首先:附上Github传送门:https://github.com/CVUsers/Smoke-Detect-by-YoloV5/tree/master,然后根据本文手把手配置环境+训练自己数据,或者使用我训练好的模型进行使用。用yolov5s训练好的已经放在了里面,用大模型训练的由于大小原因,需要的话可以戳最下方微信私聊我,免费。 左图为原图,右图为推理后的图片,以图片方式展示,视频流和实时流也能达到这个效果,由于视频大小原因,暂不上传,感兴趣的朋友细细往下看,并点个关注哟! 测试配置:GTX1050ti,不堪入目,但是实验效果还不错,再这样弱的配置下,使用YOLOv5s,YOlov5m等皆能达到30fps。 香烟图片:自己编写爬虫爬了1w张,筛选下来有近1000张可用,以及其他途径获取到的,总共暂时5k张,未来会越来越多,后续需要的可以私聊我,现在先放出5k张图片,另外加上自己辛辛苦苦使用Labelimg标注的几千张图片的XML文件也一并送上,香烟图片质量可查传送门:链接:https://pan.baidu.com/s/1t8u94x51TO7pLciU8AoaiQ 吸烟手势图片: 火灾+烟雾数据集: 这个数据集我已经有了10万左右数据,部分是朋友的,不知能不能开源,我可以送上自己收集的几万数据集。传送门: 项目框架:YOLOV5——Pytorch实现 送上作者源码传送门:https://github.com/ultralytics/yolov5,当然也可以直接使用我的:https://github.com/CVUsers/Smoke-Detect-by-YoloV5/tree/master。 标注工具:Labelimg 附上Windows工具:在我上面的github里面有哟:下载好放置桌面比较方便。 本例以使用YOLov5作者源码步骤: 我的是torch 1.5 gpu版 在git clone下作者的v5源码后: 目录切至requirement.txt 下然后 如果需要使用混合精度模型来做训练:安装Apex 以吸烟数据集为例: 在百度网盘下载好我的数据集和XML 若是想重新训练的话 标注好会生成XML文件:XML里面包含了四个点坐标和图片的名字与size。 然后在data下新建几个文件夹: 将我们的XML文件放至Annotations 将我们的图片放到images 在ImageSets中新建Main 和test.txt 和train.txt 再新建labels存放接下来生成的标签 第一个:XML文件转label.txt文件 首先写个os操作读一下data/images中图片:这个几行搞定,要注意要写成我这样的哟 (不用生成.jpg)可以通过split(’.’)再复制到ImageXML中 然后运行voc_label.py脚本: 需要注意,若是有中文路径的话,请这样读文件: 接下来就会在data/labels中看到:所有的txt标签 每个txt文本会生成一共5个数字:第一个是整形的数,表示类别:0代表第一类,以此类推,后面四个数字是坐标通过归一化后的表示。 执行train_test_split.py 其中trainval_percent = 1表示验证集比例,1代表1:9 如果有5000张图片,就会切割成4500张训练集,和500张验证集。 运行path_trans补全路径,并写入train.txt 接下来编写yaml文本: 将我们上一步生成的train.txt 和test.txt 补全路径后的这两个txt路径写入到yaml中,然后nc:修改为自己类别的数量,以及names【‘smoke’】 在上面我们做好数据预处理后,就可以开始训练了,上面的一些处理步骤,每个人都可能不同,不过大体上思路是一致的。 接下来我们可以进行预训练,下载官方的预训练模型: 当然也可以不使用预训练模型,使用与否,在总时间上是差不多的,不过 为什么要使用预训练模型? 作者已尽其所能设计了基准模型。我们可以在自己的数据集上使用预训练模型,而不是从头构建模型来解决类似的自然语言处理问题。 尽管仍然需要进行一些微调,但它已经为我们节省了大量的时间:通常是每个损失下降更快和计算资源节省。 加快梯度下降的收敛速度 更有可能获得一个低模型误差,或者低泛化误差的模型 降低因未初始化或初始化不当导致的梯度消失或者梯度爆炸问题。此情况会导致模型训练速度变慢,崩溃,直至失败。 其中随机初始化,可以打破对称性,从而保证不同的隐藏单元可以学习到不同的东西 接下来开始训练: 解释一下: 我们–data data/smoke.yaml 中就是在smoke.yaml中撰写的训练代码路径和类别等data,通过这个获取训练的图片和label标签等。 然后-cfg models/yolov5s.yaml 和 –weights weights/yolov5s.pt是获取配置和预训练模型权重 batch-size 10 大家都懂,default是16,大家可以改成16,在yolov5s中模型参施不多,百万左右,所以显存消耗不多,我的配置很差,显存4g,在使用yolov5m中以及不能调到16。 会报cuda out of memory 报错,就把batch size降低就行。 然后最后是epoch,这个也不用解释,我在使用yolov5m训练5k张图片在100epoch中花费 了24小时,一个epoch13分钟。 训练过程中,会慢慢在runs中生成tensorboard,可视化损失下降 当然也可以在本地稍微看看: 这幅图中,我们的类别只有1个,第三幅图显示了我们数据中的宽高比,归一化后,普遍在0.1左右,说明数据确实很小,也会面临模糊问题,导致数据质量降低。 分别是epoch,显存消耗…其他的大家可以查看源码 使用混合精度模型 在前面配置好环境后: 判断是否可用apex做混合精度模型训练 然后 在optimizer中amp初始化一下 o1代表级别,注意是欧 不是零。 接着: 优化反向传播。 组装到cuda训练 详情参见注释。 其中,推理一张图片,那么就在–source中的default写上图片路径, 也可以如图写上整个图片文件夹,这样会检测所有图片。 也可以写上视频地址和视频文件夹,检测所有视频,存放于inference 的out中。 改成0 就是实时检测了~默认电脑摄像头,当然也可以改成手机。这个也很简单,需要的可以私聊我,微信会放在最下方。 帧率很高,普通设备也能达到30+,可谓是速度极快,要是大家设备好一些,可以试一下YOLOv5L和YOLOV5x,跑完了可以私聊一下,与我交流。 类别100类 每类300张图片 测试图片1087张,阀值0.5 ,预测正确 预测结果 737 954 955 模型大小 33.97M 246.19M 28.99M(yolov5s.pt) yolov5s的精度和yolov4差不多,但模型大小只有yolov4的11.77%(个人数据集,数据可能有点偏差,但还是能说明问题的) 实时对比 附上视频:https://www.bilibili.com/video/av328439400/ 这篇文章大致介绍了yolov5的自训练,接下来我们可以进行调优。已经做消融对比实验,慢慢的更熟悉目标检测。继续我会在下篇中介绍文中的一些技术栈,让大家知根知底。 最后再发一次所有的链接! 香烟数据集:链接:https://pan.baidu.com/s/1t8u94x51TO7pLciU8AoaiQ 吸烟手势数据集:链接:https://pan.baidu.com/s/1BSH4yn3GBzF3hDTWAqKzDQ 烟雾数据集:链接:https://pan.baidu.com/s/1RKvkkmfpHiPunkFMAEdoAQ YOLOv5 原作者github:https://github.com/ultralytics/yolov5 我的github :https://github.com/CVUsers/Smoke-Detect-by-YoloV5/tree/master 欢迎star ,将长期更新! 最后还有很多知识点没,关注一下博主,下次。 另外欢迎加入深度学习算法交流群,与群内工程师朋友门一起交流学术,共商算法,加油!
