爬了个网站,结果发现该网站图片不好看,于是看程序员如何制作DIY表情包? 前提: 本篇博客涵盖scrapy知识点过多,需要一定基础,理解不了的可以留言, 同时还包含一个gif’制作库的使用,剩下的模块我觉得挺简单的! 其实爬虫一直爬取图片挺没意思的,单纯满足自我私欲之外,然后我就想搞点其他的,于是想到了可以爬图片制作表情包这样的想法,加上最近学了scrapy框架的知识, 正好一起使用上来,加快了爬虫的效率,以及制作图片的资源快捷性! 博客分为三大块,按照自我需求寻找思路, 觉得不错的还是点个关注和赞吧,创作不易,没动力哎。 本次使用scrapy框架爬取一个小网站, 挺担心这个网站的! first_url: https://www.52doutu.cn/post/1/ 从中点开任意一个查看全部,网址规模都是一样的:https://www.52doutu.cn/p/99/ 具体网站具体分析,不是所有网站都是傻逼网站那么简单爬取。 爬虫程序 管道 这里实现了图片分类的功能: 然后我们在运行程序:之后得到的效果图如下: 制作表情包的函数库刚开始选择二种; 最后将这个函数功能封装了下: path = r’D:pythscrapy 项目joke_image表情包’ 类似这样的 刚好我也是写了个爬虫 制作了表情包, 如果想用自己的图片制作表情包,这个函数也是可以的。动手试试吧! 总结到一个问题,学的越多,越难的很细节描述一个事物,角度不同吧,我感觉这个很简单,可能对于小白说,这个很难理解,没别的说。 喜欢就个关注和,支持支持!!

效果图如上:
前言:
分析网站:
也就是p后面的数值不一样, 这里可以匹配过去。后面代码细讲:之后打开这样的页面: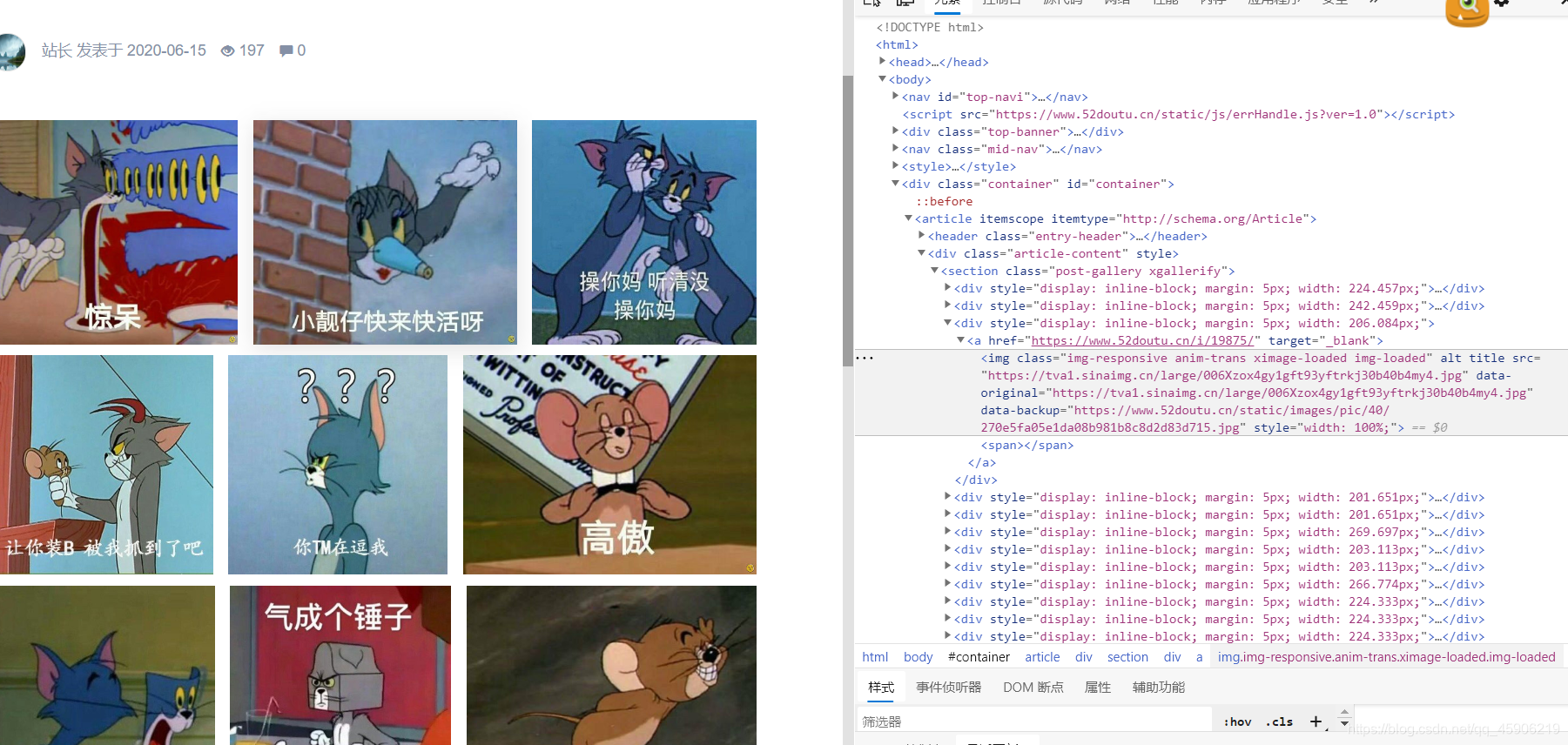
打开页面源代码,从这里获取,图片url。
编写代码:
编写spider:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from joke_image.items import JokeImageItem import time class JokeImgSpiderSpider(CrawlSpider): name = 'joke_img_spider' allowed_domains = ['52doutu.cn'] start_urls = ['https://www.52doutu.cn/post/1/'] rules = ( Rule(LinkExtractor(allow=r'.*www.52doutu.cn/post/d+/'), follow=True), Rule(LinkExtractor(allow=r'.*www.52doutu.cn/p/d+/'), callback="parse_img", follow=False) ) def parse_img(self, response): time.sleep(0.2) title = response.xpath('//h1[@class="entry-title"]/text()').get() image_urls = response.xpath('//section[@class="post-gallery"]/div/a/img/@data-original').getall() # image_urls = response.xpath('//div[@class="article-content"]//div/a/img/@data-original').getall() # 获得真实xpath格式 items = JokeImageItem() print(image_urls) items['title'] = title items['image_urls'] = image_urls yield items 编写items:
import scrapy class JokeImageItem(scrapy.Item): image = scrapy.Field() image_urls = scrapy.Field() title = scrapy.Field() 编写pipeline:
IMAGES_STORE 这个是图片仓库, setting自己设置:from joke_image.settings import IMAGES_STORE from scrapy.http import Request from scrapy.pipelines.images import ImagesPipeline class JokeImagePipeline(ImagesPipeline): def get_media_requests(self, item, info): # 不断的请求 , 然后返回, 把items传回 for url in item['image_urls']: yield Request(url, meta={'item': item}) def file_path(self, request, response=None, info=None): title = request.meta['item']['title'] path = IMAGES_STORE + f'\{title}\{request.url.split("/")[-1]}' print(f'保存在:{path}') return path 
制作表情包:
from images2gif import writeGif
import imageio
结果发现 image2gif 存在一个bug 图片只会加载第一张 就闪退
所以重写代码 最后成功:
参数也就是一个path, 存放图片的地方, 给个例子:import imageio import os # 导入制作gif函数库 class MakeImagesMovie(object): """ from class get the images_list return: small gif params: path * images path """ def __init__(self, path): self.path = path self.image_files = [] def get_image(self): for dirpath, dirnames, filenames in os.walk(path): # dirpath 所有目录的路径 包括主目录 和子目录 # dirnames 所有子目录的名称 # filenames 所有文件的名称 # 中转列表 title_img = [os.path.join(dirpath, i) for i in os.listdir(dirpath)] self.image_files.append(title_img) # 构造二维数组 def create_gif(self, image_list, gif_path, duration): frames = [] for image_name in image_list: frames.append(imageio.imread(image_name)) imageio.mimsave(gif_path, frames, 'GIF', duration=duration) return def make_movies(self): self.get_image() for title_img in self.image_files[1:]: # 遍历大列表 # frames = [] # 存放每个文件夹网址的目录 name = title_img[0].split('/')[5][:6] gif_path = f'D:/pyth/scrapy 项目/表情包gif/{name}.gif' self.create_gif(title_img[:10], gif_path, duration=0.25) print(f'成功制作出{name}的gif') 后记:这个真好玩,斗图再也没输过了。

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 376
376