查看Pandas版本 对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype) array([ 1.45600438, -0.70753348, 0.48558013, -1.35614791, -0.20220802]) ‘这是一个Series’ Index([‘a’, ‘b’, ‘c’, ‘d’, ‘e’], dtype=‘object’) dtype(‘float64’) 1.4560043774073959 -0.06486097947792556 Series有相当多的方法可以调用: pandas.core.frame.DataFrame pandas.core.series.Series Index([‘一’, ‘二’, ‘三’, ‘四’, ‘五’], dtype=‘object’) Index([‘col1’, ‘col2’, ‘col3’], dtype=‘object’) array([[‘a’, 5, 1.3], (5, 3) col2 7.00 这是Pandas中非常强大的特性,不理解这一特性有时就会造成一些麻烦 对于删除而言,可以使用drop函数或del或pop 一 1 从下面开始,包括后面所有章节,我们都会用到这份虚拟的数据集 nunique显示有多少个唯一值 7 count返回非缺失值元素个数 35 info函数返回有哪些列、有多少非缺失值、每列的类型 describe默认统计数值型数据的各个统计量 idxmax函数返回最大值所在索引,在某些情况下特别适用,idxmin功能类似 5 nlargest函数返回前几个大的元素值,nsmallest功能类似 clip和replace是两类替换函数 clip是对超过或者低于某些值的数进行截断 16.924244897959188 replace是对某些值进行替换 通过字典,可以直接在表中修改 apply是一个自由度很高的函数,在第3章我们还要提到 对于Series,它可以迭代每一列的值操作: 对于DataFrame,它在默认axis=0下可以迭代每一个列操作: https://blog.csdn.net/qq_40317204/article/details/106993293 使用assign添加列的时候,为什么会出现NaN?(提示:索引对齐)assign左右两边的索引不一样,请问结果的索引谁说了算?(内容定位:二-1-f) 【练习一】 现有一份关于美剧《权力的游戏》剧本的数据集,请解决以下问题: (a) 564 (b) 可以得到每个人物的台词数量: 台词最多的人物为: (c) 得到说过单词总数最多的人: **【练习二】**现有一份关于科比的投篮数据集,请解决如下问题: (a) 得到所有的组合及数量: (‘Jump Shot’, ‘Jump Shot’) (b) 得到与所有对手交战次数: ‘SAS’ 部分python函数参考文章: 所用数据集下载连接:
文章目录
import pandas as pd import numpy as nppd.__version__一、文件读取与写入
1.读取
(a)csv格式
df = pd.read_csv(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdatatable.csv') df.head()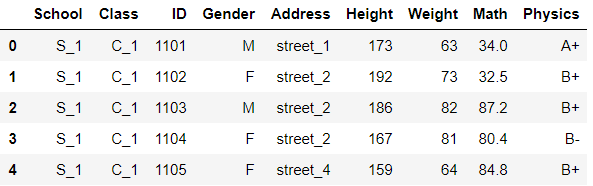
(b)txt格式
df_txt = pd.read_table(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdatatable.txt') #可设置sep分隔符参数 df_txt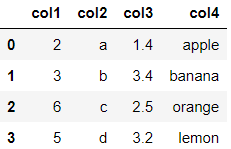
(c)xls或xlsx格式
#需要安装xlrd包 df_excel = pd.read_excel(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdatatable.xlsx') df_excel.head()
2. 写入
(a)csv格式
df.to_csv('data/new_table.csv') #df.to_csv('data/new_table.csv', index=False) #保存时除去行索引(b)xls或xlsx格式
#需要安装openpyxl df.to_excel('data/new_table2.xlsx', sheet_name='Sheet1')二、基本数据结构
1.Series
(a)创建一个Series
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='这是一个Series',dtype='float64') sa 1.456004 b -0.707533 c 0.485580 d -1.356148 e -0.202208 Name: 这是一个Series, dtype: float64(b)访问Series属性
