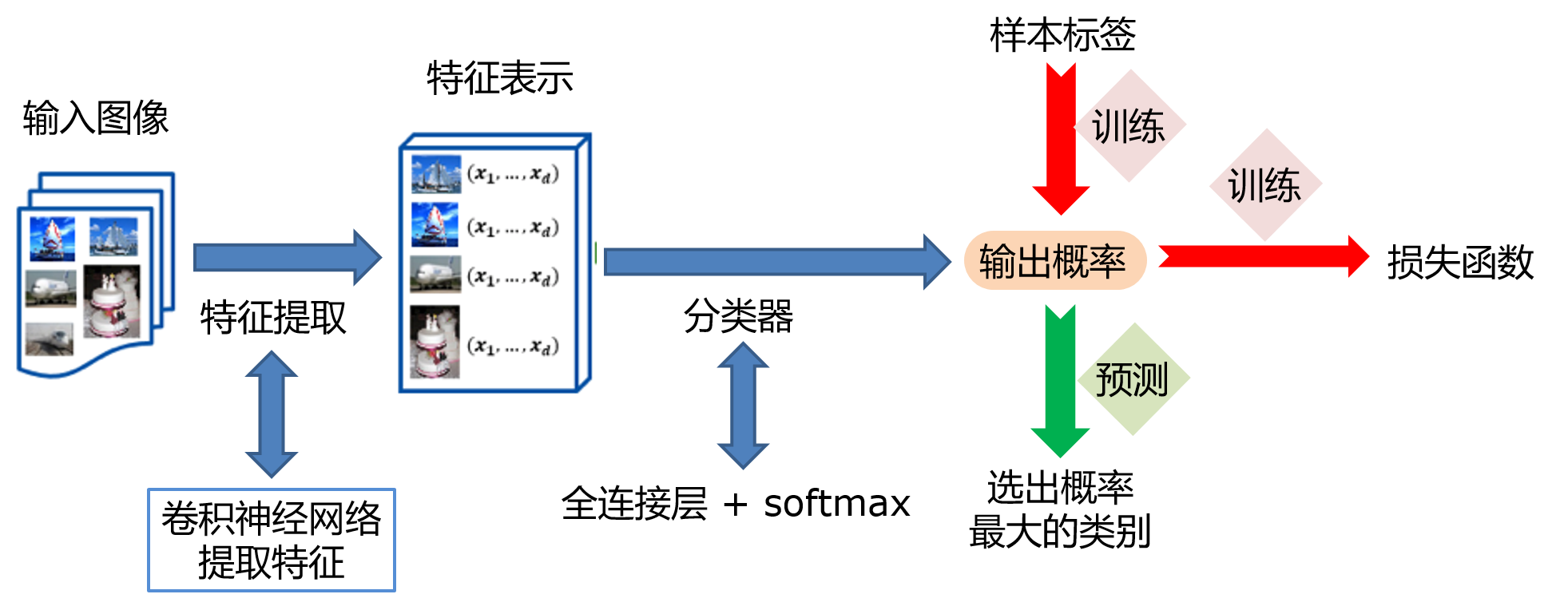
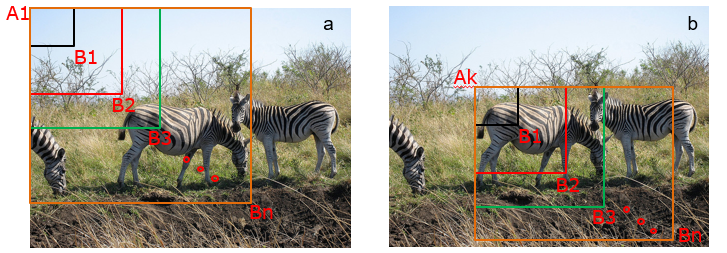
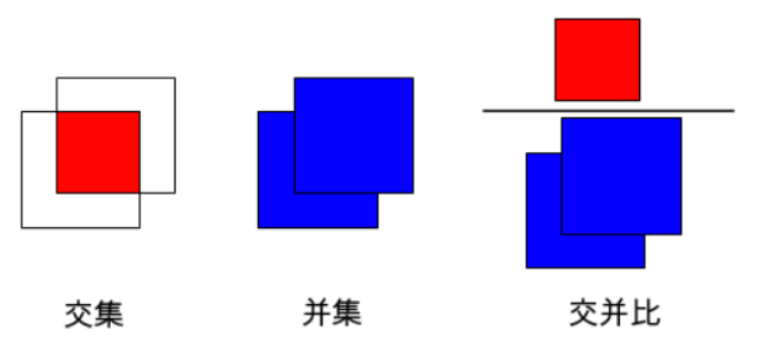
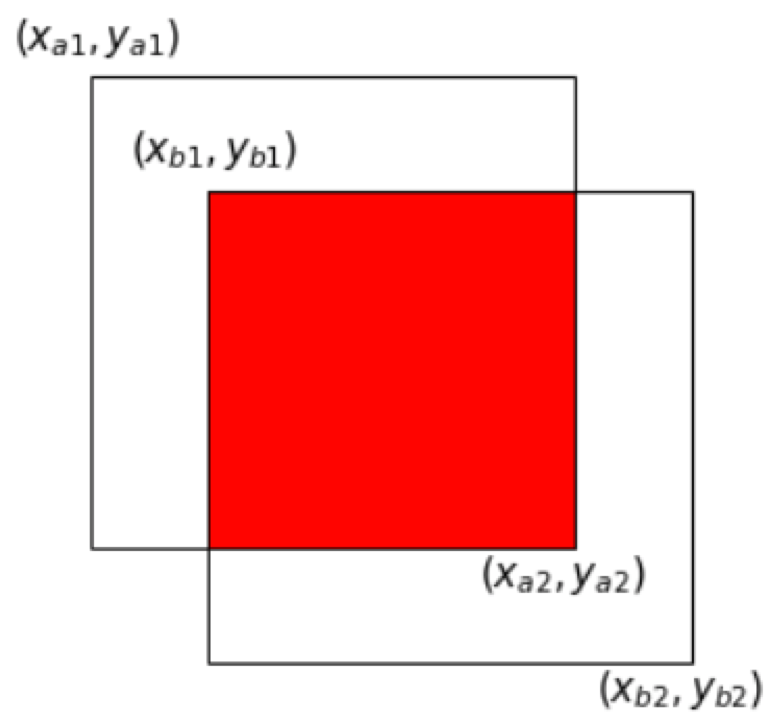
首先说一下什么是目标检测:对计算机而言,能够“看到”的是图像被编码之后的数字,但它很难解高层语义概念,比如图像或者视频帧中出现目标的是人还是物体,更无法定位目标出现在图像中哪个区域。目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置。 在上一节中我们学习了图像分类处理基本流程,先使用卷积神经网络提取图像特征,然后再用这些特征预测分类概率,根据训练样本标签建立起分类损失函数,开启端到端的训练,如 图2 所示。 但对于目标检测问题,按照 图2 的流程则行不通。因为在图像分类任务中,对整张图提取特征的过程中没能体现出不同目标之间的区别,最终也就没法分别标示出每个物体所在的位置。 为了解决这个问题,结合图片分类任务取得的成功经验,我们可以将目标检测任务进行拆分。假设我们现在有某种方式可以在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域,在一张图上可以生成很多个候选区域。然后对每个候选区域,可以把它单独当成一幅图像来看待,使用图像分类模型对它进行分类,看它属于哪个类别或者背景(即不包含任何物体的类别)。 A为图像上的某个像素点,B为A右下方另外一个像素点,A、B两点可以确定一个矩形框,记作AB。 