该系列专栏上一篇爬虫文章点击这里。 网站复杂度增加,爬虫编写的方式也会随着增加。使用Selenium 可以通过简单的方式抓取复杂的网站页面,得到想要的信息。 Selenium 是操作浏览器进行自动化,例如自动化访问网站,点击按钮,进行信息采集,对比直接使用bs4 抓取信息,Selenium的抓取速度是有很大缺陷,但是如果抓取页面不多,页面复杂时,使用Selenium是个不错的选择。 在使用 Selenium前需要安装 Selenium,使用pip命令,安装如下: 安装完成 Selenium 还需要下载一个驱动。 作者的环境说明如下: 下载好驱动后,必须把驱动给配置到系统环境,或者丢到你python的根目录下。 首先在代码中引入 selenium 可能有些读者没有把驱动配置到环境中,接下来我们可以指定驱动的位置: 以上代码调用Chrome 方法并且配置驱动地址( 成功打开百度搜索界面: 这时还差向该对象输入要搜索的值。使用 send_keys 方法可以自动键入值,编写如下: 其中input是刚刚获取的元素对象。这时运行代码查看效果: 得到id为su,使用 find_element_by_id 得到元素对象: 该元素调用click方法即可进行点击: 最终代码如下: 运行结果如下: 能够进行自动打开了,下一步接下来需要做的就是获取搜索的信息。 如下图,我们右键搜索出来了信息第一个标题,点击检查后会出现源代码。在源代码中右键,选择Copy之后点击Copy XPath,这时我们就把当前这个元素的XPath获取了。 在这里注意,理论上每一个页面的第一行结果都将会是该XPath,并不需要每一页都去获取,但也有情况不一致的时候,具体情况得具体分析。 获取到元素对象后,可以调用该元素对象的text属性获取到当前文本值: 完整代码如下: 以上代码中 则获取下一页对象并且点击跳转的代码为: 运行后发现成功跳转到第二页,接下来可以继续获取搜索栏的第一个对象,可以使用循环实现这个过程,我们设定去搜索前10页的所有第一个结果值,这时所有代码可以写为: for 循环最下面的停止2秒是为了点击下一页后数据进行加载的等待时间。 那么在这里应该是 从以上数据得知,只有第一页的XPath 不同,其它的XPath都遵循从11-21-31-41 每一页加10的规律。 完整代码如下: 以上代码中: 为之前的代码,新增循环为遍历下一页以及获取第一个结果: 首先设置一个start,因为第二页是 XPath 中变化的值为11-21-31…,设置一个变量为1,每次加10即可,所以在循环中,第一句为: 由于XPath的值其它字符串没变化,所以整一条XPath语句可以写为: 之后传入xpath函数获取元素即可: 接下来的语句都没有太大变化,只有按钮的XPath有变化,所以更改了XPath。其它代码均和之前的相似。最终运行结果如下:
Selenium 简介
本文将会使用Selenium 进行一些简单的抓取,想要深入学习Selenium 可以查看我之前写过的 《selenium3 底层剖析》 上 下 两篇。Selenium 使用注意
