我想大家对于爬虫也都多多少的都有点了解了。 那么这次还是使用大家熟悉的requests的 我们首先获取一个视频网站的网址。 返回结果是200说明就是OK了。 那么下边需要获取我们的热点内容。 标红的内容我们一般都可以用到。 我们把需要的这一些内容获取,打印到我们控制台上。 这样,我们第一次使用python爬虫,爬取文本信息就完了。 后期会有其他方法更新,关注一波呗
那么大家肯定想着爬取一些热点视频。import requests response = requests.get('https://haokan.baidu.com') print(response.status_code)


获取到这个内容,感觉就是json格式内存储的数据。
一层一层打开这个内容我们可以获取到关于视频信息的所有内容。
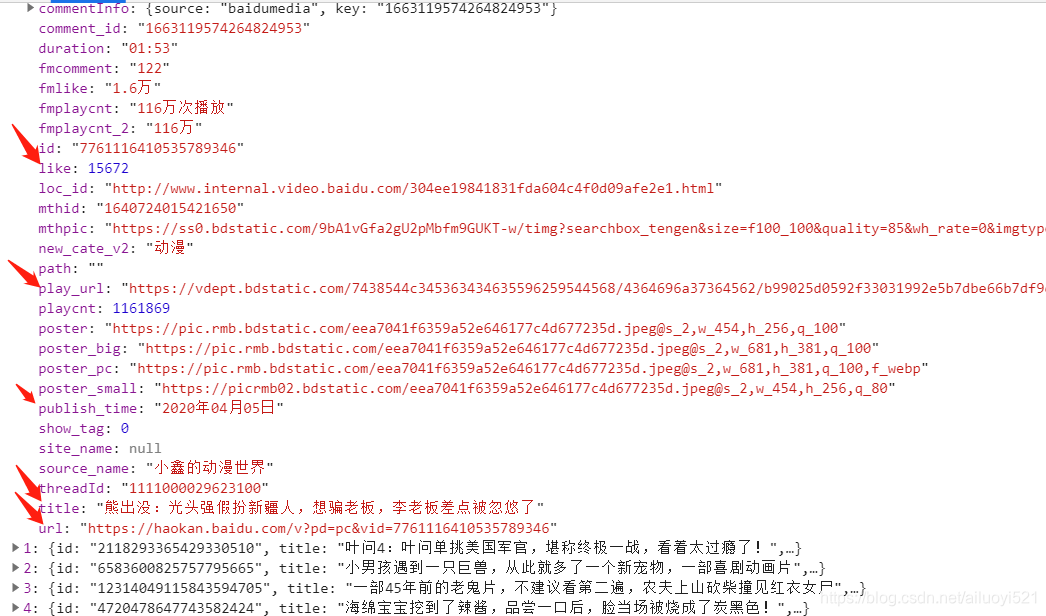

for data1 in data_list: print(data1['title']) print(data1['url']) print(data1['source_name']) 
获取到相应的内容之后,我们要获取并下载相应的视频内容。# 保存数据 with open('视频\'+title , mode='wb') as f: f.write(video_data) print('下载完成'+title) 
全部内容 import requests for page in range(5): url = 'https://haokan.baidu.com/videoui/api/videorec?tab=yingshi&act=pcFeed&pd=pc&num=5&shuaxin_id=1592446397525' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36", 'cookie': 'BDUSS=EJHUHRMNXJ2cHBHZ1NxUXZXbXBOOTFKeFhhNTdCWHA1ZHhoUDhnRjZkV0dDUDllRVFBQUFBJCQAAAAAAAAAAAEAAADieE~XSm9nZXJwb3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIZ7116Ge9deR; BAIDUID=1596023C0E05A89A1BE381DC5C6907FB:FG=1; PSTM=1591578635; BIDUPSID=6FE8C8F7A7FA3654639829B4FDAFB95F; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; H_PS_PSSID=32098_1424_31672_21112_31069_32045_30824_26350_22158; COMMON_LID=d57c922a028d4ed6aaca2ba48d1fbca7; hkpcSearch=%u5C0F%u56E2%u56E2%u8DF3%u821E; Hm_lvt_4aadd610dfd2f5972f1efee2653a2bc5=1592443452,1592444549,1592446398,1592447044; reptileData=%7B%22data%22%3A%22dd052797cc791d037fd5f827d14a9cb65b5eb2dc0fceb967a9da60661054067558aa7618f896edbee8e84ecb15b2c61db40e465f29b0007bbb17ee2ff6a0b7ed516afb8c00cc9cc0e33a29df53d6781334f714cc58c54409caa347a4b7923c587dcfc989ebbaa062a0e292cf4c86168576fa5656b4d4104f121d7d9153cb4c37%22%2C%22key_id%22%3A%2230%22%2C%22sign%22%3A%22ab21b029%22%7D; Hm_lpvt_4aadd610dfd2f5972f1efee2653a2bc5=1592447120; PC_TAB_LOG=haokan_website_page'} response = requests.get(url, headers=headers) data = response.json() data_list = data['data']['response']['videos'] # 遍历列表 for data1 in data_list: title = data1['title'] + '.mp4' url = data1['play_url'] # 发送数据请求 print('正在下载视频:', title) video_data = response.content # 保存数据 with open('小说\' + title, mode='wb') as f: f.write(video_data) print('下载完成' + title) 能跑得动的,记得点个赞呗。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 4455
4455