新人上路,请多多指教。 一直想写博客,今天才开始写第一篇。 —————————————————————————————————————————————————————————- 这次来讲一下VTM9.0中关于CU划分的部分,主要是两个函数xCompressCU和xCheckModeSplit。 xCompressCU主要针对当前CU可能进行的预测划分模式,完成相应的操作。主要分为以下几种模式(后面两种暂时还没学习,后面如果接触到会补充) 1划分模式:四叉树划分,水平二叉树划分,垂直二叉树划分,水平三叉树划分,垂直三叉树划分。通过调用函数xCompressCU完成。 2帧内预测:调用函数xCheckRDCostIntra完成。 3帧间预测:。。。。 4屏幕内容编码:。。。。 xCompressCU函数流程:初始化,调用函数initCULevel(),获取当前CU可能的预测和编码模式,并且按照顺序推入栈中。然后进入一循环,改循环会不断调取栈顶模式,将CU按照相应模式进行编码或划分,直至栈内不储存模式为止。具体代码如下: 划分主要时调用函数xCheckModeSplit完成。函数xCheckModeSplit流程如下 函数xCheckModeSplit具体代码如下: 这部分代码稍微看的有点绕,是由于xCompressCU函数中调用了函数xCheckModeSplit,在函数xCheckModeSplit又调用了xCompressCU。这样CU递归划分直到不能划分为止。对CU进行RDO的逻辑是先对当前CU进行编码,再对其划分,对划分完的各个子块进行编码,若(不划分的RDcost)> (划分的RDcost+划分需要多传输的bit数),那么就进行划分,否则不划分。可以在xCompressCU函数开头打印log判断cu划分与编码的顺序。如下图所示,其中模式5为帧内预测模式,其余为划分模式。
void EncCu::xCompressCU( CodingStructure*& tempCS, CodingStructure*& bestCS, Partitioner& partitioner, double maxCostAllowed ) { /*************************************** 初始化 ****************************************/ CHECK(maxCostAllowed < 0, "Wrong value of maxCostAllowed!"); #if ENABLE_SPLIT_PARALLELISM CHECK( m_dataId != tempCS->picture->scheduler.getDataId(), "Working in the wrong dataId!" ); if( m_pcEncCfg->getNumSplitThreads() != 1 && tempCS->picture->scheduler.getSplitJobId() == 0 ) { if( m_modeCtrl->isParallelSplit( *tempCS, partitioner ) ) { m_modeCtrl->setParallelSplit( true ); xCompressCUParallel( tempCS, bestCS, partitioner ); return; } } #endif uint32_t compBegin; uint32_t numComp; bool jointPLT = false; if (partitioner.isSepTree( *tempCS )) { #if JVET_Q0504_PLT_NON444 if( !CS::isDualITree(*tempCS) && partitioner.treeType != TREE_D ) { compBegin = COMPONENT_Y; numComp = (tempCS->area.chromaFormat != CHROMA_400)?3: 1; jointPLT = true; } else { #endif if (isLuma(partitioner.chType)) { compBegin = COMPONENT_Y; numComp = 1; } else { compBegin = COMPONENT_Cb; numComp = 2; } #if JVET_Q0504_PLT_NON444 } #endif } else { compBegin = COMPONENT_Y; #if JVET_Q0504_PLT_NON444 numComp = (tempCS->area.chromaFormat != CHROMA_400) ? 3 : 1; #else numComp = 3; #endif jointPLT = true; } SplitSeries splitmode = -1; uint8_t bestLastPLTSize[MAX_NUM_CHANNEL_TYPE]; Pel bestLastPLT[MAX_NUM_COMPONENT][MAXPLTPREDSIZE]; // store LastPLT for uint8_t curLastPLTSize[MAX_NUM_CHANNEL_TYPE]; Pel curLastPLT[MAX_NUM_COMPONENT][MAXPLTPREDSIZE]; // store LastPLT if no partition for (int i = compBegin; i < (compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); bestLastPLTSize[comID] = 0; curLastPLTSize[comID] = tempCS->prevPLT.curPLTSize[comID]; memcpy(curLastPLT[i], tempCS->prevPLT.curPLT[i], tempCS->prevPLT.curPLTSize[comID] * sizeof(Pel)); } Slice& slice = *tempCS->slice; const PPS &pps = *tempCS->pps; const SPS &sps = *tempCS->sps; const uint32_t uiLPelX = tempCS->area.Y().lumaPos().x; const uint32_t uiTPelY = tempCS->area.Y().lumaPos().y; const ModeType modeTypeParent = partitioner.modeType; const TreeType treeTypeParent = partitioner.treeType; const ChannelType chTypeParent = partitioner.chType; const UnitArea currCsArea = clipArea( CS::getArea( *bestCS, bestCS->area, partitioner.chType ), *tempCS->picture ); m_modeCtrl->initCULevel( partitioner, *tempCS );//初始化所有编码划分模式,为CU设置可能的编码划分模式 if( partitioner.currQtDepth == 0 && partitioner.currMtDepth == 0 && !tempCS->slice->isIntra() && ( sps.getUseSBT() || sps.getUseInterMTS() ) ) { auto slsSbt = dynamic_cast<SaveLoadEncInfoSbt*>( m_modeCtrl ); int maxSLSize = sps.getUseSBT() ? tempCS->slice->getSPS()->getMaxTbSize() : MTS_INTER_MAX_CU_SIZE; slsSbt->resetSaveloadSbt( maxSLSize ); #if ENABLE_SPLIT_PARALLELISM CHECK( tempCS->picture->scheduler.getSplitJobId() != 0, "The SBT search reset need to happen in sequential region." ); if (m_pcEncCfg->getNumSplitThreads() > 1) { for (int jId = 1; jId < NUM_RESERVERD_SPLIT_JOBS; jId++) { auto slsSbt = dynamic_cast<SaveLoadEncInfoSbt *>(m_pcEncLib->getCuEncoder(jId)->m_modeCtrl); slsSbt->resetSaveloadSbt(maxSLSize); } } #endif } m_sbtCostSave[0] = m_sbtCostSave[1] = MAX_DOUBLE; m_CurrCtx->start = m_CABACEstimator->getCtx(); /************************* 处理色度QP ***************************/ m_cuChromaQpOffsetIdxPlus1 = 0; if( slice.getUseChromaQpAdj() ) { // TODO M0133 : double check encoder decisions with respect to chroma QG detection and actual encode int lgMinCuSize = sps.getLog2MinCodingBlockSize() + #if JVET_Q0468_Q0469_MIN_LUMA_CB_AND_MIN_QT_FIX std::max<int>(0, floorLog2(sps.getCTUSize()) - sps.getLog2MinCodingBlockSize() - int(slice.getCuChromaQpOffsetSubdiv() / 2)); #else std::max<int>( 0, sps.getLog2DiffMaxMinCodingBlockSize() - int( slice.getCuChromaQpOffsetSubdiv()/2 ) ); #endif #if JVET_Q0267_RESET_CHROMA_QP_OFFSET if( partitioner.currQgChromaEnable() ) { m_cuChromaQpOffsetIdxPlus1 = ( ( uiLPelX >> lgMinCuSize ) + ( uiTPelY >> lgMinCuSize ) ) % ( pps.getChromaQpOffsetListLen() + 1 ); } #else m_cuChromaQpOffsetIdxPlus1 = ( ( uiLPelX >> lgMinCuSize ) + ( uiTPelY >> lgMinCuSize ) ) % ( pps.getChromaQpOffsetListLen() + 1 ); #endif } if( !m_modeCtrl->anyMode() ) { m_modeCtrl->finishCULevel( partitioner ); return; } DTRACE_UPDATE( g_trace_ctx, std::make_pair( "cux", uiLPelX ) ); DTRACE_UPDATE( g_trace_ctx, std::make_pair( "cuy", uiTPelY ) ); DTRACE_UPDATE( g_trace_ctx, std::make_pair( "cuw", tempCS->area.lwidth() ) ); DTRACE_UPDATE( g_trace_ctx, std::make_pair( "cuh", tempCS->area.lheight() ) ); DTRACE( g_trace_ctx, D_COMMON, "@(%4d,%4d) [%2dx%2d]n", tempCS->area.lx(), tempCS->area.ly(), tempCS->area.lwidth(), tempCS->area.lheight() ); m_pcInterSearch->resetSavedAffineMotion(); double bestIntPelCost = MAX_DOUBLE; if (tempCS->slice->getSPS()->getUseColorTrans()) { tempCS->tmpColorSpaceCost = MAX_DOUBLE; bestCS->tmpColorSpaceCost = MAX_DOUBLE; tempCS->firstColorSpaceSelected = true; bestCS->firstColorSpaceSelected = true; } if (tempCS->slice->getSPS()->getUseColorTrans() && !CS::isDualITree(*tempCS)) { tempCS->firstColorSpaceTestOnly = false; bestCS->firstColorSpaceTestOnly = false; tempCS->tmpColorSpaceIntraCost[0] = MAX_DOUBLE; tempCS->tmpColorSpaceIntraCost[1] = MAX_DOUBLE; bestCS->tmpColorSpaceIntraCost[0] = MAX_DOUBLE; bestCS->tmpColorSpaceIntraCost[1] = MAX_DOUBLE; if (tempCS->bestParent && tempCS->bestParent->firstColorSpaceTestOnly) { tempCS->firstColorSpaceTestOnly = bestCS->firstColorSpaceTestOnly = true; } } /***************************按照堆栈中的模式进行循环预测编码或划分,当循环结束时当前CU已选择最小的RDcost进行划分与编码****************************/ do//尝试当前编码器各种可用的模式:如skip,帧间,帧内,PCM等,进行预测及划分。 { for (int i = compBegin; i < (compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); tempCS->prevPLT.curPLTSize[comID] = curLastPLTSize[comID]; memcpy(tempCS->prevPLT.curPLT[i], curLastPLT[i], curLastPLTSize[comID] * sizeof(Pel)); } EncTestMode currTestMode = m_modeCtrl->currTestMode();//获得本次循环的编码或划分模式 currTestMode.maxCostAllowed = maxCostAllowed; if (pps.getUseDQP() && partitioner.isSepTree(*tempCS) && isChroma( partitioner.chType )) { const Position chromaCentral(tempCS->area.Cb().chromaPos().offset(tempCS->area.Cb().chromaSize().width >> 1, tempCS->area.Cb().chromaSize().height >> 1)); const Position lumaRefPos(chromaCentral.x << getComponentScaleX(COMPONENT_Cb, tempCS->area.chromaFormat), chromaCentral.y << getComponentScaleY(COMPONENT_Cb, tempCS->area.chromaFormat)); const CodingStructure* baseCS = bestCS->picture->cs; const CodingUnit* colLumaCu = baseCS->getCU(lumaRefPos, CHANNEL_TYPE_LUMA); if (colLumaCu) { currTestMode.qp = colLumaCu->qp; } } #if SHARP_LUMA_DELTA_QP || ENABLE_QPA_SUB_CTU if (partitioner.currQgEnable() && ( #if SHARP_LUMA_DELTA_QP (m_pcEncCfg->getLumaLevelToDeltaQPMapping().isEnabled()) || #endif #if ENABLE_QPA_SUB_CTU (m_pcEncCfg->getUsePerceptQPA() && !m_pcEncCfg->getUseRateCtrl() && pps.getUseDQP()) #else false #endif )) { #if ENABLE_SPLIT_PARALLELISM