这里是笔者对数模竞赛的一些内心bb,看思路的可以直接跳过。 笔者这里做的是B题,所以只说一下B题。(顺便今年的五一杯难度比去年降低了好多,可能是因为组委会考虑疫情团队沟通问题,但对于笔者一个人做题的人来说,毫无影响:)。这题加上写论文一共就花了一天时间,当然笔者的写论文水平太次,被我的老师一顿臭骂。但是模型没啥问题,各位放心) 这里问的是决策方案的差异,这里首先将 但是明显这两个方法不够“高端”,在这种小比赛里可能会比较吃亏,因为评委就喜欢一些看上去特别厉害的方法。这里笔者想到了差异显著性评判 ,这是笔者在看2012年的国赛题“葡萄酒的评价问题”优秀范文学到的方法(所以数模还是要多看论文,总能发现一些奇奇怪怪的方法,虽然都不是特别懂,但不妨碍我用它),感觉和这个资产配置属性差异差不多。 1、什么是统计假设检验? “无假设,不检验”。首先我们假设公司的资产配置策略不存在显著性差异,在显著性水平 这道题我们略过,我觉得在已知历史数据的情况下找最优就是扯淡,找增长率最大的不就得了,没啥意义。随便建了一个半页的模型,被老师骂了一顿,这里就不提了。 2020年所有基金公司仍然按照 2019 年的资产配置策略进行投资,度量每个基金公司 2020年95%置信水平下的风险价值。度量公司的风险价值就是度量每支股票的风险价值。我们需要预测未来股票价格的走势,常用的方法有蒙特卡洛模拟法。 题目要求既能保证投资效用 对于双目标求解问题,笔者一般采用的方法是将两个指标抽象为二维空间上的点 其实D题这题目没啥可说的,预测类问题已经出烂了,感觉流程和方法已经完全标准化了,没啥发挥的余地。其实我不是很明白预测类问题在数学建模里面出现的那么频繁,如果是传统的时间序列那精度非常感人,机器学习在精度上暴打传统时间序列,但如果用机器学习,那我感觉失去了数学建模的意义。每次看到一些论文用到什么神经网络我感觉这论文就没啥意义,这玩意儿极度黑箱,只能出一个结果,每个特征的重要性完全无法分析,而且就凭寻常数学建模的一万左右的数据量,用神经网络实在不是一个很好的方法,数据量太小了,而且每次调参真的是折磨,对生理和心理的耐心双重考验,调不好参数精度照样感人。 如果非要用机器学习,我就建议使用决策树,既能分析特征重要性,不需要调参就能得到足够精确的结果,且数学理论也足够丰富。我就是采用了决策树的强化版 现在几所高校被美国制裁了无法使用
前言
数模是一个很好的竞赛,我个人认为挺锻炼人的。但是有不少人是抱着加分的心态在参加数模,像mathorcup、中青杯这种小比赛在笔者的学校算作是国家级比赛,加分和国赛美赛是同一水平,但是获奖难度确是低了数倍,一等奖直接在综测加4分,二等奖加2分,相当于智育成绩高了6.6分,我觉得这是对不参加此类竞赛的同学极度的不公平,因为这种比赛的二等奖本身就不是什么特别困难的事情。
笔者自己所在的院系有着相当激烈的竞争氛围,但我不认为这是一件什么好事情,大家总是在各种奇奇怪怪的地方争取综测加分,我听说了各种买论文、买专利等为了加分的举动(相比这些行为水数模竞赛还算可以接受的事情,毕竟是自己的努力拿到的)。笔者的一个朋友在期末算综测的时候总是特别沮丧,他没参加竞赛,他成绩特别好,但是相比那些“水综测”的人,他没法拿到一等奖。出于对朋友的同情,也有对水加分这一行为的厌恶,笔者在mathorcup报名的最后一天将名字划去,参加比赛只为提高自己,不为加分。
我还是希望参加数模的人是真正想要去学习技能提升自己的人参加,与其参加了一大堆比赛,不如就好好参加一两个,好好复盘,对自己更有益处。也希望院系的风气能趋于正常,不为无意义的排名干那些没有意义的事情。五一杯
第一问
家公司的
支股票的选择转换为
的矩阵:
其中
代表第
家公司在第
支股票的投资金额。
我们可以将
的每一行作为公司的资产配置属性,比较向量之间的差异作为公司的决策差异。比较向量之间的差异的方法有很多,比如常用的欧式距离或者余弦距离。
所谓统计假设检验就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设是否合理。而把只限定第一类错误概率的统计假设检验就称之为显著性检验。
在上例中,我们的假设就是一种显著性检验。因为方差检验不适用于估计参数和估计总体分布,而是用于检验试验的两个组间是否有差异。而方差检验正是用于检测我们所关心的是这两个集合(两个分布)的均值是否存在差异。
2、为什么要做显著性检验?