本原创项目长期更新,旨在完成校园异常行为实时精检测,做到集成+N次开发+优化(不止局限于调包)为止,近期将不断更新以下模型+数据+标注文件+教程。关注博主,Star 一下github,一起开始美妙的目标检测之路吧~~
一、项目展示
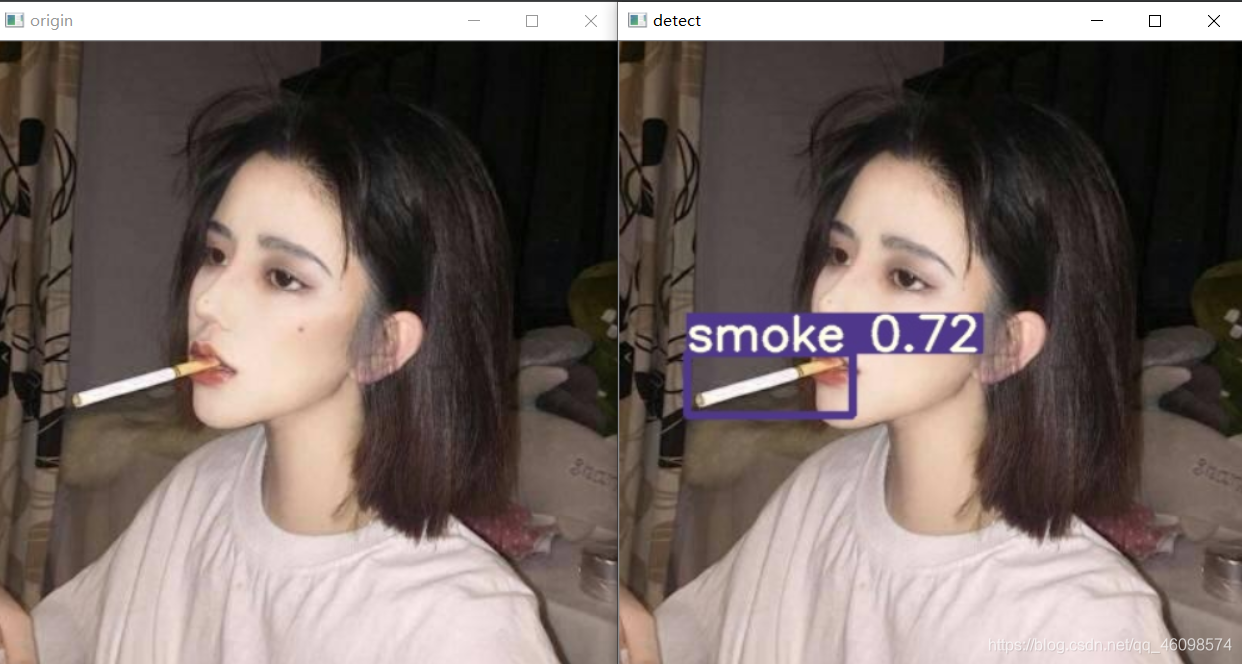
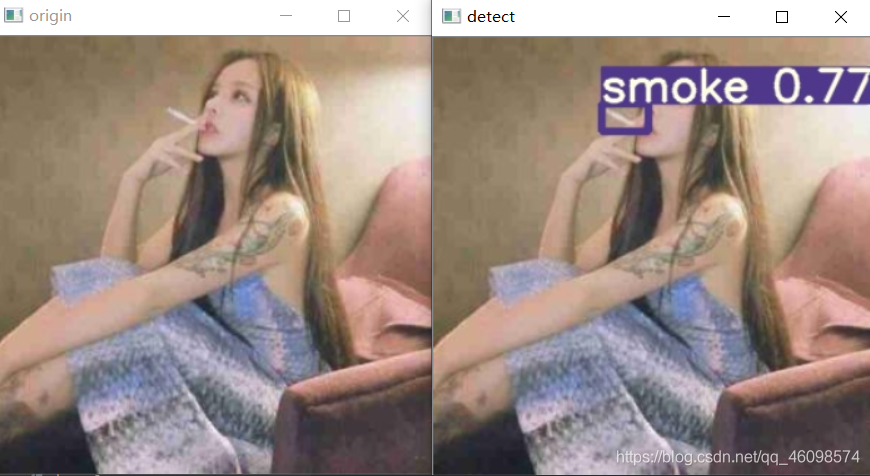
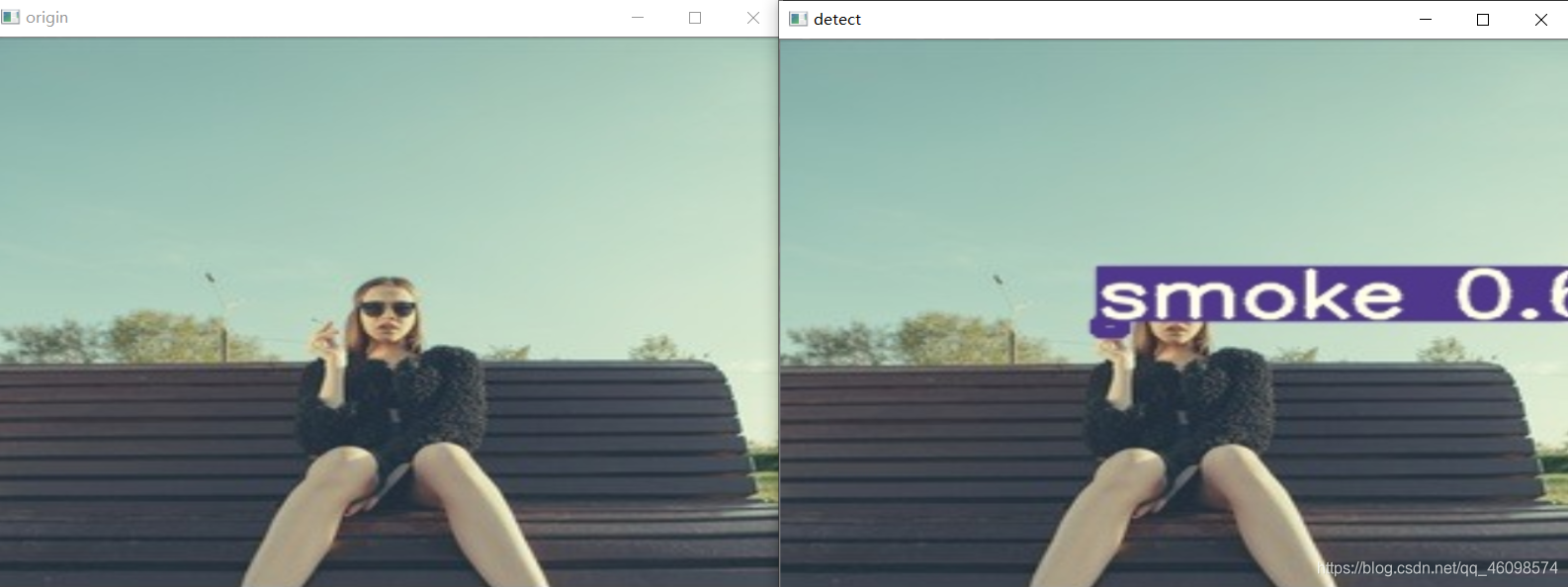
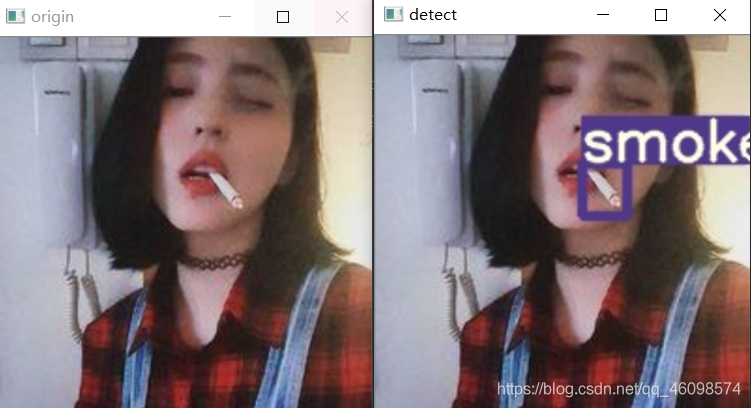
二、项目资源共享
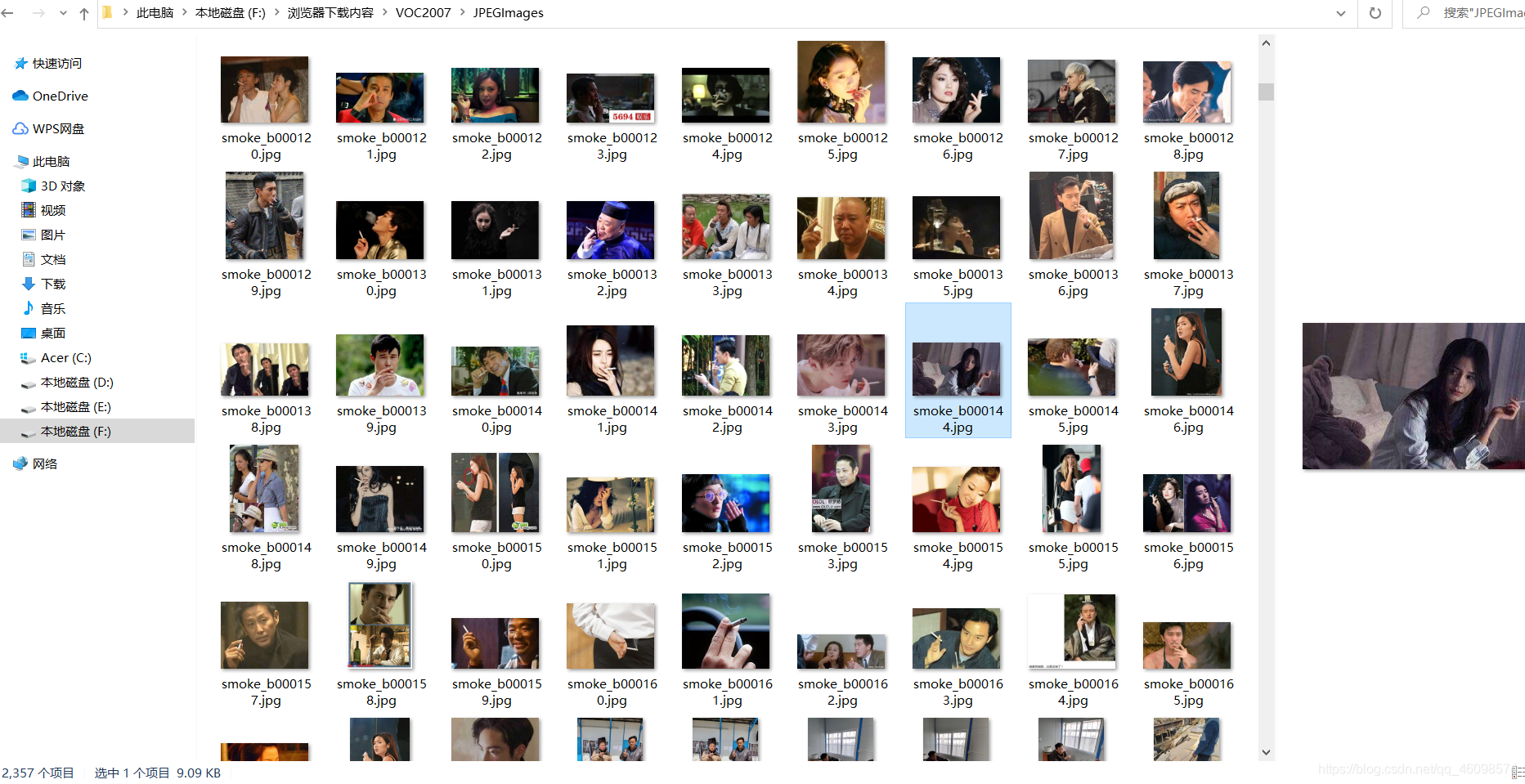
1:训练图片:香烟图片+吸烟手势+烟雾
提取码:n2wr:如下图

三、实践教学
3.1环境配置
Cython numpy==1.17 opencv-python torch>=1.4 matplotlib pillow tensorboard PyYAML>=5.3 torchvision scipy tqdm pip install -U -r requirements.txt git clone https://github.com/NVIDIA/apex && cd apex 然后切换至目录下 pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" . --user && cd .. && rm -rf apex 3.2数据标注与预处理