pip install selenium
GitHub火狐驱动下载地址
下载(英文不好的同学右键一键翻译即可,每个版本都有对应浏览器版本的使用说明,看清楚下载即可)
正式开始
from selenium import webdriver driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') 这里使用 executable_path 指定驱动地址)为“F:pythondrchromedriver_win32chromedriver.exe”,这时就可以指定了驱动位置,也可以不用配置到环境了。
这时运行一下代码,查看是否会打开一个浏览器。
这时将会成功打开谷歌浏览器。
这时 driver 变量为浏览器对象,通过 driver 操作浏览器,使用get方法可以访问一个网址。这时我们可以访问 百度。代码如下:from selenium import webdriver driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://baidu.com")
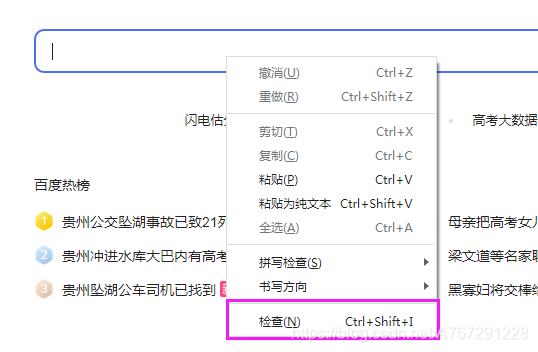
例如我们想搜索爬虫,使用selenium实现自动搜索。首先需要了解的一个函数为 find_element_by_id,该函数可以通过id 找到界面元素。在html中,大部分有特殊作用的元素会赋予一个id,搜索时需要填写的是百度搜索关键字的文本框,将鼠标移动到文本框,对准文本框点击鼠标右键,点击检查可以查看元素。
点击检查后将会出现一个源码窗口:
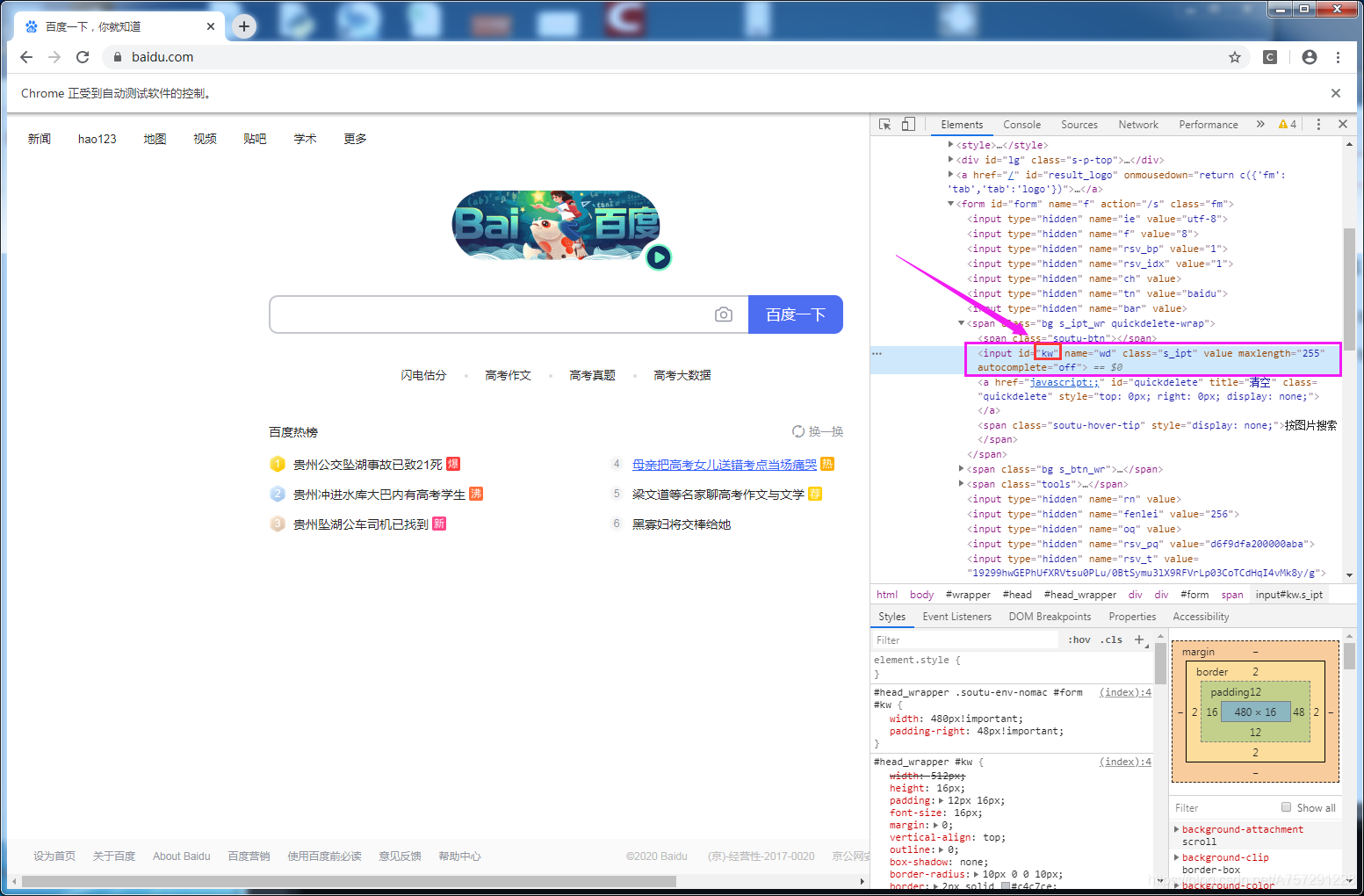
其中input为文本框元素,id的值是 kw。
这时得知了文本框的id 值为kw,可以使用 find_element_by_id 函数给予id值,找到元素对象,并且可以操作元素对象进行增删操作。由于 find_element_by_id 是浏览器对象的方法,使用浏览器对象调用,代码如下:input = driver.find_element_by_id('kw') input.send_keys("爬虫")
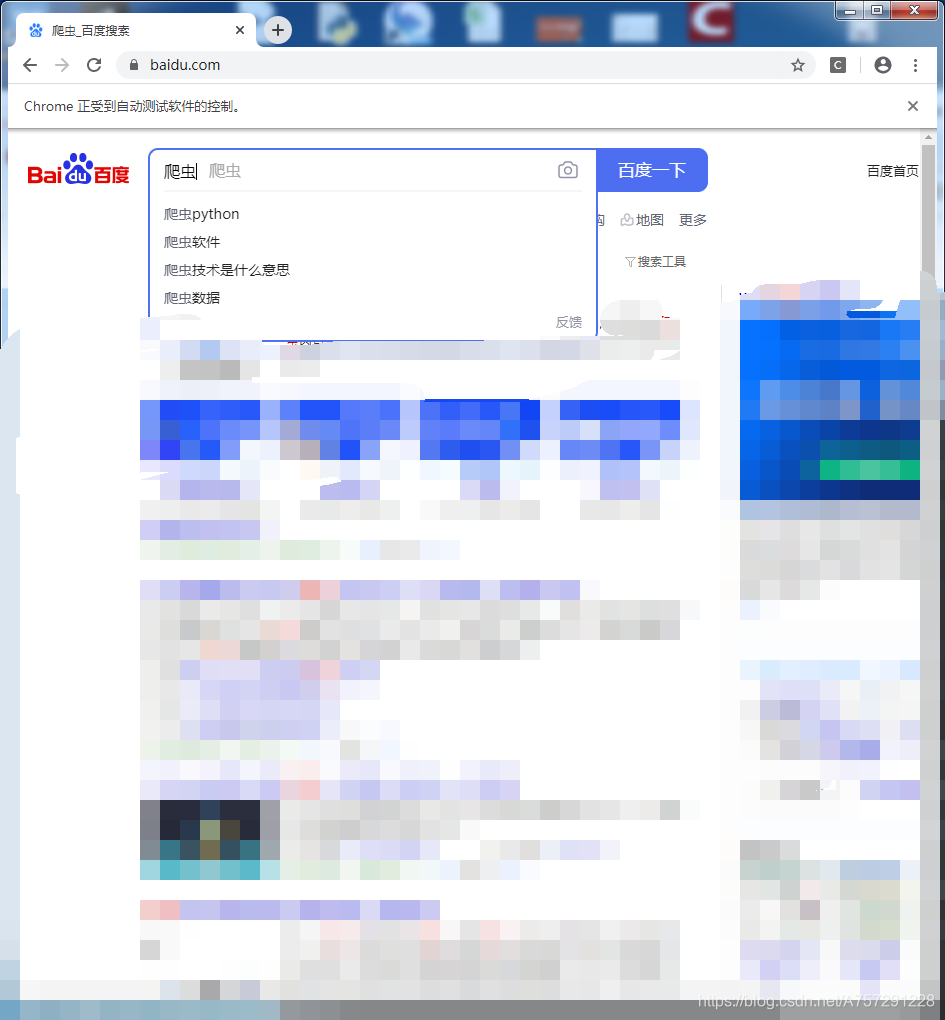
这时自动键入了要搜索的关键帧“爬虫”。接下来根据之前的步骤,应该找到 百度一下 按钮的id,随后点击即可。通过相同的流程,得到百度一下 按钮的html代码:<input type="submit" id="su" value="百度一下" class="bg s_btn"> enter = driver.find_element_by_id('su') enter.click() from selenium import webdriver driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://www.baidu.com/") input = driver.find_element_by_id('kw') input.send_keys("爬虫") enter = driver.find_element_by_id('su') enter.click()
