HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库 所谓的数据模型,就是指的我们HBase的数据结构。我数据扔进去之后,给用户展现出什么样子的。底层又存储成什么样的。 这个简单的逻辑架构先带我们认识HBase的结构。后面还会丰富它,并且纠正它,这里只是为了方便好理解。 所谓的逻辑结构,就是HBase给我们展现出来的是什么样的数据。 下一个概念教RowKey,非常非常重要,在HBase中非常重要。这个RowKey可以和关系型数据库中的主键做一个类比 所谓物理结构,就是HBase在底层是怎么存储的。我们以上面的一个Store为例,看一下它底层是怎么存储的。以张三这个数据为例
HBase基础

什么是HBase

它第一句就告诉我们了是Hadoop的Database,跟Hadoop有关系的,a distributed分布式的,scalable可扩展的,根据这句话的描述,我们可以知道,HBase的数据是存储再Hadoop中HDFS中的,它数据是要落盘的。我们搭建HBase的时候呢,它是一个集群,是分布式的,可扩展的意思就是横向扩展的意思。可以添加很多很多的节点。big data store海量数据的存储。所以HBase是存储系统。什么时候用HBase

其中有些词汇我们拿出来分析一下,random随机的,realtime实时的,read/write读写,Big Data海量数据,这句话大概意思就是,你想随机实时的读写海量数据,这个时候我们就可以考虑使用HBase。并且看图:

它还是一个数十万行和数百万列的大表。这是它项目的目标,支持这么大的表
而且它还说了是将谷歌的BigTable进行了开源实现,相当于借鉴了谷歌的BigTableHBase定义
思考题:什么是NoSQL?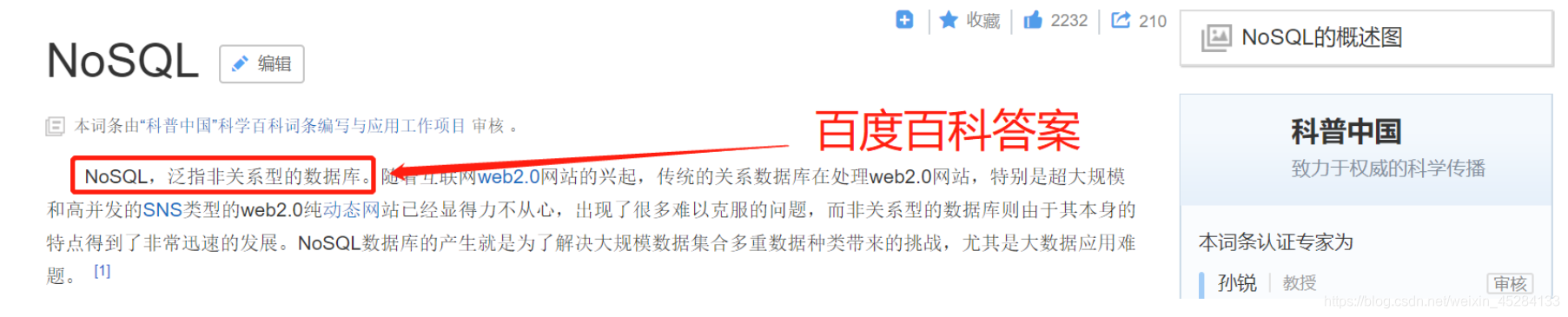
说的具体点,就是,非关系型,分布式,不提供ACID的数据库设计模式,这里的ACID指的是数据库四个事务特性。原子,一致,隔离,持久。以键值形式,和面向文档形式存储。
我们其实再大数据领域,已经有了海量存储系统,HDFS,那么为什么还要一个HBase呢?我们关心存储系统,主要关心就是读写问题,HDFS的读写太慢了,它是批量读写,一次写海量数据,一次读海量数据,不能做到随机读写,比如说:我在10亿条数据中修改一个数据,HDFS是不支持这个操作的,我们的HDFS主要做什么呢?