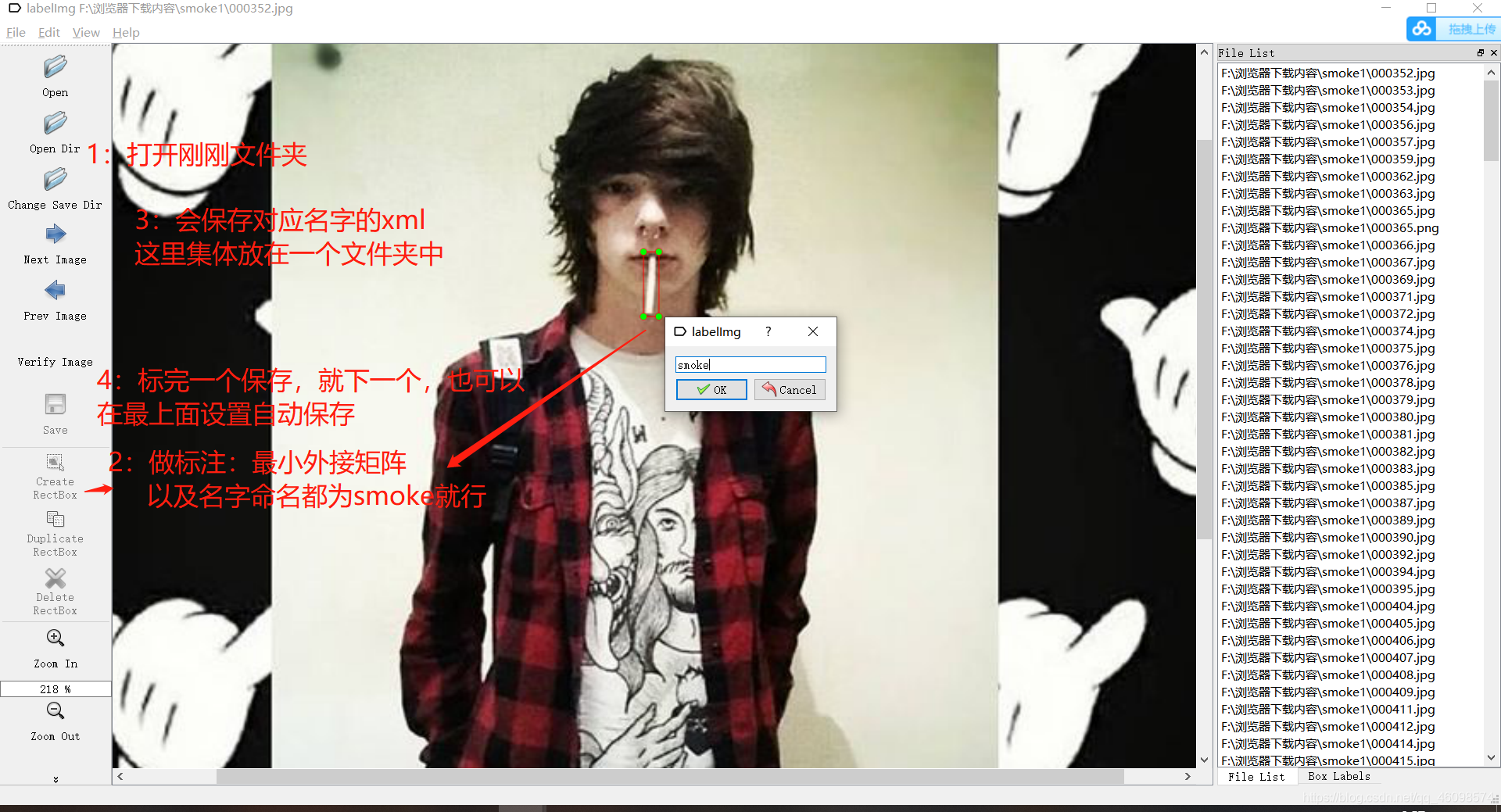
3.2.1附上自己的Lablimg简易教学:
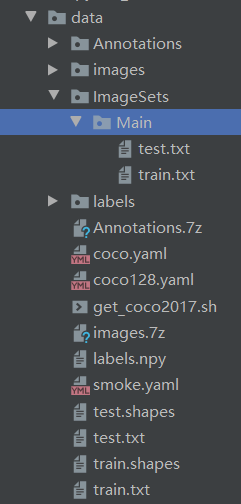
3.2.2 几个自己写的脚本用于转换数据集与训练前准备
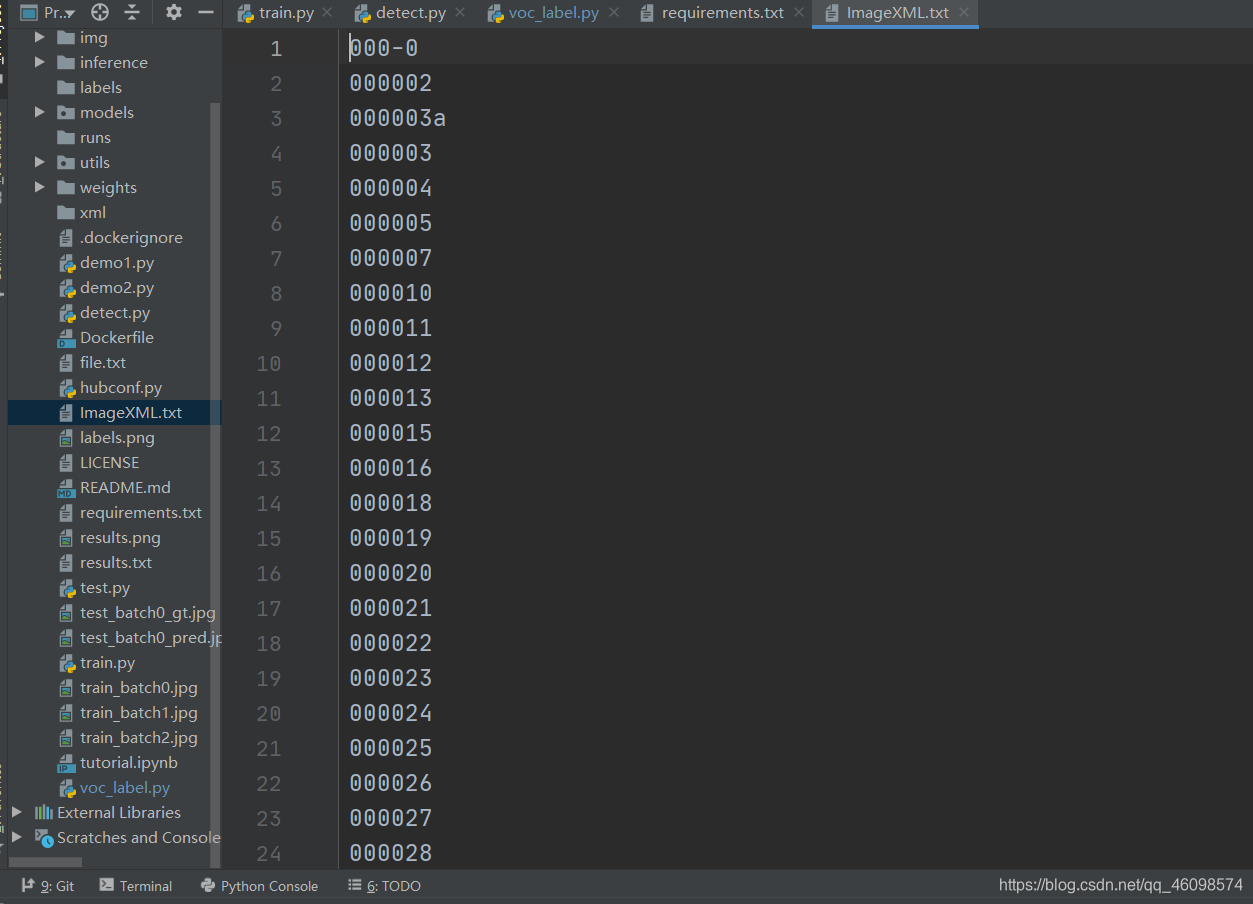
# 坐标xml转txt import os import xml.etree.ElementTree as ET classes = ["smoke"] # 输入名称,必须与xml标注名称一致 def convert(size, box): print(size, box) dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): print(image_id) in_file = open(r'./data/Annotations/%s.xml' % (image_id), 'rb') # 读取xml文件路径 out_file = open('./data/labels/%s.txt' % (image_id), 'w') # 需要保存的txt格式文件路径 tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): cls = obj.find('name').text if cls not in classes: # 检索xml中的名称 continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n') image_ids_train = open('./ImageXML.txt').read().strip().split() # 读取xml文件名索引 for image_id in image_ids_train: print(image_id) convert_annotation(image_id) open(r'./data/Annotations/%s.xml' % (image_id), 'rb') 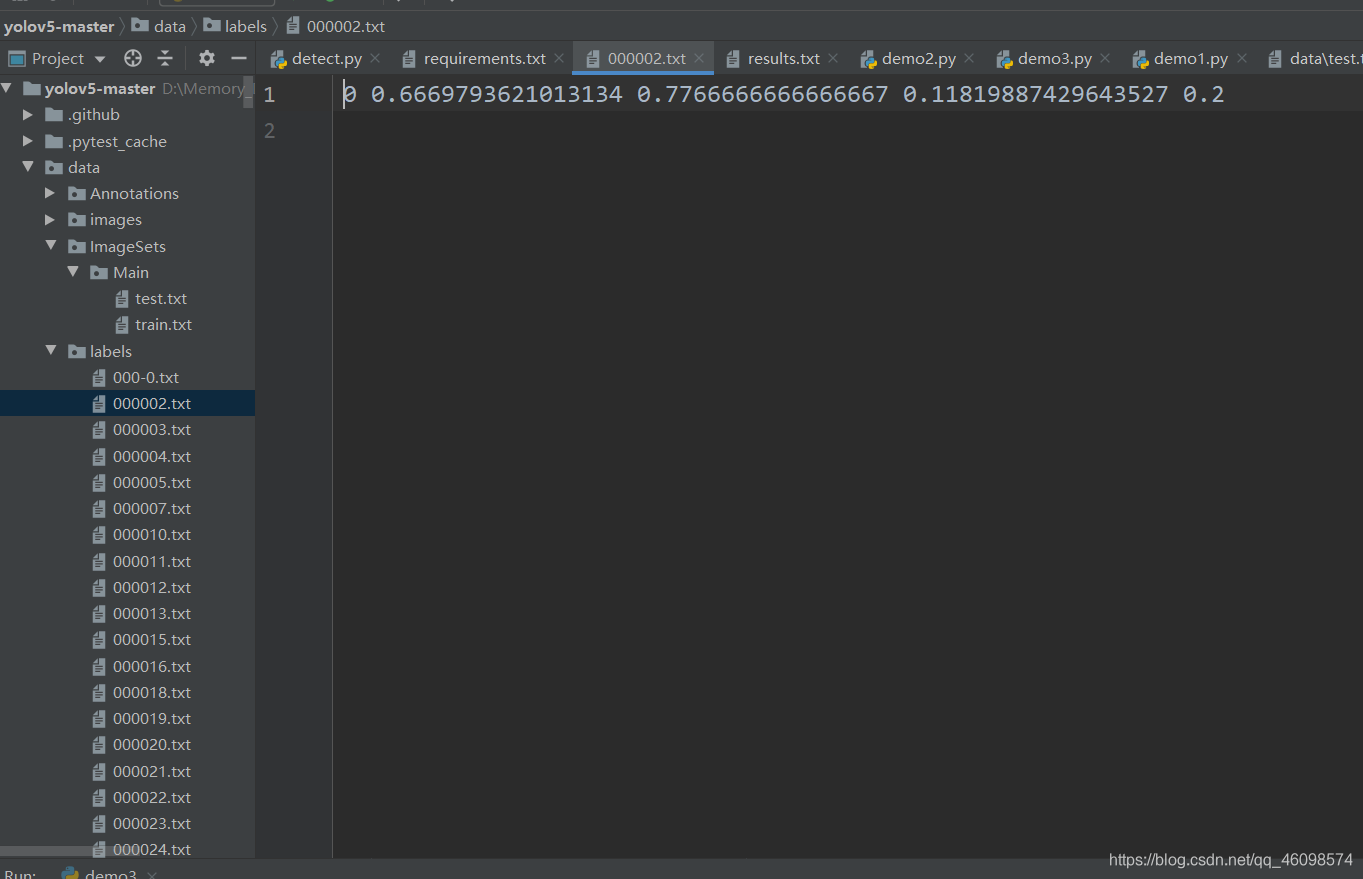
3.2.3 切分训练集与测试集:
import os import random trainval_percent = 1 # 可自行进行调节 train_percent = 1 xmlfilepath = './data/Annotations' txtsavepath = './data/ImageSetsMain' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) # ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('./data/ImageSets/Main/test.txt', 'w') ftrain = open('./data/ImageSets/Main/train.txt', 'w') # fval = open('ImageSets/Main/val.txt', 'w') for i in list: name = total_xml[i][:-4] + 'n' if i in trainval: # ftrainval.write(name) if i in train: ftest.write(name) # else: # fval.write(name) else: ftrain.write(name) # ftrainval.close() ftrain.close() # fval.close() ftest.close() trainval_percent = 1 # 可自行进行调节 import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join sets = ['train', 'test'] classes = ['smoke'] # 自己训练的类别 def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): in_file = open('data/Annotations/%s.xml' % (image_id), 'rb') out_file = open('data/labels/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + 'n') wd = getcwd() for image_set in sets: if not os.path.exists('data/labels/'): os.makedirs('data/labels/') image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split() list_file = open('data/%s.txt' % (image_set), 'w') for image_id in image_ids: list_file.write('data/images/%s.jpgn' % (image_id)) convert_annotation(image_id) list_file.close()
见smoke.yaml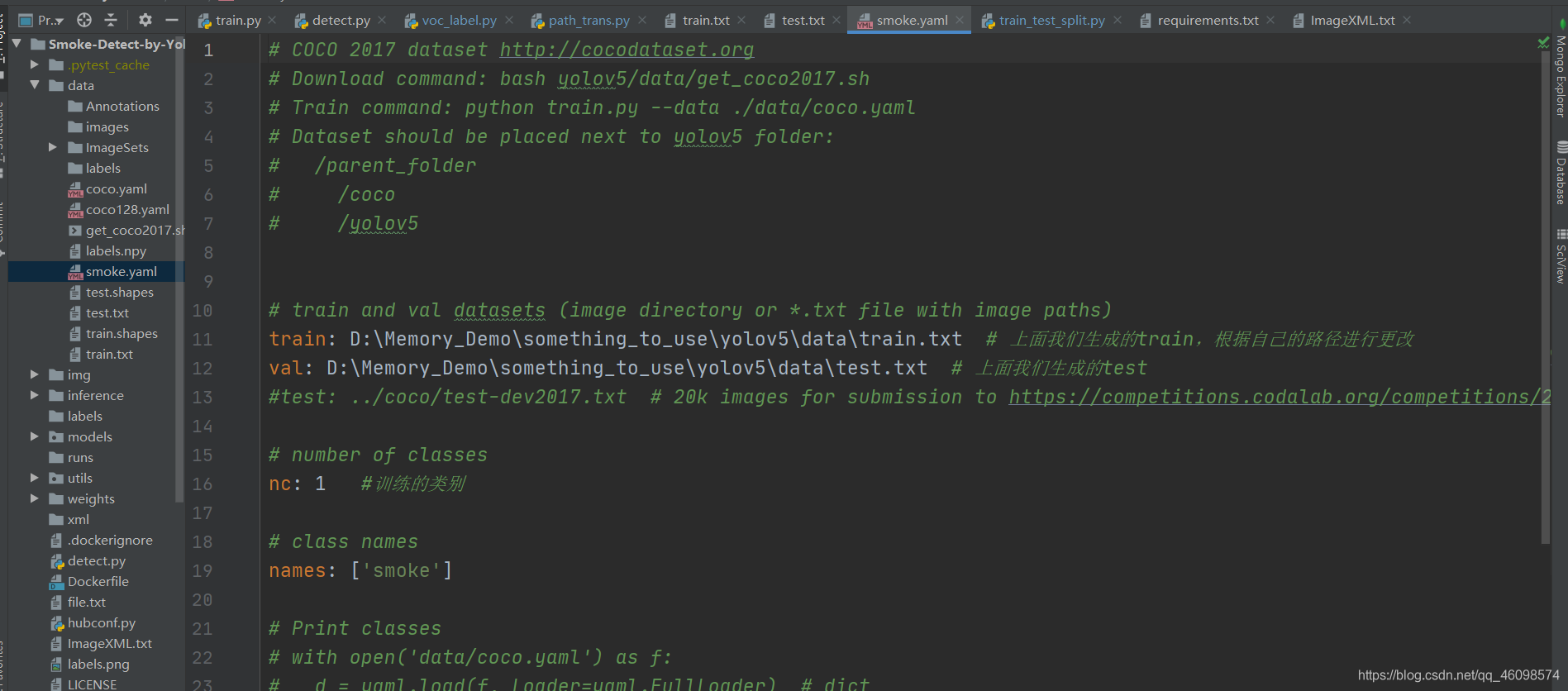