因为我们想要判断样本与我们对总体所做的假设之间的差异是纯属机会变异,还是由我们所做的假设与总体真实情况之间不一致所引起的。 在我们的例子中,差异就是H的均值要高于Z的均值,但是最终的结论p>0.05证明,这个差异纯属机会变异(H均值>Z均值是偶然的,当H和Z的采样点数趋于无穷多时,H的均值会趋近等于Z的均值)而不是假设与真实情况不一致。如果p值<0.05,那么也就意味着我们的假设(H集合和Z集合没差别)与真实情况不一致,这就使得假设不成立,即H集合和Z集合有差别。
的情况下,
接受原假设,
拒绝原假设。
表示第i个总体的样本均值,则
其中,
为第
个总体的样本观察值个数。
,则
式中,
。
。它是各组平均值
与总平均值
的误差平方和,反映了 各水平总体的样本均值之间的差异程度,因此又称为组间平方和。
。它是每个水平或各组的各样本数据与其组平均值误差的平方和,反映了每个样本各观察值的离散状况,因此又称为组内平方和或残差平方和。
。
是
与
的比值。
最后的结果我用了一张热力图表示:
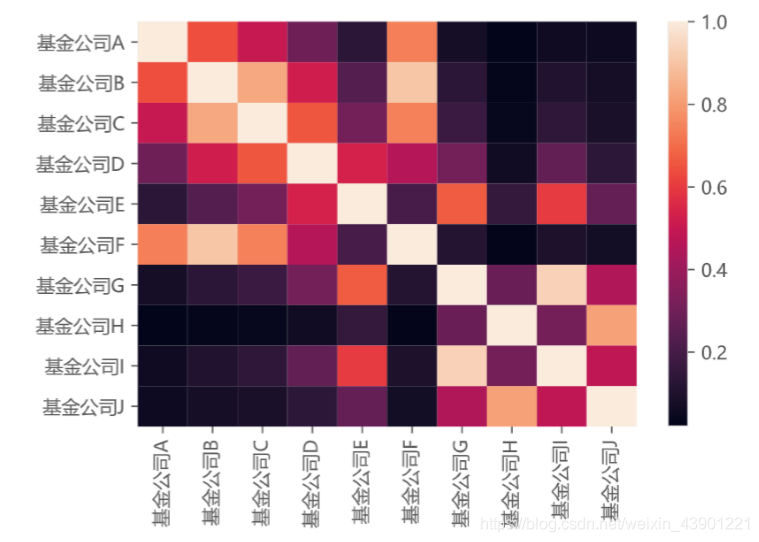
