大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语— 本片博文为大家带来的是Hive与Spark SQL的读写操作。 包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。需要强调的一点是,如果要在 Spark SQL 中包含Hive 的库,并不需要事先安装 Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。 若要把 Spark SQL 连接到一个部署好的 Hive 上,你必须把 hive-site.xml 复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好 Hive,Spark SQL 也可以运行。 需要注意的是,如果你没有部署好Hive,Spark SQL 会在当前的工作目录中创建出自己的 Hive 元数据仓库,叫作 metastore_db。此外,如果你尝试使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的 classpath 中有配好的 hdfs-site.xml,默认的文件系统就是 HDFS,否则就是本地文件系统)。 如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可. Hive 的元数据存储在 derby 中, 仓库地址: 在spark-shell执行 hive 方面的查询比较麻烦.spark.sql(“”).show Spark 专门给我们提供了书写 HiveQL 的工具: spark-sql spark-sql 得到的结果不够友好, 所以可以使用hiveserver2 + beeline 本次的就到这里了, 好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/

目录

Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQ L编译时可以包含 Hive 支持,也可以不包含。一. 使用内嵌的 Hive
$SPARK_HOME/spark-warehouse
然而在实际使用中, 几乎没有任何人会使用内置的 Hive二. 使用外置的 Hive
2.1 准备工作
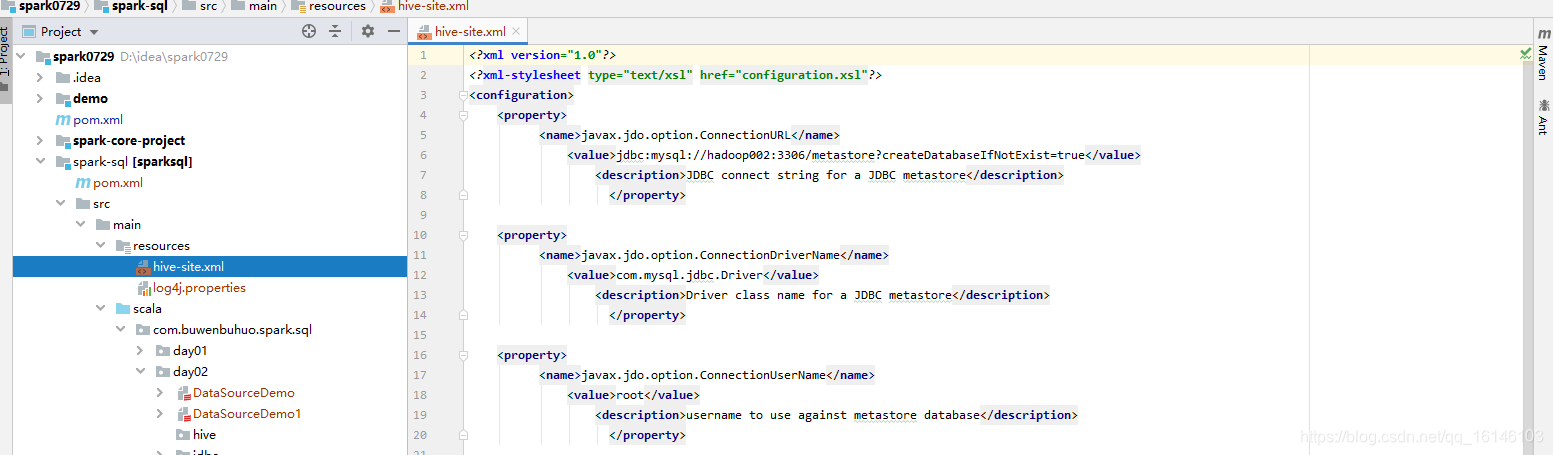
[bigdata@hadoop002 conf]$ cp /opt/module/hive/conf/hive-site.xml hive-site.xml // 内容如下 <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop002:3306/metastore?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>199712</value> <description>password to use against metastore database</description> </property> <property> <name>hive.zookeeper.quorum</name> <value>hadoop002,hadoop003,hadoop004</value> <description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> </configuration>
[bigdata@hadoop002 jars]$ cp /opt/software/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar ./
[bigdata@hadoop002 conf]$ cp /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml ./ [bigdata@hadoop002 conf]$ cp /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml ./ 
2.2 启动 spark-shell
scala> spark.sql("show tables").show 