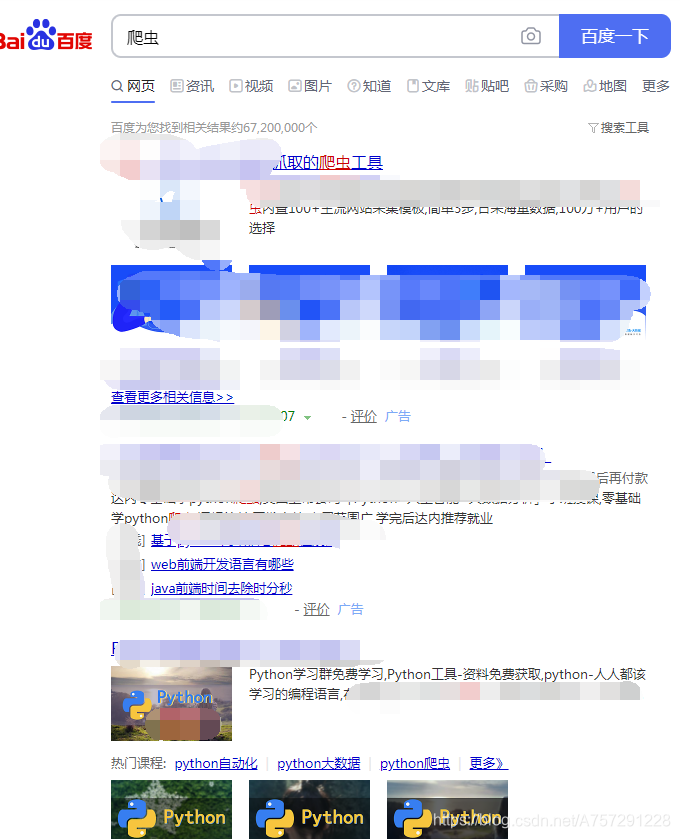
信息获取
在这里需要介绍一个知识点 xpath,我们可以理解xpath就像 x,y坐标一样的东西,用于html或者说xml语言中的定位,表示一个位置。简单的使用并不需要去学习它如何编写,因为从浏览器中我们可以直接得到。
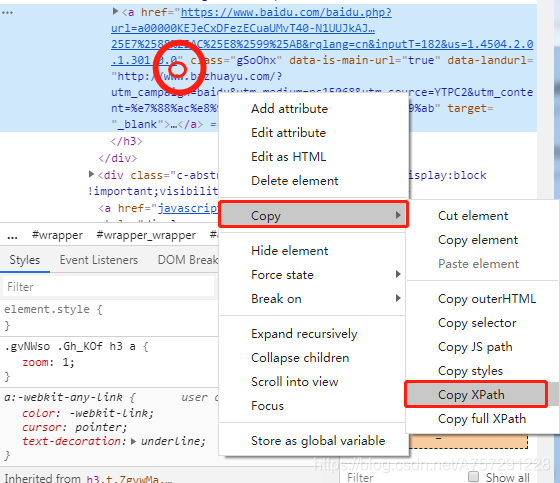
获取到了XPath后,复制到文本框,查看是如下形式://*[@id="3001"]/div[1]/h3/a
我们简单实用XPath不需要了解过多,接下来可以使用 find_element_by_xpath 获取到当前元素对象。res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') print(res_element.text) from selenium import webdriver import time driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://www.baidu.com/") input = driver.find_element_by_id('kw') input.send_keys("爬虫") enter = driver.find_element_by_id('su') enter.click() time.sleep(2) res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') print(res_element.text) time.sleep(2) 是为了等待点击搜索后页面加载数据,不然会获取不到对象。
结果如下:

以上省略了浏览器自动打开并搜索内容的过程,直接查看了结果。
那么我们每一页都获取第一个结果,这时只需要自动点击下一页后获取即可。
首先得到下一页按钮的元素对象:

复制XPath值为://*[@id="page"]/div/a[10] nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[10]') nextbtn_element.click() from selenium import webdriver import time driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://www.baidu.com/") input = driver.find_element_by_id('kw') input.send_keys("爬虫") enter = driver.find_element_by_id('su') enter.click() time.sleep(2) for _ in range(10): res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') print(res_element.text) nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[10]') nextbtn_element.click() time.sleep(2)
运行后,结果发现报错:
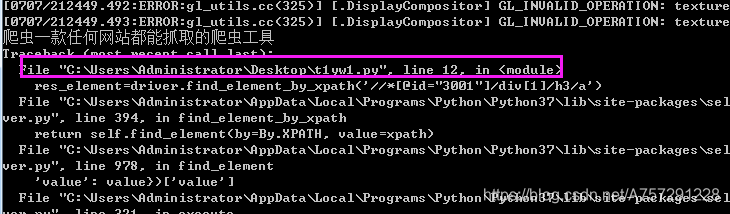
我们的12行为:res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') //*[@id="3001"]/div[1]/h3/a 定位错误,没有找到该定位的元素。我们查看第一页、第二页、第三页的第一条结果进行对比:第一页://*[@id="3001"]/div[1]/h3/a 第二页://*[@id="11"]/h3/a 第三页://*[@id="21"]/h3/a 第四页://*[@id="31"]/h3/a 第五页://*[@id="41"]/h3/a
并且发现下一页按钮的 XPath也发生了改变,变成了://*[@id="page"]/div/a[11] from selenium import webdriver import time #请求网页 driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://www.baidu.com/") #输入并且搜索 input = driver.find_element_by_id('kw') input.send_keys("爬虫") enter = driver.find_element_by_id('su') enter.click() #等待2秒加载 time.sleep(2) #获取第一个结果并且点击下一页 res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') print(res_element.text) nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[10]') nextbtn_element.click() time.sleep(2) #设置一个变量start start=1 #循环点击下一页 并且获取第一条数据 for _ in range(10): start+=10 xpath_val=r'//*[@id="'+str(start)+r'"]/h3/a' #//*[@id="11"]/h3/a