel进⾏标注(free、occupied、unknow)。
标注完成的voxel grid就是⼀个visibility volume,反映了Lidar数据的可⻅信息,它可以和相应的原始点云结 合,作为⽹络的输⼊参与到⽹络的训练中。特别地,visibility volume可以⼗分容易 地被整合到现有的detection⽹络中。作者⽂章中选择了pointpillar作为backbone。 并提出early fusion和late fusion两种整合⽅式,实验表明,额外加⼊visibility volume可以⼤幅度提⾼现有detection⽹络的性能。

这篇文章探索了如何使用image信息辅助基于voting的3D检测框架。之前的VoteNet依靠voting机制有效增强了点云中的几何信息。这篇文章展示了ImVoteNet如何使用额外的图像,提供geometric,semantic和texture信息于3D voting的过程,详细介绍了如何将2D的geometric信息提升到3D。通过使用基于梯度混合的多模态的训练方法,ImVoteNet极大提升了处理稀疏或不友好分布点云的3D检测性能。
网上写的已经够多了,例子。
利用votenet去改进单目标tracking的效果,比之前的单目标3D工作高了20个点左右,并能保持40FPS。
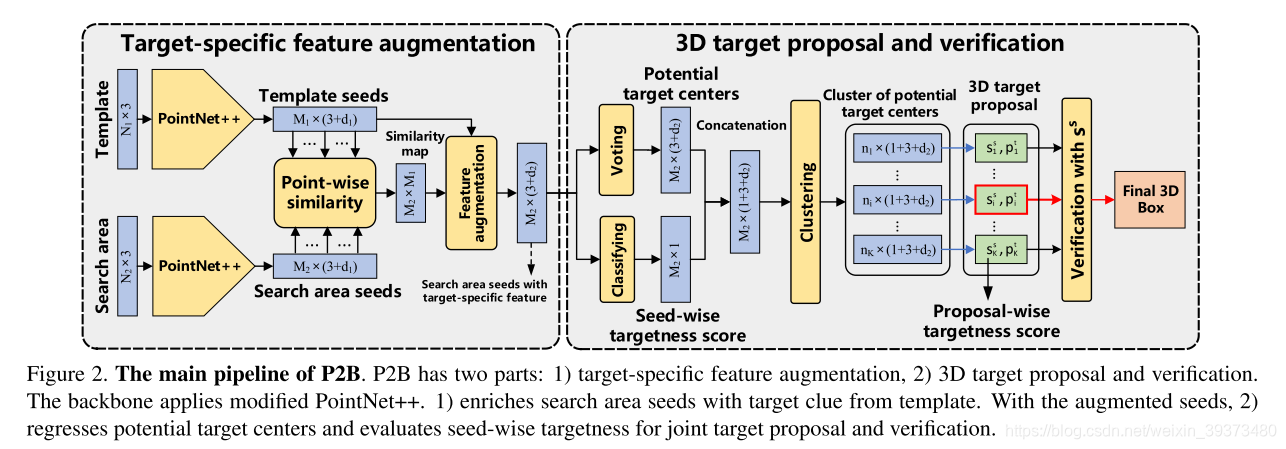
Pipeline
先通过两个共享权重的PointNet++去获得template seeds和search area seeds,然后计算Point-wise similarity如下:
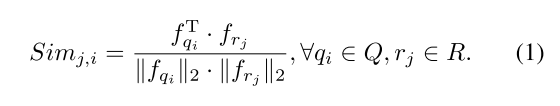
然后这个similarity再贴到复制后的template seed之后,利用一个PointNet去聚合特征,就得到了search area seeds with target-specific features。
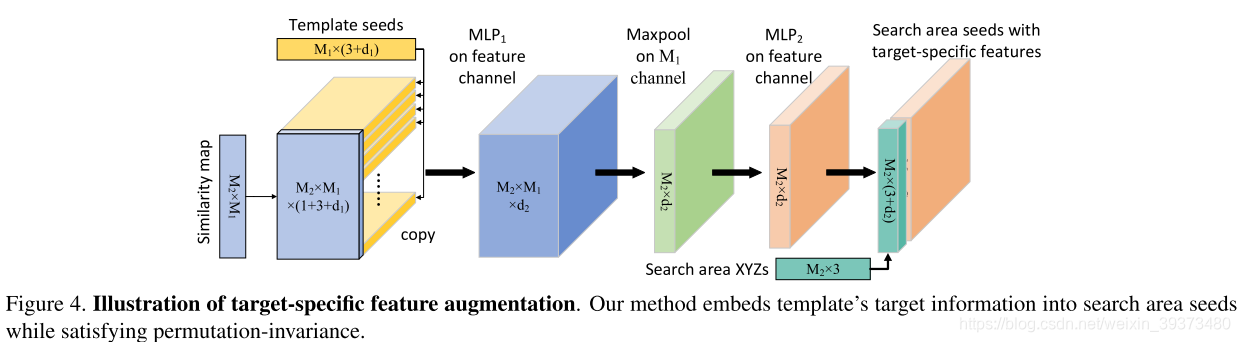
后半部分就是一个votenet的改进版,在进行voting的同时预测每一个vote的seed是前景的概率(即图上的classifying)。最后输出相应最大的bonding box。
在KITTI上达到了不错的结果。在实现时,每一次的search area为上一帧template的附近2m范围。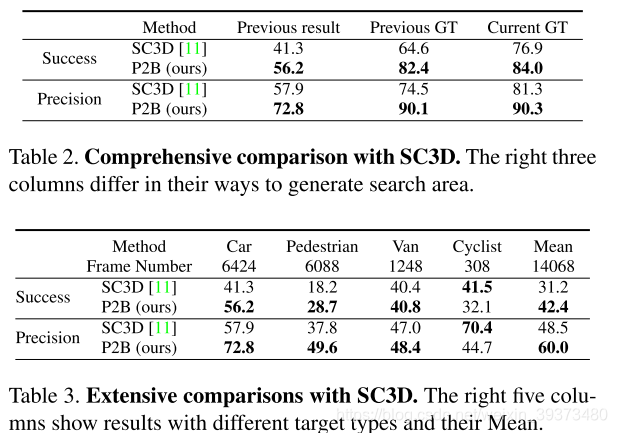
目前的3D目标检测方法通常只能适用于单个domain场景,即使有一些能迁移到其它场景的方法,也需要调整大量的超参和设置。为了解决这一问题,作者提出了一个能同时应用于室内和室外场景的通用网络——DOPS,该网络不仅能检测出目标的3D bounding boxes,还能预测出目标的shapes,然而并非所有的数据集都会有3D shapes的ground truth,故在3D shapes的预测部分作者用了弱监督的方式将CAD数据集上的shape model迁移学习到了target数据集上,以实现shape的预测。
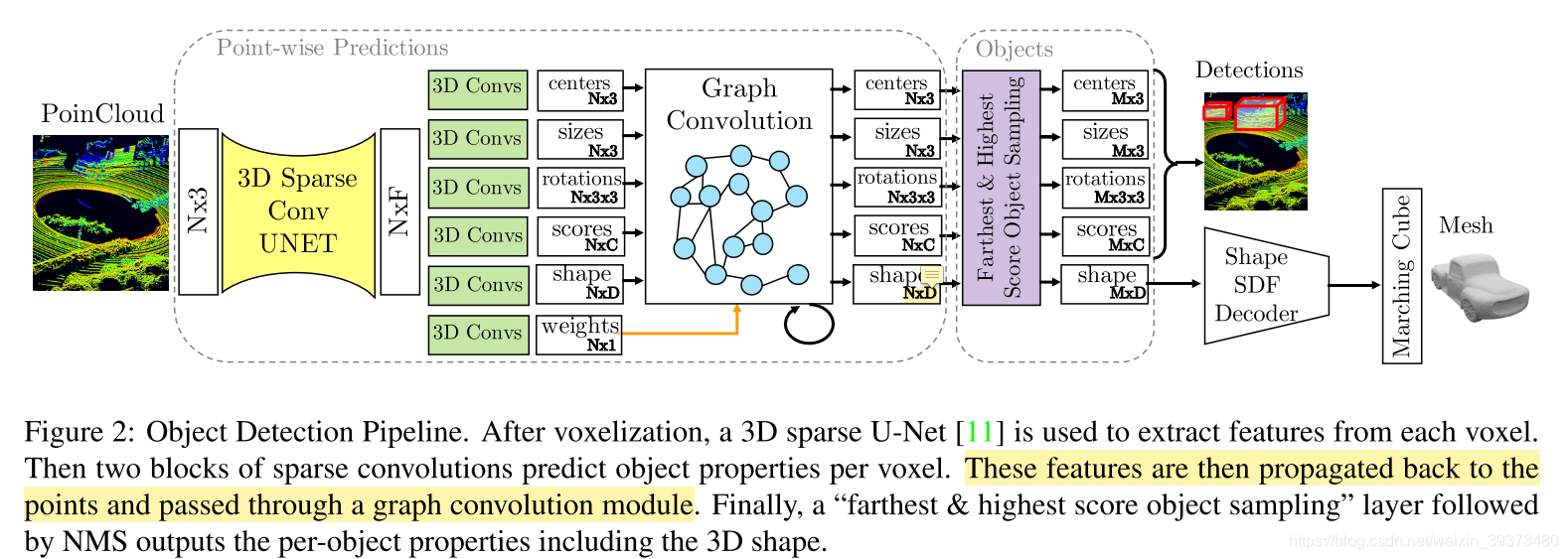
Pipeline