主要存储静态数据,所以我们搞了个HBase,它快在了哪里呢?快在了随机实时读写上。它是支持这个的。我现在有海量的数据,在10亿条数据中修改某一条,删除某一条,都是能做到的HBase数据模型
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,很多个kv键值对我们通常称之为Map,HBase更像是一个multi-dimensional mapHBase简单逻辑结构
如图所示:底下这张图就是HBase他给我们用户呈现出来的样子。与我们关系型数据库中的表是一样的,非常相似。有行有列
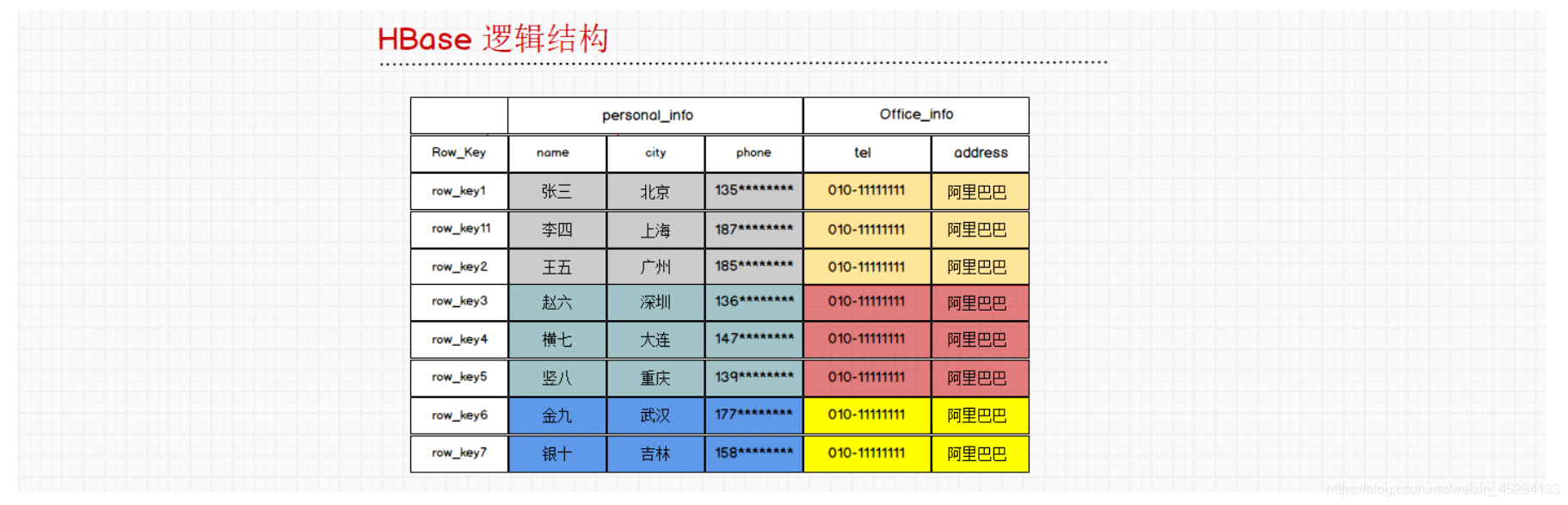
而在这张图中,有一个非常重要的概念在里面,就是personal_info和Office_info的位置,我们称之为列族。它的英文为Colum n Family,意思就是多个列的组合。一个列族下面有多个列。
在底层存储的时候,一个列族的数据,我们是存储在一起的,不同列族的数据,我们是分开存储的。

第二个就是列的概念,相当于关系型数据库中的字段是一个概念。其实这个列理解起来简单
