题目中有个顶级,忽然觉得这篇博客要弄的高大上一些,要不都对不起标题呢? 上篇博客,我们已经将分布式需要配置的一些基本环境已经配置完毕,接下来就是实操环节了,这部分尽量将过程描述清晰,由于我操作的是windows操作系统,所以博客中相关步骤的截图都已windows为准。 对于分布式爬虫初学阶段,先从scrapy简单爬虫写起即可。 为了测试方便,我找了一个规则比较简单的网址,ImapBox下载频道 通过scrapy创建一个基本的爬虫,关于如何创建,本文不再涉及,可翻阅之前文章即可,注意,因为我电脑安装scrapy多个,并且本项目采用了虚拟环境,所以scrapy中添加了完整路径。
写在前面
scrapy爬取ImapBox下载频道
https://download.csdn.net/ ,该网址对应的数据可以通过https://download.csdn.net/home/get_more_latest_source?page=2 修改URL中参数page的值即可以不断获取数据,非常贴心。创建爬虫
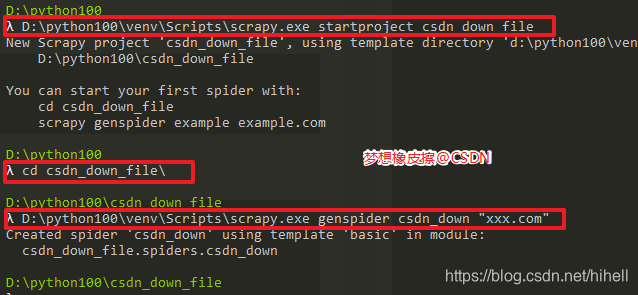
通过命令创建完毕,即可进入编码环节
修改settin
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