s.valuess.names.indexs.dtype(c)取出某一个元素
s['a'](d)调用方法
s.mean()print([attr for attr in dir(s) if not attr.startswith('_')])['T', 'a', 'abs', 'add', 'add_prefix', 'add_suffix', 'agg', 'aggregate', 'align', 'all', 'any', 'append', 'apply', 'argmax', 'argmin', 'argsort', 'array', 'asfreq', 'asof', 'astype', 'at', 'at_time', 'attrs', 'autocorr', 'axes', 'b', 'between', 'between_time', 'bfill', 'bool', 'c', 'clip', 'combine', 'combine_first', 'convert_dtypes', 'copy', 'corr', 'count', 'cov', 'cummax', 'cummin', 'cumprod', 'cumsum', 'd', 'describe', 'diff', 'div', 'divide', 'divmod', 'dot', 'drop', 'drop_duplicates', 'droplevel', 'dropna', 'dtype', 'dtypes', 'duplicated', 'e', 'empty', 'eq', 'equals', 'ewm', 'expanding', 'explode', 'factorize', 'ffill', 'fillna', 'filter', 'first', 'first_valid_index', 'floordiv', 'ge', 'get', 'groupby', 'gt', 'hasnans', 'head', 'hist', 'iat', 'idxmax', 'idxmin', 'iloc', 'index', 'infer_objects', 'interpolate', 'is_monotonic', 'is_monotonic_decreasing', 'is_monotonic_increasing', 'is_unique', 'isin', 'isna', 'isnull', 'item', 'items', 'iteritems', 'keys', 'kurt', 'kurtosis', 'last', 'last_valid_index', 'le', 'loc', 'lt', 'mad', 'map', 'mask', 'max', 'mean', 'median', 'memory_usage', 'min', 'mod', 'mode', 'mul', 'multiply', 'name', 'nbytes', 'ndim', 'ne', 'nlargest', 'notna', 'notnull', 'nsmallest', 'nunique', 'pct_change', 'pipe', 'plot', 'pop', 'pow', 'prod', 'product', 'quantile', 'radd', 'rank', 'ravel', 'rdiv', 'rdivmod', 'reindex', 'reindex_like', 'rename', 'rename_axis', 'reorder_levels', 'repeat', 'replace', 'resample', 'reset_index', 'rfloordiv', 'rmod', 'rmul', 'rolling', 'round', 'rpow', 'rsub', 'rtruediv', 'sample', 'searchsorted', 'sem', 'set_axis', 'shape', 'shift', 'size', 'skew', 'slice_shift', 'sort_index', 'sort_values', 'squeeze', 'std', 'sub', 'subtract', 'sum', 'swapaxes', 'swaplevel', 'tail', 'take', 'to_clipboard', 'to_csv', 'to_dict', 'to_excel', 'to_frame', 'to_hdf', 'to_json', 'to_latex', 'to_list', 'to_markdown', 'to_numpy', 'to_period', 'to_pickle', 'to_sql', 'to_string', 'to_timestamp', 'to_xarray', 'transform', 'transpose', 'truediv', 'truncate', 'tshift', 'tz_convert', 'tz_localize', 'unique', 'unstack', 'update', 'value_counts', 'values', 'var', 'view', 'where', 'xs']2.DataFrame