但是它没有那么简单,我们关系型数据库中是不是要建表,建表的时候需要声明这个表中有哪些字段。有哪些列,都要提前规划好,而每个字段都会有相应的数据类型跟随,是Int类型,还是Varchar类型,而在我们HBase中建表的时候,我们其实是不需要声明列的,我们建表的时候只需要声明列明就够了。

我们没有列怎么插入数据呢?我们HBase的列,就是在我们插入数据的时候才会出现。那我们是不是这个列可以随便写呢,我们插入数据的时候,想插入那个列,就插入哪个列,如果这个列以前没有,那么插入数据的时候是不是就有了呀。这个其实是和我们的底层存储有关系的。一会儿我们说底层存储时会讲。
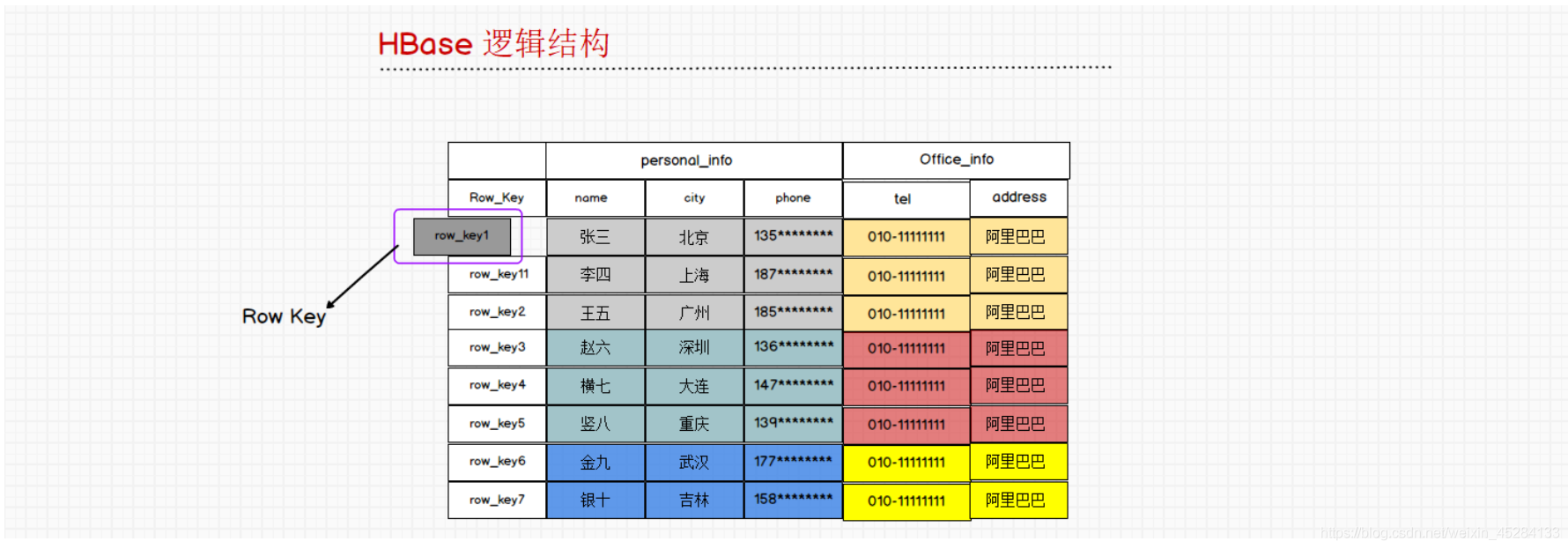
我们这个RowKey,在我们的HBase中比哪个主键要强太多了。那么这个重要性体现在什么地方呢?首先我们观察一下,会发现它时有序的。也就是说,我们HBase中的数据是有序的。排序的时候我们是按照RowKey的字典顺序排序的。看第二个11和第三个2就会发现了。他是一个字符一个字符比的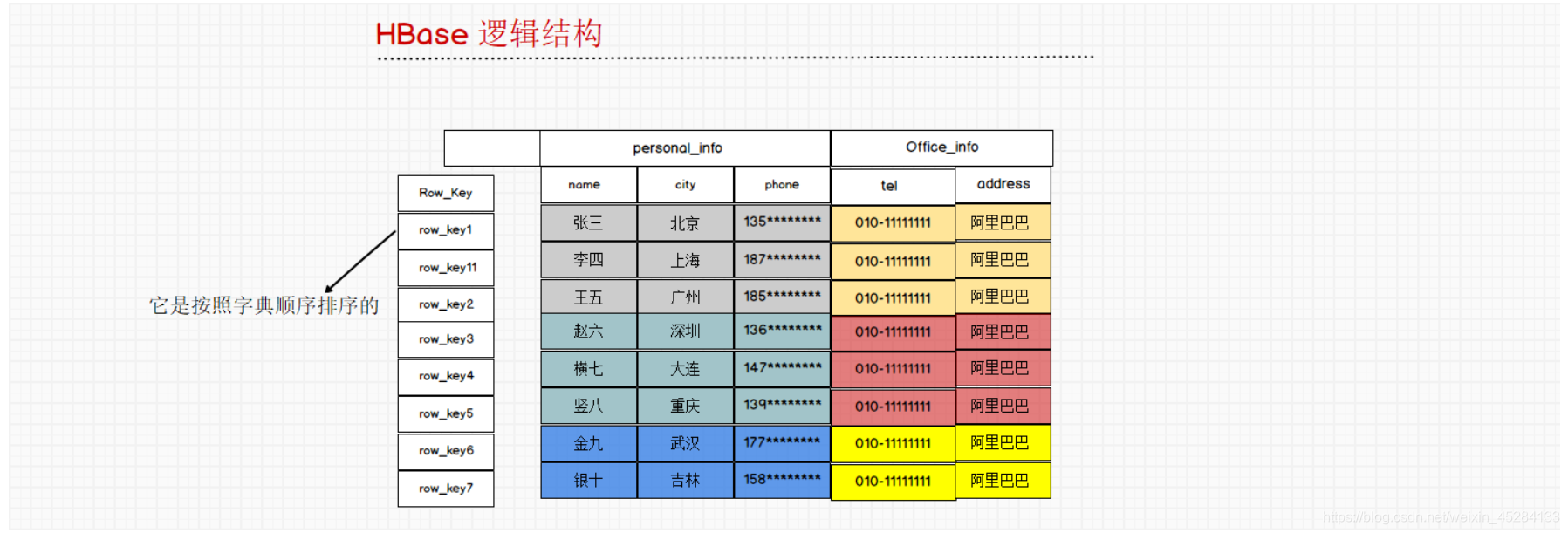