scala> spark.sql("select * from emp").show // 显示100行 scala> spark.sql("select * from emp").show(100) // 显示截断的内容 scala> spark.sql("select * from emp").show(100,false) 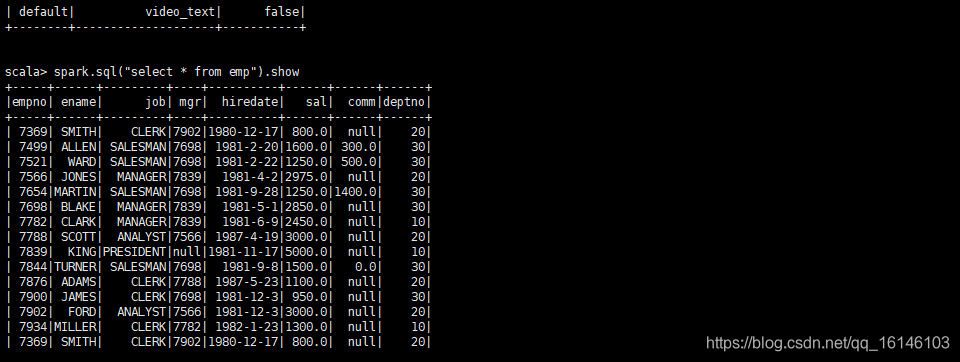
scala> spark.sql("select count(*) from emp").show(100,false) // 退出 scala> :q 
2.2 启动 spark-sql
// 一般用于测试学习 [bigdata@hadoop002 spark]$ bin/spark-sql spark-sql> select count(*) from emp; 
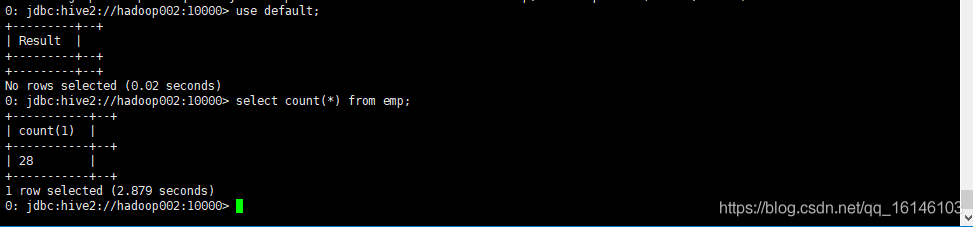
2.3 使用hiveserver2 + beeline
[bigdata@hadoop002 spark]$ sbin/start-thriftserver.sh
[bigdata@hadoop002 spark]$ bin/beeline # 然后输入 !connect jdbc:hive2://hadoop002:10000 # 然后按照提示输入用户名和密码 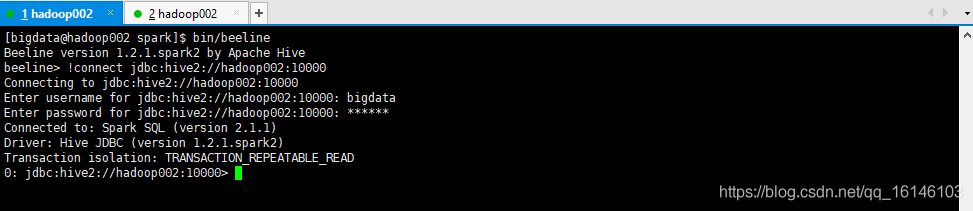
三. 在代码中访问 Hive
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.1.1</version> </dependency> 3.1 从hive中读数据
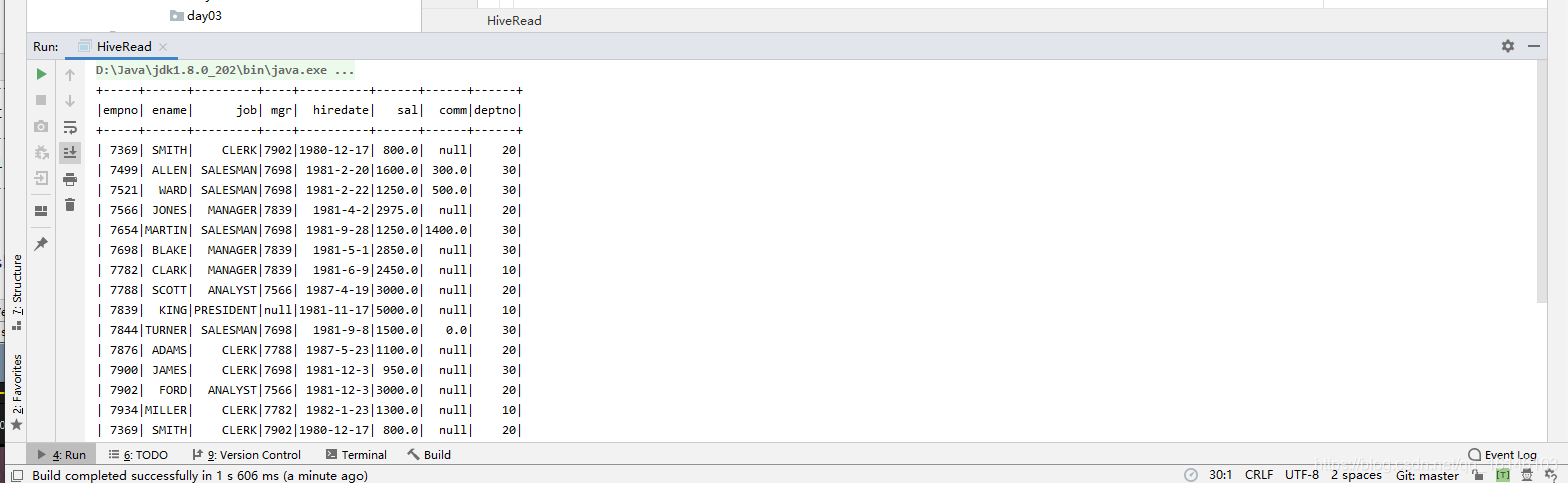