DOPS的网络框架如图所示,由四个部分组成:首先输入点云通过稀疏卷积的3D U-Net提取特征并预测每个点的目标属性和shape嵌入;然后将每个点的预测通过一个图卷积网络得到进一步的预测;再迭代地最远点采样最高分数boxes得到最终的3D bounding boxes,同时每个点的shape嵌入经过SDF decoder后用Marching Cubes algorithm输出shape的mesh结构。
Per Point 3D Object Prediction
输入点云通过稀疏卷积的3D-UNet提取到特征后再通过两层的稀疏卷积预测得到每个点的3D目标属性:center、size、rotation matrix、semantic logits以及shape embedding。其中rotation matrix为一个3*3的矩阵,由预测的(cosx, sinx, cosy, siny, cosz, sinz)6个参数和公式R = Rx * Ry * Rz计算得到。
Box Prediction Loss
作者将box的预测损失设置为8个顶点的Huber loss,而非通常的中心点、尺寸以及朝向的多loss组合,很好地避免了多loss调超参的问题,增强了网络的通用性。同时作者将那些预测的box和GT box的IOU大于0.7的点设为positive点,其余的点设为negative点,并用softmax loss来优化该分类过程(GT boxes内的点label为正,GT boxes外的点label为负)。
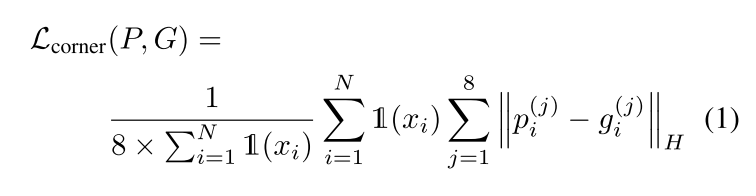
Proposing Boxes
为了得到少数精确的boxes,作者用了迭代地最远点采样最高分数box的方法而非NMS,该方法简单描述如下:
假设迭代选择到第t步时,前t-1步选择的boxes集为
,那么第t个box按下式选择: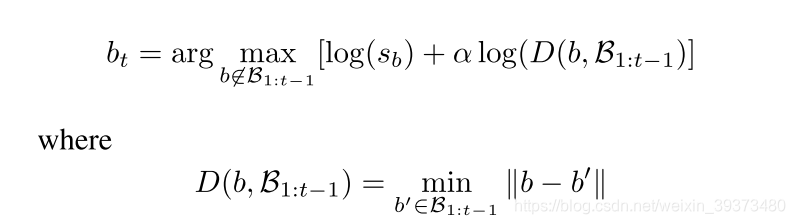
其中
是box b的语义分数。作者认为,该方法和NMS相比能达到目标的高置信度和空间多样性的平衡。
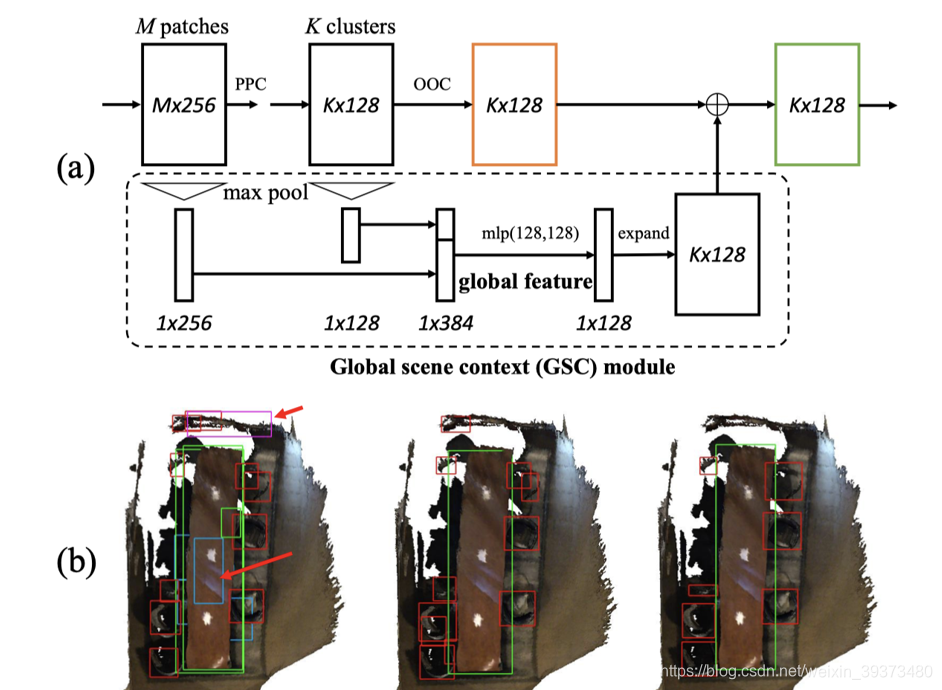
这篇论文主要是在Votenet上面增加了三个模块,用来提升performance。这三个模块分别是Patch-patch context (PPC) module,Object-object context (OOC) module 和Global-scene context (GSC) module。作者认为这样的设计,就讲patch,object和scene的信息都进行了交互,达到了Multi-Level Context的效果。
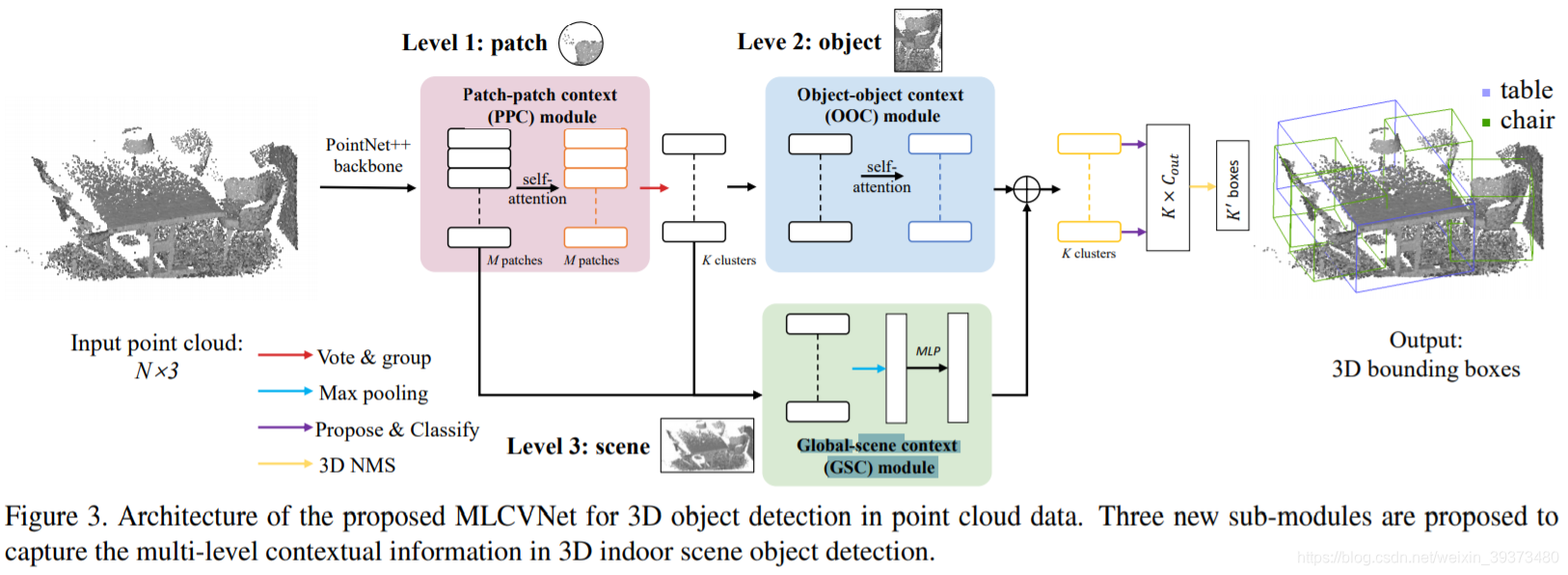
PPC Module
就是在M个patch之间加了一个self-attention,作者认为这样可以增加voting到物体中心的效果。
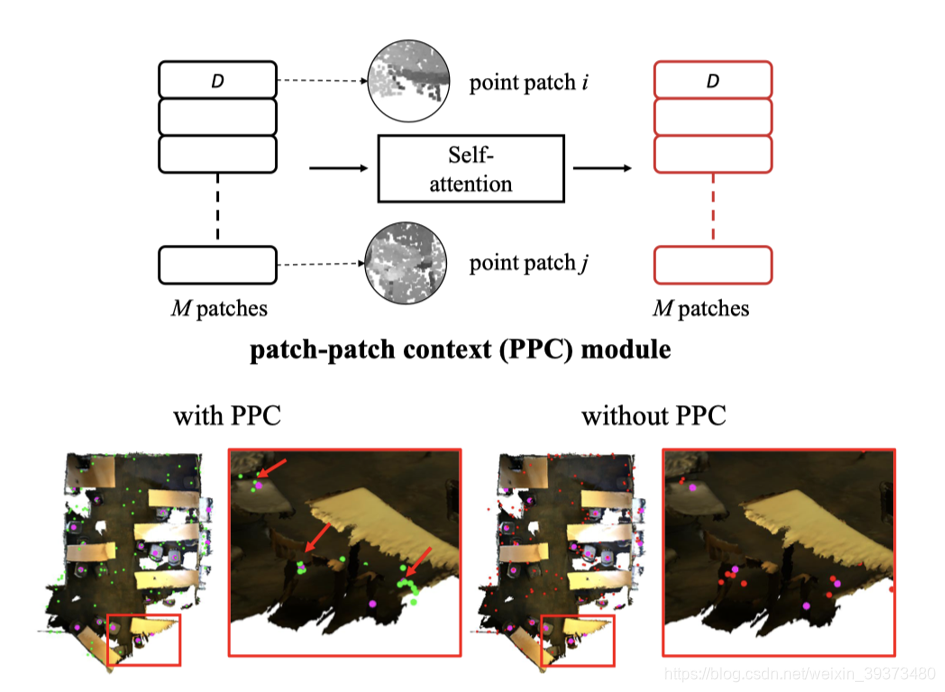
OOC Module
本质上就是K个clusters之间的self-attention,其可以让proposal生成过程中的overlap减少。
GSC Module
它将前面patch级别和cluster级别的特征变成全局特征,然后拼接到输出之前的特征上,相当于引入了全局信息。实验发现这样的设计可以让输出更可靠。