当A遍历图像上所有像素点,B则遍历它右下方所有的像素点,最终生成的矩形框集合{AiBj}将会包含图像上所有可以选择的区域。 只要我们对每个候选区域的分类足够的准确,则一定能找到跟实际物体足够接近的区域来。穷举法也许能得到正确的预测结果,但其计算量也是非常巨大的,其所生成的总的候选区域数目约为 R-CNN的系列算法分成两个阶段,先在图像上产生候选区域,再对候选区域进行分类并预测目标物体位置,它们通常被叫做两阶段检测算法。SSD和YOLO算法则只使用一个网络同时产生候选区域并预测出物体的类别和位置,所以它们通常被叫做单阶段检测算法。 检测任务需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念。通常使用边界框(bounding box,bbox)来表示物体的位置,边界框是正好能包含住物体的矩形框,如 图4 所示,图中3个人分别对应3个边界框。 通常有两种格式来表示边界框的位置: 在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的 注意: 要完成一项检测任务,我们通常希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: 锚框与物体边界框不同,是由人们假想出来的一种框。先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。在下图中,以像素点[300, 500]为中心可以使用下面的程序生成3个框,如图中蓝色框所示,其中锚框A1跟人像区域非常接近。 在目标检测模型中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度。在训练过程中,模型通过学习不断的调整参数,最终能学会如何判别出锚框所代表的候选区域是否包含物体,如果包含物体的话,物体属于哪个类别,以及物体边界框相对于锚框位置需要调整的幅度。 上面我们画出了以点 我们将用这个概念来描述两个框之间的重合度。两个框可以看成是两个像素的集合,它们的交并比等于两个框重合部分的面积除以它们合并起来的面积。下图a中红色区域是两个框的重合面积,图b中蓝色区域是两个框的相并面积。用这两个面积相除即可得到它们之间的交并比,如 图5 所示。 假如位置关系如 图6 所示: 如果二者有相交部分,则相交部分左上角坐标为: 相交部分右下角坐标为: 计算先交部分面积: 矩形框A和B的面积分别是: 计算相并部分面积: 计算交并比: 思考: 两个矩形框之间的相对位置关系,除了上面的示意图之外,还有哪些可能,上面的公式能否覆盖所有的情形? 为了直观的展示交并比的大小跟重合程度之间的关系,图7 示意了不同交并比下两个框之间的相对位置关系,从 IoU = 0.95 到 IoU = 0. 要想知道什么是YOLO首先要知道什么是yolo。 这里是YOLOv3的主干网络为Darknet53,整体结构如下 YOLOv4主干网络为CSPDarkNet53,其有两种输入结构,一种是416X416 另一种是608×608 不断进行下采样是为了获得更高语义的信息,最终我们只选择了最后三个shape的特征层进行下一步的操作,因为他们具有更高语义的信息。 下图左边是普通的残差卷积,右边是含有CSPnet结构的残差卷积,可以看到CSP残差结构有一个大的 残差边,直接跳过了堆叠的残差结果,直接连向输出 该部分也称为特征金字塔 PANet是2018的一种实例分割算法,其具体结构由反复提升特征的意思。