英特尔在2018年正式推出了身材依然只有U盘大小的第二代神经计算棒(Neural Compute Stick 2/NCS 2),可让开发者更智能、更高效地开发和部署深度神经网络应用,满足新一代智能设备的需求。
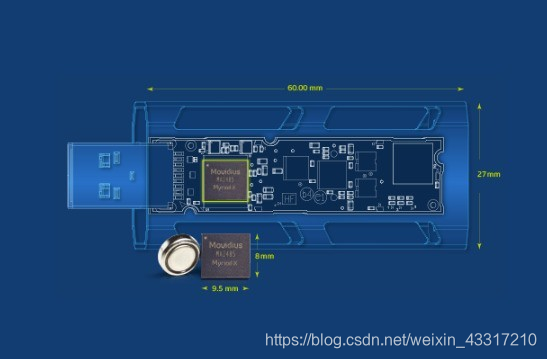
NCS 2 仍然类似U盘造型,尺寸只有72.5×27×14毫米,通过USB 3.0 Type-A接口插入主机,兼容64位的Ubuntu 16.04.3、CentOS 7.4、Windows 10操作系统。
NCS 2内置了最新的Intel Movidius Myriad X VPU视觉处理器,集成16个SHAVE计算核心、专用深度神经网络硬件加速器,可以极低的功耗执行高性能视觉和AI推理运算,支持TensorFlow、Caffe开发框架。
NCS 2的性能比之前的Movidius计算棒有了极大的提升,其中图像分类性能高出约5倍,物体检测性能则高出约4倍。
最近通过参加DFRobot行业AI开发者大赛,入手了一个NCS 2。
NCS 2的主要定位就是在应用于物联网。传统嵌入式设备受价格和体积影响,一般性能比较低(嵌入式设备使用的单片机、树莓派等计算、控制核心的性能肯定比电脑使用的cpu差得多),并不适合做深度学习中有关图像的运算。而GPU等设备因为体积较大,价格昂贵等因素,无法应用于物联网的设备端,而且在物联网的设备端只需要训练好的网络模型进行推理,不需要训练,因此在一定程度上来说,GPU用于推理会造成性能过剩。而NCS2则解决了这个矛盾,它的主要定位就是用于物联网的设备端,代替原有设备进行深度学习的推理,实现边缘计算。NCS2的体积较小,价格低,专门用于图像计算,性能高于传统的嵌入式设备,起到了取长补短的功能。
本文主要就是对NCS 2在常用图像分类,目标检测等物联网应用场景进行测试,检测NCS 2在实现深度学习网络的推理中的表现。
操作系统:ubuntu 16.04
软件环境:OpenVINO 2019 r1
测试硬件:NCS 2(vpu)
CPU(Intel Core i7-8750H)
本部分将4个经典的深度学习模型分别部署在CPU和NCS2,对比了他们的推理性能。
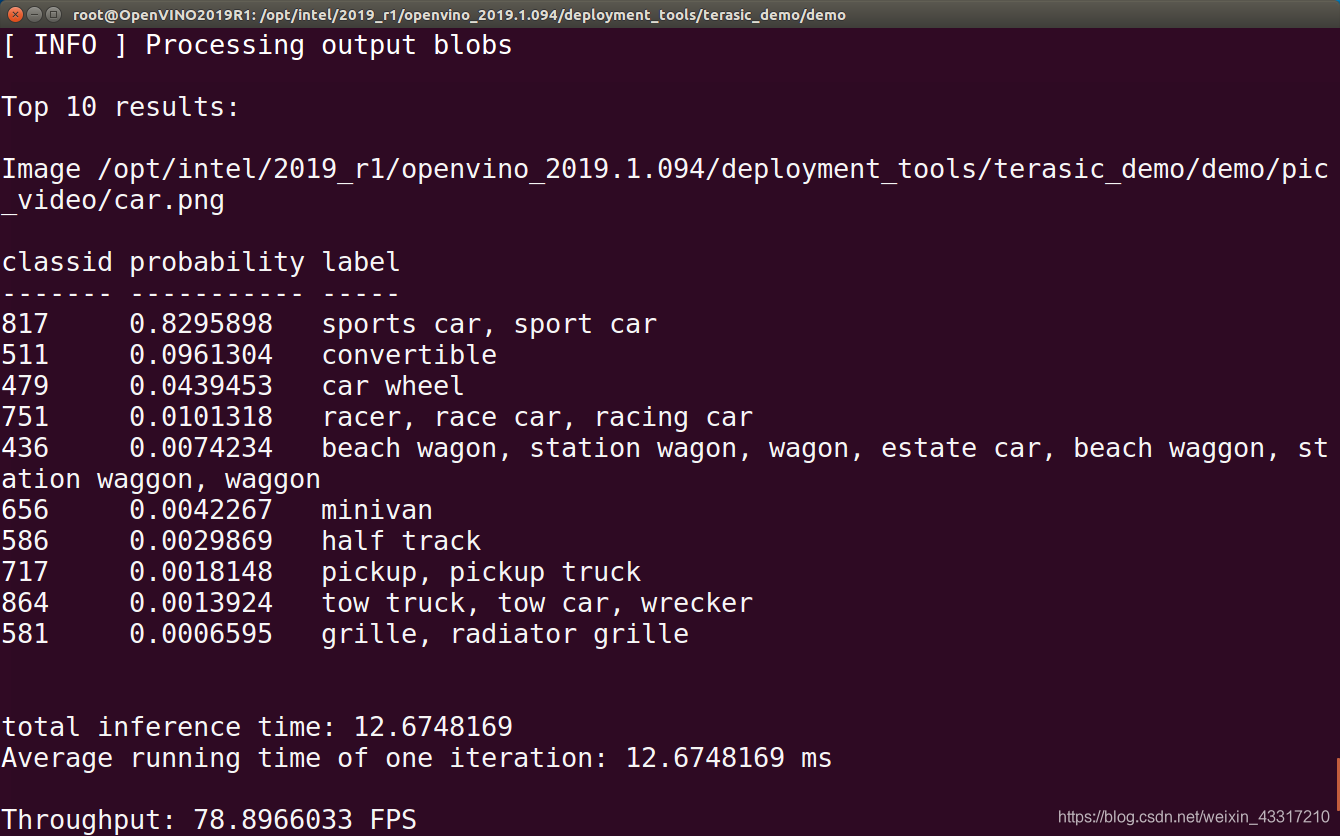
在这个部分中,我们将使用cpu和NCS 2(vpu)分别实现squeezenet的推理,实现对下图的分类