CHECK( tempCS->picture->scheduler.getSplitJobId() > 0, "Changing lambda is only allowed in the master thread!" ); #endif if (currTestMode.qp >= 0) { updateLambda (&slice, currTestMode.qp, #if WCG_EXT && ER_CHROMA_QP_WCG_PPS m_pcEncCfg->getWCGChromaQPControl().isEnabled(), #endif CS::isDualITree (*tempCS) || (partitioner.currDepth == 0)); } } #endif if( currTestMode.type == ETM_INTER_ME )//帧间运动估计-运动搜索(wan) { if( ( currTestMode.opts & ETO_IMV ) != 0 ) { const bool skipAltHpelIF = ( int( ( currTestMode.opts & ETO_IMV ) >> ETO_IMV_SHIFT ) == 4 ) && ( bestIntPelCost > 1.25 * bestCS->cost ); if (!skipAltHpelIF) { tempCS->bestCS = bestCS; xCheckRDCostInterIMV(tempCS, bestCS, partitioner, currTestMode, bestIntPelCost); tempCS->bestCS = nullptr; } } else { tempCS->bestCS = bestCS; xCheckRDCostInter( tempCS, bestCS, partitioner, currTestMode ); tempCS->bestCS = nullptr; } } else if (currTestMode.type == ETM_HASH_INTER)// IBC? { xCheckRDCostHashInter( tempCS, bestCS, partitioner, currTestMode ); } else if( currTestMode.type == ETM_AFFINE )// 仿射,旋转(266) { xCheckRDCostAffineMerge2Nx2N( tempCS, bestCS, partitioner, currTestMode ); } #if REUSE_CU_RESULTS else if( currTestMode.type == ETM_RECO_CACHED )//快速算法,内存级别 { xReuseCachedResult( tempCS, bestCS, partitioner ); } #endif else if( currTestMode.type == ETM_MERGE_SKIP )//MERGE,SKIP(wan) { xCheckRDCostMerge2Nx2N( tempCS, bestCS, partitioner, currTestMode ); CodingUnit* cu = bestCS->getCU(partitioner.chType); if (cu) cu->mmvdSkip = cu->skip == false ? false : cu->mmvdSkip; } #if !JVET_Q0806 else if( currTestMode.type == ETM_MERGE_TRIANGLE ) { xCheckRDCostMergeTriangle2Nx2N( tempCS, bestCS, partitioner, currTestMode ); } #else else if( currTestMode.type == ETM_MERGE_GEO )//一个CU划分成两个,分别找 { xCheckRDCostMergeGeo2Nx2N( tempCS, bestCS, partitioner, currTestMode ); } #endif else if( currTestMode.type == ETM_INTRA )//帧内 { #if SPLIT_TEST printf("intra: (%2d,%2d) %2d %2d : mode:%2d chan:%dn", tempCS->area.blocks[0].x, tempCS->area.blocks[0].y, tempCS->area.blocks[0].width, tempCS->area.blocks[0].height, currTestMode.type, partitioner.chType); #endif if (slice.getSPS()->getUseColorTrans() && !CS::isDualITree(*tempCS)) { bool skipSecColorSpace = false; skipSecColorSpace = xCheckRDCostIntra(tempCS, bestCS, partitioner, currTestMode, (m_pcEncCfg->getRGBFormatFlag() ? true : false));//帧内预测编码 #if JVET_Q0820_ACT if ((m_pcEncCfg->getCostMode() == COST_LOSSLESS_CODING) && !m_pcEncCfg->getRGBFormatFlag()) { skipSecColorSpace = true; } #endif if (!skipSecColorSpace && !tempCS->firstColorSpaceTestOnly) { xCheckRDCostIntra(tempCS, bestCS, partitioner, currTestMode, (m_pcEncCfg->getRGBFormatFlag() ? false : true)); } if (!tempCS->firstColorSpaceTestOnly) { if (tempCS->tmpColorSpaceIntraCost[0] != MAX_DOUBLE && tempCS->tmpColorSpaceIntraCost[1] != MAX_DOUBLE) { double skipCostRatio = m_pcEncCfg->getRGBFormatFlag() ? 1.1 : 1.0; if (tempCS->tmpColorSpaceIntraCost[1] > (skipCostRatio*tempCS->tmpColorSpaceIntraCost[0])) { tempCS->firstColorSpaceTestOnly = bestCS->firstColorSpaceTestOnly = true; } } } else { CHECK(tempCS->tmpColorSpaceIntraCost[1] != MAX_DOUBLE, "the RD test of the second color space should be skipped"); } } else { xCheckRDCostIntra(tempCS, bestCS, partitioner, currTestMode, false); } } else if (currTestMode.type == ETM_PALETTE)//调色板 { xCheckPLT( tempCS, bestCS, partitioner, currTestMode ); } else if (currTestMode.type == ETM_IBC)//IBC { xCheckRDCostIBCMode(tempCS, bestCS, partitioner, currTestMode); } else if (currTestMode.type == ETM_IBC_MERGE) { xCheckRDCostIBCModeMerge2Nx2N(tempCS, bestCS, partitioner, currTestMode); } else if( isModeSplit( currTestMode ) )//compresscu-先判断能否继续划分-xCheckModeSplit-compresscu {//如果判断type是五种划分模式其中一种 #if SPLIT_TEST printf("split: (%2d,%2d) %2d %2d : mode:%2d chan:%dn", tempCS->area.blocks[0].x, tempCS->area.blocks[0].y, tempCS->area.blocks[0].width, tempCS->area.blocks[0].height, currTestMode.type, partitioner.chType); #endif if (bestCS->cus.size() != 0) { splitmode = bestCS->cus[0]->splitSeries; } assert( partitioner.modeType == tempCS->modeType ); int signalModeConsVal = tempCS->signalModeCons( getPartSplit( currTestMode ), partitioner, modeTypeParent ); int numRoundRdo = signalModeConsVal == LDT_MODE_TYPE_SIGNAL ? 