四、开始训练
4.1:开始训练
yolov5s yolov5m yolov5l yolov5x来 我在我的github中方了yolov5s,比较小,只有25mb,专门为移动端考虑了,真好。 python train.py --data data/smoke.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 10 --epochs 100 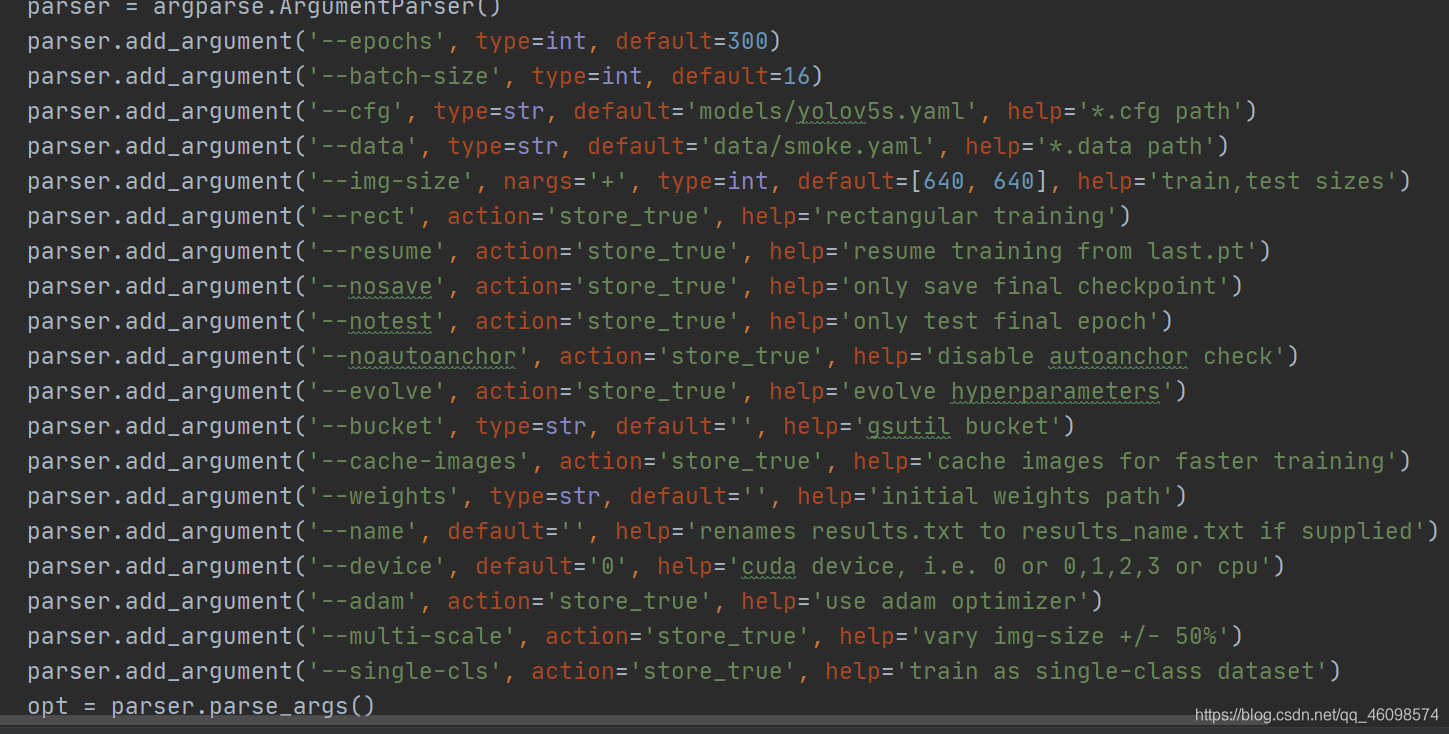
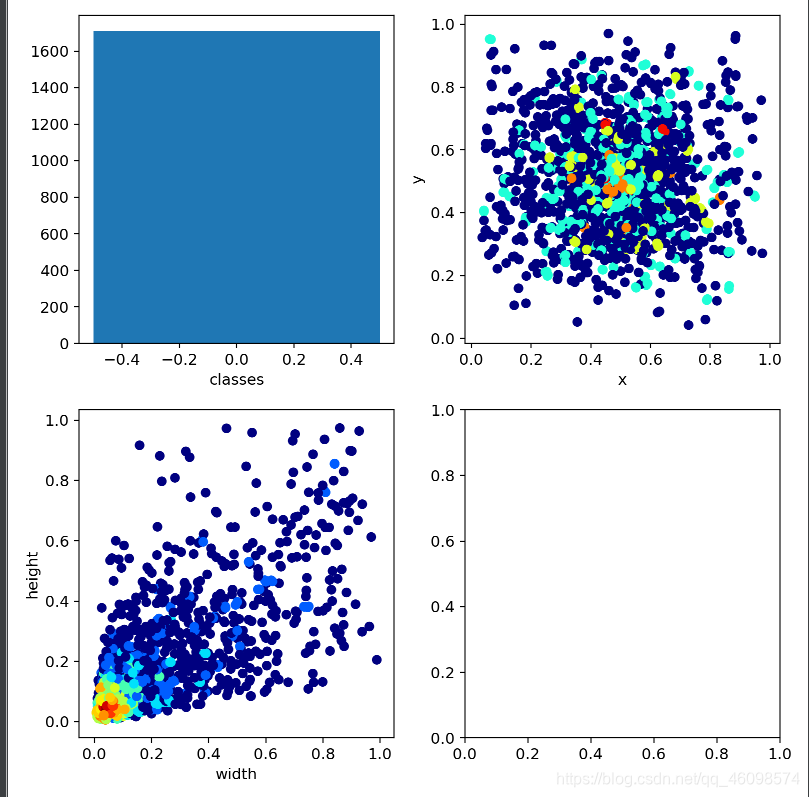
4.2:训练过程
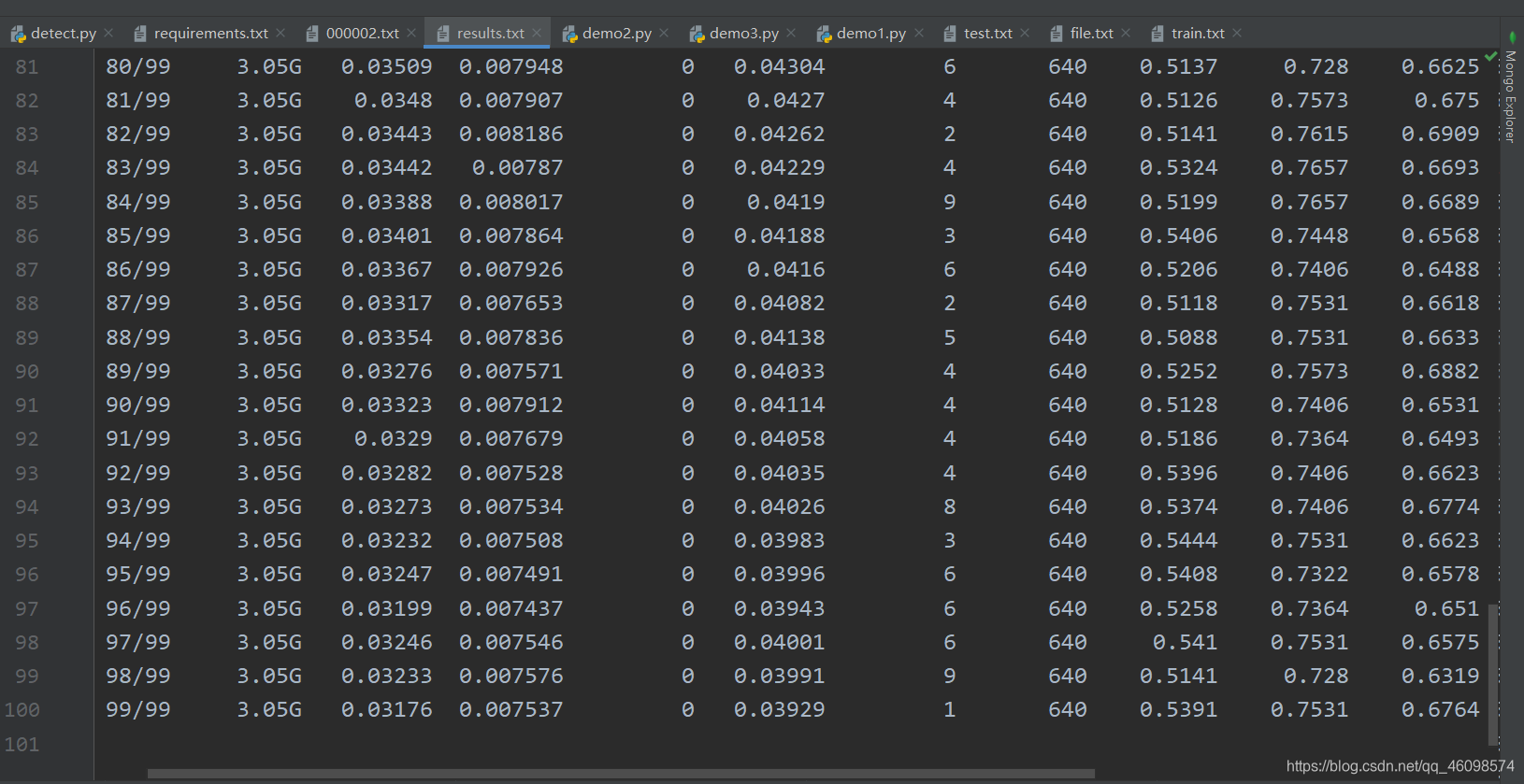
4.3:训练优化
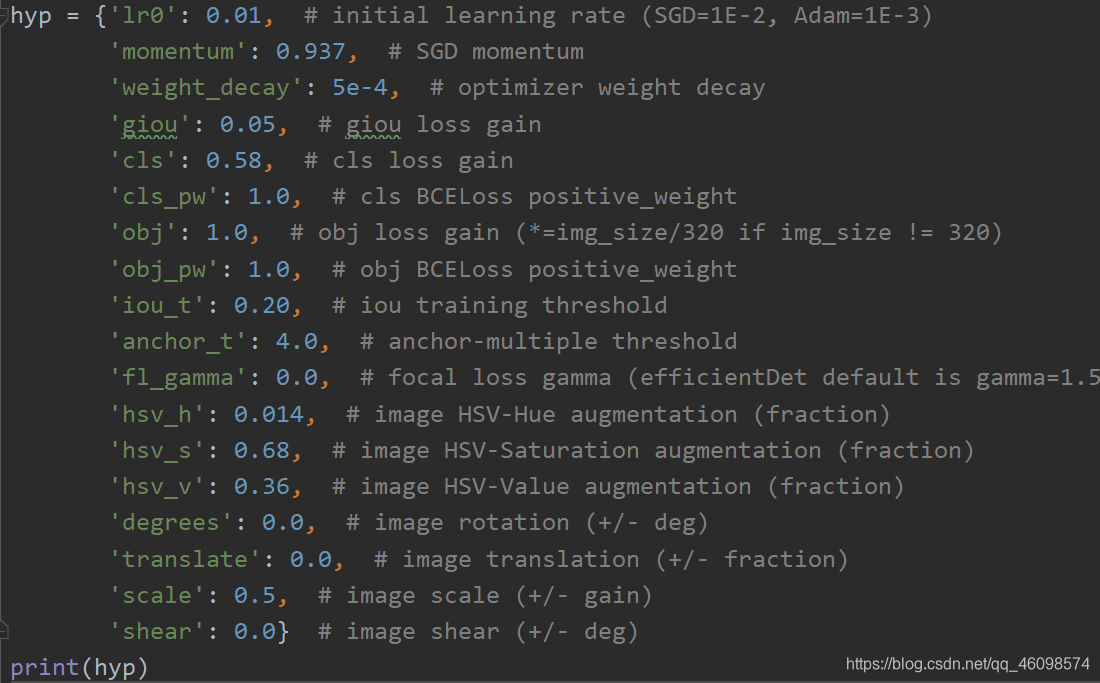
mixed_precision = True try: # Mixed precision training https://github.com/NVIDIA/apex from apex import amp except: print('Apex recommended for faster mixed precision training: https://github.com/NVIDIA/apex') mixed_precision = False # not installed if mixed_precision: model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0) if mixed_precision: with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test) device = torch_utils.select_device(opt.device, apex=mixed_precision, batch_size=opt.batch_size) if device.type == 'cpu': mixed_precision = False 4.4 训练参数:
五、实时检测
运行detect.py即可
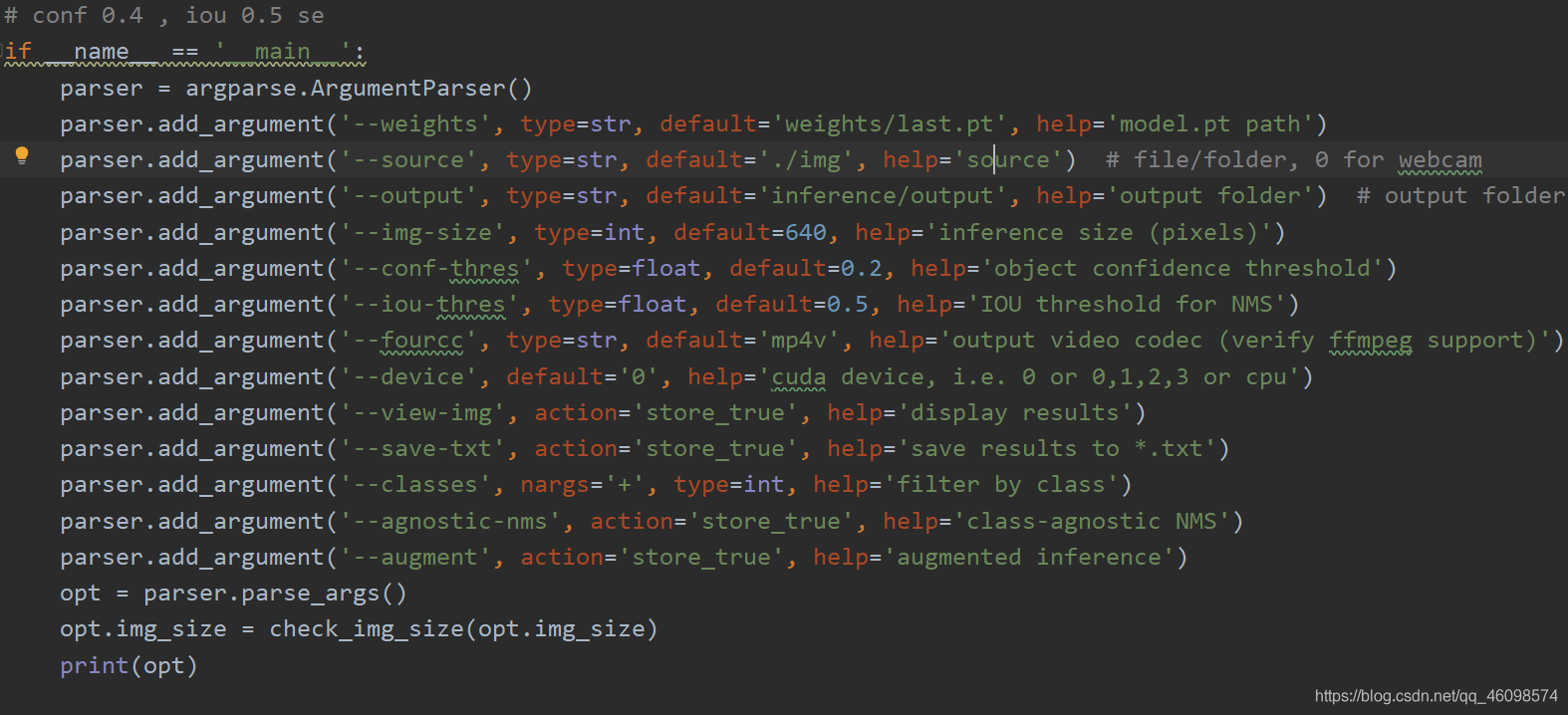
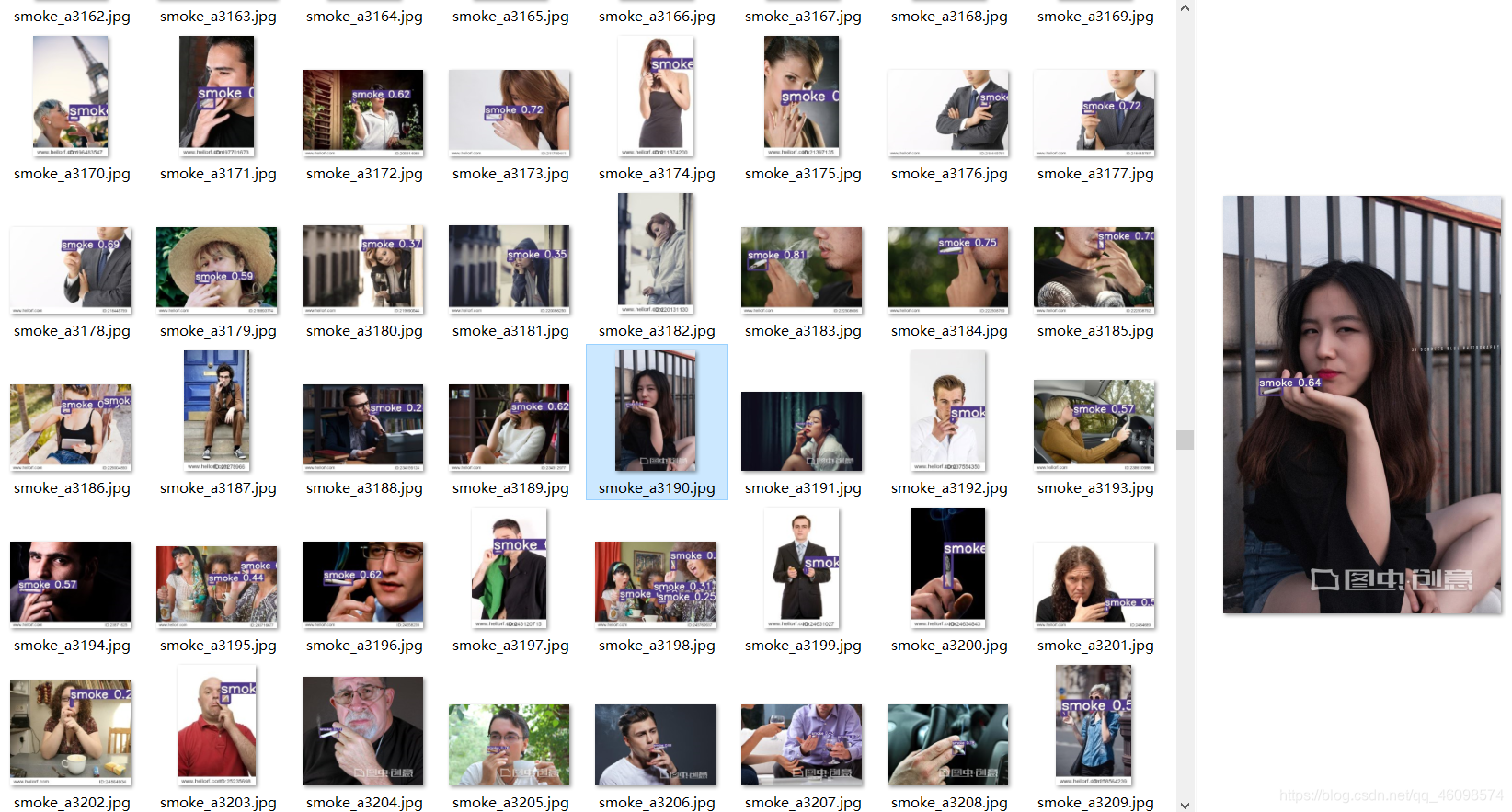
六、YOLO系列可视化对比
yolov3-tiny yolov4 yolov5 
七、写在后面
全部链接传送门
提取码:n2wr
提取码:9r8t
提取码:ag0x
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)










 1960
1960