而在我们检索数据库的时候,我们需要对数据库进行查询,我们检索数据的时候只能根据这个RowKey去检索。比如说稳要查一下这个李四的电话号码是多少?如果是关系型数据库,稳直接用SQL就可以查询select name from 表名 where name = 李四,我们如果在HBase中查询李四数据的时候,只能查询RowKey11这条数据在哪里
用其他的什么列区检索能不能实现?其实也是能实现的,只不过性能是非常差的,如果稳通过name去检索李四,它会扫描全表,将姓名等于李四的过滤出来。如果我们就想要姓名等于李四的手机号,通过RowKey去查询,我们怎么做呢?我们可以将姓名这个字段融入到RowKey当中。RowKey是我们自己设定的,我们就可以通过RowKey加上Name去过滤李四。RowKey我们自己设计,想怎么设计,就怎么设计。我们效率之所以高,也是因为RowKey是有序的。完全可以混入二分查找法来加速我们的查询。至于RowKey到底怎么设计,我们后面再说。
这里注意一个小点,就是同一个RowKey的列族是会别切分的。如图:
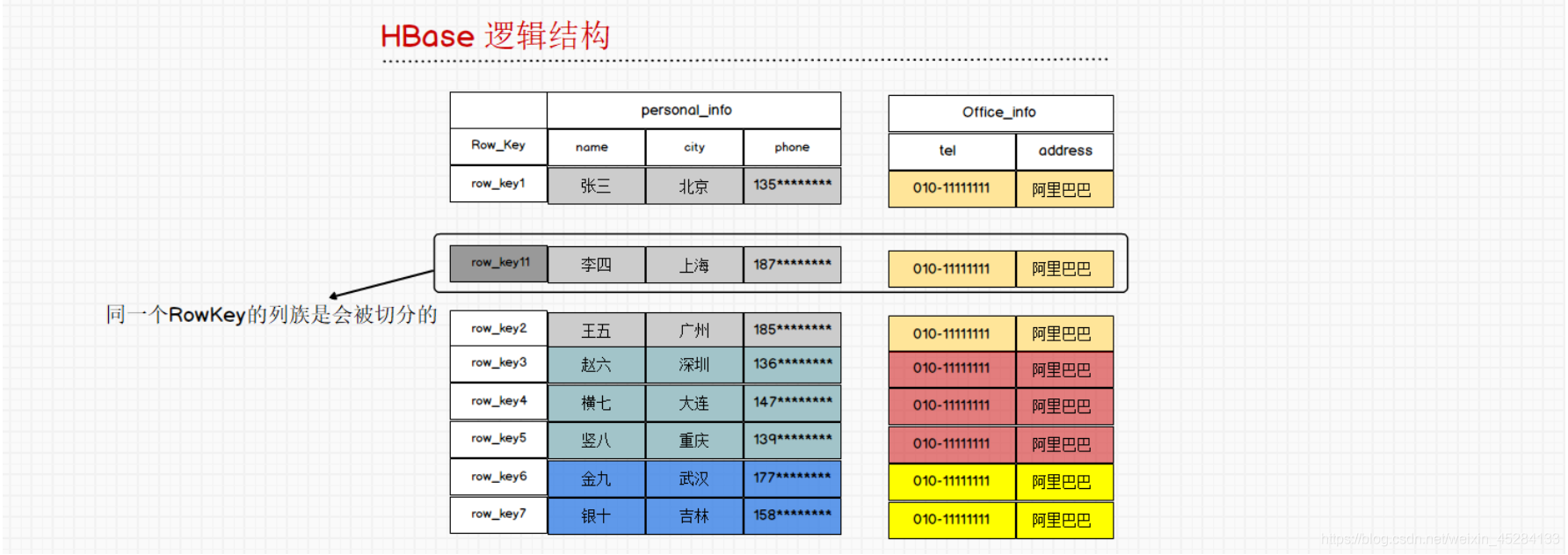
