获取豆瓣top250电影信息,包括电影海报链接、详情链接、中/外文名、评分、评价人数、一句话评价等 pip install package-name URL:https://movie.douban.com/top250 https://movie.douban.com/top250?start=i(i for i in range(10)) 伪装请求头,获取目标网页源码网页获取 使用bs4和re库提取网页源码中的目标信息 使用xlwt模块创建操作excel 成功获取数据
python爬虫——爬取豆瓣top250电影信息
环境
非自带包都是使用如下语句安装:实现步骤
对网页进行简单分析发现,一共有10个页,每个页面有25部电影的信息。
各页面的URL构成为构造源码请求函数
import urllib.request, urllib.error import ssl def askURL(url): ''' 用于请求网页源码 ''' #部分网站会根据请求头中的User-Agent内容进行判断,如果是爬虫则限制访问,所以要对请求头进行伪装,模拟浏览器访问,根据需要还可添加其它头部信息 #User-Agent信息可以用Chrome打开网页,按F12打开Web检查器,在Network栏目下的Headers中可找到 head = {} head["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36" request = urllib.request.Request(url, headers = head) html = "" #用于接收网页的源码信息 context = ssl._create_unverified_context() ''' 当使用urllib打开https的链接时,会检验一次ssl证书. 而当目标网站使用的是自签名证书时,就会抛出urllib2.URLError的错误. 解决办法一:ssl._create_default_https_context = ssl._create_unverified_context 全局取消证书验证 解决办法二:创建未验证的上下文,在url中传入上下文参数 context = ssl._create_unverified_context() ''' try: response = urllib.request.urlopen(request, context= context) html = response.read().decode() #read()函数获取到的是bytes类型的数据,decode()用于将其解码 except urllib.error.HTTPError as e: if hasattr(e, "code"): #hasattr()判断一个对象是否含有某种属性 print(e.code) #code 为http状态码 if hasattr(e, "reason"): print(e.reason) #错误原因 return html 获取目标数据
可以看到想要获取的信息在一个div class="item标签中

from bs4 import BeautifulSoup #网页解析,获取数据 import re #正则模块,提取信息 #创建正则表达式,获取对应信息 #影片详情连接 findLink = re.compile(r'<a href="(.*?)">') #影片图片连接 findimgSrc = re.compile(r'src="(.*?)"', re.S) #re.S 忽略换行符 #影片片名 findTitle = re.compile(r'<span class="title">(.*?)</span>') #影片评分 findRating = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') #评价人数 findJudge = re.compile(r'<span>(d*)人评价</span>') #一句话评价 findInq = re.compile(r'<span class="inq">(.*?)</span>') #影片相关内容 findBd = re.compile(r'<p class="">(.*?)