package com.buwenbuhuo.spark.sql.day02.hive import org.apache.spark.sql.SparkSession /** ** * * @author 不温卜火 * * * @create 2020-08-05 14:19 ** * MyImapBox : https://buwenbuhuo.blog.csdn.net/ * */ object HiveRead { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession .builder() .master("local[*]") .appName("HiveRead") // 添加支持外部hive .enableHiveSupport() .getOrCreate() import spark.implicits._ spark.sql("show databases") spark.sql("select * from emp").show spark.close() } }
3.2 从hive中写数据
3.2.1 使用hive的insert语句去写
3.2.1.1 写入数据(默认保存到本地)
package com.buwenbuhuo.spark.sql.day02.hive import org.apache.spark.sql.SparkSession /** ** * * @author 不温卜火 * * * @create 2020-08-05 14:26 ** * MyImapBox : https://buwenbuhuo.blog.csdn.net/ * */ object HiveWrite { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession .builder() .master("local[*]") .appName("HiveWrite") // 添加支持外部hive .enableHiveSupport() .getOrCreate() import spark.implicits._ // 先创建一个数据库 // 创建一次就行否则会报错 // spark.sql("create database spark0805").show spark.sql("use spark0805") // spark.sql("create table user1(id int,name string)").show spark.sql("insert into user1 values(10,'lisi')").show } }