(a)创建一个DataFrame
df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]}, index=list('一二三四五')) df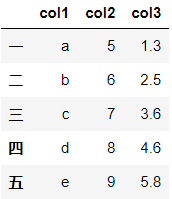
(b)从DataFrame取出一列为Series
df['col1']一 1.3 二 2.5 三 3.6 四 4.6 五 5.8 Name: col3, dtype: float64type(df)type(df['col3'])(c)修改行或列名
df.rename(index={'一':'1'},columns={'col1':'第一列'})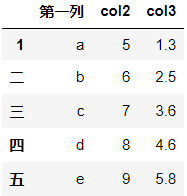
(d)调用属性和方法
df.indexdf.columnsdf.values
[‘b’, 6, 2.5],
[‘c’, 7, 3.6],
[‘d’, 8, 4.6],
[‘e’, 9, 5.8]], dtype=object)df.shapedf.mean() #本质上是一种Aggregation操作,将在第3章详细介绍
col3 3.56
dtype: float64(e)索引对齐特性
df1 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3]) df2 = pd.DataFrame({'A':[1,2,3]},index=[3,1,2]) df1-df2 #由于索引对齐,因此结果不是0
(f)列的删除与添加
df.drop(index='五',columns='col1') #设置inplace=True后会直接在原DataFrame中改动
df['col1']=[1,2,3,4,5] del df['col1'] df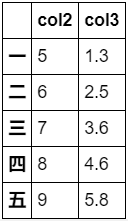
pop方法直接在原来的DataFrame上操作,且返回被删除的列,与python中的pop函数类似df['col1']=[1,2,3,4,5] df.pop('col1')
二 2
三 3
四 4
五 5
Name: col1, dtype: int64df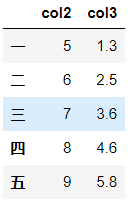
可以直接增加新的列,也可以使用assign方法df1['B']=list('abc') df1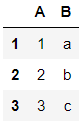
df1.assign(C=pd.Series(list('def'))) #思考:为什么会出现NaN?(提示:索引对齐)assign左右两边的索引不一样,请问结果的索引谁说了算?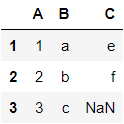
但assign方法不会对原DataFrame做修改(g)根据类型选择列
df.select_dtypes(include=['number']).head()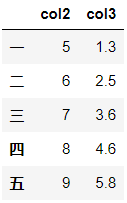
df.select_dtypes(include=['float']).head()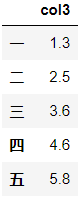
(h)将Series转换为DataFrame
# 此部操作之后,s成为一series s = df.mean() s.name='to_DataFrame' scol2 7.00 col3 3.56 Name: to_DataFrame, dtype: float64# 将s,转换成dataframe s.to_frame()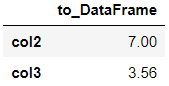
使用T符号可以转置s.to_frame().T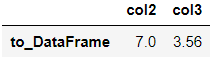
三、常用基本函数
df = pd.read_csv(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdatatable.csv')1.head和tail
df.head()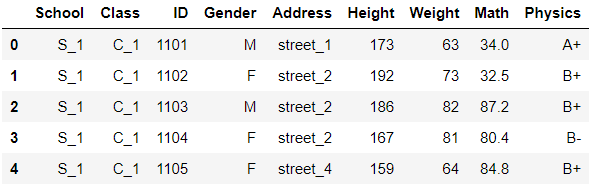
df.tail()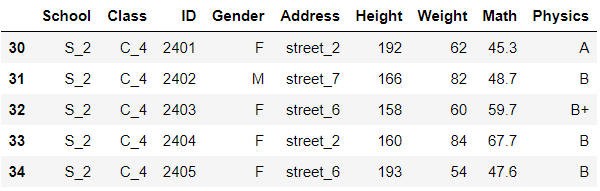
可以指定n参数显示多少行df.head(2)
2.unique和nunique
df['Physics'].nunique()