上图为原始的PANet的结构,可以看出来其具有**一个非常重要的特点就是特征的反复提取。**在(a)里面是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。 这里对三次卷积后的特征层进行卷积和上采样处理,这里用的是两倍上采样,这样13x13x1024的特征层就变成了-26x26x512,这样我们就可以用我们上采样得到的特征层与我们主干网络获取到的26x26x512的特征层进行堆叠,从而实现特征融合,融合之后再卷积再次进行上采样,再堆叠融合,这样就对三个特征层都完成了特征融合了,然后我们还要加深特征提取。 怎样加深呢?我们又采取了下采样的方式,进行52x52x256的就又变成了26x26x512的特征层,然后就又可以与下面的26x26x512的特征层进行堆叠融合了,再下采样,再融合。这样一套下来我们就得到了很有效的特征了。然后就交给yolo head对提取的特征进行结果预测。 yolov4和yolov3的yolohead是一样的结构,这里拿13x13x1024的yolohead为例子,来说明。 除去CSPDarknet53和Yolo Head的结构外,都是特征金字塔的结构。 主干特征提取网络Backbone的改进点有两个: 加强特征提取网络多了许多上采样和下采样。 由第二步我们可以获得三个特征层的预测结果,shape分别为(N,13,13,1024),(N,26,26,512),(N,52,52,256)的数据,对应每个图分为13X13、26X26、52X52,的网格上3个预测框的位置。 但是这个预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。 