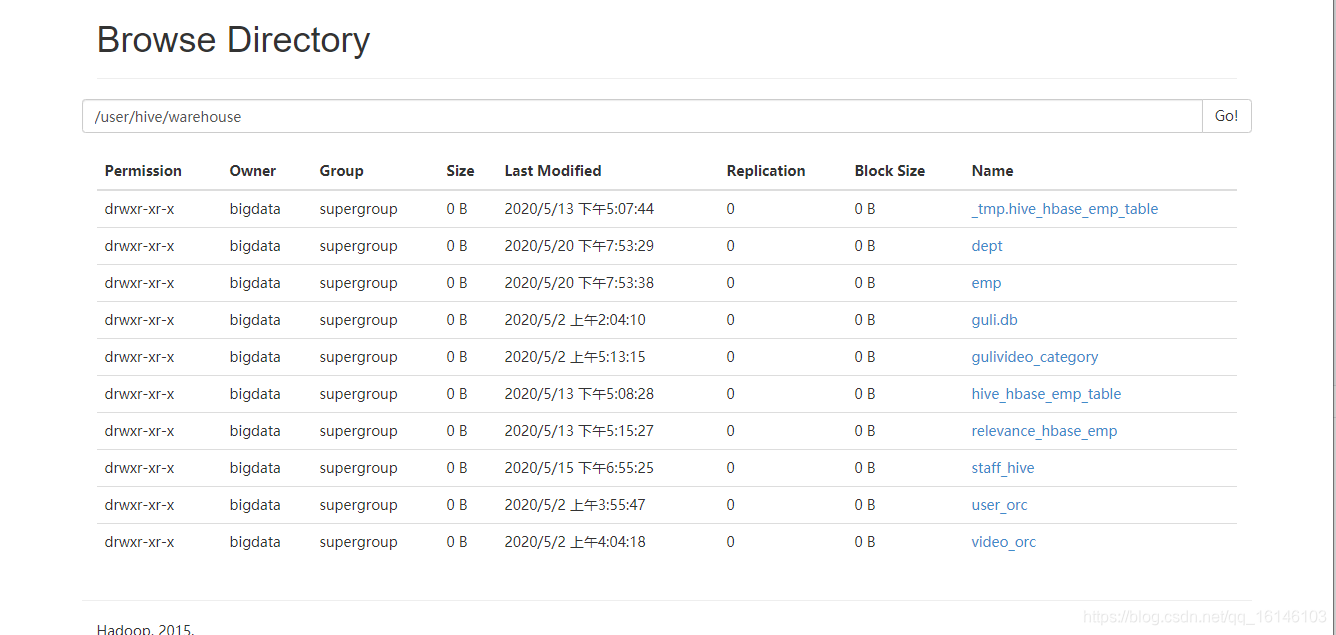

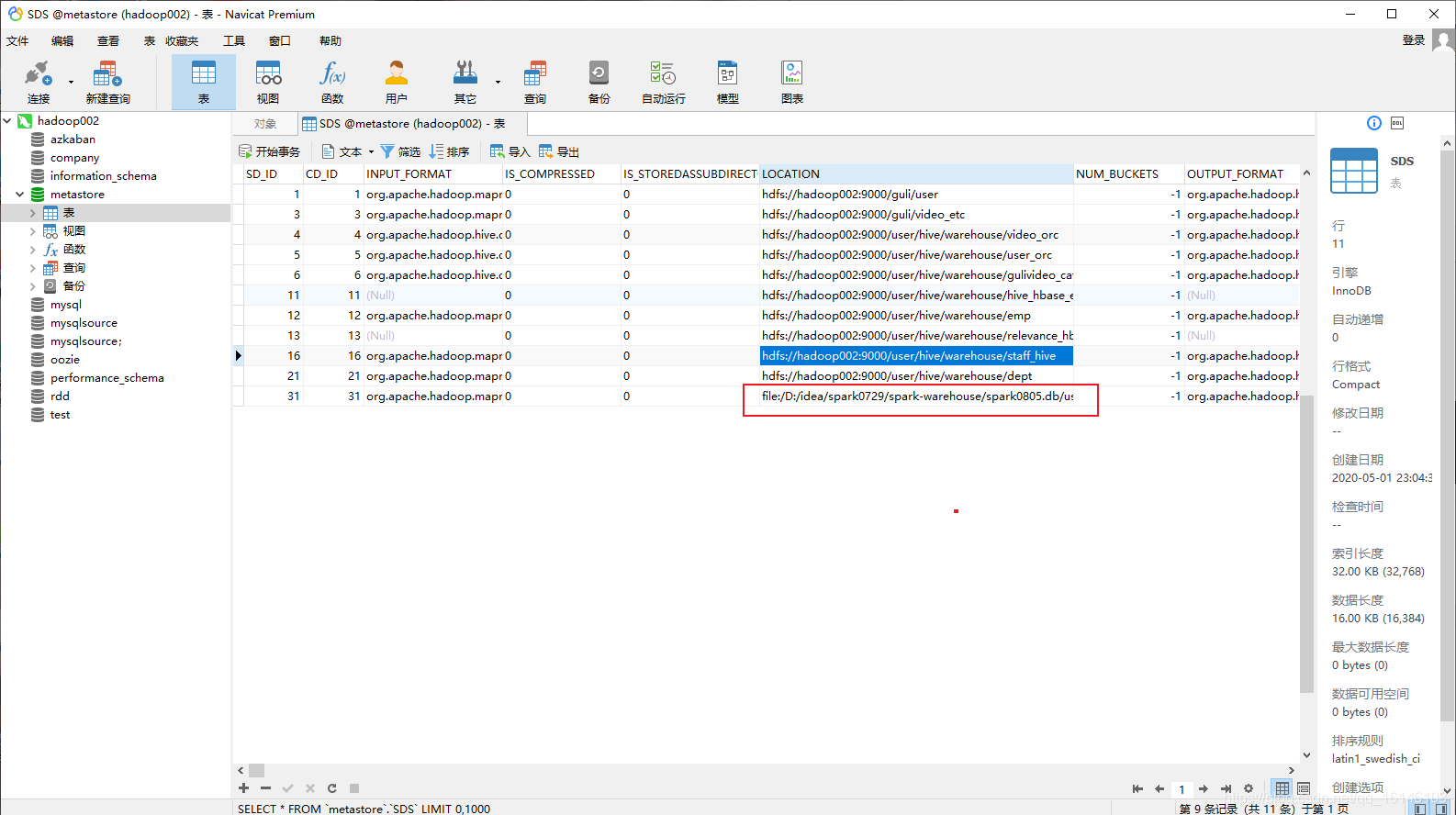
3.2.1.2 通过参数修改数据库仓库的地址
package com.buwenbuhuo.spark.sql.day02.hive import org.apache.spark.sql.SparkSession /** ** * * @author 不温卜火 * * * @create 2020-08-05 14:26 ** * MyImapBox : https://buwenbuhuo.blog.csdn.net/ * */ object HiveWrite { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME","bigdata") val spark: SparkSession = SparkSession .builder() .master("local[*]") .appName("HiveWrite") // 添加支持外部hive .enableHiveSupport() .config("spark.sql.warehouse.dir", "hdfs://hadoop002:9000/user/hive/warehouse") .getOrCreate() import spark.implicits._ // 先创建一个数据库 // 创建一次就行否则会报错 spark.sql("create database spark0806").show spark.sql("use spark0806") spark.sql("create table user1(id int,name string)").show spark.sql("insert into user1 values(10,'lisi')").show } }