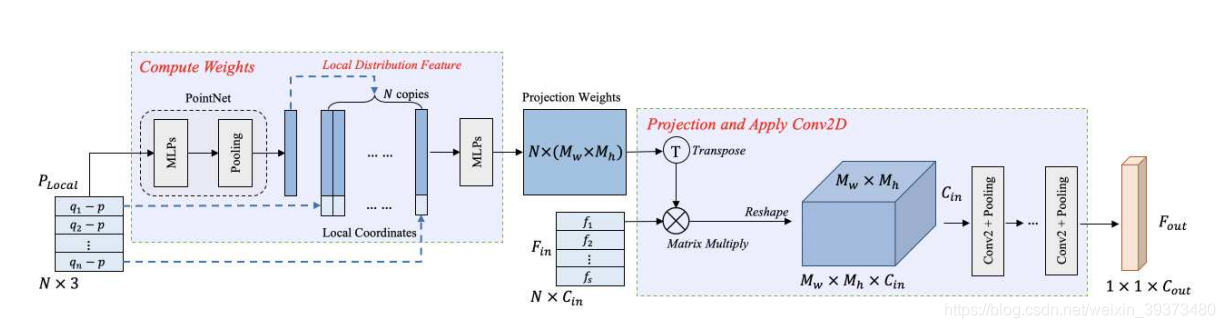
利用类似注意力机制的映射,将每个采样点的邻居结点映射到2D平面上再使用2DCNN去进行局部特征聚合。
局部使用PointNet去得到一个局部的全局特征,然后拼接到每个点的坐标上,通过学习一个映射矩阵,映射到2D的网格中,再使用2D CNN去得到一个编码的特征。
其在ScanNet和S3DIS上都达到了不错的效果,其还可以加到SOTA的模型上,进一步提升其效果。
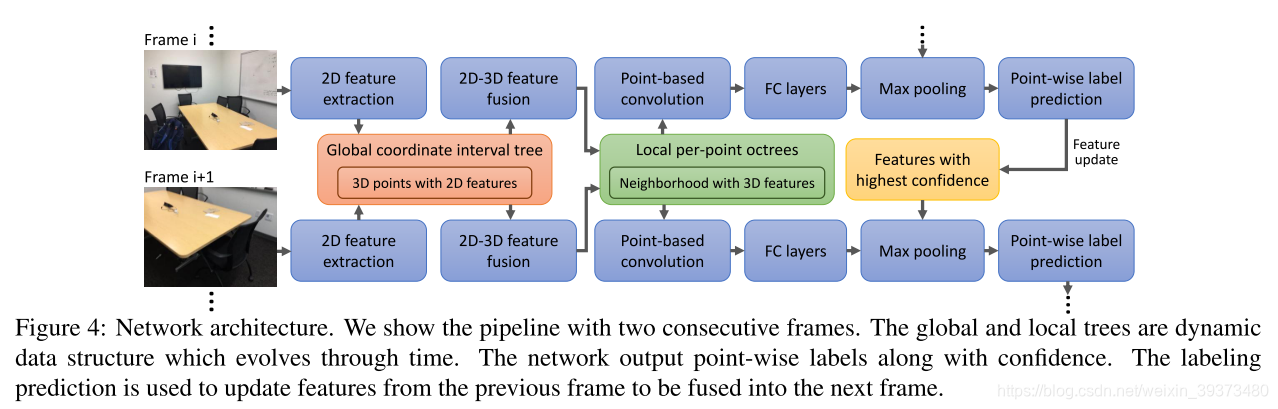
用LIDAR数据的前后帧关系去做语义分割。
论文的Pipeline比较简单,就是通过两帧的数据作为输入,中间使用sparseconv进行网络搭建。两个核心模块是Cross-frame Global Attention (CGA) modules和Cross-frame Local Interpolation (CLI) module。前者就是一个attention机制,后者就是在差值的时候用前一帧的特征去3-NN插值。

在SemanticKITTI上结果一般,仅能达到43.1。
与上一篇工作一样用到多帧之间的关系,不过是做室内场景的。通过RGB-D为输入,通过Global-local tree去构建graph,然后通过Point convolution去聚合特征。
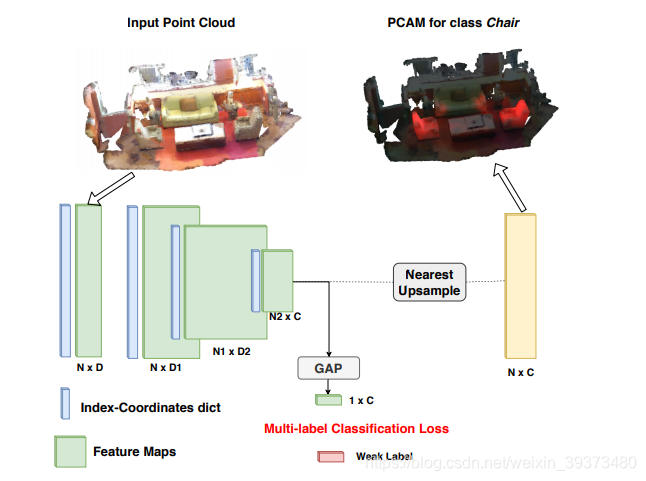
随着3D传感器的发展,大规模3D数据的获取已经不是什么难事了,相比之下对所获取的3D数据进行point-level的语义标注则要困难许多,比如ScanNet数据集,只需要20个人就能采集到1513个3D scans,但是却需要500多个人来完成point-level的标注工作,为了保证标注的准确性,每个scan还需要2-3个人进行重复确认,标注一个scan要花费16-22分钟,这样下来,建立一个大规模的3D数据集无疑要消耗大量的时间和人力成本,很不经济。故作者提出了一种弱监督的3D语义分割的算法,只需要cloud-level的类别标注就可以达到某些全监督算法的性能,而cloud-level每个scan的平均标注时间只要15秒到3分钟,效率是全监督point-level标注的6-70倍左右。
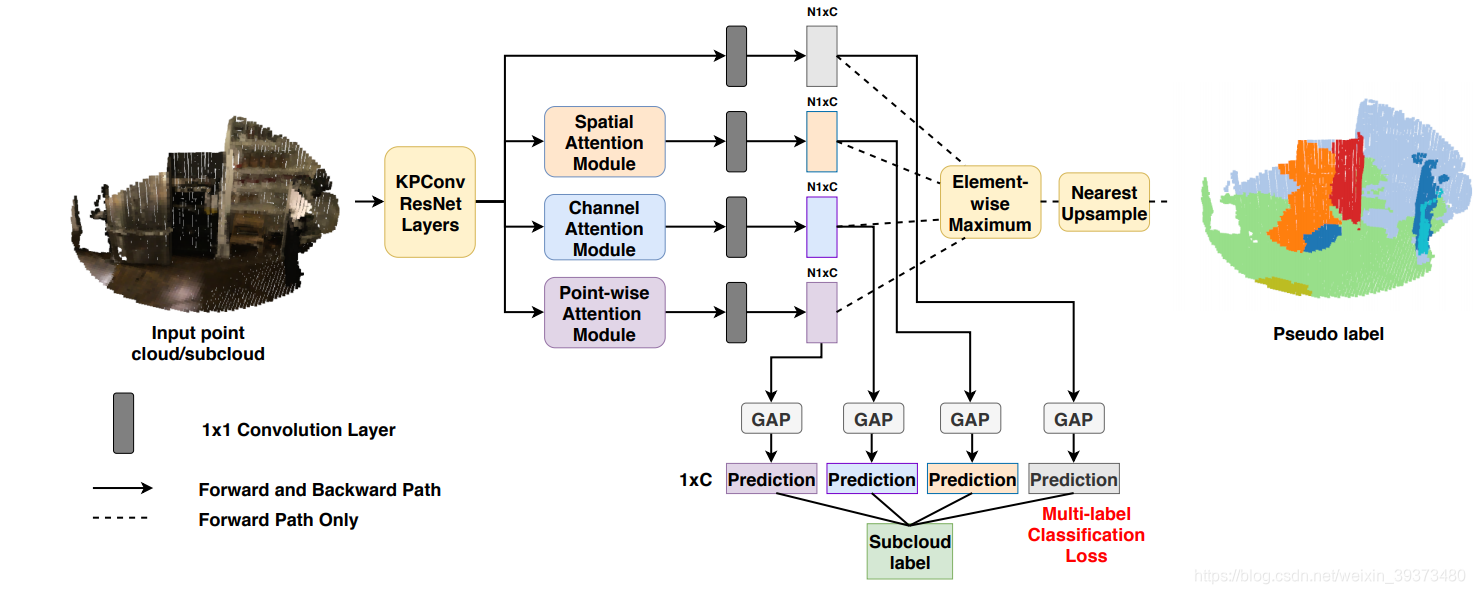
这篇论文的核心贡献主要在于提出了一个structuring的方式来代替传统PointNet++一代最远点采样+KNN的速度问题。至于GCN的部分,其实与之前的工作大同小异。
论文的核心贡献在于这张图,它可以one-shot找好采样点和每个采样点的邻居点,不需要再像传统的方法一样进行FPS+KNN(Ball-query)。其核心思想是先使用网格化将所有点都放到网格中,然后对于每个网格中只保留固定个数的点,然后采样和找邻居都只对这些网格的剩余点进行处理。
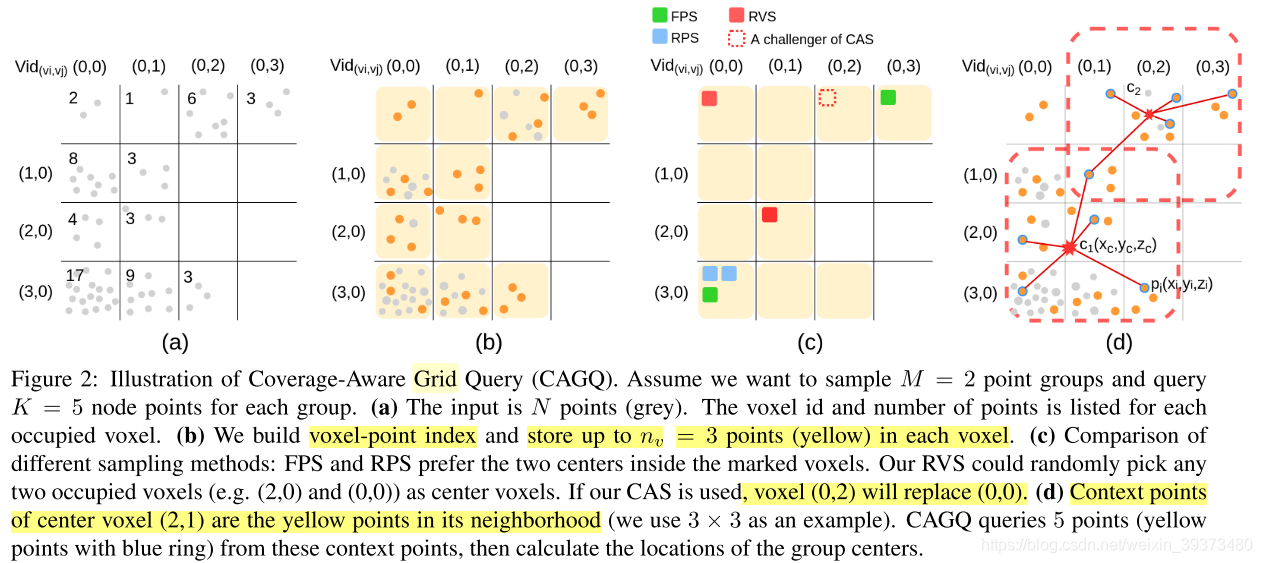
文章中提出了两种采样方法:
(1)Random Voxel Sampling (RVS),即随机选择网格,即使这样采样,也会比直接在点云上随机采样更加均匀。