颜色越深说明两家公司的显著性差异越大,颜色越浅说明两家公司的显著性差异越小。第二问
第三问
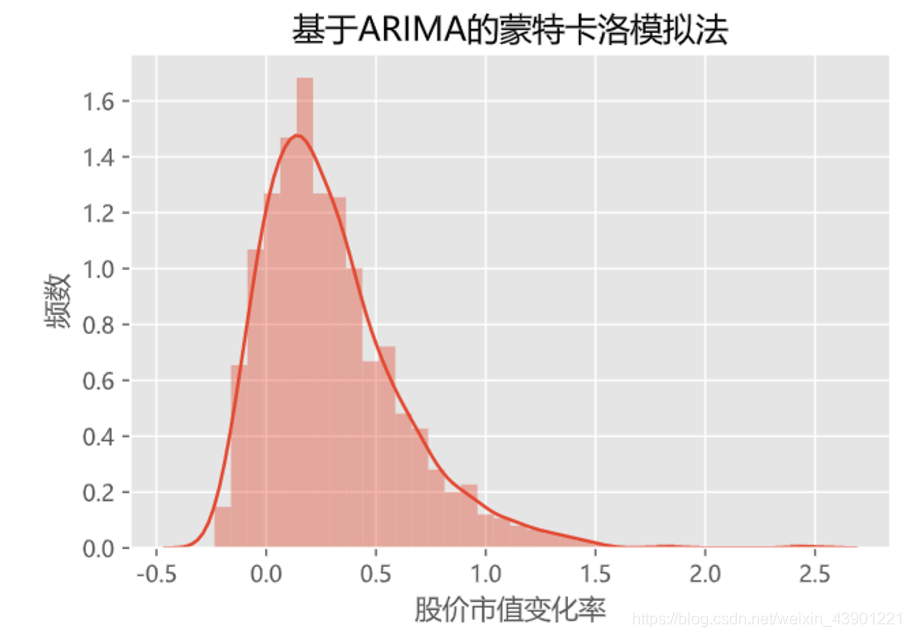
但是蒙特卡洛使用的准则是随机几何布朗运动法,同样离不开一个字,“low”。我们要让它高端起来,所以我们改变它的模拟方法,使用其它时间序列的方法来代替随机几何运动。这里笔者采用的是
时间序列对蒙特卡洛模拟法进行优化,使用不同的
、
值进行1000 次的模拟,如此得到的数据走势更具科学性,而 不是单单的随机运动。 公式这里就不列了,网上都有(主要是打公式太麻烦)。
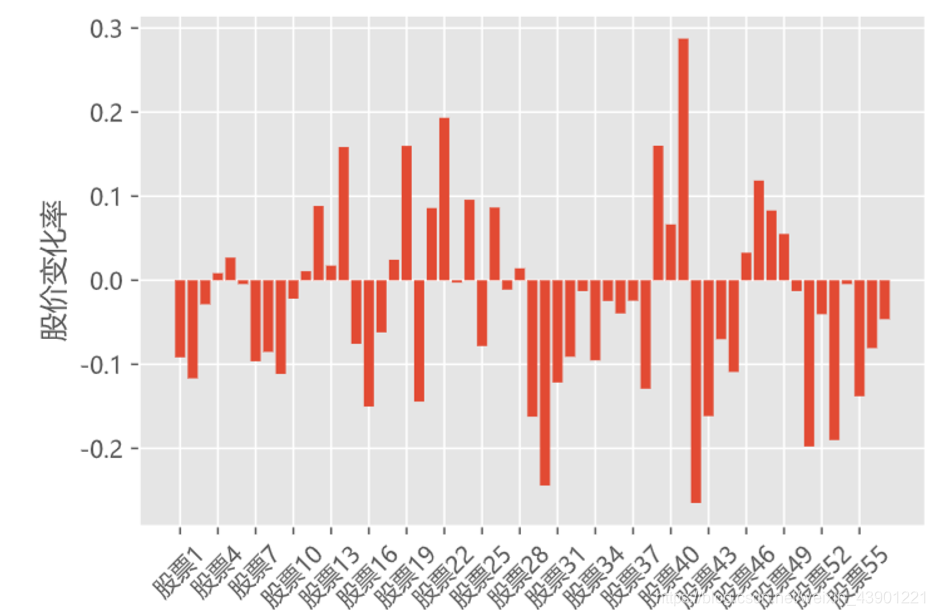
第四问
最大化,同时又能使风险价值
最低,选择最优的股票投资组合策略。
。因
为风险价值和增长率量纲不同,我们要对它们进行标准化处理:
求
到原点的距离
,距离越近说明风险价值越小,投资增长率越大:
稳健的投资者不会将钱全部买入一支股票,所以我们为了简化模型,我们决定
投资n支股票,每支股票的投资金额一致。