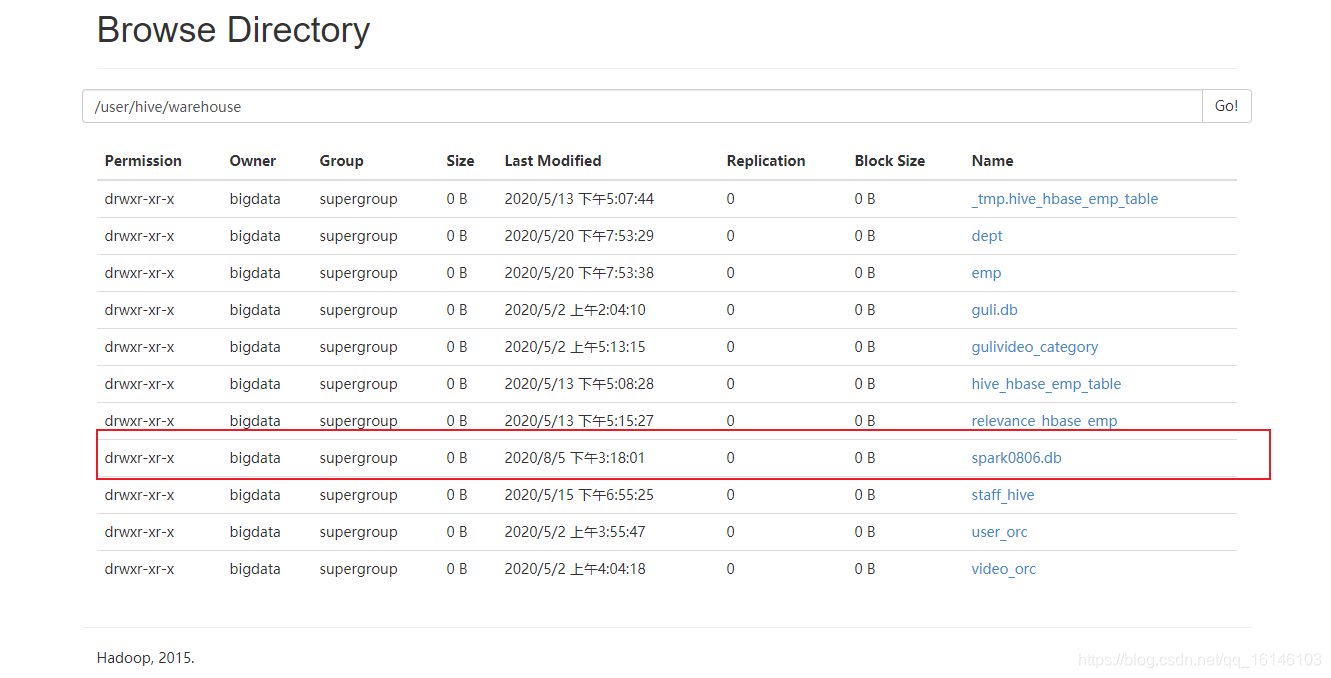
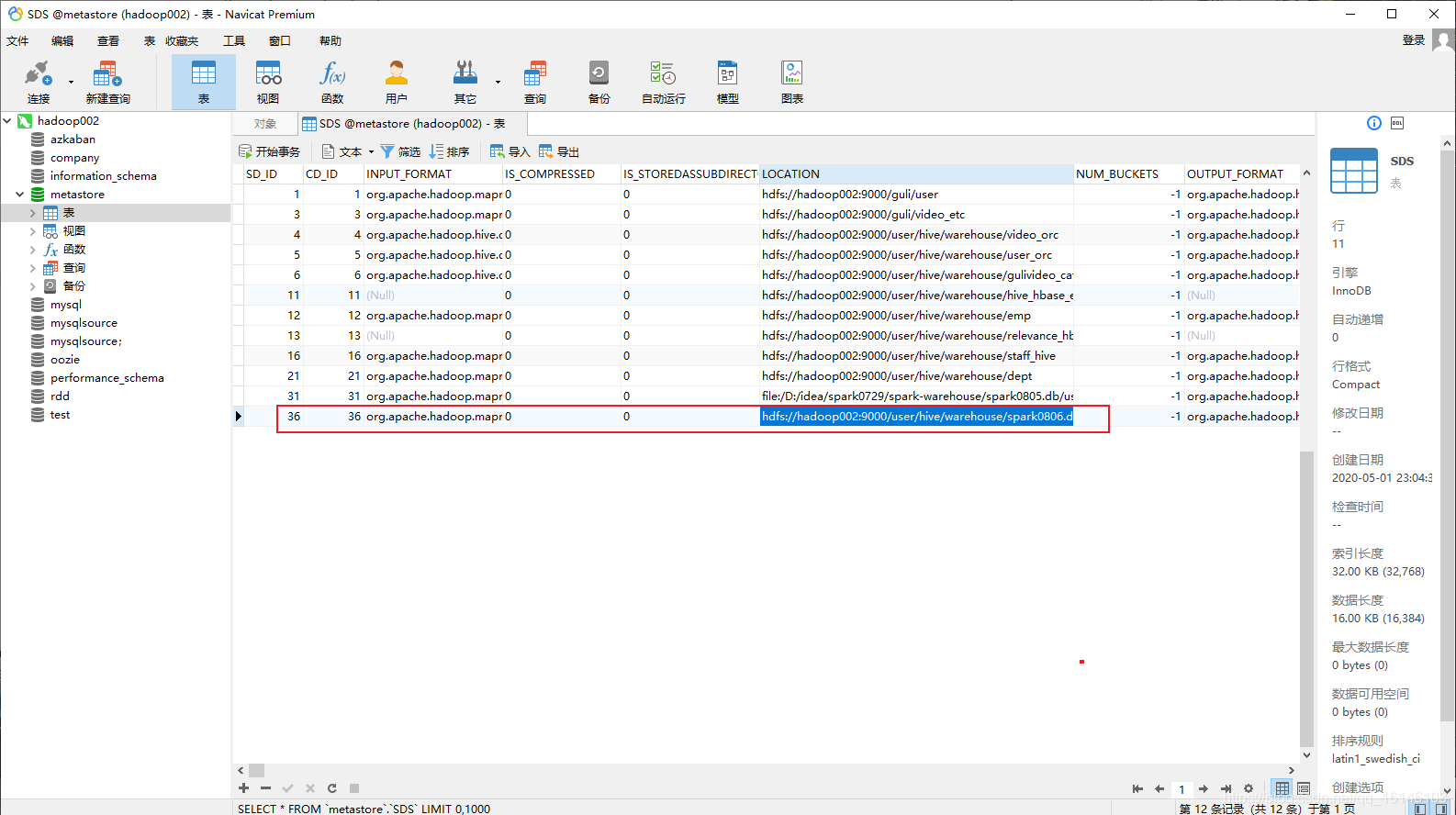
3.2.2 df.svaeAsTable(” “)
package com.buwenbuhuo.spark.sql.day02.hive import org.apache.spark.sql.{DataFrame, SparkSession} /** ** * * @author 不温卜火 * * * @create 2020-08-05 14:26 ** * MyImapBox : https://buwenbuhuo.blog.csdn.net/ * */ object HiveWrite { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME","bigdata") val spark: SparkSession = SparkSession .builder() .master("local[*]") .appName("HiveWrite") // 添加支持外部hive .enableHiveSupport() .config("spark.sql.warehouse.dir", "hdfs://hadoop002:9000/user/hive/warehouse") .getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("d:/users.json") spark.sql("user spark1016") // 可以把数据写入到hive中,表可以存着也可以不存在 df.write.mode("append").saveAsTable("user2") spark.close() } } 3.2.3 df.svaeAsTable(” “)