(2)Coverage-Aware Sampling (CAS),即先随机采样,然后通过迭代,每次选出一个挑战的体素,去对比所有的已选体素,看替换了以后覆盖率会不会变高。
文章同时也提出了两种找邻居的方法:
(1) Cube Query:类似pointnet++的ball query但是覆盖率更高
(2) K-Nearest Neighbors
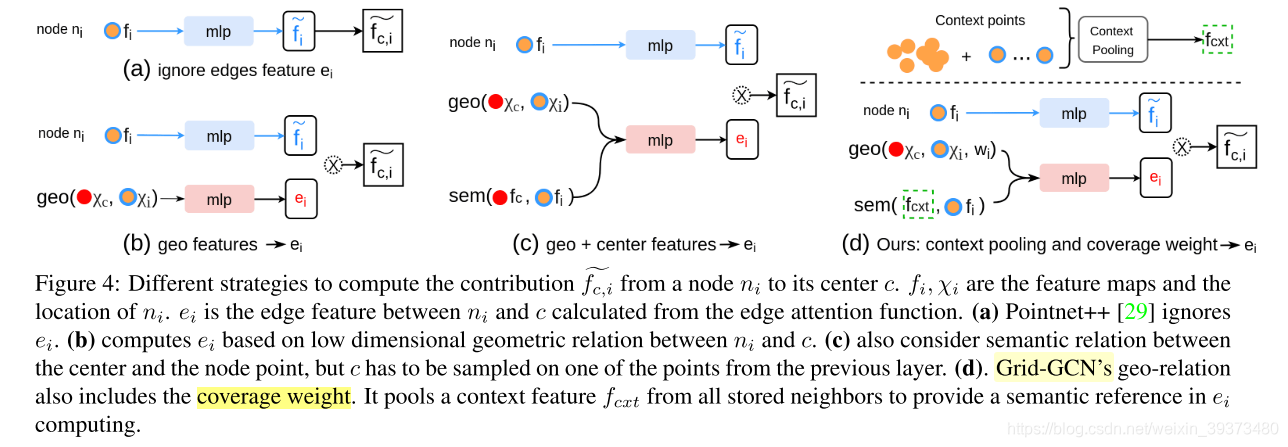
至于GCN部分,其实没有本质的改进,就是在计算边的权重的时候多考虑了一个覆盖率和一个每个体素剩下来的点pool后的特征。
速度确实很快,提出来的新方法在采样点和邻居对于整体点云的覆盖率也更高,但是在数据集上的表现一般。
利用随机采样去代替最远点采样,使得网络可以使用特别大的点云进行训练学习,而且速度比较快。
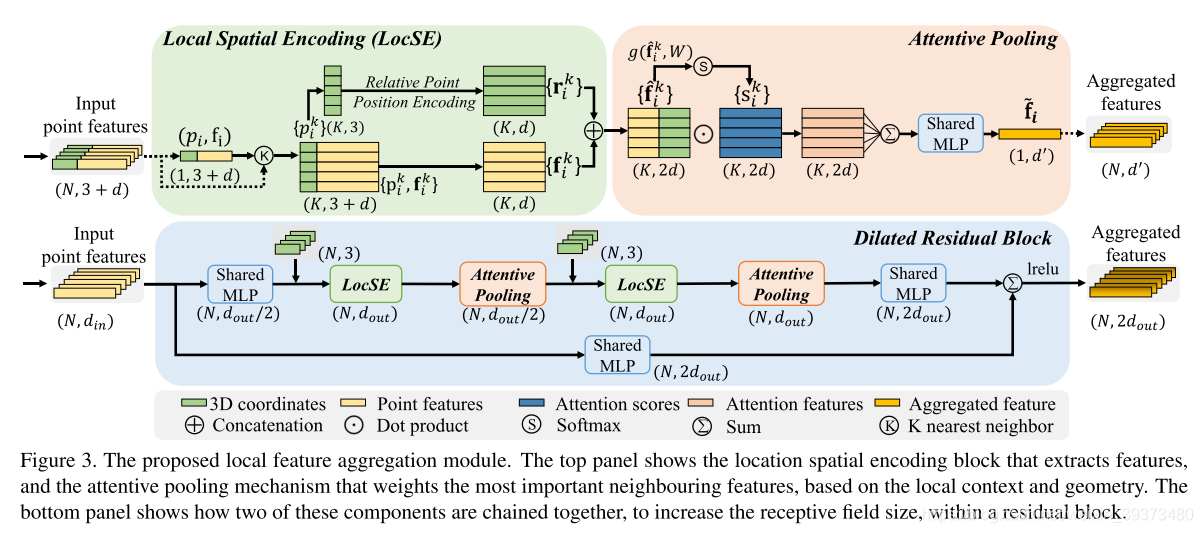
整个Pipeline是比较简单的,LocSE模块比较像2019CVPR的RS-CNN,后面的Attentive Pooling就是一个利用attention去加权特征的方式。值得注意的是在每一层里面LocSE和Attentive Pooling都使用了两次,作者称这样的结构为膨胀结构。也正是因为这样,才能在随机采样的点上达到这么好的encoding能力。
这篇论文提出了一个可学习的数据增强方式,可以显著增加以前一些方法的效果(仅限分类)。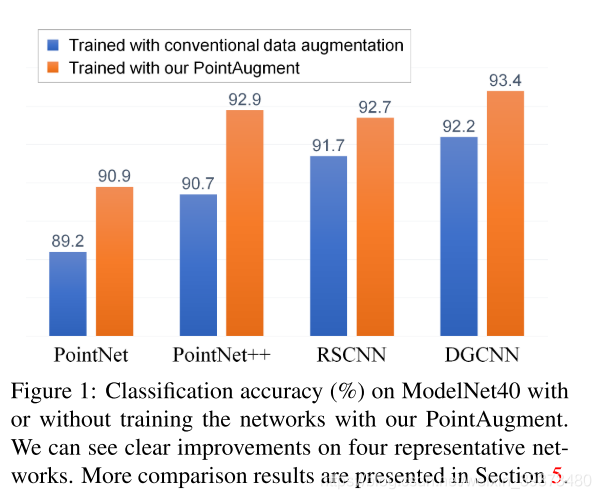
Pipeline
具体的Pipeline如下,其实就是设计了一个可以学习的Augmentor去设计更难更有效果的数据增强,去提升Classifier的效果。注意到训练的时候是原始的输入和增强过的输入一起去优化。
Augmentor的设计如右图,每个点的特征通过一个PointNet的结果去得到全局特征,然后通过引入一个噪声去生成
的旋转矩阵,可以同样用逐个点的特征拼上全局特征和噪声,得到一个
的位移矩阵。最后两个矩阵可以生成最后的数据增强矩阵。
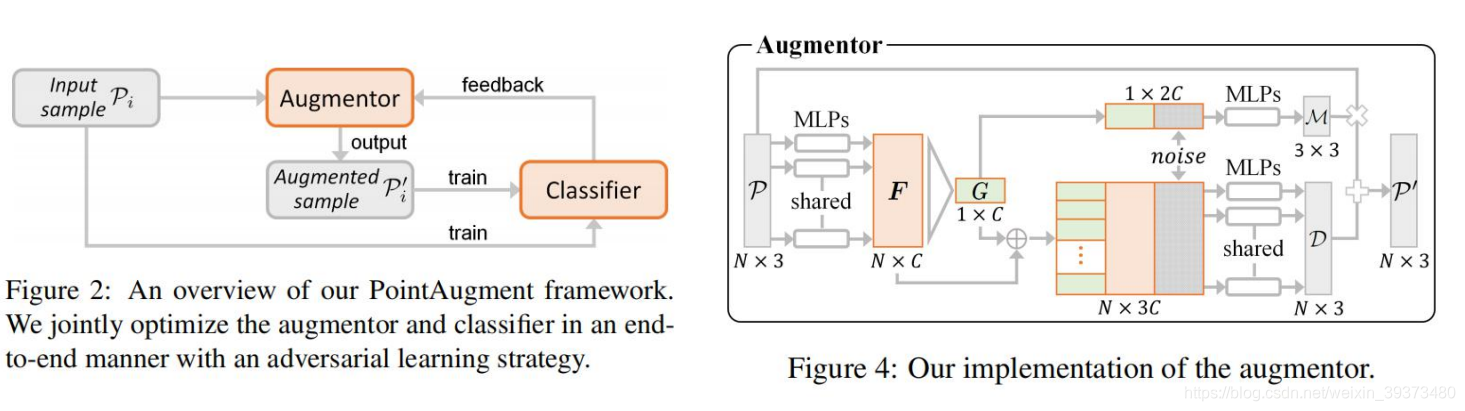
如何训练
作者认为,由Augmentor生成出来的sample
应该满足以下两个要求:
(1)
应该要比普通的样本
更难,因此其设计了如下Loss,即让
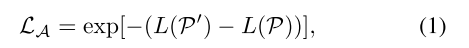
(2)
不能失去自己本来的一些特征,即不一样,但不能太不一样(如飞机变成汽车)。因此其引入了一个项
相当于引入了一个上确界。
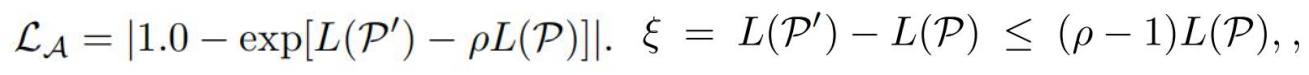
因此在训练的时候就像GAN一样,对Augmentor和Classifer轮流训练,其Loss如下:

这里还在训练Classifier的时候提出了要让原始的输入和Augmentor增强后的输入得到的全局特征相互接近。
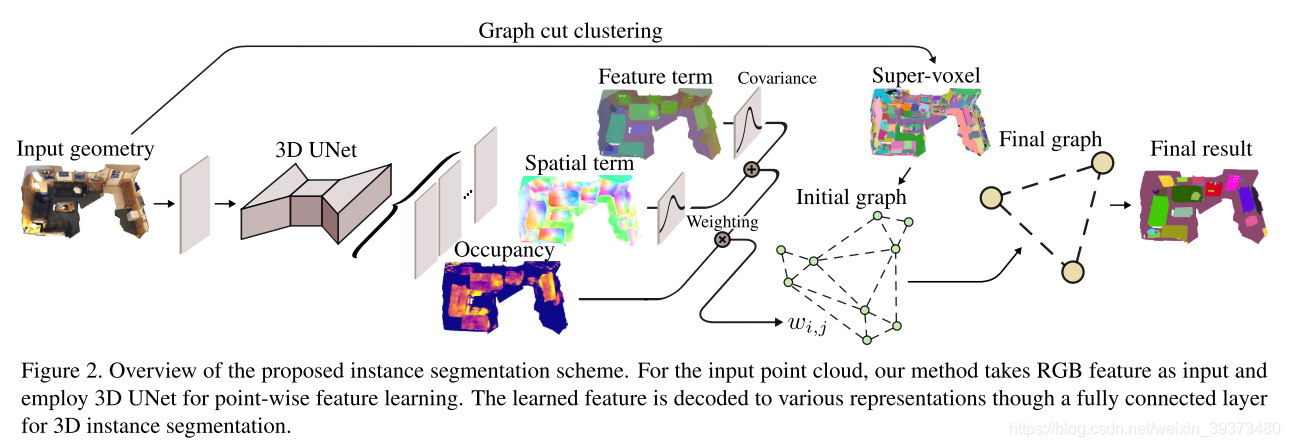
基于体素化的3D实例分割网络,会由于对无效的空体素的处理而浪费大量的计算,空间稀疏卷积网络出现可以有效的消除体素化网络的这一缺陷,作者在稀疏卷积的基础上提出了OccuSeg网络,并引入了“3D occupancy size/signal”的概念(表示每个实例所占据的voxels的数量),occupancy signal能够缓解3D点云中目标尺度,位置,纹理和光强等模糊性的诸多问题。