</p>', re.S) def getData(baseurl): datalist = [] for i in range(10): url = baseurl + str(i*25) html = askURL(url) #保存获取到的网页源码 #解析数据 #BeautifulSoup4将复杂文档转换成一个复杂的树形结构,便于获取指定内容,需指定目标数据和和解析器 soup = BeautifulSoup(html, "html.parser") for item in soup.find_all("div", class_ = "item"): #查找符合要求的所有字符串形成列表,类似于css选择器 # print(item) #测试查看电影item信息是否获取到 data = [] #保存一部电影的全部信息 item = str(item) #item是bs4.element.Tag类型的,需要转换成字符串类型,便于使用正则提取信息 link = re.findall(findLink, item)[0] #根据findLink匹配item中的字段,并返回匹配信息,如r'<a href="(.*?)">'中(.*?)就是所匹配到的信息,r表示忽略转义等特殊字符作为普通字符处理 data.append(link) imgSrc = re.findall(findimgSrc, item)[0] data.append(imgSrc) title = re.findall(findTitle, item) if len(title) >= 2: data.append(title[0]) data.append(re.sub(r'xa0', '', title[1].replace("/", ""))) else: data.append(title[0]) data.append(' ') rating = re.findall(findRating, item)[0] data.append(rating) judge = re.findall(findJudge, item)[0] data.append(judge) inq = re.findall(findInq, item) if len(inq) != 0: inq = re.sub(r'xa0', '', inq[0]) data.append(inq.replace("。", "")) else: data.append(' ') bd = re.findall(findBd, item)[0] bd = re.sub('...<br(.*?)>', ' ', bd) bd = re.sub(r'/', ' ', bd) bd = re.sub(r'xa0', ' ', bd) data.append(re.sub(r'n ', '', bd).strip()) # print(data, end='') datalist.append(data) return datalist 保存数据到excel
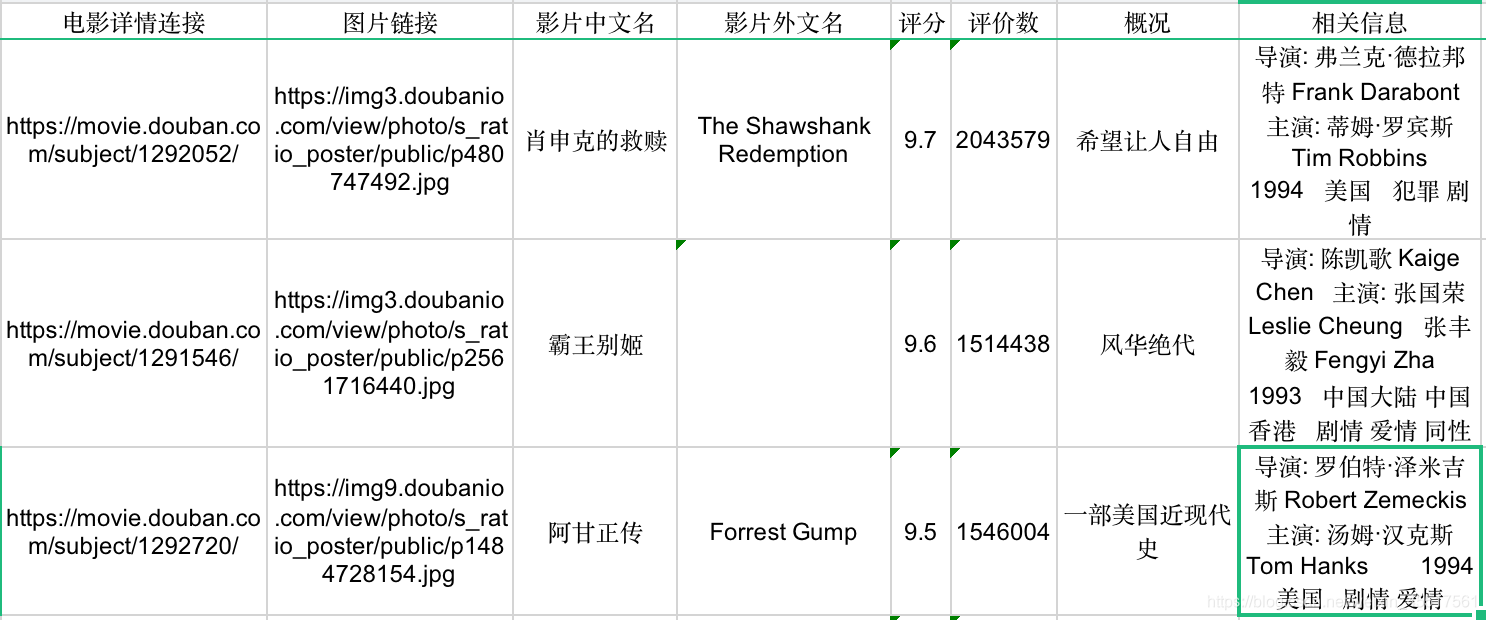
import xlwt def savaData(data, path): workbook = xlwt.Workbook(encoding="utf-8") #实例化一个工作区,相当于构建一个框架 worksheet = workbook.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表,cell_overwrite_ok=True 表示可以对单元格进行重设值 col = ('电影详情连接', '图片链接', '影片中文名', '影片外文名', '评分', '评价数', '概况', '相关信息') for i in range(8): worksheet.write(0, i, col[i]) #第一个参数表示行,第二个参数为列,第三个参数为要写入的内容,行列都是从0开始 for i in range(250): for j in range(8): worksheet.write(i+1, j, data[i][j]) #写入数据 print('第%d条'%i) workbook.save(path) #保存 测试
baseurl = 'https://movie.douban.com/top250?start=' datalist = getData(baseurl) savePath = '豆瓣电影Top250.xls' savaData(datalist, savePath)
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 1万+
1万+