
“机器智能是人类永远需要的一项发明。”— Nick Bostrom.
如果您可以回顾几年前的AI并将其与现在的AI进行比较,您会惊讶地发现AI的发展速度随着时间的增长呈指数级增长。
它已扩展到各种领域,例如ML,Expert Systems,NLP等数十个领域。
尽管AI的思路是构建可以自行思考和执行的更智能的系统,但仍然需要对其进行训练。
AI的ML领域是为实现非常精确的目标而创建的,它引入了多种算法,从而可以更顺畅地进行数据处理和决策。
机器学习算法是任何模型背后的大脑,可让机器学习并使其更智能。
这些算法的工作方式是,为它们提供第一批数据,并且随着时间的流逝和算法的准确性的提高,额外的数据也被引入到算法中。
定期将算法应用于新数据和新经验的过程可提高机器学习的整体效率。
机器学习算法对于与分类,预测建模和数据分析相关的各种任务至关重要。
“机器学习方面的突破将价值十个微软。”- Bill Gates
在本节中,我们将重点介绍现有的各种ML算法。 ML算法的三个主要范例是:
顾名思义,监督算法通过定义一组输入数据和预期结果来工作。 通过在训练数据上迭代执行功能并让用户输入控制参数来改进模型。 如果发现其映射的预测正确,则认为该算法是成功的。
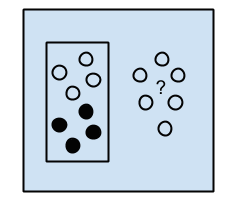
在监督算法在用户标记的数据上进行输出预测时,将这些训练结果在没有用户干预的情况下来训练未标记数据。
这个算法可以对数据进行分类和分组,以识别一些隐藏或未发现的类别,通常用作监督学习的初步步骤。
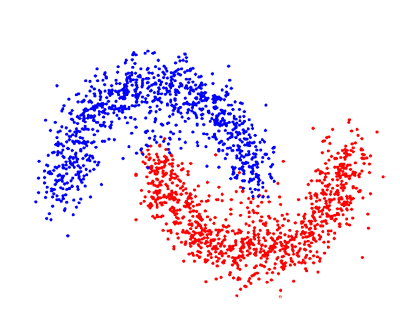
强化学习算法旨在在探索和开发之间找到完美的平衡,而无需标记数据或用户干预。
这些算法通过选择一个动作并观察结果来工作,在此基础上,它了解结果的准确程度。 反复重复此过程,直到算法选择正确的策略为止。
在熟悉了几种类型的ML算法之后,我们继续演示一些流行的算法。
1.线性回归
线性回归是一种监督型ML算法,可帮助找到点集合的近似线性拟合。
线性回归的核心是识别两个变量之间关系的线性方法,其中两个值之一是从属值,另一个是独立的。
其背后的原理是要理解一个变量的变化如何影响另一个变量,从而导致正或负的相关关系。
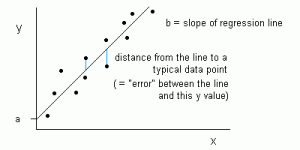
该线称为回归线,由线性方程Y = a * X + b表示。
在此等式中:
该算法适用于预测输出是连续的并且具有恒定斜率的情况,例如:
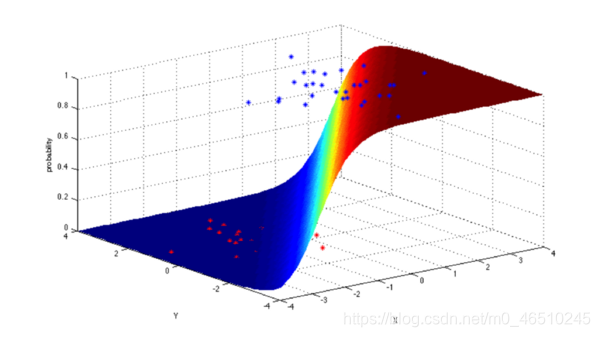
Logistic回归算法通常用于二进制分类问题,在这些情况下,事件通常会导致通过或失败,正确或错误这两个值中的任何一个。
最适合需要预测因变量将属于两类之一的概率的情况。
该算法的常见用例是确定给定的笔迹是否与所讨论的人匹配,或未来几个月的油价是否会上涨。
通常,回归可用于实际应用中,例如:
决策树算法属于监督型机器学习,用于解决回归和分类问题。 目的是使用决策树从观察并处理每个级别的结果。
决策树是一种自上而下的方法,其中从训练数据中选择最合适的属性作为根,并对每个分支重复该过程。 决策树通常用于:
它是几种在线平台上经常推荐的算法。
它通过在数据集中搜索通用的数据进行操作,然后在它们之间建立关联。
它通常用于数据挖掘和从关系数据库学习关联规则。
该算法背后的思想是保持相关项目尽可能扩展到更大的集合,以创建更有用的关联。
该算法的应用包括突出显示市场中的购买趋势。
此外,它更易于实现,并且可以用于大型数据集。
朴素贝叶斯分类器被归类为高效的监督ML算法,并且是最简单的贝叶斯网络模型之一。
它通过对数据应用贝叶斯定理,并假设给定变量的值的情况下,每对特征之间都具有条件独立性。
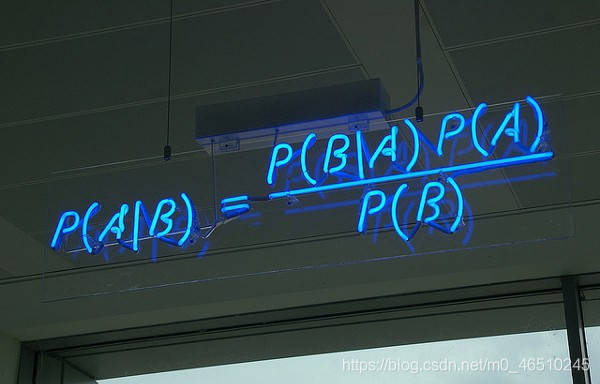
