在之前的博客里已经基本上介绍了Hadoop的基本架构,Hadoop包含三大基本组件: 这篇博客主要是对Hadoop三大基本组件之一的HDFS进行深入的学习。 随着数据量越来越大,在一一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。 HDFS(Hadoop Distributed File System):是Hadoop的分布式文件系统的实现。它的设计目标是存储海量的数据,并为分布在网络中的大量客户端提供数据访问。 HDFS是一种分布式文件系统,将文件存储到不同的计算机节点中。如何将文件保存到不同节点中? 最终解决方案: 主从模式 文件被拆分为多个Block(块)放到不同的DataNode中,在HDFS 1.x 中每个块默认大小为64MB,HDFS 2.x 中每个块默认大小为128MB,同一个块会备份到多个DataNode中存储。 HDFS组成架构如下所示: 整个系统的元数据都保存在NameNode中 NameNode元数据管理过程 为什么块的大小不能设置太小,也不能设置太大? 为什么文件操作不直接写入fsimage,而要写入单独的edits文件? 为什么要使用Secondary NameNode合并操作日志? NameNode单点故障会导致整个Hadoop崩溃 HDFS高可用性 Block DataNode NameNode 元数据( Metadata ) 心跳 客户端(Client)
一、HDFS概述
1.1 HDFS产生背景
1.2 HDFS定义
HDFS是高容错性的,可以部署在低成本的硬件之上,HDFS提供高吞吐量地对应用程序数据访问。
HDFS的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。1.1 HDFS特性
1.2 HDFS局限性
二、HDFS架构思路解析
2.1 HDFS架构思路解析1
HDFS是基于何种思路来设计目前的架构?2.2 HDFS架构思路解析2
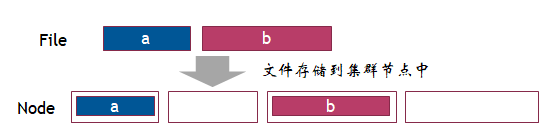
采用这种方法存在以下两种优点:
1、可靠性高,一个节点坏掉,启用备份
2、读取速度快,同一份数据多个备份同时读
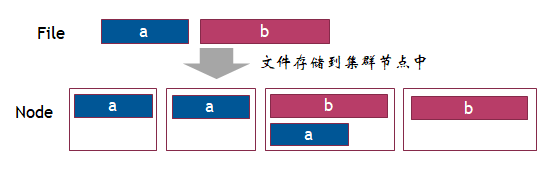
那又存在什么局限性呢?
大文件保存和读取困难(如:单个100G文件)。2.3 HDFS架构思路解析3
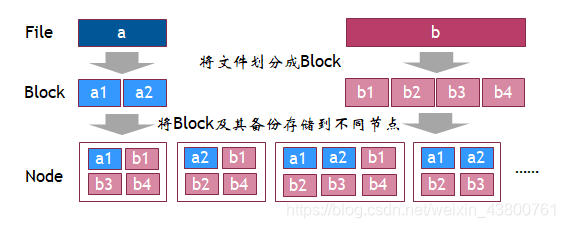
2.4 HDFS架构思路解析4
节点中只存储了文件的Block,文件的原始信息丢失
逐个节点去查找?
还是建立一个管理节点,专门来管理各个节点的信息?