2 : 1; bool skipInterPass = false; for( int i = 0; i < numRoundRdo; i++ ) { //change cons modes if( signalModeConsVal == LDT_MODE_TYPE_SIGNAL ) { CHECK( numRoundRdo != 2, "numRoundRdo shall be 2 - [LDT_MODE_TYPE_SIGNAL]" ); tempCS->modeType = partitioner.modeType = (i == 0) ? MODE_TYPE_INTER : MODE_TYPE_INTRA; } else if( signalModeConsVal == LDT_MODE_TYPE_INFER ) { CHECK( numRoundRdo != 1, "numRoundRdo shall be 1 - [LDT_MODE_TYPE_INFER]" ); tempCS->modeType = partitioner.modeType = MODE_TYPE_INTRA; } else if( signalModeConsVal == LDT_MODE_TYPE_INHERIT ) { CHECK( numRoundRdo != 1, "numRoundRdo shall be 1 - [LDT_MODE_TYPE_INHERIT]" ); tempCS->modeType = partitioner.modeType = modeTypeParent; } //for lite intra encoding fast algorithm, set the status to save inter coding info //对于精简帧内编码快速算法,设置状态以保存帧间编码信息 if( modeTypeParent == MODE_TYPE_ALL && tempCS->modeType == MODE_TYPE_INTER ) { m_pcIntraSearch->setSaveCuCostInSCIPU( true ); m_pcIntraSearch->setNumCuInSCIPU( 0 ); } else if( modeTypeParent == MODE_TYPE_ALL && tempCS->modeType != MODE_TYPE_INTER ) { m_pcIntraSearch->setSaveCuCostInSCIPU( false ); if( tempCS->modeType == MODE_TYPE_ALL ) { m_pcIntraSearch->setNumCuInSCIPU( 0 ); } } xCheckModeSplit( tempCS, bestCS, partitioner, currTestMode, modeTypeParent, skipInterPass );//划分函数 //recover cons modes tempCS->modeType = partitioner.modeType = modeTypeParent; tempCS->treeType = partitioner.treeType = treeTypeParent; partitioner.chType = chTypeParent; if( modeTypeParent == MODE_TYPE_ALL ) { m_pcIntraSearch->setSaveCuCostInSCIPU( false ); if( numRoundRdo == 2 && tempCS->modeType == MODE_TYPE_INTRA ) { m_pcIntraSearch->initCuAreaCostInSCIPU(); } } if( skipInterPass ) { break; } } if (splitmode != bestCS->cus[0]->splitSeries) { splitmode = bestCS->cus[0]->splitSeries; const CodingUnit& cu = *bestCS->cus.front(); cu.cs->prevPLT = bestCS->prevPLT; for (int i = compBegin; i < (compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); bestLastPLTSize[comID] = bestCS->cus[0]->cs->prevPLT.curPLTSize[comID]; memcpy(bestLastPLT[i], bestCS->cus[0]->cs->prevPLT.curPLT[i], bestCS->cus[0]->cs->prevPLT.curPLTSize[comID] * sizeof(Pel)); } } } else { THROW( "Don't know how to handle mode: type = " << currTestMode.type << ", options = " << currTestMode.opts ); } } while( m_modeCtrl->nextMode( *tempCS, partitioner ) );//开始删掉栈顶的模式与接下来栈内不会存在的模式,进入CU下一个编码/划分模式 ////////////////////////////////////////////////////////////////////////// // Finishing CU #if ENABLE_SPLIT_PARALLELISM if( bestCS->cus.empty() ) { CHECK( bestCS->cost != MAX_DOUBLE, "Cost should be maximal if no encoding found" ); CHECK( bestCS->picture->scheduler.getSplitJobId() == 0, "Should always get a result in serial case" ); m_modeCtrl->finishCULevel( partitioner ); return; } #endif //如果划分失败,则删除m_ComprCUCtxList栈顶,结束划分 if( tempCS->cost == MAX_DOUBLE && bestCS->cost == MAX_DOUBLE ) { //although some coding modes were planned to be tried in RDO, no coding mode actually finished encoding due to early termination //thus tempCS->cost and bestCS->cost are both MAX_DOUBLE; in this case, skip the following process for normal case m_modeCtrl->finishCULevel( partitioner ); return; } // set context states m_CABACEstimator->getCtx() = m_CurrCtx->best; // QP from last processed CU for further processing //copy the qp of the last non-chroma CU int numCUInThisNode = (int)bestCS->cus.size(); if( numCUInThisNode > 1 && bestCS->cus.back()->chType == CHANNEL_TYPE_CHROMA && !CS::isDualITree( *bestCS ) ) { CHECK( bestCS->cus[numCUInThisNode-2]->chType != CHANNEL_TYPE_LUMA, "wrong