我们HBase是一个分布式存储系统,一旦涉及到分布式,我们就要有一个分区的概念,这里和Kafka比较类似。它的分区时横向分的,而每一个分区都叫做Region,Region地区地域的意思。而每一个分区都有一个RowKey的范围。至于分区怎么分,我们后面会说。相同的RowKey不可以跨Region,言外之意就是一行的数据只能存储在一个分区里面。
下面还有一个概念叫做Store,Store存储的意思,它时干什么用的呢?他就是干数据存储的一个组件。那么我一个Store存储的单元是什么?也就是说我一个Store负责的区域是什么?它负责的是一个Region中的一个列族。如图:
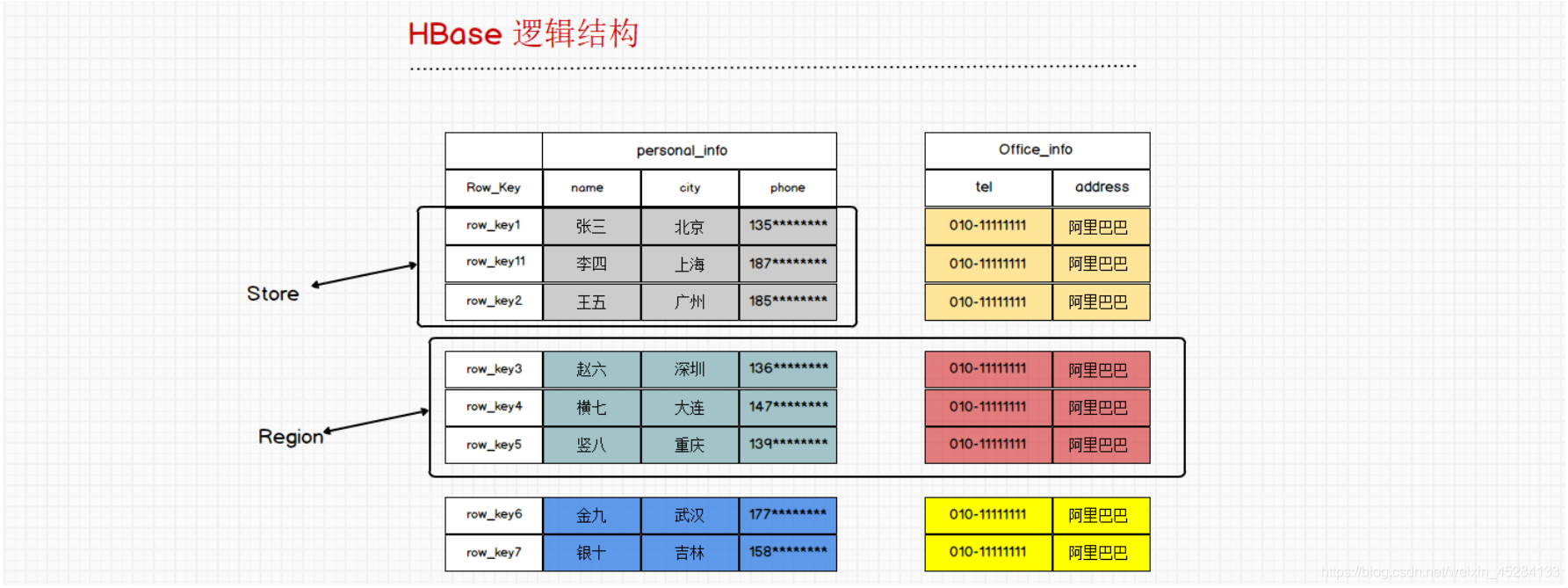
我们的一个表中会有多个Region,我们的一个表中也会有很多个列族,而我们刚才的那个图中应该有几个Store才对呢?有6个才对。
下图是回顾总结。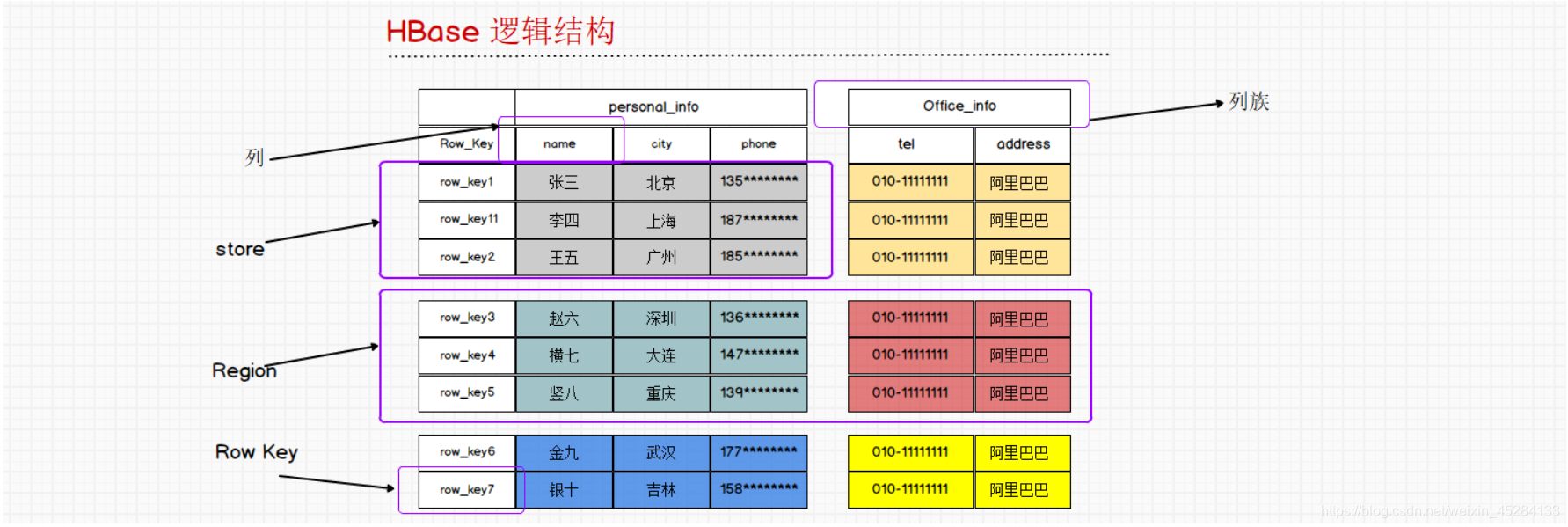
HBase简单物理结构

我们存储一行数据要存储这么多东西?它看着也像一张表。我们看一下都是什么,如图所示:
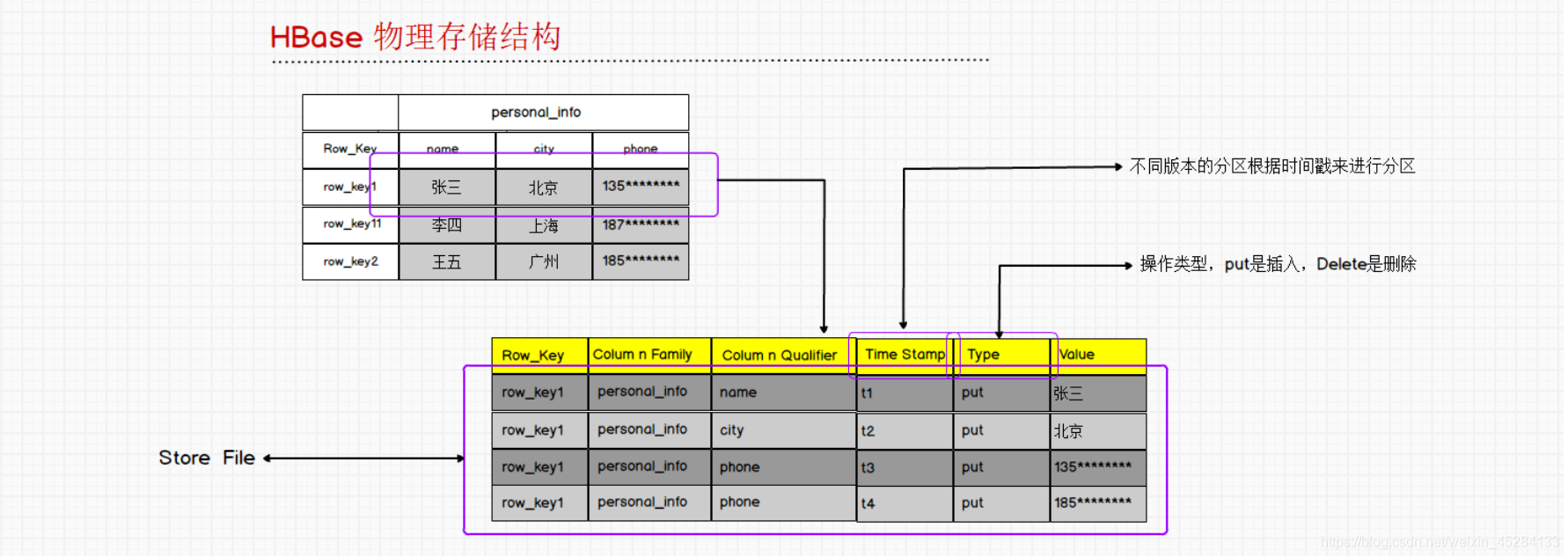
