Raft是一种共识算法,旨在使其易于理解。它在容错和性能上与Paxos等效。不同之处在于它被分解为相对独立的子问题,并且干净地解决了实用系统所需的所有主要部分。我们希望Raft能够使更多的受众获得共识,并且这个更广泛的受众将能够开发出比当今更高质量的基于共识的系统。 Raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。 Raft协议的工作原理进行了高度的概括: Reft协议中,一个节点在任意时刻处于一下三个状态之一: 系统中只能有一个leader,如果一段时间内,发现没有leader,则大家通过选举投票选出leader,leader 会不停的给follower发送心跳消息,表示自己存活,如果leader故障,那么follower 会转为残敌data,重新选举出leader。 选举过程: 在上述过程中,根据来自其他节点的消息,可能出现三种情况: 第一种情况,赢得选举后,新leader 会立刻给所有节点发消息,广而告之,避免其余节点出发新的选举。在这里我们回到投票者的视角,投票者如何决定是否给一个选举者投票的的呢? 第二种情况:比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。 第三种情况:没有任何节点获得 majority(大多数)投票–平票。 如果出现平票的情况,那么系统是不可用的(没有leader是不能处理客户端写请求的)。因此Raft 引入了 randomized election timeouts来尽量避免平票的情况,同时,leader-based共识算法中,节点的数目都是奇数个,尽量保证majority 的出现。 当系统(leader)收到一个来自客户端的写请求,到返回给客户端,整个过程从leader的视角来看会经历以下步骤: 可以看到日志的提交过程有点类似两阶段提交(2PC),不过2PC的区别在于,leader只需要大多数(majority)节点恢复即可,这样只要超过一半节点处于工作状态则系统就是可用的。 到此只是讨论了只要日志被复制到大多数节点,就能保证不会回滚,即使在各种异常的情况下,这根据leader election 提到的选举约束有关。 Reft协议只支持一下属性 选举安全性。 即任意 term内最多一个leader被选出。在一个复制集中,任何时刻只能有一个leader,系统中同时又多余一个leader, 称之为脑裂(brain spilt),这是非常严重的问题,会导致数据覆盖。 