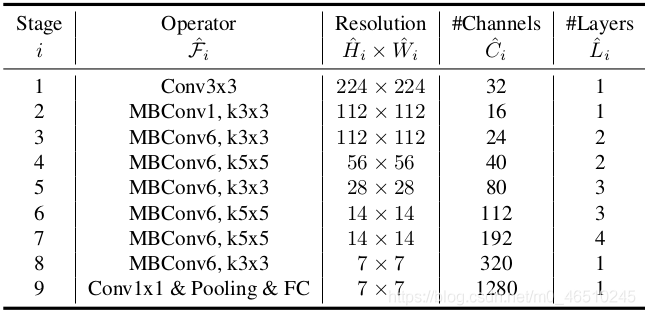
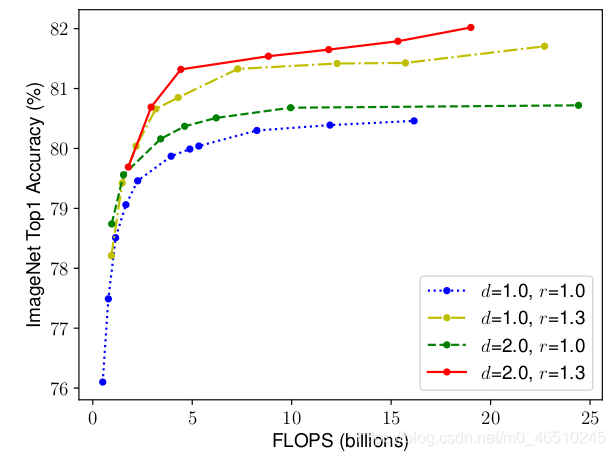
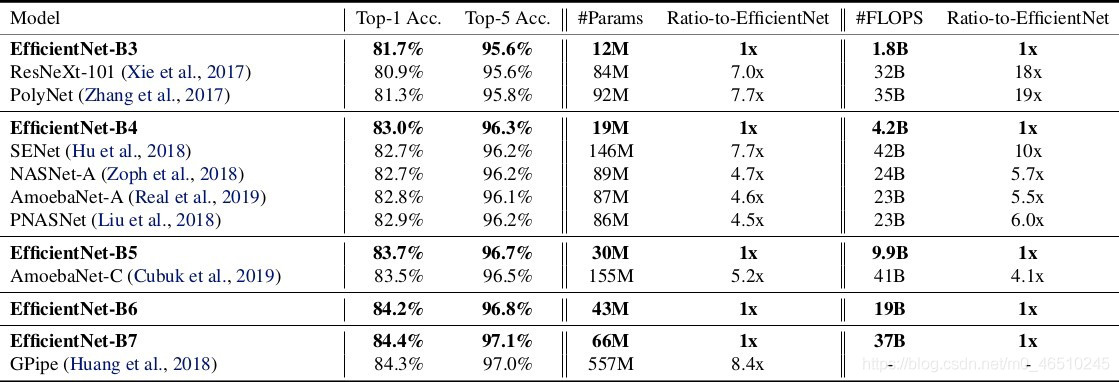
自从Alex net在2012年ImageNet挑战赛中获胜后,卷积神经网络就在计算机视觉领域中无处不在。它们甚至在自然语言处理中也有应用,目前最先进的模型使用卷积运算来保留上下文并提供更好的预测。然而,与其他神经网络一样,设计cnn网络的关键问题之一是模型缩放,例如决定如何增加模型的尺寸,以提供更好的准确性。 这是一个冗长的过程,需要手动命中和试验,直到产生一个足够准确的模型,满足资源约束。这个过程耗费资源和时间,并且常常产生精度和效率都不理想的模型。 考虑到这一问题,谷歌在2019年发表了一篇论文,对一个新的CNNs家族i进行了处理。例如最新的EfficientNet。这些CNNs不仅提供了更好的准确性,而且通过减少参数和每秒浮点运算流形提高了模型的效率。本文的主要贡献是: 设计一个简单的移动设备大小的基线架构:efficient – net – b0 提供了一种有效的复合缩放方法来增加模型的尺寸,以达到最大的精度增益。 该方法可以推广到现有的CNN体系结构,如移动网络和ResNet。然而,选择一个好的基线网络是获得最佳结果的关键,因为复合标度方法只是通过复制基网络的底层卷积操作和网络结构来提高网络的预测能力。 为此,作者利用神经结构搜索建立了一个高效的网络结构——efficient – net – b0。它在ImageNet上仅用5.3M参数和0.39B延迟就实现了77.3%的精度。(Resnet-50提供了26M参数和4.1B FLOPS 76%的准确性)。 该网络的主要组成部分是附加了压缩激励优化的MBConv。MBConv类似于在MobileNet v2中使用的inverted residual blocks。这些在卷积块的开始和结束之间形成了快捷连接。首先使用1×1卷积扩展输入激活映射,以增加特征映射的深度。