Pipeline
OccuSeg的网络框架如下图所示,主要分为Multi-task Learning和Instance Clustering两个阶段。首先将体素化(voxel size为2cm)的点云scene输入到3D UNet backbone中进行特征提取,然后用三个task head分别产生语义分割的特征和空间嵌入以及occupancy回归的结果,最后进行graph-based以及occupancy-aware的instance clustering过程产生最终的实例分割结果。
Loss
论文联合学习的Loss如下所示:
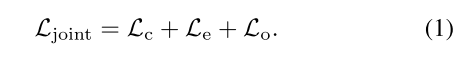
其中
为语义分割中每个voxel类别标签预测的交叉熵损失,
是实例嵌入(包括空间和特征嵌入)的损失,
是occupancy size的回归损失。
(1)Embedding Learning
作者注意到空间嵌入是scale-aware的而特征嵌入并没有这一特点,故区别于其他直接将空间嵌入和特征嵌入结合在一起的方法,作者将这两者分开考虑,将实例嵌入
定义为:
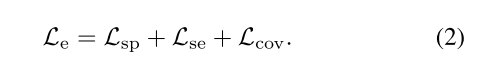
其中
为空间嵌入损失,
为特征嵌入损失,
为用于正则化处理的协方差项。各项的具体表达式如下:
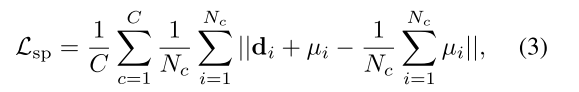
其中C是输入点云的实例数,
是第c个实例中的体素数,
是第i个体素的空间嵌入,
代表第c个实例中第i体素的位置。这其实是votenet中的voting操作,将每个实例的点靠近每个实例的中心。
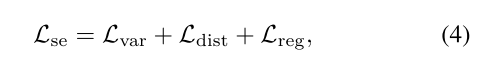
其中方差项
使得当前点的特征嵌入靠近其所属实例平均的特征嵌入,距离项
使得各个实例之间尽量远离,正则项
用于保证嵌入值有界。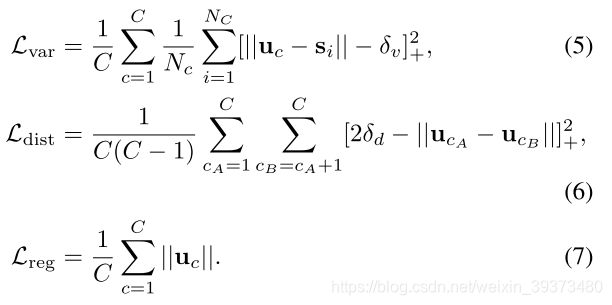
其中
代表第c个实例的平均特征嵌入,
表示第c个实例中第i个体素特征嵌入,阈值
和
被预定义为0.1和1.5,以确保实例内的嵌入距离小于实例间的距离。
协方差项
旨在学习每个实例最优化的聚类区域,
代表第c个实例中第i个体素预测特征/空间的协方差,在第c-th实例中平均化bi得到
,然后将i-th体素属于c-th实例的概率定义为:
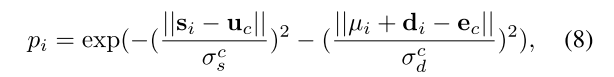
其中
表示预测的c-th实例的中心位置,
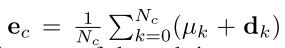
公式(8)其实将空间embedding和特征embedding都归一化到一个均值为0,方差为1的正太分布上,因此当pi > 0.5时,就认为i-th体素属于c-th实例,故可将协方差项的损失定义为交叉熵损失:
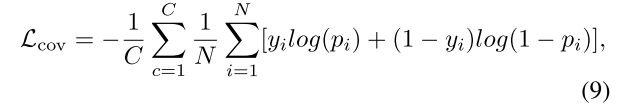
yi = 1表示i属于c,N表示输入点云中点的数目
(2)Occupancy Regression
其中c-th实例中