chType" ); bestCS->prevQP[partitioner.chType] = bestCS->cus[numCUInThisNode-2]->qp; } else { bestCS->prevQP[partitioner.chType] = bestCS->cus.back()->qp; } if ((!slice.isIntra() || slice.getSPS()->getIBCFlag()) && partitioner.chType == CHANNEL_TYPE_LUMA && bestCS->cus.size() == 1 && (bestCS->cus.back()->predMode == MODE_INTER || bestCS->cus.back()->predMode == MODE_IBC) && bestCS->area.Y() == (*bestCS->cus.back()).Y() ) { const CodingUnit& cu = *bestCS->cus.front(); bool isIbcSmallBlk = CU::isIBC(cu) && (cu.lwidth() * cu.lheight() <= 16); CU::saveMotionInHMVP( cu, isIbcSmallBlk ); } bestCS->picture->getPredBuf(currCsArea).copyFrom(bestCS->getPredBuf(currCsArea)); bestCS->picture->getRecoBuf( currCsArea ).copyFrom( bestCS->getRecoBuf( currCsArea ) ); m_modeCtrl->finishCULevel( partitioner );//删除m_ComprCUCtxList栈顶 if( m_pcIntraSearch->getSaveCuCostInSCIPU() && bestCS->cus.size() == 1 ) { m_pcIntraSearch->saveCuAreaCostInSCIPU( Area( partitioner.currArea().lumaPos(), partitioner.currArea().lumaSize() ), bestCS->cost ); } #if ENABLE_SPLIT_PARALLELISM if( tempCS->picture->scheduler.getSplitJobId() == 0 && m_pcEncCfg->getNumSplitThreads() != 1 ) { tempCS->picture->finishParallelPart( currCsArea ); } #endif if (bestCS->cus.size() == 1) // no partition { CHECK(bestCS->cus[0]->tileIdx != bestCS->pps->getTileIdx(bestCS->area.lumaPos()), "Wrong tile index!"); if (bestCS->cus[0]->predMode == MODE_PLT) { for (int i = compBegin; i < (compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); bestCS->prevPLT.curPLTSize[comID] = curLastPLTSize[comID]; memcpy(bestCS->prevPLT.curPLT[i], curLastPLT[i], curLastPLTSize[comID] * sizeof(Pel)); } bestCS->reorderPrevPLT(bestCS->prevPLT, bestCS->cus[0]->curPLTSize, bestCS->cus[0]->curPLT, bestCS->cus[0]->reuseflag, compBegin, numComp, jointPLT); } else { for (int i = compBegin; i<(compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); bestCS->prevPLT.curPLTSize[comID] = curLastPLTSize[comID]; memcpy(bestCS->prevPLT.curPLT[i], curLastPLT[i], bestCS->prevPLT.curPLTSize[comID] * sizeof(Pel)); } } } else { for (int i = compBegin; i<(compBegin + numComp); i++) { ComponentID comID = jointPLT ? (ComponentID)compBegin : ((i > 0) ? COMPONENT_Cb : COMPONENT_Y); bestCS->prevPLT.curPLTSize[comID] = bestLastPLTSize[comID]; memcpy(bestCS->prevPLT.curPLT[i], bestLastPLT[i], bestCS->prevPLT.curPLTSize[comID] * sizeof(Pel)); } } const CodingUnit& cu = *bestCS->cus.front(); cu.cs->prevPLT = bestCS->prevPLT; // Assert if Best prediction mode is NONE // Selected mode's RD-cost must be not MAX_DOUBLE. CHECK( bestCS->cus.empty() , "No possible encoding found" ); CHECK( bestCS->cus[0]->predMode == NUMBER_OF_PREDICTION_MODES, "No possible encoding found" ); CHECK( bestCS->cost == MAX_DOUBLE , "No possible encoding found" ); }
void EncCu::xCheckModeSplit(CodingStructure *&tempCS, CodingStructure *&bestCS, Partitioner &partitioner, const EncTestMode& encTestMode, const ModeType modeTypeParent, bool &skipInterPass ) { const int qp = encTestMode.qp; const Slice &slice = *tempCS->slice; const int oldPrevQp = tempCS->prevQP[partitioner.chType]; const auto oldMotionLut = tempCS->motionLut; #if ENABLE_QPA_SUB_CTU const PPS &pps = *tempCS->pps; const uint32_t currDepth = partitioner.currDepth; #endif const auto oldPLT = tempCS->prevPLT; const PartSplit split = getPartSplit( encTestMode );//获得cu划分方式 const ModeType modeTypeChild = partitioner.modeType; CHECK( split == CU_DONT_SPLIT, "No proper split provided!" ); tempCS->initStructData( qp );//初始化tempCS m_CABACEstimator->getCtx() = m_CurrCtx->start; const TempCtx ctxStartSP( m_CtxCache, SubCtx( Ctx::SplitFlag, m_CABACEstimator->getCtx() ) ); const TempCtx ctxStartQt( m_CtxCache, SubCtx( Ctx::SplitQtFlag, m_CABACEstimator->getCtx() ) ); const TempCtx ctxStartHv( m_CtxCache, SubCtx( Ctx::SplitHvFlag, m_CABACEstimator->getCtx() ) ); const TempCtx ctxStart12( m_CtxCache, SubCtx( Ctx::Split12Flag, m_CABACEstimator->getCtx() ) ); const TempCtx ctxStartMC( m_CtxCache, SubCtx( Ctx::ModeConsFlag, m_CABACEstimator->getCtx() ) ); m_CABACEstimator->resetBits(); m_CABACEstimator->split_cu_mode( split, *tempCS, partitioner ); m_CABACEstimator->mode_constraint( split, *tempCS, partitioner, modeTypeChild ); const double factor = ( tempCS->currQP[partitioner.chType] > 30 ? 