此处要讲一下yolo4的预测原理,yolo3的3个特征层分别将整幅图分为13X13、26X26、52X52,的网格**,每个网络点负责一个区域的检测。** 我们知道特征层的预测结果对应着三个预测框的位置,我们先将其reshape一下,其结果为(N,13,13,1024),(N,26,26,512),(N,52,52,256) 最后一个维度中的85包含了4+1+80,分别代表x_offset、y_offset、h和w、置信度、分类结果。 yolo4的解码过程就是将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。 当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选 主要参考于 从V1到V4,让你读懂YOLO原理 YOLOV3可参考该博客:
前言
如图所示:

目标检测发展历程
图2:图像分类流程示意图
图3:候选区域
,假设
,总数将会达到
个,如此多的候选区域使得这种方法几乎没有什么实用性。但是通过这种方式,我们可以看出,假设分类任务完成的足够完美,从理论上来讲检测任务也是可以解决的,亟待解决的问题是如何设计出合适的方法来产生候选区域。基本概念
边界框(bounding box)
图4:边界框
,其中
是矩形框左上角的坐标,
是矩形框右下角的坐标。图4中3个红色矩形框用xyxy格式表示如下:
。
。
。
,其中
是矩形框中心点的坐标,w是矩形框的宽度,h是矩形框的高度。
,这样的边界框也被称为真实框(ground truth box),如 图4 所示,图中画出了3个人像所对应的真实框。模型会对目标物体可能出现的位置进行预测,由模型预测出的边界框则称为预测框(prediction box)。