log特性匹配,就是说如果两个节点上的某一个log entry的log index相同且term相同,那么在该index之前所有log entry 应该都相同, 首先leader在某一term的任意位置只会创建一个 log entry,且log entry是 append-only。 其次,consustency check, leader 在AppendEntries只包含最新log entry 之前的一个log的 term和index,如果follower对应的term index找不到日志,那么久告诉leader 不一致。 leader 完整性:如果一个log entry在某个任期没被提交(committed),那么这条日志一定会在所有更高的term的leader的日志里面,这跟leader election、log replication狗友关系 State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. 究其根本,是因为 term4的时候leader s1 在(c)时刻提交了之前term2任期的日志。为了杜绝这种情况:在某个leader选举成功后,不会直接提交前任leader 时期的日志,而是通过提交当前任期的日志的时候,‘顺手’把之前的日志提交了。如果leader 选举之后没有收到客户端的请求呢?,在任期来时的时候立即尝试复制、提交一条空 log 因此 在上图中不会出现(c)的情况,即term4任期的leader s1不会复制term2 的日志到s3。而是如同(e)描述的情况,通过复制-提交term4的日志顺便提交term2的日志。如果term4的日志提交成功,那么term2 的日志也一定提交成功,此时,即使 s1 crash,s5也不会重新当选。 Raft保证Election safety,即一个任期内最多只有一个leader,但在网络分割(network partition)的情况下,可能会出现两个leader,但两个leader所处的任期是不同的。如果leader收不到majority节点消息,那么可以自己 stop down,自行转换到follower状态。 follower的crash处理方式相对简单,leader只要不停的给follower发消息即可。当leader crash的时候,事情就会变得复杂。 https://thesecretlivesofdata.com/raft/ https://raft.github.io/#implementations 参见 :https://raft.github.io/