首先,利用OpenVINO将squeezenet 图像分类模型部署在cpu上。
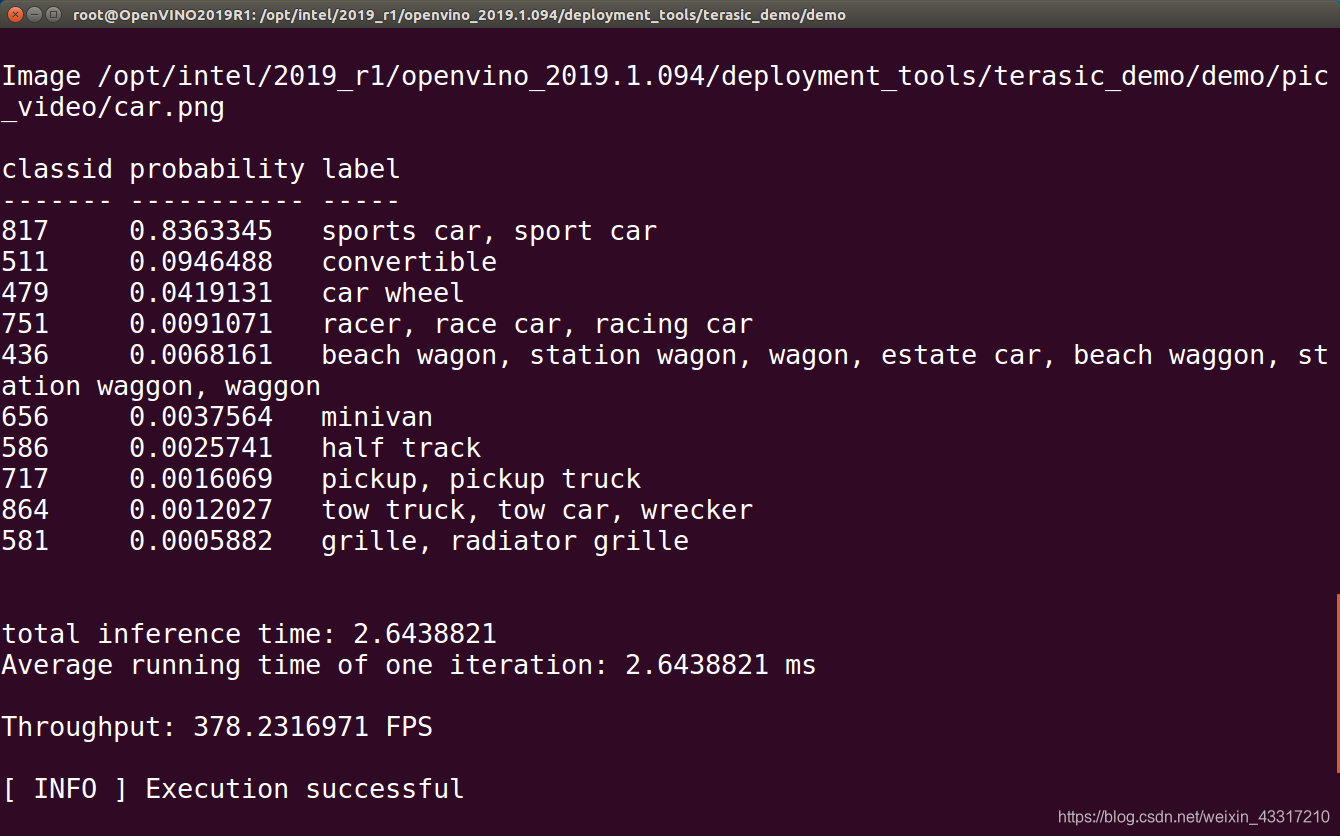
CPU得到的推理结果如下图所示,图片中显示了TOP10分类以及其相应概率,同时可以看到CPU在squeezenet的推理速度非常快,可以达到378.231FPS,远远超过普通应用的需求。
同理,利用OpenVINO将squeezenet 图像分类模型部署在NCS 2(vpu)上。
VPU得到的推理结果如下图所示,图片中显示了TOP10分类以及其相应概率。与CPU的推理结果相比,VPU推理得到的结果与CPU结果的大致相同,但是在具体某种类的概率上有所不同,这是因为CPU推理时,使用的是32位的浮点数,而VPU推理的时候使用的是16位的浮点数,因此在具体的概率值上,可能会有轻微的变化,但是在分类的准确度上不会有太大影响。同时可以看到vpu在squeezenet的推理速度相对cpu较慢,为78.89FPS,仍可以满足绝大多数普通需求。
这一部分将测试车牌识别模型,车牌自动识别系统如今广泛应用于小区,停车场。实现阻止无关车辆,放行登记车辆,自动缴费等功能。模型将对下列图片中的车牌号进行识别和检测