简而言之,考虑到事件B已经发生,用它来找到事件A发生的可能性。 朴素贝叶斯最适合-
仿照人脑建模的人工神经网络实现了神经元的巨大迷宫,或者说简化并模拟了节点之间相互传递信息的过程。
这些相互连接的节点通过边缘将数据瞬时传递给其他节点,以进行快速处理,从而使学习更加顺畅。
人工神经网络从数据集中学习,而不是通过一组特定的规则进行编程。 能够对非线性过程进行建模,它们可以在以下领域中实施:
k-均值聚类是一种迭代的无监督学习算法,可将n个观察值划分为k个簇,每个观察值均属于最近的簇均值。

简而言之,该算法基于数据点的相似性来聚合数据点的集合。 它的应用范围包括在Python,SciPy,Sci-Kit Learn和data mining等编程语言和库中聚集相似和相关的网络搜索结果。
K均值聚类的实际应用-
识别假新闻
垃圾邮件检测和过滤
按类型对书籍或电影进行分类
规划城市时的热门交通路线
支持向量机
支持向量机被归类为监督机器学习算法,主要用于分类和回归分析。
该算法通过建立一个可以将新示例和新数据分配给一个类别的模型来工作,每个类别间可以容易地区别开来。
在维数大于样本数的情况下,SVM非常有效,并且存储效率极高。
SVM应用程序可以在以下领域找到:
K近邻是一种用于回归和分类问题的监督ML算法。
通常用于模式识别,该算法首先存储并使用距离函数识别数据中所有输入之间的距离,选择最接近中心点的k个指定输入并输出:
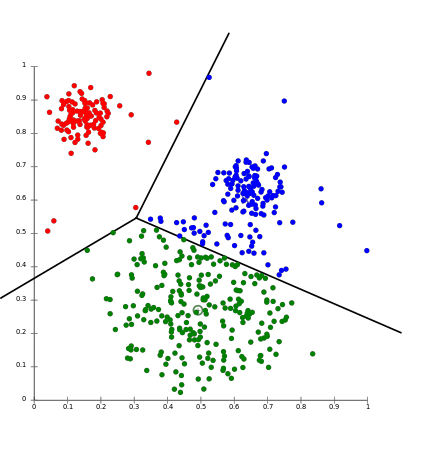
该算法的实际应用包括:
降维算法通过使用两种主要方法(特征选择或特征提取)之一减少数据集中的维度空间或随机变量的数量来工作。
此算法通常用于预处理数据集并删除冗余特征,从而使算法更容易训练模型。
此算法还具有一些不错的好处,例如:
一些著名的降维算法是:
主成分分析是ML的无监督算法之一,主要用于通过使用特征消除或特征提取来缩小特征空间的维数。
它也是探索性数据分析和建立预测模型的工具。 需要标准化的数据,PCA可以作为帮助:

PCA旨在减少数据集中的冗余,使其更简单而又不影响准确性。 它通常部署在图像处理和风险管理领域。
随机森林通过实现决策树使用多种算法来解决分类,回归和其他类似问题。
它的工作方式是,创建带有随机数据集的决策树堆,并在其上反复训练模型以获得接近准确的结果。
最后,将来自这些决策树的所有结果组合在一起,以识别出最常出现在输出中的最合适的结果。
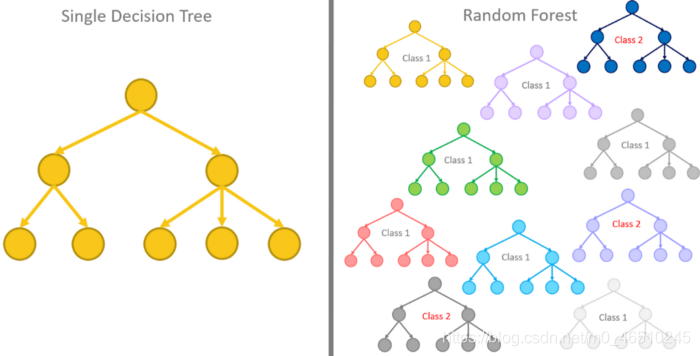
可以在以下领域找到“随机森林”应用程序:
银行账户,信用卡欺诈检测
检测并预测药物的药物敏感性
通过分析患者的病历来识别患者的疾病
预测购买特定股票时的估计损失或利润
梯度增强和Ada增强
增强是一种用于集成ML算法的技术,可将弱学习者转换为强学习者。 当数据丰富时,需要使用增强算法,并且我们试图减少监督学习中的偏差和方差。 以下是两种流行的增强算法。
通常以迭代方式(例如决策树)构建预测模型,将梯度增强算法用于分类和回归问题。 通过对强者的错误进行培训,从而提高了弱者的学习能力,从而获得了一个比较准确的学习者。
AdaBoost是Adaptive Boosting的缩写,当弱学习者失败时,它会改进模型。 它通过修改附加到样本中实例的权重以将精力更多地集中在困难实例上来实现,然后,弱学习者的输出将被合并以形成加权总和,并被视为最终的提升后的输出。
机器学习算法对于数据科学家来说至关重要,因为它们在现实世界中的应用日益广泛。 使用上述各种算法,您可以找到最适合解决问题的算法。 尽管这些算法有有监督也有无监督,但它们可以处理各种任务,并且能够与其他算法同步工作。
作者:Claire D.
deephub翻译组:孟翔杰
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 3万+
3万+