谈谈 Raft 算法
什么是Raft
Raft会先选举出leader,leader完全负责replicated log的管理。leader负责接受所有客户端更新请求,然后复制到follower节点,并在“安全”的时候执行这些请求。如果leader故障,followes会重新选举出新的leader。leader election
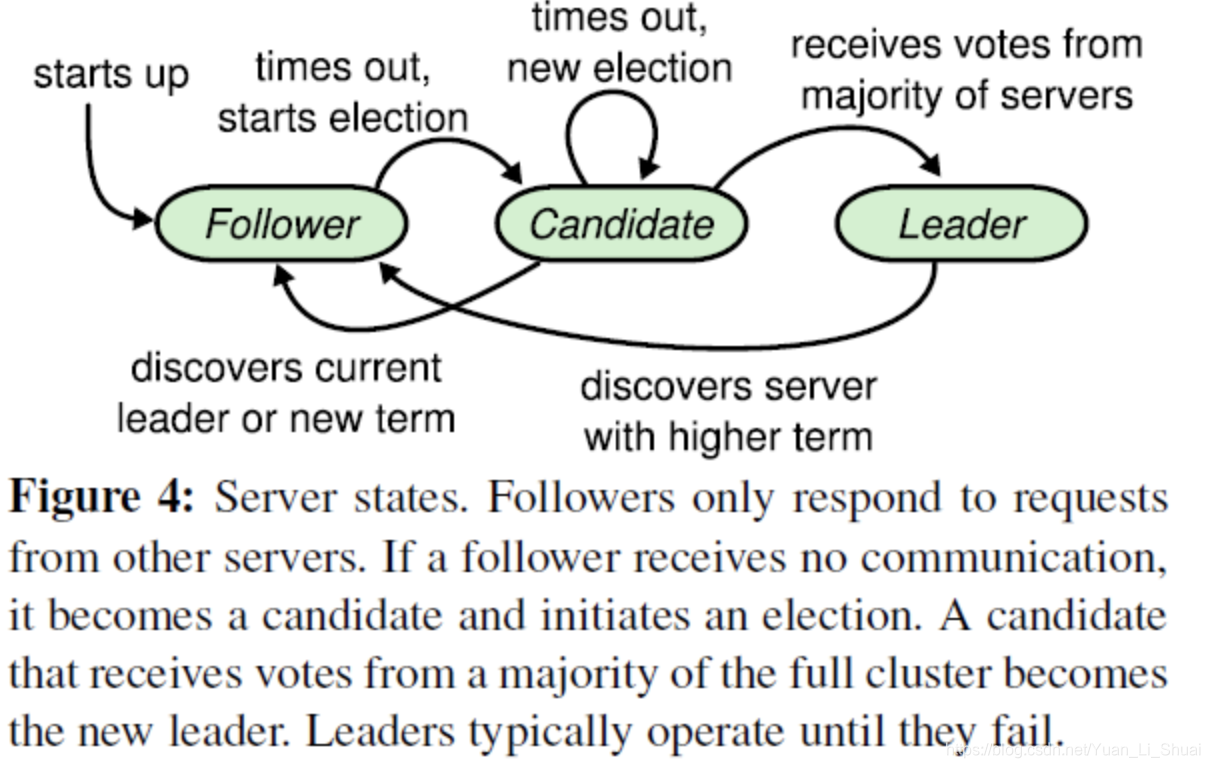
term

term以 election(选举)开始,然后就是一段时间或长或短的稳定工作期(normal Operation)。term是递增的,这就充当了逻辑时钟的概念。选举过程详解:
有以下约束:
log replication
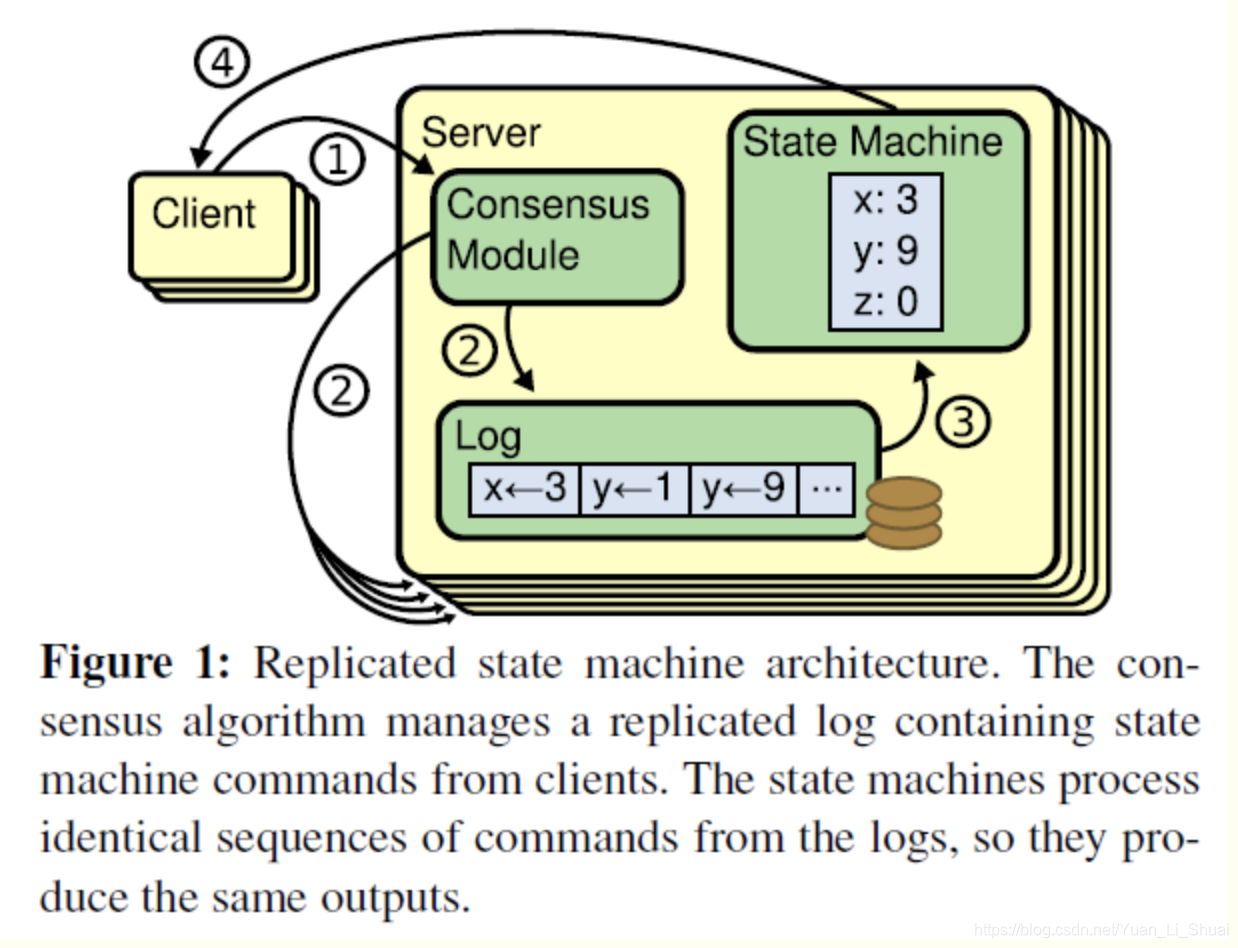
Replicated state machines (复制状态机)
共识算法的实现 一般是基于复制状态机(replication state machines)。
** 复制状态机 : 相同的状态 + 相同的输入 = 相同的状态。**请求完整流程
Raft 算法并未保证高可用,并不是强一致性,而是最终一致性,leader 会不断尝试给follower 发送 log entries,知道所有节点的log entries都相同。safety
这一节主要讨论Raft主协议在各种各样的异常情况下是如何工作的。
衡量一个分布式算法,有许多属性,如:

Election safety
在Raft 中两点保证了这个属性:
一个节点某一任期内最多只能投一票
只能获得majority 投票的节点才能成为leader。
因此 某一任期内一定只有一个leader。log matching
如何做到的只要依赖以下两点:
leader completeness vs elcetion restriction
一个日志被复制到大多数节点才算 committed
一个节点得到大多数节点的投票才能成为leader,而节点A给节点B投票的一个重要的前提,B的日志不能比A的日志旧。
上面两点都提到了 majority: commit majority and vote majority。根据Quorum,这两个 majority 一定是有重合,因此被选举出来的 leader 一定包含了最新的committed 的日志。