二、HDFS组成架构
2.1 HDFS组成架构介绍
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block) 映射信息;
(4)处理客户端读写请求。
(1)存储实际的数据块
(2)执行数据块的读/写操作
(1)文件切分。文件上传HDFS的时候, Client将文件切分成一 个个的Block, 然后进行上传
(2)与NameNode交互,获取文件的位置信息
(3)与DataNode交互,读取或者写入数据
(4)Client提供一 些命 令来管理HDFS,比如NameNode格式化
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
(1)辅助NameNode,分担其工作量,比如定期台并fsimage和edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode。2.2 Namenode的元数据管理机制
2.3 三个问题
总结: HDFS块的大小设置主要取决于磁盘传输速率。
2.4 Checkpoint过程

2.5 NameNode单点故障恢复
SN与NN并不是时刻同步的,checkpoint有时间间隔,这会导致恢复后有数据丢失
NSF(Network File System,网络文件系统)可与网络中的主机相互传输文件
NN可配置NFS灾备服务器,在写入fsimage、fstime、edits、edits.new等文件时,同步写入到NSF服务器中,进而避免NN数据丢失
三、HDFS数据写入机制

0:NameNode需要通过心跳机制收集DataNode的生存状态和存储状态;用以在第3步时,分配最佳的block存储位置。
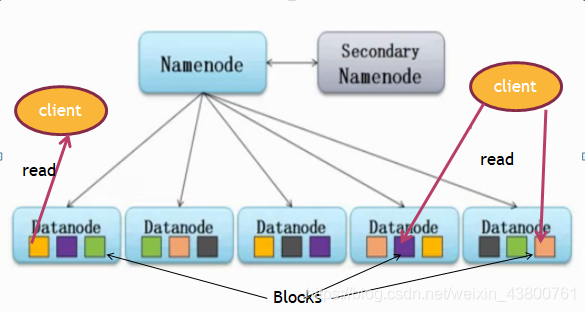
四、HDFS数据读取机制
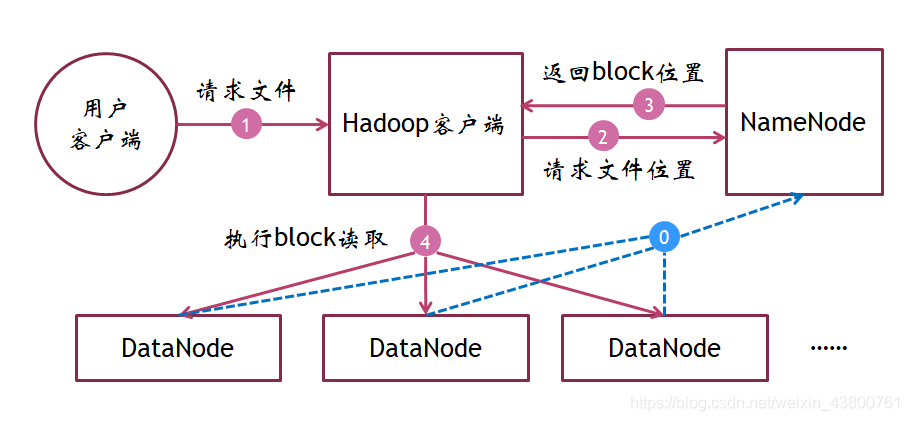
0:NameNode需要通过心跳机制收集DataNode的生存状态;在第3步时,不会将失效的DataNode位置返回给客户端
五、涉及概念(总结)
所有的文件将被拆分为若干block(缺省每个block大小为64mb),以存放在不同的DataNode中(每个block将有3个备份保存到不同DataNode)
用于存储block, block以文件的形式随机存储在集群的各个DataNode上
DataNode不知道数据的内容,提取数据时无法知道每个Block该哪个DataNode上提取,于是需要记录每个Block存储在何处(NameNode上的元数据)。
记录文件的元数据,NameNode知道所有的文件对应哪些Block以及这些Block都存放在何处
与各个DataNode通信并管理DataNode
描述数据的数据(data about data)
包含了:每个文件的文件名、文件位置、访问权限和各个块的名称和位置
大量小文件会生成过多元数据记录,降低NameNode查询效率(小文件定义:远远小于block边界大小的文件)。
例:64Mb的文件分配1个block,占用1条元数据记录;而同样大小的1024个64Kb的文件,须分配1024个block,占用1024条元数据记录
NameNode记录了所有的DataNode,但如果DataNode突然失效,NameNode需要迅速的知道;于是需要每个DataNode定期(默认每3秒)向NameNode发送心跳信息
代表用户通过与NameNode和DataNode交互来访问整个文件系统.
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 1209
1209