看到这里我们感觉HBase更像一个多维的Map,V是谁呢?就是什么张三,北京电话,谁是K呢?每一行除去V,前面的一大堆都叫K。这个K是多个字段组成的,所以我们叫他多维的Map。下面的一行数据对应的就是上面的一个小单元格,入下面张三一大行数据,对应的就是上面一个单元格张三的位置,北京也是如此。但是我们上面只有三个单元格,为啥下面有四行数据呢?最后两行数据都是电话,为什么会存储两条数据呢?其实是更新了。HBase会认时间戳的,他会显示最新时间戳的数据信息。它是以追加一条数据的方式,实现了修改和删除的功能。为什么不直接修改呢?是因为我们的数据是海量数据,直接修改数据首先要定位数据,开销非常大。其实HBase是牺牲了一部分读取的性能换来了它写性能的提升。我们在HBase中删除一条数据使用Delete的时候,我们会将数据类型进行更改变成Delete,当HBase检索到这条数据看到它这个类型,HBase会判断的,删除的数据不会再显示。这个删除的数据不会永久保留,我们后续再说
这里还牵扯数来一个版本的问题,就是时间戳,我们可以设定我们要几个版本的数据,我想保留一条数据的三个版本,我就将version设成3,会显示出最近一条数据追加更新的三条历史记录一样的东西。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 148
148