Raft 与其他协议(Viewstamped Replication、 MongoDB)不同,Raft时钟保证leader包含最新的已经提交的日志,因此leader不会从follower catchup 日志,这大大简化了系统复杂性。state Machine safety
如果节点将魔衣位置的log entry 应用到了状态机,那么其他节点在同一位置不能应用不同的日志。简单来说,所有节点在同一位置(index in log entriex)应该应用同样的日志。
但是往往事与愿违:
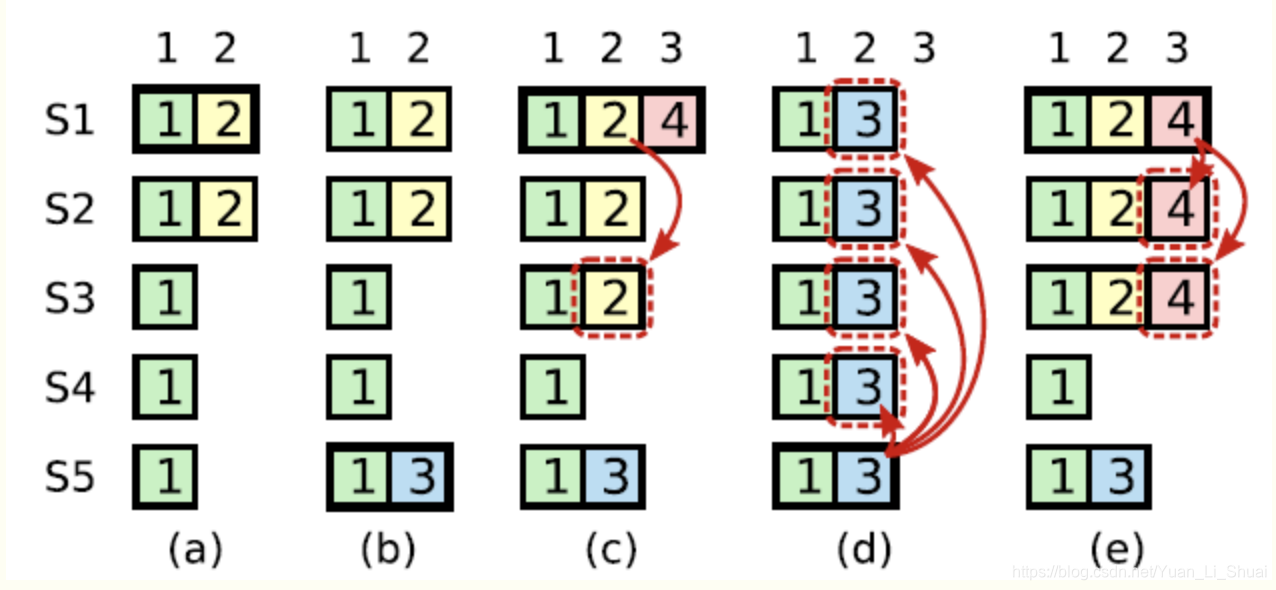
上图是一个较为复杂的情况。在时刻(a), s1是leader,在term2提交的日志只赋值到了s1 s2两个节点就crash了。在时刻(b), s5成为了term 3的leader,日志只赋值到了s5,然后crash。然后在©时刻,s1又成为了term 4的leader,开始赋值日志,于是把term2的日志复制到了s3,此刻,可以看出term2对应的日志已经被复制到了majority,因此是committed,可以被状态机应用。不幸的是,接下来(d)时刻,s1又crash了,s5重新当选,然后将term3的日志复制到所有节点,这就出现了一种奇怪的现象:被复制到大多数节点(或者说可能已经应用)的日志被回滚。
Corner case
srale leader
leader crash
Raft协议强依赖Leader节点的可用性来确保集群数据的一致性。数据的流向只能从leader节点向follower 节点转移。当Client向集群leader节点提交数据后,leader节点接受道德数据处于未提交的状态,接着leader节点会并发向所有follower节点复制数据big等待接受响应,确保至少集群中超过半数节点已接收导数据后再向client确认数据已接收。一旦向client发出数据接受ACK响应后,表明测试数据状态已经进入提交状态。leader节点再向follower 节点发通知告知该数据状态以提交。
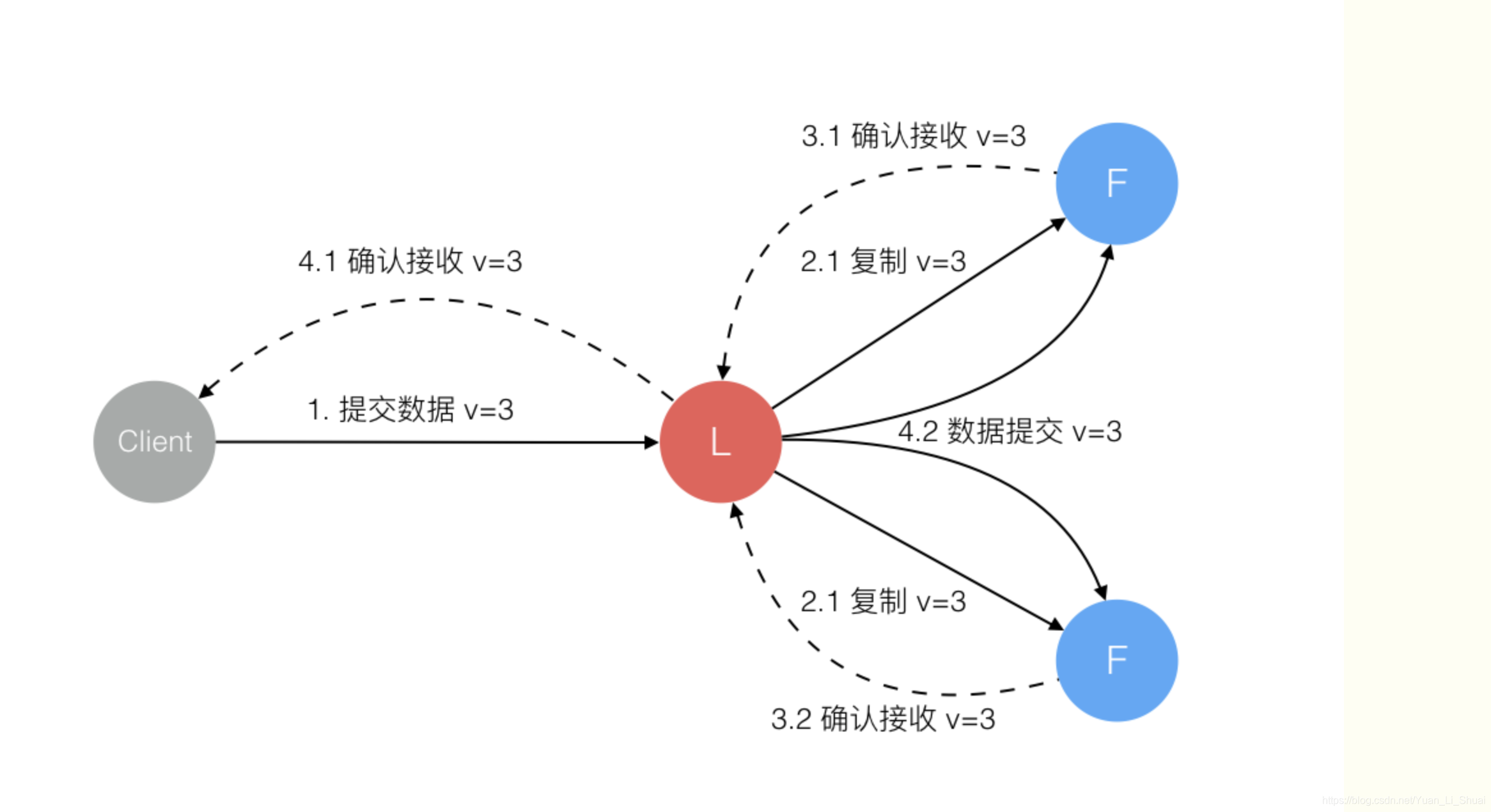
在上述过程中,leader 节点可能在任意时刻carsh。
1.数据到达 Leader节点前:
这个阶段leader挂掉不影响数据一致性
2. 数据到达Leader节点,但是未复制到Follower 节点