1.1 : 1.075 ); tempCS->useDbCost = m_pcEncCfg->getUseEncDbOpt(); if (!tempCS->useDbCost) CHECK(bestCS->costDbOffset != 0, "error"); const double cost = m_pcRdCost->calcRdCost( uint64_t( m_CABACEstimator->getEstFracBits() + ( ( bestCS->fracBits ) / factor ) ), Distortion( bestCS->dist / factor ) ) + bestCS->costDbOffset / factor; m_CABACEstimator->getCtx() = SubCtx( Ctx::SplitFlag, ctxStartSP ); m_CABACEstimator->getCtx() = SubCtx( Ctx::SplitQtFlag, ctxStartQt ); m_CABACEstimator->getCtx() = SubCtx( Ctx::SplitHvFlag, ctxStartHv ); m_CABACEstimator->getCtx() = SubCtx( Ctx::Split12Flag, ctxStart12 ); m_CABACEstimator->getCtx() = SubCtx( Ctx::ModeConsFlag, ctxStartMC ); //停止划分,具体原因不清楚 if (cost > bestCS->cost + bestCS->costDbOffset #if ENABLE_QPA_SUB_CTU || (m_pcEncCfg->getUsePerceptQPA() && !m_pcEncCfg->getUseRateCtrl() && pps.getUseDQP() && (slice.getCuQpDeltaSubdiv() > 0) && (split == CU_HORZ_SPLIT || split == CU_VERT_SPLIT) && (currDepth == 0)) // force quad-split or no split at CTU level在CTU级别强制四叉树分割或不分割 #endif ) { xCheckBestMode( tempCS, bestCS, partitioner, encTestMode ); return; } const bool chromaNotSplit = modeTypeParent == MODE_TYPE_ALL && modeTypeChild == MODE_TYPE_INTRA ? true : false; if( partitioner.treeType != TREE_D ) { tempCS->treeType = TREE_L; } else { if( chromaNotSplit ) { CHECK( partitioner.chType != CHANNEL_TYPE_LUMA, "chType must be luma" ); tempCS->treeType = partitioner.treeType = TREE_L; } else { tempCS->treeType = partitioner.treeType = TREE_D; } } partitioner.splitCurrArea( split, *tempCS );//进行划分,计算划分子块区域以及坐上坐标 bool qgEnableChildren = partitioner.currQgEnable(); // QG possible at children level m_CurrCtx++; tempCS->getRecoBuf().fill( 0 ); tempCS->getPredBuf().fill(0); AffineMVInfo tmpMVInfo; bool isAffMVInfoSaved; m_pcInterSearch->savePrevAffMVInfo(0, tmpMVInfo, isAffMVInfoSaved); BlkUniMvInfo tmpUniMvInfo; bool isUniMvInfoSaved = false; if (!tempCS->slice->isIntra()) { m_pcInterSearch->savePrevUniMvInfo(tempCS->area.Y(), tmpUniMvInfo, isUniMvInfoSaved); } do { const auto &subCUArea = partitioner.currArea();//划分后的子块区域 if( tempCS->picture->Y().contains( subCUArea.lumaPos() ) ) { const unsigned wIdx = gp_sizeIdxInfo->idxFrom( subCUArea.lwidth () ); const unsigned hIdx = gp_sizeIdxInfo->idxFrom( subCUArea.lheight() ); CodingStructure *tempSubCS = m_pTempCS[wIdx][hIdx]; CodingStructure *bestSubCS = m_pBestCS[wIdx][hIdx]; tempCS->initSubStructure( *tempSubCS, partitioner.chType, subCUArea, false );//子块cu初始化 tempCS->initSubStructure( *bestSubCS, partitioner.chType, subCUArea, false ); tempSubCS->bestParent = bestSubCS->bestParent = bestCS; double newMaxCostAllowed = isLuma(partitioner.chType) ? std::min(encTestMode.maxCostAllowed, bestCS->cost - m_pcRdCost->calcRdCost(tempCS->fracBits, tempCS->dist)) : MAX_DOUBLE; newMaxCostAllowed = std::max(0.0, newMaxCostAllowed); xCompressCU(tempSubCS, bestSubCS, partitioner, newMaxCostAllowed);//递归调用 tempSubCS->bestParent = bestSubCS->bestParent = nullptr; if( bestSubCS->cost == MAX_DOUBLE ) { CHECK( split == CU_QUAD_SPLIT, "Split decision reusing cannot skip quad split" ); tempCS->cost = MAX_DOUBLE; tempCS->costDbOffset = 0; tempCS->useDbCost = m_pcEncCfg->getUseEncDbOpt(); m_CurrCtx--; partitioner.exitCurrSplit(); xCheckBestMode( tempCS, bestCS, partitioner, encTestMode ); if( partitioner.chType == CHANNEL_TYPE_LUMA ) { tempCS->motionLut = oldMotionLut; } return; } bool keepResi = KEEP_PRED_AND_RESI_SIGNALS; tempCS->useSubStructure( *bestSubCS, partitioner.chType, CS::getArea( *tempCS, subCUArea, partitioner.chType ), KEEP_PRED_AND_RESI_SIGNALS, true, keepResi, keepResi ); //从子结构中复制编码数据,将bestSubCS的cu,pu,tu复制到tempCS中 if( partitioner.currQgEnable() ) { tempCS->prevQP[partitioner.chType] = bestSubCS->prevQP[partitioner.chType]; } if( partitioner.isConsInter() ) { for( int i = 0; i < bestSubCS->cus.size(); i++ ) { CHECK( bestSubCS->cus[i]->predMode != MODE_INTER, "all CUs must be inter mode in an Inter coding region (SCIPU)" ); } } else if( partitioner.isConsIntra() ) { for( int i = 0; i < bestSubCS->cus.size(); i++ ) { CHECK( bestSubCS->cus[i]->predMode == MODE_INTER, "all CUs must not be inter mode in an Intra coding region (SCIPU)" ); } } tempSubCS->releaseIntermediateData();//清空子节点数据 bestSubCS->releaseIntermediateData(); if( !tempCS->slice->isIntra() && partitioner.isConsIntra() ) { tempCS->cost = m_pcRdCost->calcRdCost( tempCS->fracBits, tempCS->dist ); if( tempCS->cost > bestCS->cost ) { tempCS->cost = MAX_DOUBLE; tempCS->costDbOffset = 0; tempCS->useDbCost = m_pcEncCfg->getUseEncDbOpt(); m_CurrCtx--; partitioner.exitCurrSplit(); if( partitioner.chType == CHANNEL_TYPE_LUMA ) { tempCS->motionLut = oldMotionLut; } return; } } } } while( partitioner.nextPart( *tempCS ) );//进行下一个子块的划分 partitioner.exitCurrSplit();//清除m_partStack栈顶,将深度减一 m_CurrCtx--; if( chromaNotSplit ) { //Note: In local dual tree region, the chroma CU refers to the central luma CU's QP. //If the luma CU QP shall be predQP (no residual in it and before it in the QG), it must be revised to predQP before encoding the chroma CU //Otherwise, the chroma CU uses predQP+deltaQP in encoding but is decoded as using predQP, thus causing encoder-decoded mismatch on chroma qp. if( tempCS->pps->getUseDQP() ) { //find parent CS that including all coded CUs in the QG before this node CodingStructure* qgCS = tempCS; bool deltaQpCodedBeforeThisNode = false; if( partitioner.currArea().lumaPos() != partitioner.currQgPos ) { int numParentNodeToQgCS = 0; while( qgCS->area.lumaPos() != partitioner.currQgPos ) { CHECK( qgCS->parent == nullptr, "parent of qgCS shall exsit" ); qgCS = qgCS->parent; numParentNodeToQgCS++; } //check whether deltaQP has been coded (in luma CU or luma&chroma CU) before this node CodingStructure* parentCS = tempCS->parent; for( int i = 0; i < numParentNodeToQgCS; i++ ) { //checking each parent CHECK( parentCS == nullptr, "parentCS shall exsit" ); for( const auto &cu : parentCS->cus ) { if( cu->rootCbf && !isChroma( cu->chType ) ) { deltaQpCodedBeforeThisNode = true; break; } } parentCS = parentCS->parent; } } //revise luma CU qp before the first luma CU with residual in the SCIPU to predQP if( !deltaQpCodedBeforeThisNode ) { //get pred QP of the QG const CodingUnit* cuFirst = qgCS->getCU( CHANNEL_TYPE_LUMA ); CHECK( cuFirst->lumaPos() != partitioner.currQgPos, "First cu of the Qg is wrong" ); int predQp = CU::predictQP( *cuFirst, qgCS->prevQP[CHANNEL_TYPE_LUMA] ); //revise to predQP int firstCuHasResidual = (int)tempCS->cus.size(); for( int i = 0; i < tempCS->cus.size(); i++ ) { if( tempCS->cus[i]->rootCbf ) { firstCuHasResidual = i; break; } } for( int i = 0; i < firstCuHasResidual; i++ ) { tempCS->cus[i]->qp = predQp; } } } assert( tempCS->treeType == TREE_L ); uint32_t numCuPuTu[6]; tempCS->picture->cs->getNumCuPuTuOffset( numCuPuTu ); tempCS->picture->cs->useSubStructure( *tempCS, partitioner.chType, CS::getArea( *tempCS, partitioner.currArea(), partitioner.chType ), false, true, false, false ); #if JVET_Q0438_MONOCHROME_BUGFIXES if (isChromaEnabled(tempCS->pcv->chrFormat)) { #endif partitioner.chType = CHANNEL_TYPE_CHROMA; tempCS->treeType = partitioner.treeType = TREE_C; m_CurrCtx++; const unsigned wIdx = gp_sizeIdxInfo->idxFrom( partitioner.currArea().lwidth() ); const unsigned hIdx = gp_sizeIdxInfo->idxFrom( partitioner.currArea().lheight() ); CodingStructure *tempCSChroma = m_pTempCS2[wIdx][hIdx]; CodingStructure *bestCSChroma = m_pBestCS2[wIdx][hIdx]; tempCS->initSubStructure( *tempCSChroma, partitioner.chType, partitioner.currArea(), false ); tempCS->initSubStructure( *bestCSChroma, partitioner.chType, partitioner.currArea(), false ); tempCS->treeType = TREE_D; xCompressCU( tempCSChroma, bestCSChroma, partitioner ); //attach chromaCS to luma CS and update cost bool keepResi = KEEP_PRED_AND_RESI_SIGNALS; //bestCSChroma->treeType = tempCSChroma->treeType = TREE_C; CHECK( bestCSChroma->treeType != TREE_C || tempCSChroma->treeType != TREE_C, "wrong treeType for chroma CS" ); tempCS->useSubStructure( *bestCSChroma, partitioner.chType, CS::getArea( *bestCSChroma, partitioner.currArea(), partitioner.chType ), KEEP_PRED_AND_RESI_SIGNALS, true, keepResi, true ); //release tmp resource tempCSChroma->releaseIntermediateData(); bestCSChroma->releaseIntermediateData(); //tempCS->picture->cs->releaseIntermediateData(); #if JVET_Q0438_MONOCHROME_BUGFIXES m_CurrCtx--; } #endif tempCS->picture->cs->clearCuPuTuIdxMap( partitioner.currArea(), numCuPuTu[0], numCuPuTu[1], numCuPuTu[2], numCuPuTu + 3 ); #if !JVET_Q0438_MONOCHROME_BUGFIXES m_CurrCtx--; #endif //recover luma tree status partitioner.chType = CHANNEL_TYPE_LUMA; partitioner.treeType = TREE_D; partitioner.modeType = MODE_TYPE_ALL; } // Finally, generate split-signaling bits for RD-cost check const PartSplit implicitSplit = partitioner.getImplicitSplit( *tempCS ); { bool enforceQT = implicitSplit == CU_QUAD_SPLIT; // LARGE CTU bug if( m_pcEncCfg->getUseFastLCTU() ) { unsigned minDepth = 0; unsigned maxDepth = floorLog2(tempCS->sps->getCTUSize()) - floorLog2(tempCS->sps->getMinQTSize(slice.getSliceType(), partitioner.chType)); if( auto ad = dynamic_cast<AdaptiveDepthPartitioner*>( &partitioner ) ) { ad->setMaxMinDepth( minDepth, maxDepth, *tempCS ); } if( minDepth > partitioner.currQtDepth ) { // enforce QT enforceQT = true; } } if( !enforceQT ) { m_CABACEstimator->resetBits(); m_CABACEstimator->split_cu_mode( split, *tempCS, partitioner ); partitioner.modeType = modeTypeParent; m_CABACEstimator->mode_constraint( split, *tempCS, partitioner, modeTypeChild ); tempCS->fracBits += m_CABACEstimator->getEstFracBits(); // split bits加上划分的bit } } tempCS->cost = m_pcRdCost->calcRdCost( tempCS->fracBits, tempCS->dist );//计算当前划分模式总的代价 // Check Delta QP bits for splitted structure if( !qgEnableChildren ) // check at deepest QG level only xCheckDQP( *tempCS, partitioner, true ); // If the configuration being tested exceeds the maximum number of bytes for a slice / slice-segment, then // a proper RD evaluation cannot be performed. Therefore, termination of the // slice/slice-segment must be made prior to this CTU. // This can be achieved by forcing the decision to be that of the rpcTempCU. // The exception is each slice / slice-segment must have at least one CTU. if (bestCS->cost != MAX_DOUBLE) { } else { bestCS->costDbOffset = 0; } tempCS->useDbCost = m_pcEncCfg->getUseEncDbOpt(); if( tempCS->cus.size() > 0 && modeTypeParent == MODE_TYPE_ALL && modeTypeChild == MODE_TYPE_INTER ) { int areaSizeNoResiCu = 0; for( int k = 0; k < tempCS->cus.size(); k++ ) { areaSizeNoResiCu += (tempCS->cus[k]->rootCbf == false) ? tempCS->cus[k]->lumaSize().area() : 0; } if( areaSizeNoResiCu >= (tempCS->area.lumaSize().area() >> 1) ) { skipInterPass = true; } } // RD check for sub partitioned coding structure. xCheckBestMode( tempCS, bestCS, partitioner, encTestMode );//比较当前划分方式与之前划分方式,然后选择代价较小的 if (isAffMVInfoSaved) m_pcInterSearch->addAffMVInfo(tmpMVInfo); if (!tempCS->slice->isIntra() && isUniMvInfoSaved) { m_pcInterSearch->addUniMvInfo(tmpUniMvInfo); } tempCS->motionLut = oldMotionLut; tempCS->prevPLT = oldPLT; tempCS->releaseIntermediateData(); tempCS->prevQP[partitioner.chType] = oldPrevQp; }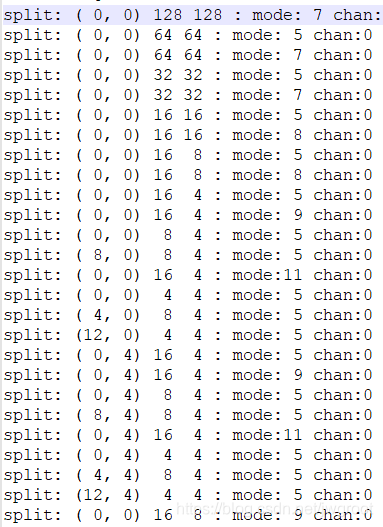
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 1372
1372