的平均值被视为当前实例的occupancy size的预测值(为了提高鲁棒性,occupancy size的真值和预测值均做了对数表达)
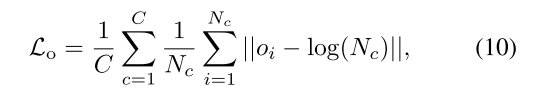
作者还定义了相关预测误差来评估occupancy size预测的性能
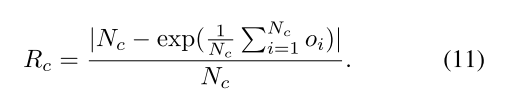
Instance Clustering
作者在这里采用graph-based的分割方法,利用bottom-up的策略将输入的voxels分组成super-voxels以实现实例分割,(由于3D空间中实例boundary的几何连续性,这种方法比对应的2D问题处理更有效)
定义super-voxel
的空间嵌入为:
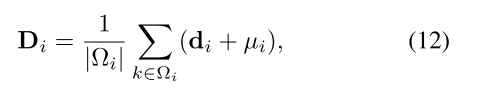
其中
表示属于
中的所有voxels的集合,
为
中voxels的数目。
的特征嵌入
,occupancy size
,协方差也类似地定义。
定义occupancy ratio ri,来指导instance clustering过程,
表示vi中的voxel过多,
表示vi中的voxel过少

根据上述的super-voxel的定义,可以建立一个无向图
,
表示产生的super-voxel,
表示super-voxel顶点对,
表示顶点对之间的权重(
和
之间的相似性),权重越大表示vi和vj越有可能属于同一个实例
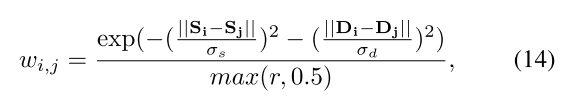
其中
,
,
分别表示特征协方差,空间协方差和occupancy ratio,在这里r能够起到惩罚over segmentation和merge部分分割的作用
在满足
的条件下(
设置为0.5),对于E中所有的边,选择权重最高的边
将其顶点merge为一个新的顶点,反复迭代,直至没有边的权重 > T0,这时,G中剩余的顶点在满足
的条件下label为实例以消除假阳性。这个步骤类似于条件随机场。
该工作在ScanNet的语义分割和实例分割benchmark上都刷到了第一名,并且网络非常地轻巧。
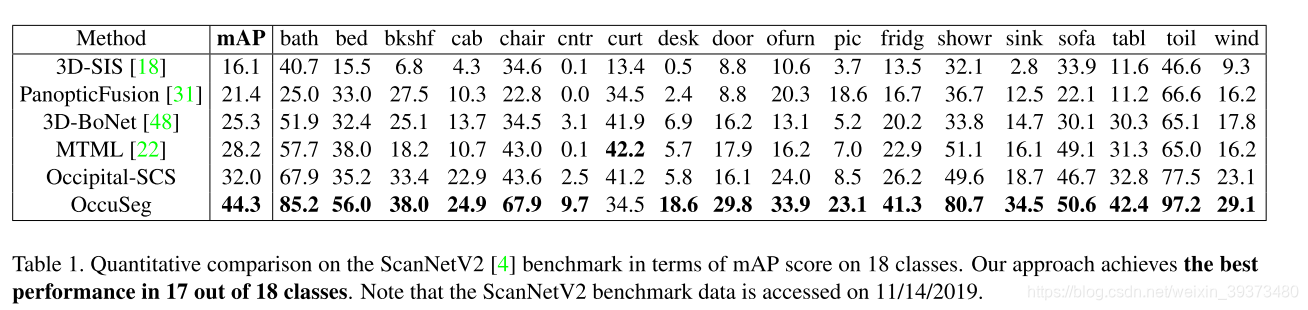
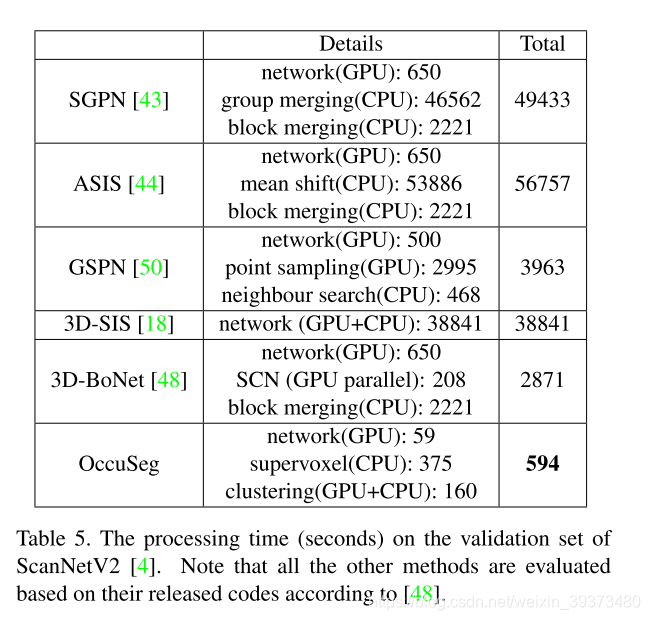
这一篇的创新点主要在Dual-Set Point Grouping上面。其本质思想是通过votenet去移动点到物体的中心,然后对这个移动后的vote和原始点云同时聚类。
Pipeline
整体的网络框架如上图所示,由三个模块组成,即主干网、点云聚类模块和ScoreNet。输入点云经由3D U-Net主干网提取特征后分成两个分支分别预测每个点的语义和相对于实例中心点的offset;然后在点云聚类模块中通过利用每个点的语义、原始坐标和shift坐标(原始点坐标+offset值)进行点的实例分组得到cluster proposals,最后ScoreNet对cluster proposals打分之后进行非极大值抑制得到最终的实例分割结果。
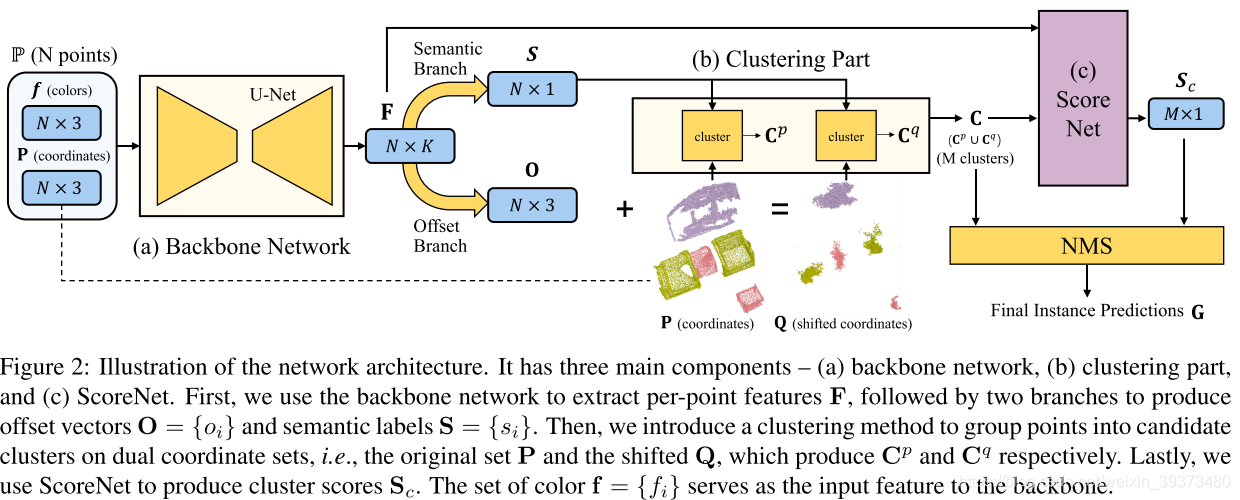
Offset Prediction
其在Offset Prediction Branch中为了解决large-size目标上边缘点回归的offset不精准的问题,提出了中心点朝向loss(cosine相似度):