res_element=driver.find_element_by_xpath(xpath_val) print(res_element.text) nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[11]')#//*[@id="page"]/div/a[11] //*[@id="page"]/div/a[11] nextbtn_element.click() time.sleep(2) from selenium import webdriver import time #请求网页 driver = webdriver.Chrome(executable_path=r'F:pythondrchromedriver_win32chromedriver.exe') driver.get("https://www.baidu.com/") #输入并且搜索 input = driver.find_element_by_id('kw') input.send_keys("爬虫") enter = driver.find_element_by_id('su') enter.click() #等待2秒加载 time.sleep(2) #获取第一个结果并且点击下一页 res_element=driver.find_element_by_xpath('//*[@id="3001"]/div[1]/h3/a') print(res_element.text) nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[10]') nextbtn_element.click() time.sleep(2) #设置一个变量start start=1 #循环点击下一页 并且获取第一条数据 for _ in range(10): start+=10 xpath_val=r'//*[@id="'+str(start)+r'"]/h3/a' #//*[@id="11"]/h3/a res_element=driver.find_element_by_xpath(xpath_val) print(res_element.text) nextbtn_element=driver.find_element_by_xpath('//*[@id="page"]/div/a[11]')#//*[@id="page"]/div/a[11] //*[@id="page"]/div/a[11] nextbtn_element.click() time.sleep(2) start+=10 xpath_val=r'//*[@id="'+str(start)+r'"]/h3/a' res_element=driver.find_element_by_xpath(xpath_val)
由于有一些其它信息所以打码了,这就是一个简单的selenium爬虫编写方式,之后将会持续更新爬虫系列。
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