unique显示所有的唯一值df['Physics'].unique()array(['A+', 'B+', 'B-', 'A-', 'B', 'A', 'C'], dtype=object)3.count和value_counts
df['Physics'].count()
value_counts返回每个元素有多少个df['Physics'].value_counts()B+ 9 B 8 B- 6 A 4 A- 3 A+ 3 C 2 Name: Physics, dtype: int644.describe和info
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 35 entries, 0 to 34 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 School 35 non-null object 1 Class 35 non-null object 2 ID 35 non-null int64 3 Gender 35 non-null object 4 Address 35 non-null object 5 Height 35 non-null int64 6 Weight 35 non-null int64 7 Math 35 non-null float64 8 Physics 35 non-null object dtypes: float64(1), int64(3), object(5) memory usage: 2.6+ KBdf.describe()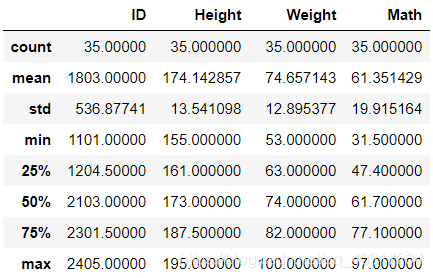
可以自行选择分位数df.describe(percentiles=[.05, .25, .75, .95])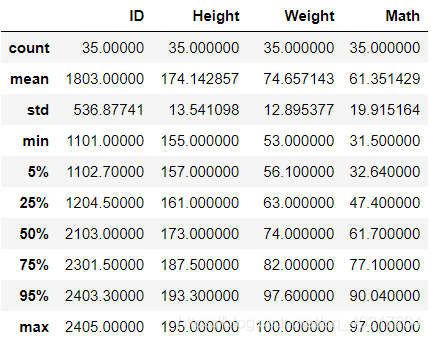
对于非数值型也可以用describe函数df['Physics'].describe()count 35 unique 7 top B+ freq 9 Name: Physics, dtype: object5.idxmax和nlargest
df['Math'].idxmax()df['Math'].nlargest(3)5 97.0 28 95.5 11 87.7 Name: Math, dtype: float646.clip和replace
df['Math'].head()0 34.0 1 32.5 2 87.2 3 80.4 4 84.8 Name: Math, dtype: float64df['Math'].clip(33,80).head()0 34.0 1 33.0 2 80.0 3 80.0 4 80.0 Name: Math, dtype: float64df['Math'].mad()df['Address'].head()0 street_1 1 street_2 2 street_2 3 street_2 4 street_4 Name: Address, dtype: objectdf['Address'].replace(['street_1','street_2'],['one','two']).head()0 one 1 two 2 two 3 two 4 street_4 Name: Address, dtype: objectdf.replace({'Address':{'street_1':'one','street_2':'two'}}).head()
7.apply函数
df['Math'].apply(lambda x:str(x)+'!').head() #可以使用lambda表达式,也可以使用函数0 34.0! 1 32.5! 2 87.2! 3 80.4! 4 84.8! Name: Math, dtype: objectdf.apply(lambda x:x.apply(lambda x:str(x)+'!')).head() #这是一个稍显复杂的例子,有利于理解apply的功能
对于Pandas中axis参数的理解如下:四、排序
1.索引排序
df.set_index('Math').head() #set_index函数可以设置索引,将在下一章详细介绍
df.set_index('Math').sort_index().head() #可以设置ascending参数,默认为升序,True
2.值排序
df.sort_values(by='Class').head()
多个值排序,即先对第一层排,在第一层相同的情况下对第二层排序df.sort_values(by=['Address','Height']).head()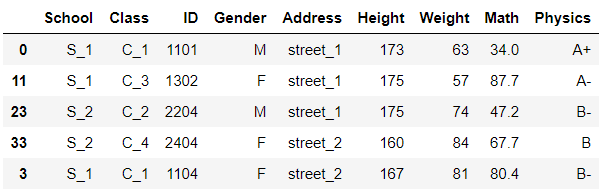
五、问题与练习
1. 问题
2. 练习
(a)在所有的数据中,一共出现了多少人物?