,其中L是类别标签,P是物体属于该类别的概率。一张输入图片可能会产生多个预测框,接下来让我们一起学习如何完成这样一项任务。锚框(Anchor)
交并比
为中心,生成的三个锚框,我们可以看到锚框A1 与真实框 G1的重合度比较好。那么如何衡量这三个锚框跟真实框之间的关系呢,在检测任务中是使用交并比(Intersection of Union,IoU)作为衡量指标。这一概念来源于数学中的集合,用来描述两个集合
和
之间的关系,它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数,具体计算公式如下:
图5:交并比
假设两个矩形框A和B的位置分别为: $$A: [x_{a1}, y_{a1}, x_{a2}, y_{a2}]$$
图6:计算交并比
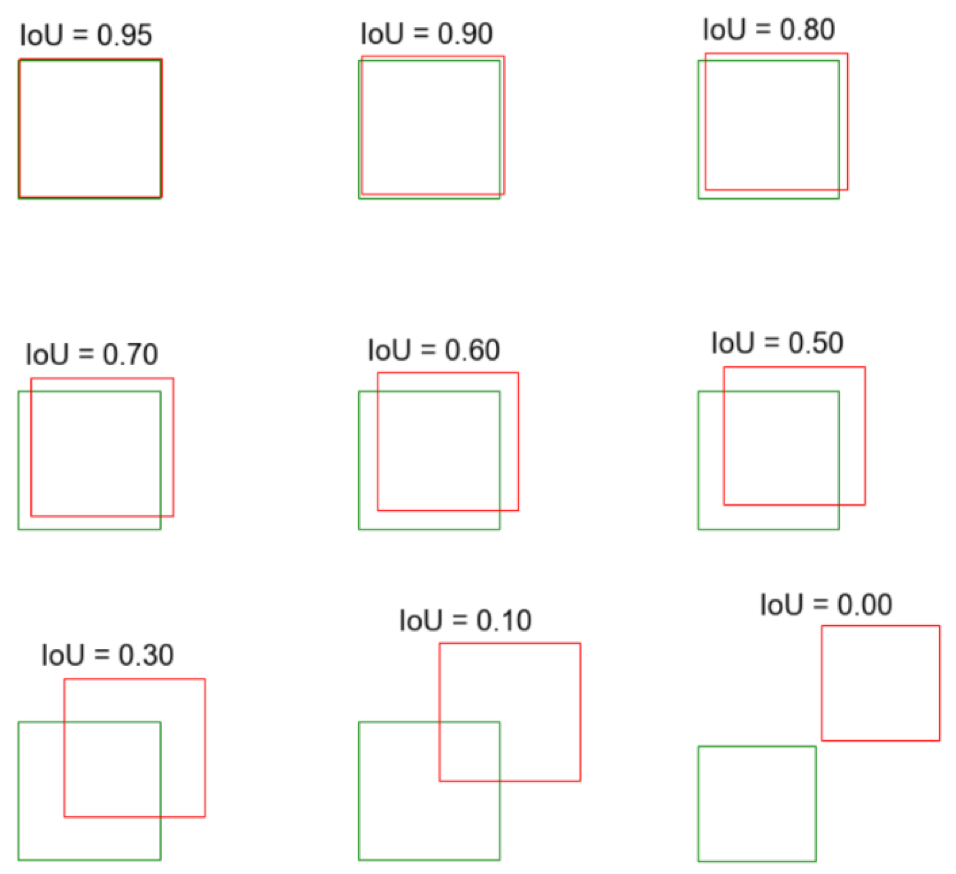
图7:不同交并比下两个框之间相对位置示意图
有了基础概念的基础,就可以开始模型了。
YOLOv4整体介绍
什么是YOLOv4
YOLO是You Only Look Once的缩写。它是一种使用深卷积神经网络学习的特征来检测物体的目标检测器。
物体检测的两个步骤可以概括为:
剩下的基础概念一级yolov1到v3可以看下这篇文章从V1到V4,让你读懂YOLO原理,大致了解下,这里将尽可能详细的讲一下YOLOv4的网络原理以及其代码实现。主干网络
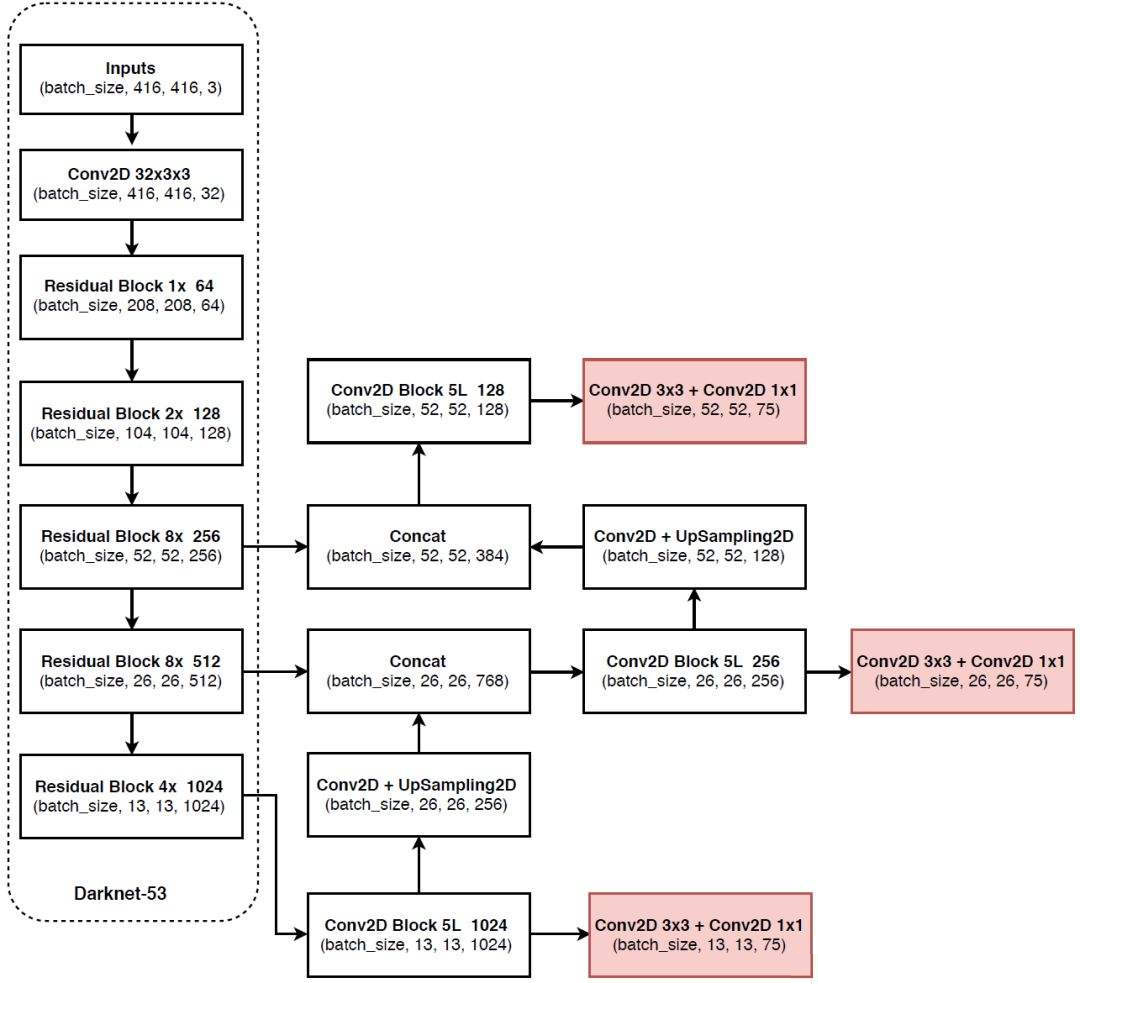 YOLOv3网络结构
YOLOv3网络结构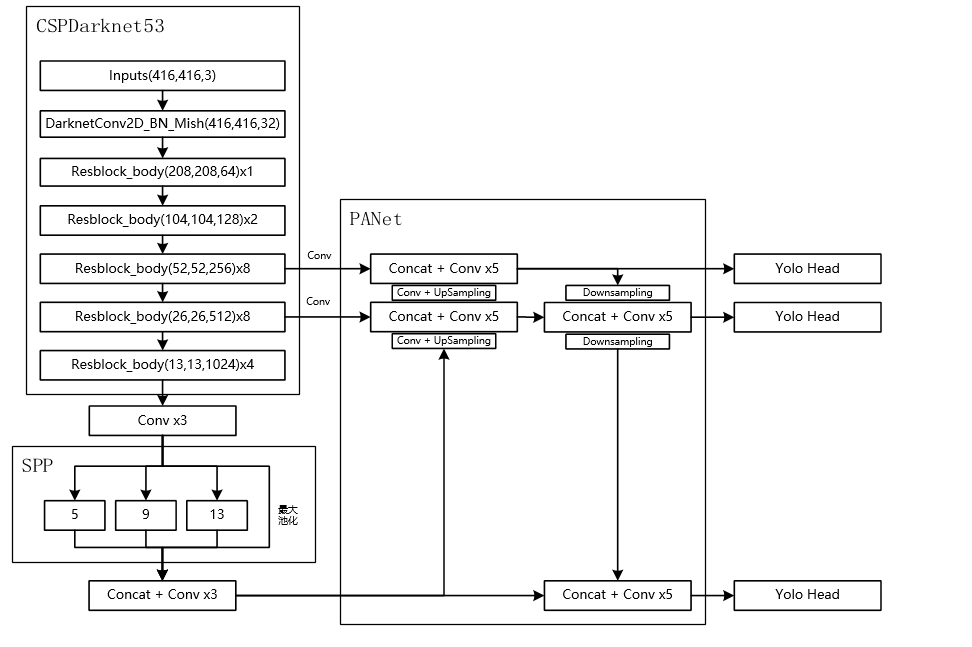 YOLOv4网络结构