这个阶段Leader挂掉,数据属于未提交状态,Client不会接受ACK认为超时失败可安全发起重试。Follower 节点上没有改数据,重新选举后Client重试重新提交可成功。
原来的Leader节点恢复后作为Follower加入集群重新从当前任期的新Leader处同步数据,强制保持和Leader 数据一致。
3. 数据到达 Leader 节点,成功复制到Follower所有节点,但是还未向 Leader 响应接收
这个阶段Leader 挂掉,虽然数据在Follower 节点处于未提交状态,但保持一致,重新选举leader 后可完成数据提交,此时Client由于不知道到底提交成功没有,可重试提交。
针对这种情况Raft请求实现幂等性,也就是要实现每部去重机制
4.数据到达 Leader 节点,成功复制到Follower部分节点,但还未向Leader响应接收
这个阶段 Leader挂掉,数据在Follower节点处于未提交状态且不一致,Raft协议要求投票只能投给拥有最新数据的节点。
所以拥有最新数据的节点会被选为Leader再强制同数据到Follower,数据不会丢失并最终一致。
5.数据到达 Leader节点,成功复制到 Follower所有的或者多数节点,数据在 Leader 处于已提交状态,但是 Follower处于未提交状态
这个阶段 Leader挂掉,重新选出Leader后的处理流程和阶段3一样
6.数据到达Leader节点,成功复制Follower 所有节点或者多数节点,数据在所有节点都处于已提交状态,但是还未响应Client
这个阶段 Leader 挂掉,Cluster内部数据其实已经是一致的。Client重复重试基于幂等策略对一致性无影响。
7.网络分区导致的脑裂情况,出现双 Leader
网络分区将原先Leader节点和Follower节点隔开,Follower收不到Leader的心跳将发起选举产生新Leader。这是就产生了双leader,原先的Leader独自在一个区,想他提交数据不可能复制到多数节 点所以永远提交不成功,网络恢复后旧的 Leader 发现集群中有更新任期(term)的新Leader 则自动降级为Follower 并从新Leader处同步数据达成集群数据一致。
动画演示Raft:
Raft 算法-实现:
https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 56
56