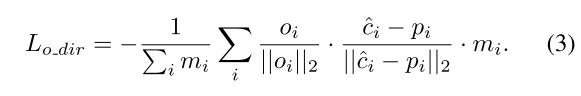
Clustering
在上一步得到每个点的语义、原始坐标和shift坐标后,用上图的算法对点云进行实例聚类。在该算法中,每个点设置近邻半径r作为空间约束,避免了半径大于r的同语义点被分成一个实例组,而且由于该聚类算法作用在“dual” set(原始坐标集和shift坐标集)上,避免了原始坐标集的聚类可能将邻近实例的同语义点分成一个实例组以及shift坐标集的聚类可能无法正确地将large-size的边缘点正确分组的问题。
ScoreNet
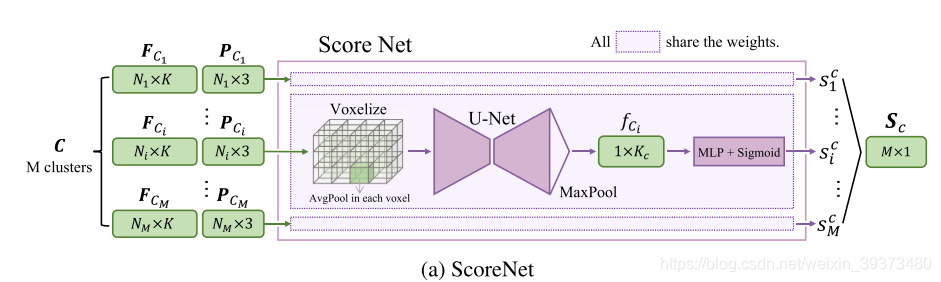
ScoreNet的内部结构如上图所示,为了让ScoreNet输出的分数更好地反映每个cluster proposal的质量,作者定义了soft IOU来对score进行监督:
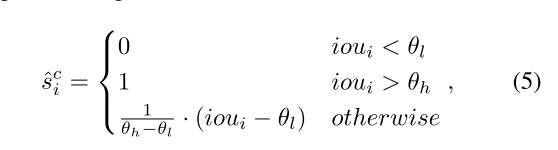
其中
和
分别设置为0.25和0.75。最后score预测的交叉熵loss为:
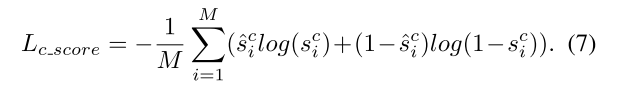
ScanNet上层级刷到过第一名
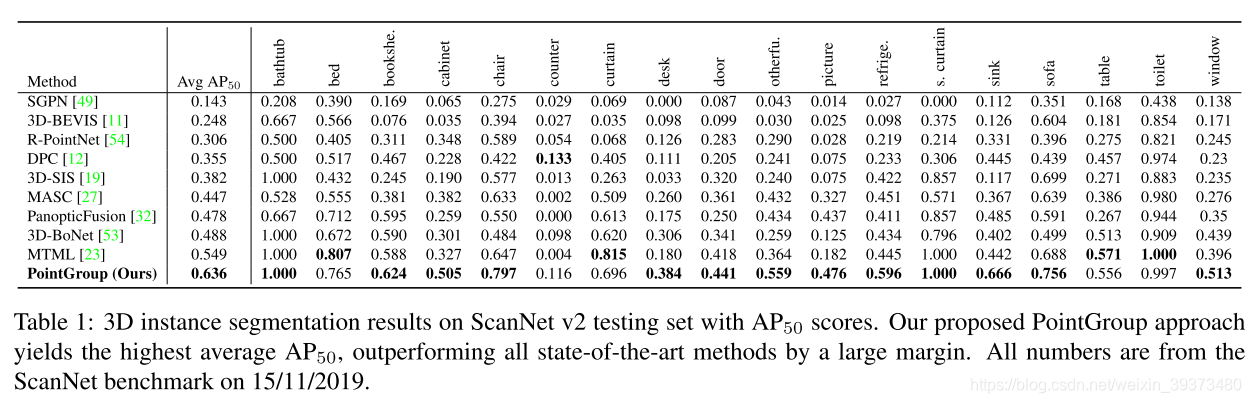
这篇论文主要是在votenet上面进行了一系列改进(1)用了更厉害的sparseconv作为backbone而不是pointnet++;(2)用了DGCNN去学习proposal之间的特征,使得bounding box的输出效果更好;(3)使用特定的Loss增加特征或者空间上的近似度,然后使用DBSCAN聚类。
3D-MPA的整个网络框架如上图所示,主要由三个部分组成,proposal generation部分对输入点云中的每个点vote其所属实例的中心点然后根据vote结果产生proposals;proposal consolidation部分利用图卷积网络得到proposals之间higher-level的关系来对提取的proposal features进行refine;object generation部分对前面产生的proposals进行聚类得到最终的目标检测以及语义实例分割结果。
在object generation的过程中,将前面得到的proposals通过MLP产生objectness score,该分数用于表明proposal为positive还是negative,和某个gt中心点距离小于0.3m的设为正,大于0.6m或和两个gt中心点距离相等(避免模糊性)的设为负。对正proposals继续预测其语义类别,aggregation features和二值实例mask,负proposals不做处理。语义类别的loss为交叉熵loss;二值实例mask的loss为focal loss(前背景点数量不平衡);proposal refine过程作者认为NMS可能会错误地将正确的proposal去掉,故作者引入了aggregation features并在其上进行聚类得到最终的实例proposal,由于proposals的数量(K ~ 500)比原始点云中点的数量(N ~ 106)少了几个数量级,故在proposals上聚类并不消耗内存, aggregation features的loss为:

作者尝试了以后发现使用DBSCAN结合第一种Loss的效果最好,其中
表示GT实例的中心点,
表示GT实例区域对中心点的半径。
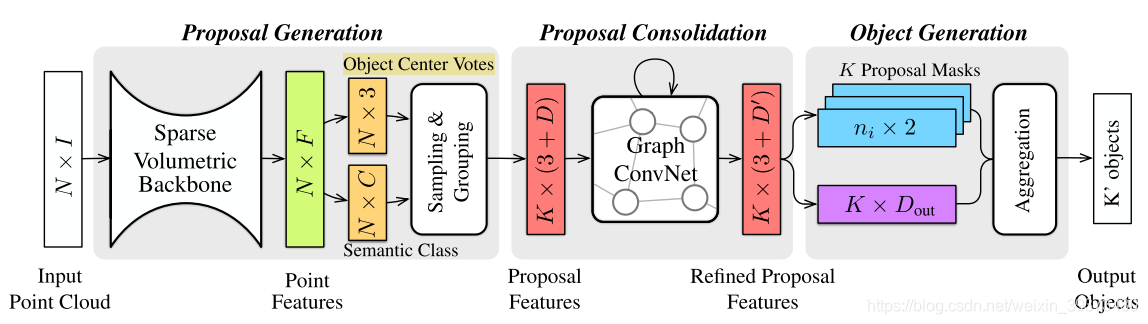
这篇工作提出了一个串联的coarse-to-fine的点云上采样网络,并提出了local-patch的对抗学习方法。
(1)这篇论文的pipeline如图所示,先有PointNet(图中的Feature Extraction)提出一个全局的特征,通过两层FC层得到一个粗糙的重建结果(图中的Coarse Reconstruction)。然后原始点云通过最远点下采样(FPS)得到的点与该重建结果在点的个数维度拼接起来,送入Lifting module。
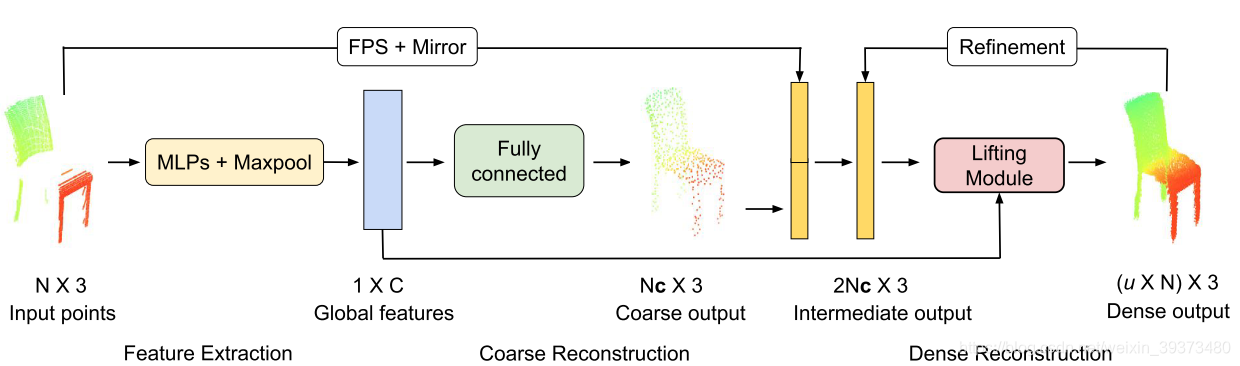
(2)Lifting module的结构如下,主要就通过了点云的坐标,全局特征和2Dgrid(FoldingNet中提出的,即通过cutting, squeezing, 或stretching的方法将物体映射到2D平面)一起作为输入,然后通过up-down-up的结构(如PU-GAN)去进行重构。
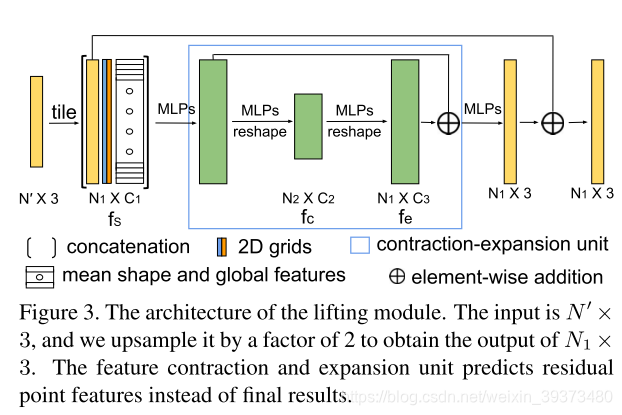
(3)这篇工作还提出了一个patch-based的对抗学习,结构如下:
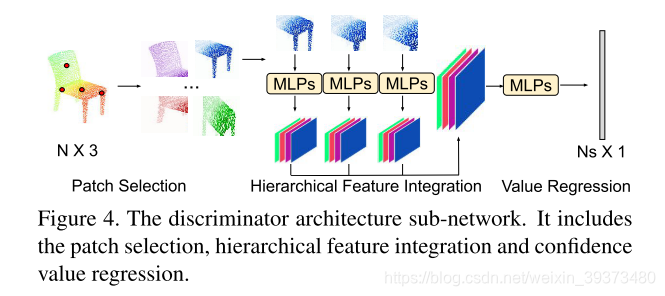
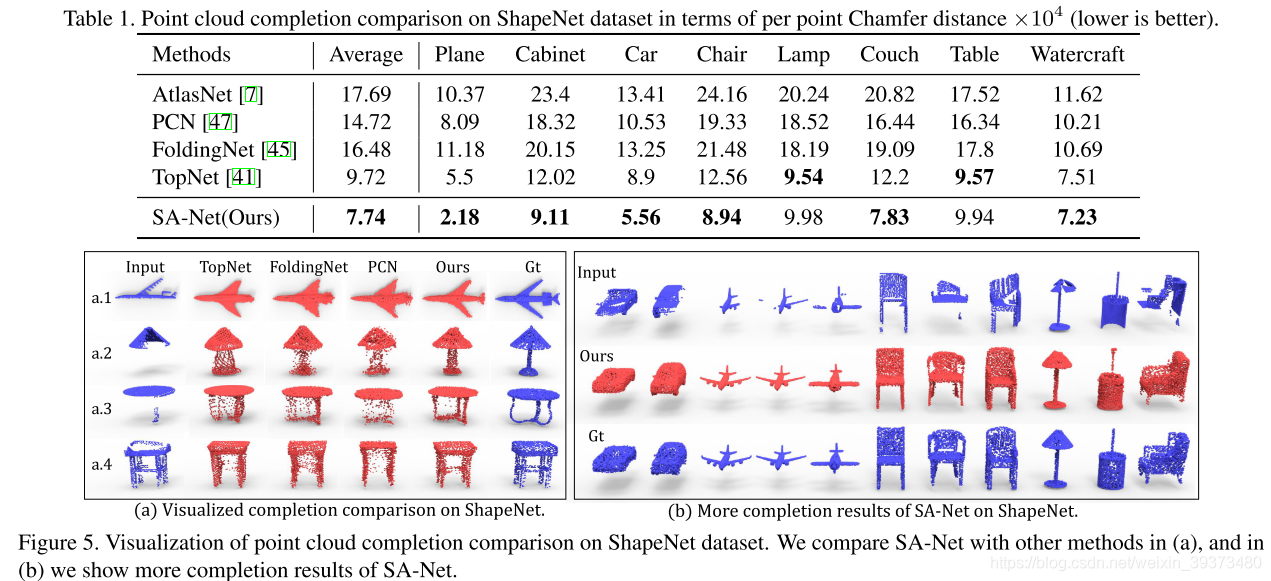
实验结果其比baseline的PCN和TopNet好了很多,但是没有对比最近的SOTA方法。
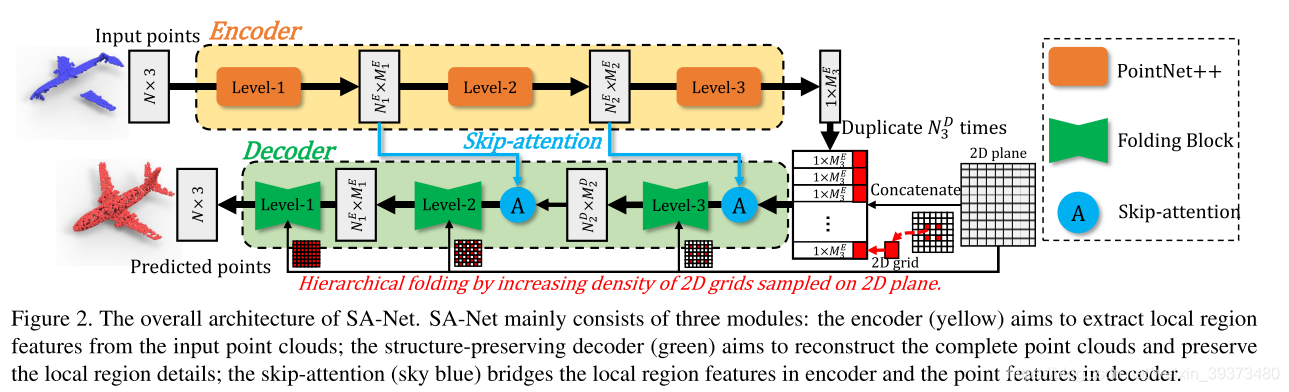
这篇工作提出了一个利用跳跃注意力机制来更好地重建的方法。
Pipeline
如图所示,encoder其实就是一个PointNet++,decoder被称为folding block(下面会讲)在encoder和decoder相同的scale的层之间会有一个注意力机制去加权encoder的特征到decoder的每个点上,这是这篇工作的核心贡献。
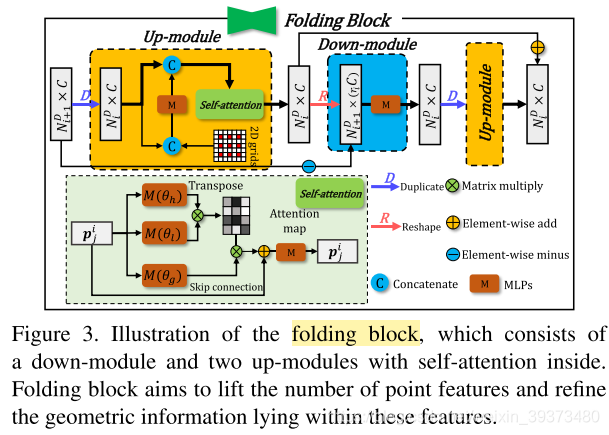
Folding block
其实也是使用了PU-GAN之中up-down-up的操作,只不过在up模块中多了一个自注意力机制。并且这篇工作中改进了FoldingNet中的folding模块。
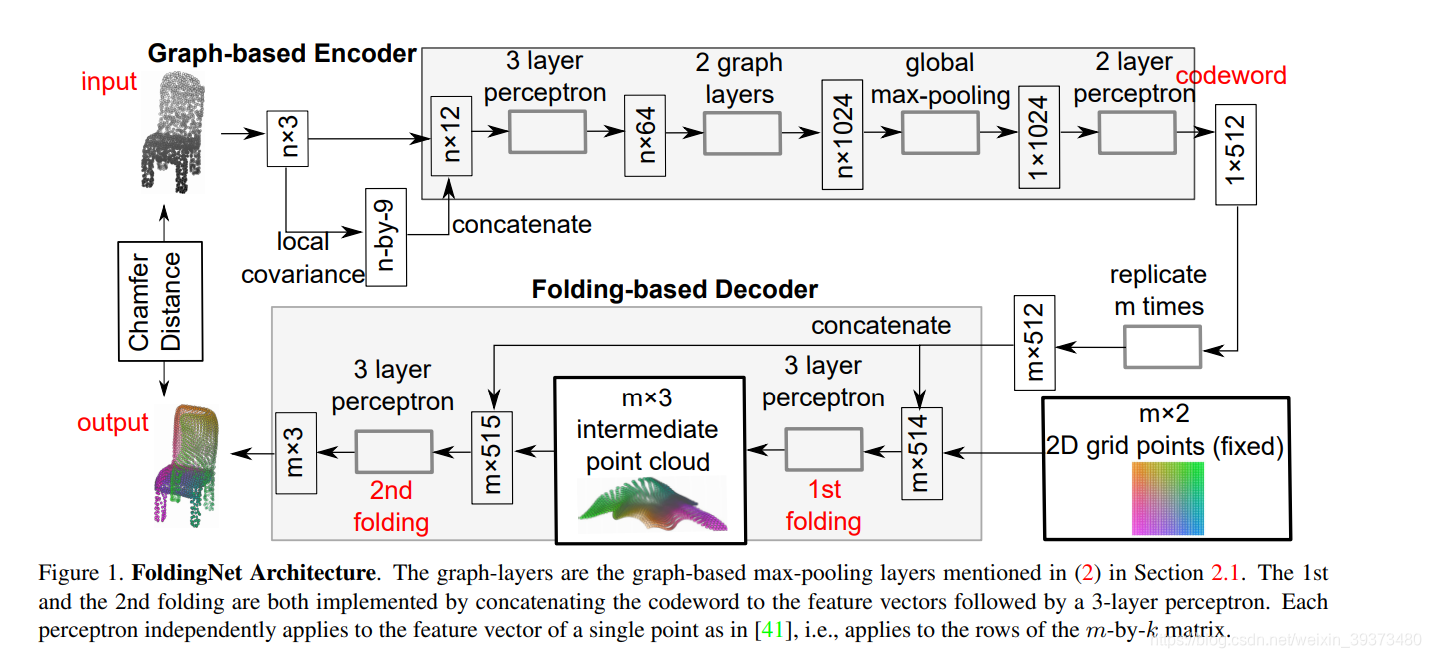
在FoldingNet中(如上图),由3D投影到的2D grid被拼接到复制过的全局的特征上,并通过新的MLP生成3维度的逐点特征,再继续拼接,出重建点云。但是再这一篇工作里它对于每一个层使用了不同分辨率的对2D grid进行采样,通过逐渐增加密度来不断encode更密集的特征(如下图)。
感谢这个大哥在知乎上面写的3D点云相关论文笔记,节省了我很多看文章的时间~
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)











 1291
1291