首先,将模型部署在cpu上测试其性能:
测试结果如下图所示:

模型成功识别出来了车牌号“冀 MD711”,推理速度达到77.01FPS,性能有些过剩,远超普通应用的需求。
将模型应用于VPU:
得到的结果如下图所示:

VPU同样正确识别出来了车牌号“冀 MD711”,推理速度达到20.79FPS。可以满足一般应用的需求。
人脸检测模型也是在现实生活中广泛引用的深度学习模型,下面将测试一个人脸检测模型在CPU、VPU上的性能表现。本文测试的模型不仅包含人脸检测,还包括人脸3D模型检测,性别判定,年龄预测,表情判定等,因此总体模型比较复杂,具体应用时可以单独选择一项或几项应用。
首先查看模型部署在CPU上的性能表现:

在CPU上,模型的推理速度依然非常快,可以达到38.14FPS。可见高性能的CPU即使在如此复杂的模型推理中,依然有些性能过剩。
而VPU的测试结果则如下所示:

在VPU上,模型的推理速度减慢为10.79FPS,在实际应用上可能会显得比较慢。这因为测试的模型比较复杂的缘故,实际应用中,可能并不需要人脸3D模型检测,性别判定,年龄预测,表情判定等全部功能,因此对模型进行简化可以加快其推理速度,使模型成功引用与VPU,替代嵌入式设备的控制核心进行深度学习推理任务。
本部分将测试GoogleNetV2物体检测模型在CPU、VPU上的性能表现。
首先看CPU的性能表现:

检测的速度达到:31.72FPS
然后看VPU的表现性能:

检测的速度达到:13.01FPS
这个结果与4.3的测试结果类似,使用CPU检测性能过剩,而使用VPU推理的速度则稍微变慢。这说明在某些较复杂的模型中单独一个NCS 2可能并不能完全胜任深度学习模型的推理工作,可以考虑将推理任务分组由多个NCS 2完成,或者使用NCS 2作为核心推理设备的加速组件用于加快模型推理。
通过以上测试可以得出,Intel推出的NCS 2(VPU)可以作为物联网设备端AI应用的计算核心,胜任诸如图像分类,车牌检测等常用的深度学习模型的推理任务,实现边缘计算的功能。在应用某些较为复杂的模型时,可以使用多个NCS2(VPU)进行协同工作,或者将NCS 2作为核心推理设备的加速组件,加速模型的推理,实现更好的应用。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 3736
3736