接下来是3×3 Depth-wise和Point-wise的卷积,减少了输出feature map中的通道数量。快捷连接连接狭窄的层,而较宽的层之间存在跳跃连接。这种结构有助于减少所需操作的总体数量以及模型大小。 模型扩展。(a)是一个基线网例;(b)-(d)是只增加网络宽度、深度或分辨率一维的常规缩放。(e)是我们提出的以固定比例均匀缩放三个维度的复合缩放方法。 卷积神经网络可以在三个维度上缩放:深度、宽度和分辨率。网络的深度与网络的层数相对应。宽度与层中神经元的数量相关联,或者更确切地说,与卷积层中滤波器的数量相关联。分辨率就是输入图像的高度和宽度。上面的图2更清晰地展示了跨这三个维度的缩放。 通过叠加更多卷积层来增加深度,可以让网络学习更复杂的特征。然而,更深层次的网络往往受到梯度消失的影响,变得难以训练。尽管批处理标准化和跳转连接等新技术在解决这个问题上很有效,但经验研究表明,仅通过增加网络的深度,实际的准确率就会很快达到饱和。例如,Resnet-1000提供了与Resnet-100相同的精度,尽管有很多额外的层。 缩放网络的宽度可以让各层了解更多细粒度的特征。这一概念在广泛的ResNet和Mobile Net等工作中得到了广泛的应用。然而,随着深度的增加,宽度的增加会阻碍网络学习复杂的特征,从而导致精度增益减少。 较高的输入分辨率提供了图像的更多细节,从而增强了模型推理较小物体和提取更精细模式的能力。但就像其他缩放维度一样,它本身也提供了有限的精度增益。 采用不同的网络宽度(w)、深度(d)和分辨率®系数对基线模型进行缩放。 这引出了一个重要的观察结果: 1:增大网络宽度、深度或分辨率的任何维度都会提高精度,但对于较大的模型,精度增益会减小。 根据不同的基线网络工程调整网络宽度。 这意味着,为了提高准确度,网络的规模应该部分由三个维度的组合来贡献。上图中的经验证据证实了这一点,在上图中,针对不同的深度和分辨率设置,网络的精度随着宽度的增加而建模。 结果表明,只缩放一维(宽度)快速停滞的精度增益。