此问题的决策变量可以定义为:
所以模型的目标函数为:
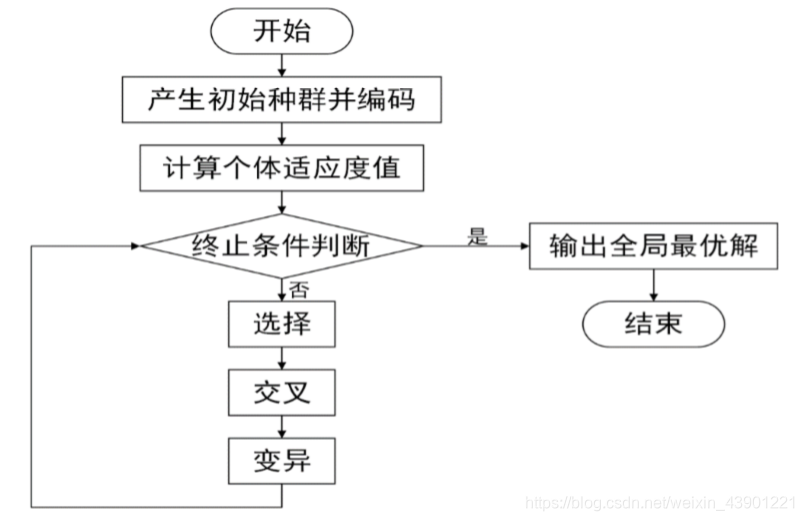
由此问题转化为0-1规划问题,求解还是很轻松的,lingo、暴力求解、智能算法都可以很轻松求解。笔者用的遗传算法,这里就不多阐述了,网上也有一大堆资料。
mathorcup
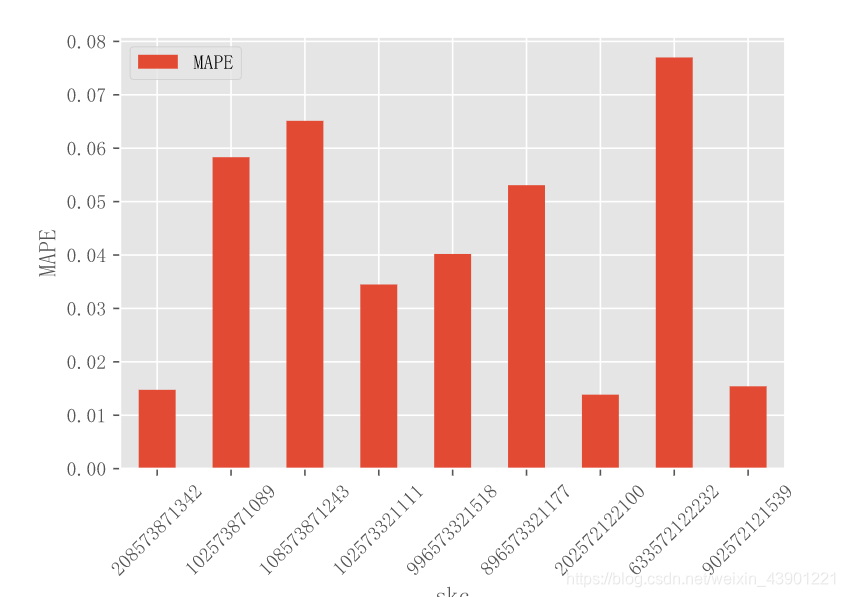
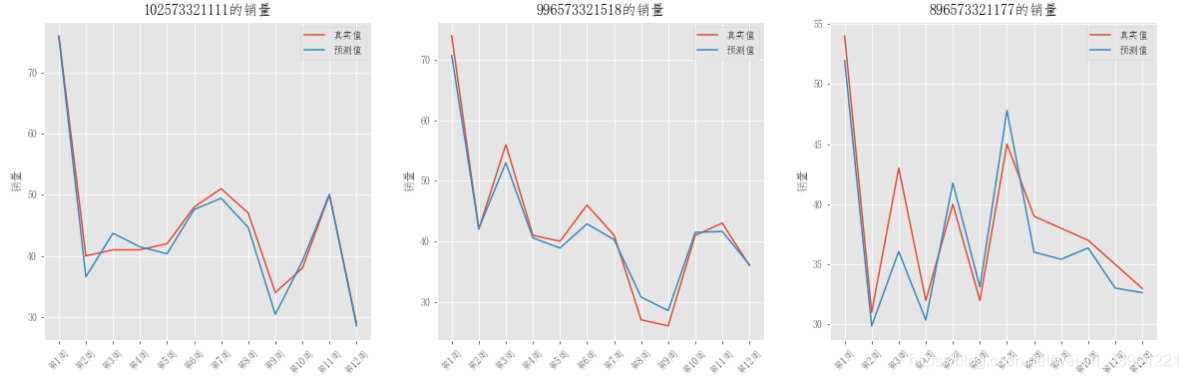
(梯度提升树)来做的,过程就不阐述了,机器学习实在没啥想说的,精度还不错,
在
左右。
后记
,当然笔者所在的渣渣学校是不可能被美国看上的。但是向开源软件靠近是大势所趋,这次我尝试比赛全程不使用
,全用
,当然也是和我选择的题目有关,我都是选择的数据分析类题目,一是这类题目我很熟悉,二是我真的不会用python解方程和线性规划=。=
05-25  2797
2797
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