(b)以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
(c)以单词计数,谁说了最多的单词?(不是单句单词最多,是指每人说过单词的总数最多,为了简便,只以空格为单词分界点,不考虑其他情况)pd.read_csv(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdataGame_of_Thrones_Script.csv').head()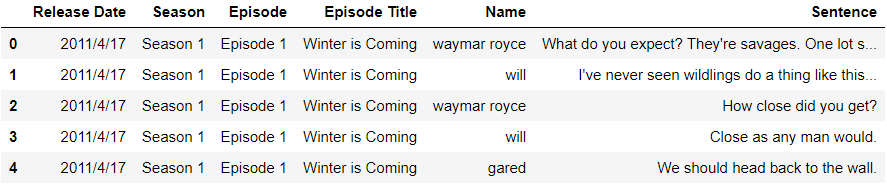
df['Name'].nunique()df['Name'].value_counts()tyrion lannister 1760 jon snow 1133 daenerys targaryen 1048 cersei lannister 1005 jaime lannister 945 ... night watch stable boy 1 tell me something 1 little sam 1 ser vance 1 allister 1 Name: Name, Length: 564, dtype: int64df['Name'].value_counts().index[0]'tyrion lannister'df_words = df.assign(Words=df['Sentence'].apply(lambda x:len(x.split()))).sort_values(by='Name') df_words.head()
L_count = [] N_words = list(zip(df_words['Name'],df_words['Words'])) for i in N_words: if i == N_words[0]: L_count.append(i[1]) last = i[0] else: L_count.append(L_count[-1]+i[1] if i[0]==last else i[1]) last = i[0] df_words['Count']=L_count df_words['Name'][df_words['Count'].idxmax()]'tyrion lannister'
(a)哪种action_type和combined_shot_type的组合是最多的?
(a)在所有被记录的game_id中,遭遇到最多的opponent是一个支?(由于一场比赛会有许多次投篮,但对阵的对手只有一个,本题相当于问科比和哪个队交锋次数最多)df = pd.read_csv(r'C:UserschenyiqunDesktopjoyful-pandas-masterjoyful-pandas-masterdataKobe_data.csv',index_col='shot_id') df.head()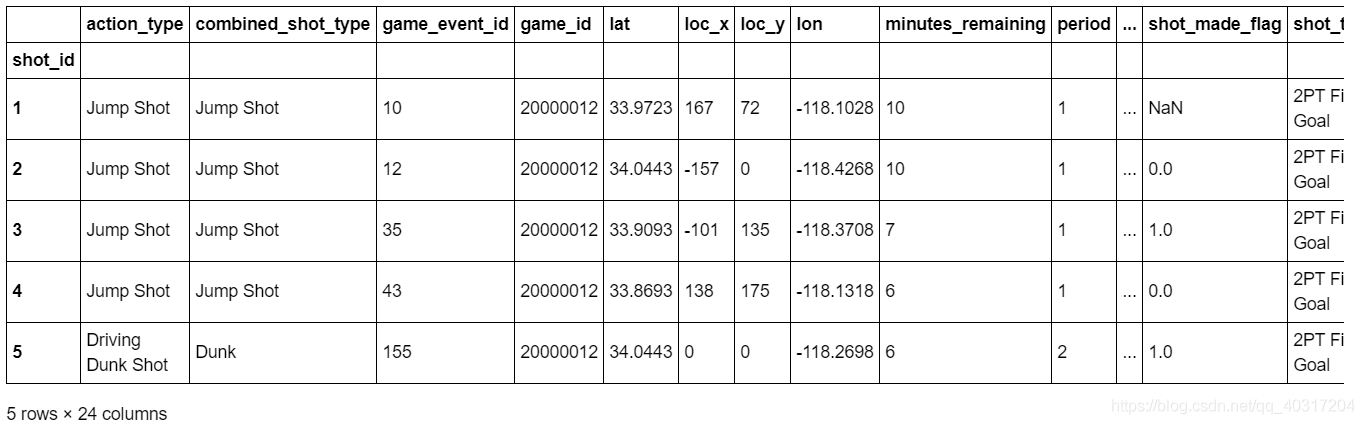
pd.Series(list(zip(df['action_type'],df['combined_shot_type']))).value_counts()(Jump Shot, Jump Shot) 18880 (Layup Shot, Layup) 2567 (Driving Layup Shot, Layup) 1978 (Turnaround Jump Shot, Jump Shot) 1057 (Fadeaway Jump Shot, Jump Shot) 1048 (Running Jump Shot, Jump Shot) 926 (Pullup Jump shot, Jump Shot) 476 (Turnaround Fadeaway shot, Jump Shot) 439 (Slam Dunk Shot, Dunk) 411 (Reverse Layup Shot, Layup) 395 (Jump Bank Shot, Jump Shot) 333 (Driving Dunk Shot, Dunk) 310 (Dunk Shot, Dunk) 262 (Tip Shot, Tip Shot) 182 (Alley Oop Dunk Shot, Dunk) 122 (Step Back Jump shot, Jump Shot) 118 (Floating Jump shot, Jump Shot) 114 (Driving Reverse Layup Shot, Layup) 97 (Hook Shot, Hook Shot) 84 (Driving Finger Roll Shot, Layup) 82 (Alley Oop Layup shot, Layup) 80 (Reverse Dunk Shot, Dunk) 75 (Running Layup Shot, Layup) 72 (Turnaround Bank shot, Bank Shot) 71 (Driving Finger Roll Layup Shot, Layup) 69 (Driving Slam Dunk Shot, Dunk) 48 (Running Bank shot, Bank Shot) 48 (Running Hook Shot, Hook Shot) 41 (Finger Roll Layup Shot, Layup) 33 (Fadeaway Bank shot, Jump Shot) 31 (Finger Roll Shot, Layup) 28 (Driving Jump shot, Jump Shot) 28 (Jump Hook Shot, Jump Shot) 24 (Running Dunk Shot, Dunk) 19 (Reverse Slam Dunk Shot, Dunk) 16 (Putback Layup Shot, Layup) 15 (Follow Up Dunk Shot, Dunk) 15 (Driving Hook Shot, Hook Shot) 14 (Turnaround Hook Shot, Hook Shot) 14 (Pullup Bank shot, Bank Shot) 12 (Running Reverse Layup Shot, Layup) 11 (Cutting Layup Shot, Layup) 6 (Running Finger Roll Layup Shot, Layup) 6 (Driving Bank shot, Bank Shot) 5 (Hook Bank Shot, Bank Shot) 5 (Putback Dunk Shot, Dunk) 5 (Driving Floating Jump Shot, Jump Shot) 5 (Running Finger Roll Shot, Layup) 4 (Running Pull-Up Jump Shot, Jump Shot) 4 (Tip Layup Shot, Layup) 2 (Running Tip Shot, Tip Shot) 2 (Putback Slam Dunk Shot, Dunk) 2 (Turnaround Finger Roll Shot, Layup) 2 (Cutting Finger Roll Layup Shot, Layup) 1 (Driving Floating Bank Jump Shot, Jump Shot) 1 (Turnaround Fadeaway Bank Jump Shot, Jump Shot) 1 (Running Slam Dunk Shot, Dunk) 1 dtype: int64pd.Series(list(zip(df['action_type'],df['combined_shot_type']))).value_counts().index[0]pd.Series(list(list(zip(*(pd.Series(list(zip(df['game_id'],df['opponent']))) .unique()).tolist()))[1])).value_counts()SAS 91 PHX 87 UTA 84 DEN 83 POR 81 SAC 80 HOU 77 MIN 76 LAC 68 GSW 67 DAL 64 MEM 49 BOS 44 SEA 44 IND 39 DET 38 PHI 37 ORL 34 NYK 34 CLE 34 OKC 33 TOR 33 WAS 32 MIA 32 MIL 31 CHA 31 NOH 31 CHI 31 ATL 29 NJN 28 VAN 18 NOP 16 BKN 3 dtype: int64 pd.Series(list(list(zip(*(pd.Series(list(zip(df['game_id'],df['opponent']))) .unique()).tolist()))[1])).value_counts().index[0]
Python zip() 函数解析
Python split()函数解析
https://download.csdn.net/download/qq_40317204/12568932
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 232
232