YOLOv4网络结构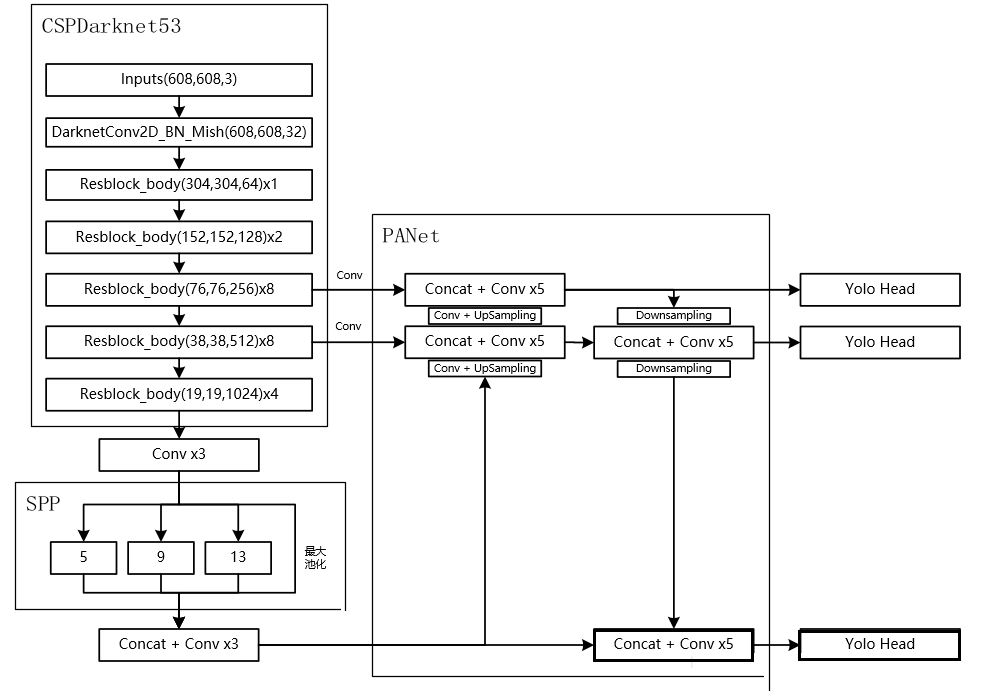 YOLOv4网络结构
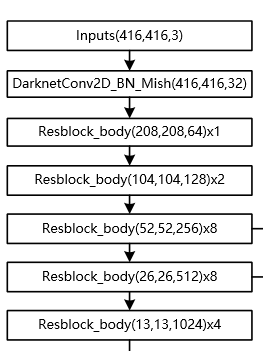
YOLOv4网络结构网络分解
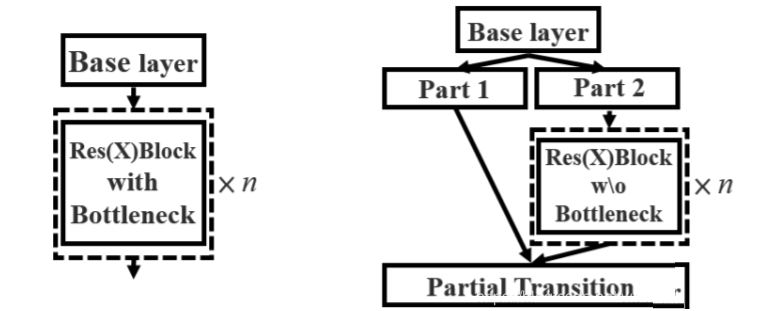
CSPDarknet53
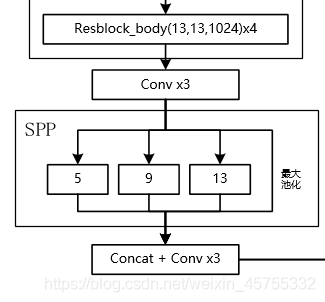
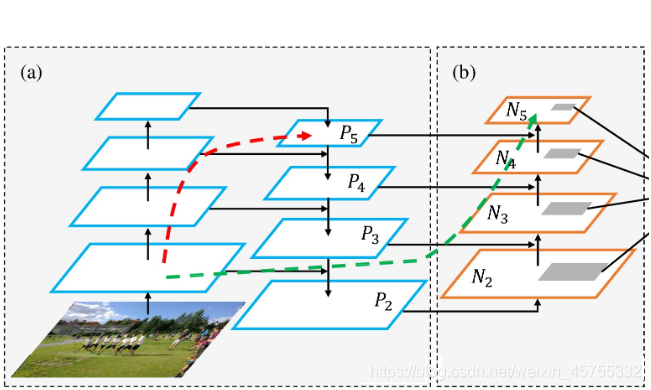
PANet结构——加强特征提取网络
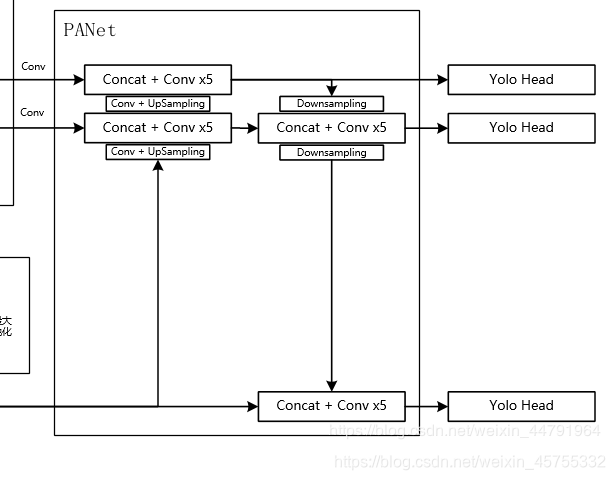
YOLO head


 这两个和上面是一样的,就划分的网格多了许多。
这两个和上面是一样的,就划分的网格多了许多。 YOLOv4与YOLOv3的区别
先验框
这一部分基本上是所有目标检测通用的部分。不过该项目的处理方式与其它项目不同。其对于每一个类进行判别。
1、取出每一类得分大于self.obj_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
https://blog.csdn.net/weixin_44791964/article/details/106014717
https://xiaobaibubai.blog.csdn.net/article/details/105914455
https://blog.csdn.net/weixin_44791964/article/details/103276106
05-12  1万+
1万+
本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)