package com.buwenbuhuo.spark.sql.day02.hive import org.apache.spark.sql.{DataFrame, SparkSession} /** ** * * @author 不温卜火 * * * @create 2020-08-05 14:26 ** * MyImapBox : https://buwenbuhuo.blog.csdn.net/ * */ object HiveWrite { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME","bigdata") val spark: SparkSession = SparkSession .builder() .master("local[*]") .appName("HiveWrite") // 添加支持外部hive .enableHiveSupport() .config("spark.sql.warehouse.dir", "hdfs://hadoop002:9000/user/hive/warehouse") .getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("d:/users.json") spark.sql("user spark1016") df.write.insertInto("user2") // 基本等价于mode("append").saveAsTable("user2") spark.close() } }

如果我的博客对你有帮助、如果你喜欢我的博客内容,请“” “评论”“”一键三连哦!听说的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。后不要忘了关注我哦!

本网页所有视频内容由 imoviebox边看边下-网页视频下载, iurlBox网页地址收藏管理器 下载并得到。
ImovieBox网页视频下载器 下载地址: ImovieBox网页视频下载器-最新版本下载
本文章由: imapbox邮箱云存储,邮箱网盘,ImageBox 图片批量下载器,网页图片批量下载专家,网页图片批量下载器,获取到文章图片,imoviebox网页视频批量下载器,下载视频内容,为您提供.
阅读和此文章类似的: 全球云计算
 官方软件产品操作指南 (170)
官方软件产品操作指南 (170)









 1万+
1万+