然而,这与层数(深度)或输入分辨率的增加相结合,可以增强模型的预测能力。 这些观察在某种程度上是预期的,可以用直觉来解释。例如,如果输入图像的空间分辨率增加,那么卷积层的数量也应该增加,以便接收域足够大,能够覆盖现在包含更多像素的整个图像。这就引出了第二个观察结果: 2:为了追求更高的精度和效率,在进行卷积时,网络宽度、深度和分辨率等各维度的平衡至关重要。 卷积神经网络可以被认为是各种卷积层的叠加或组合。此外,这些层可以划分为不同的阶段。例如 ResNet有五个阶段,每个阶段中的所有层都具有相同的卷积类型。因此,一个CNN可以用数学表示为: N表示网络 i代表阶段号码, Fᵢ代表卷积操作第i阶段, L代表的 Fᵢᵢ阶段的重复次数 HᵢWᵢCᵢ代表阶段的输入张量形状。 可以推导出的方程1,Lᵢ控制网络的深度,Cᵢ负责网络的宽度而Hᵢ和Wᵢ影响输入分辨率。由于搜索空间巨大,要找到一组好的系数来缩放每一层的尺寸是不可能的。因此,为了限制搜索空间,作者制定了一套基本规则。 缩放模型中的所有层/阶段都将使用与基线网络相同的卷积操作 所有的图层必须以恒定的比例均匀缩放 建立这些规则后,可参数化为: 式中,w、d、r为尺度网络宽度、深度、分辨率系数;F̂ᵢL̂ᵢ,Ĥᵢ,Ŵᵢ,Ĉᵢ是预定义的参数基线网络。 作者提出一个简单的,但有效的缩放技术,使用一个复合系数ɸ统一规模网络的宽度、深度和分辨率有原则的方式: ɸ是一个用户定义,全局比例因子(整数)控制多少资源可用而α,β,γ决定如何将这些资源分配给网络深度、宽度,分别和分辨率。卷积操作的FLOPS 与d, w, r的FLOPS 成正比,因为将深度加倍将使FLOPS 加倍,而将宽度或分辨率加倍将使FLOPS 几乎增加四倍。所以,扩展网络使用方程3将增加总FLOPS (αβγ²²)^ɸ。因此,为了确保总FLOPS 不超过2 ^ϕ,约束(αβγ²²)≈2。这意味着,如果我们有两倍的可用资源,我们可以简单地使用复合系数2的一次方。 参数α,β,γ-可以确定使用网格搜索通过设置ɸ= 1,发现导致最好的精度的参数。一旦发现,这些参数可以是固定的,和复合系数ɸ可以增加变大,但更精确的模型。这就是效率网- b1到效率网- b7的构造方式,名称后面的整数表示复合系数的值。 这项技术使得作者能够制作出比现有的ConvNets精度更高的模型,同时也极大地减少了整体FLOPS 和模型尺寸。 EfficientNet 与现有网络在ImageNet挑战中的比较 该标度方法具有通用性,可与其他结构相结合,有效地对卷积神经网络进行标度,提高了标度精度。 作者:Armughan Shahid deephub翻译组 作者:Armughan Shahid deephub翻译组
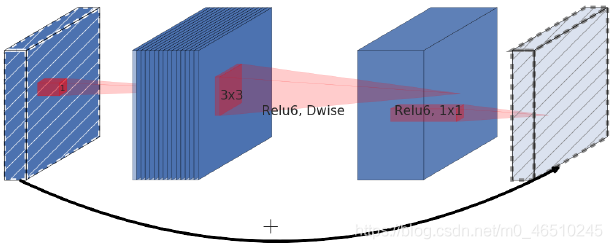
from keras.layers import Conv2D, DepthwiseConv2D, Add def inverted_residual_block(x, expand=64, squeeze=16): block = Conv2D(expand, (1,1), activation=’relu’)(x) block = DepthwiseConv2D((3,3), activation=’relu’)(block) block = Conv2D(squeeze, (1,1), activation=’relu’)(block) return Add()([block, x]) 缩放比例
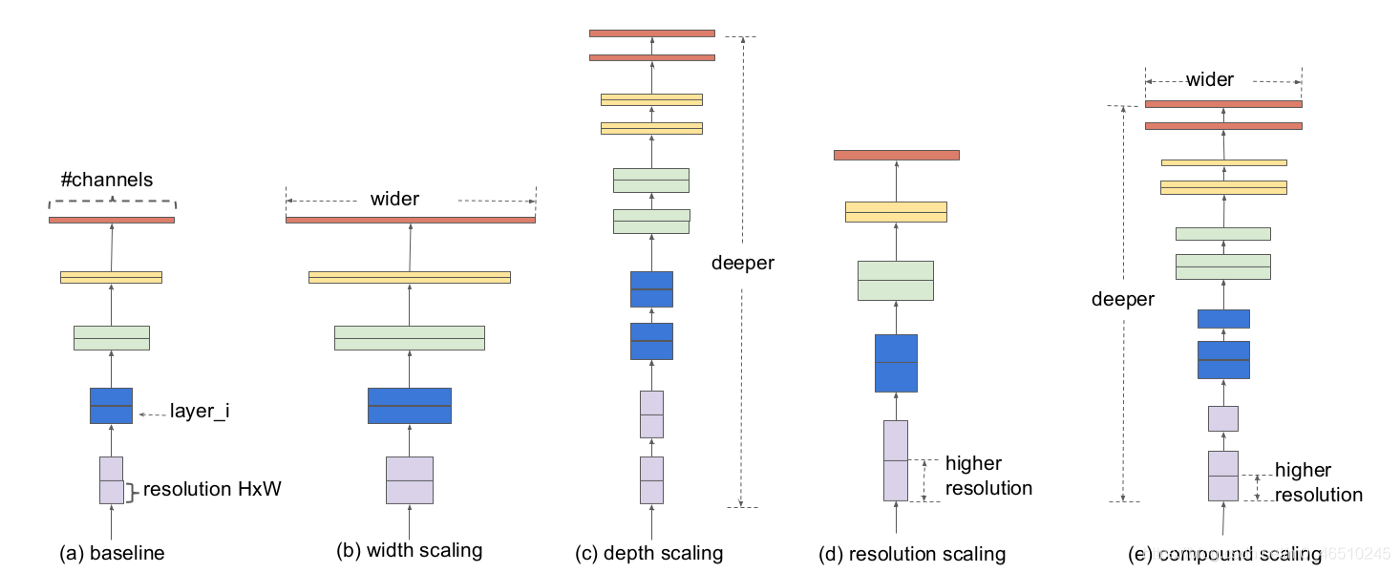
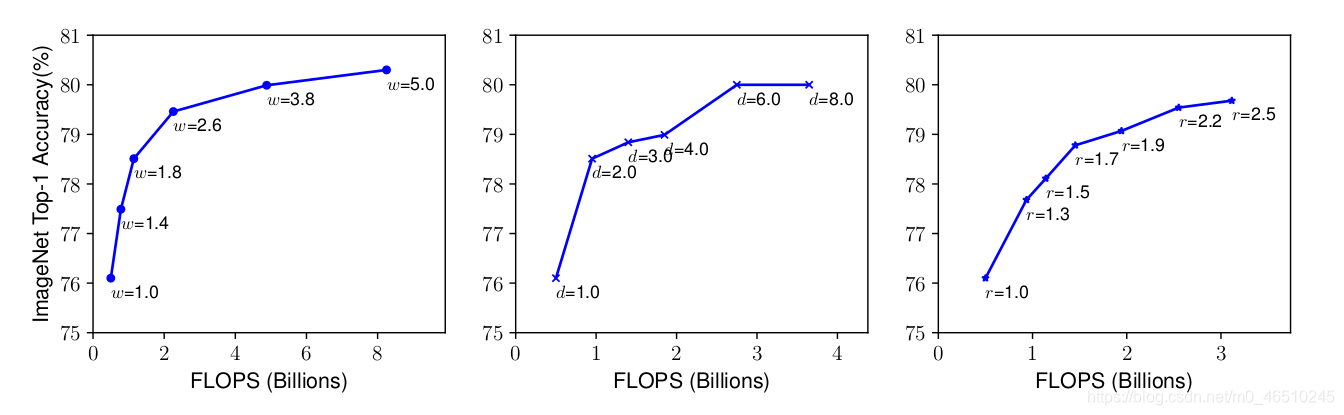
缩放的方法
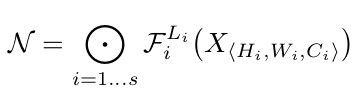
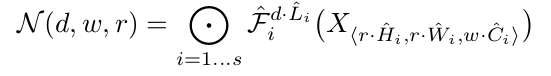

结果
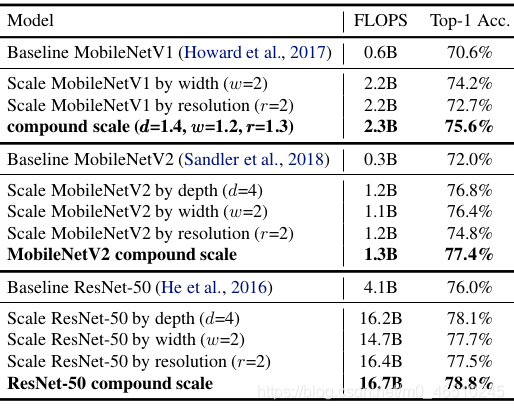
引用:
引用:
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 722
722